数据松弛Data Relaxation
数据松弛作用:
train和test的特征各自去掉频率不一致的取值,让train和test关于某特征的各种取值的概率分布全都一致。
松弛代码:
import pandas as pd
import numpy as np
import multiprocessing
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
import lightgbm as lgb
import gc
from time import time
import datetime
import matplotlib.pyplot as plt
from tqdm import tqdm_notebook
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold, KFold, TimeSeriesSplit, train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import graphviz
import pandas as pd
import datatable as dt
warnings.simplefilter('ignore')
sns.set()
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage(deep=True).sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
c_prec = df[col].apply(lambda x: np.finfo(x).precision).max()
if c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max and c_prec == np.finfo(np.float32).precision:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df
def plot_numerical(feature):
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(16, 18))
sns.kdeplot(train[feature], ax=axes[0][0], label='Train');#第1行图的第1幅图
sns.kdeplot(test[feature], ax=axes[0][0], label='Test');#第1行图的第1幅图
sns.kdeplot(train[train['isFraud']==0][feature], ax=axes[0][1], label='isFraud 0')
sns.kdeplot(train[train['isFraud']==1][feature], ax=axes[0][1], label='isFraud 1')
test[feature].index += len(train)
axes[1][0].plot(train[feature], '.', label='Train');#第2行图的第1幅图
axes[1][0].plot(test[feature], '.', label='Test');
axes[1][0].set_xlabel('Row index');
axes[1][0].legend()
test[feature].index -= len(train)#减去偏置时间
axes[1][1].plot(train[train['isFraud']==0][feature], '.', label='isFraud 0');
axes[1][1].plot(train[train['isFraud']==1][feature], '.', label='isFraud 1');
axes[1][1].set_xlabel('row index');
axes[1][1].legend()
pd.DataFrame({'train': [train[feature].isnull().sum()], 'test': [test[feature].isnull().sum()]}).plot(kind='bar', rot=0, ax=axes[2][0]);
pd.DataFrame({'isFraud 0': [train[(train['isFraud']==0) & (train[feature].isnull())][feature].shape[0]],
'isFraud 1': [train[(train['isFraud']==1) & (train[feature].isnull())][feature].shape[0]]}).plot(kind='bar', rot=0, ax=axes[2][1]);
fig.suptitle(feature, fontsize=18);
#第1行的两个子图
axes[0][0].set_title('Train/Test KDE distribution');
axes[0][1].set_title('Target value KDE distribution');
#第2行的两个子图
axes[1][0].set_title('Index versus value: Train/Test distribution');
axes[1][1].set_title('Index versus value: Target distribution');
#第3行的两个子图
axes[2][0].set_title('Number of NaNs');
axes[2][1].set_title('Target value distribution among NaN values');
plt.show()
def relax_data(df_train, df_test, col):
cv1 = pd.DataFrame(df_train[col].value_counts().reset_index().rename({col:'train'},axis=1))
cv2 = pd.DataFrame(df_test[col].value_counts().reset_index().rename({col:'test'},axis=1))
cv3 = pd.merge(cv1,cv2,on='index',how='outer')
factor = len(df_test)/len(df_train)
cv3['train'].fillna(0,inplace=True)
cv3['test'].fillna(0,inplace=True)
cv3['remove'] = False
cv3['remove'] = cv3['remove'] | (cv3['train'] < len(df_train)/10000)
cv3['remove'] = cv3['remove'] | (factor*cv3['train'] < cv3['test']/3)
cv3['remove'] = cv3['remove'] | (factor*cv3['train'] > 3*cv3['test'])
cv3['new'] = cv3.apply(lambda x: x['index'] if x['remove']==False else 0,axis=1)
cv3['new'],_ = cv3['new'].factorize(sort=True)
cv3.set_index('index',inplace=True)
cc = cv3['new'].to_dict()
df_train[col] = df_train[col].map(cc)
df_test[col] = df_test[col].map(cc)
return df_train, df_test
数据准备:
train=pd.read_csv('./ieee-fraud-detection/train1.csv')
train=reduce_mem_usage(train)
test =pd.read_csv('./ieee-fraud-detection/test1.csv')
test=reduce_mem_usage(test)
松弛前的效果:
plot_numerical('C7')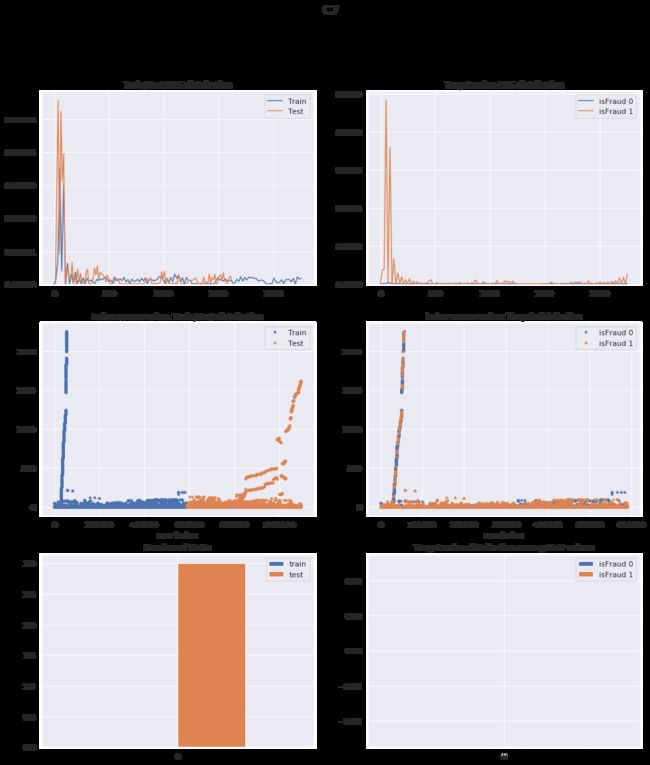
松弛后的效果:
train, test = relax_data(train, test, 'C7')
plot_numerical('C7')