机器学习案例1---A journey through Titanic
// 1.Imports 引入Python库
// pandas
import pandas as pd
from pandas import Series,DataFrame//#2. numpy,matplotlib,seaborn
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns #数据可视化模块
sns.set_style('whitegrid')//#3. machine learning 引入机器学习裤
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC,LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB#4.get titanic & test csv files as a DataFrame 读取数据
titanic_df=pd.read_csv("C://Users//Allen//Desktop//titantic//train.csv")
test_df=pd.read_csv("C://Users//Allen//Desktop//titantic//test.csv")#5.privew data 预览数据
titanic_df.head() PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S 6.字段解释:
VARIABLE DESCRIPTIONS:
是否生还 survival Survival
(0 = No; 1 = Yes)
等级 pclass Passenger Class
(1 = 1st; 2 = 2nd; 3 = 3rd)
姓名 name Name
性别 sex Sex
年龄 age Age
海外兄弟姐妹数 sibsp Number of Siblings/Spouses Aboard
海外父母/子女数 parch Number of Parents/Children Aboard
机票号 ticket Ticket Number
旅客票价 fare Passenger Fare
舱室 cabin Cabin
着陆地点 embarked Port of Embarkation
(C = Cherbourg; Q = Queenstown; S = Southampton)#7.查看数据表信息
titanic_df.info()
print("---------------------------------")
test_df.info()
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object*
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
---------------------------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB# 8.删除非必要字段, 在分析和预测中这些字段不会起作用
titanic_df=titanic_df.drop(['PassengerId','Name','Ticket'],axis=1)
test_df=test_df.drop(['Name','Ticket'],axis=1)# 9.分析各字段---Embarked
# only in titanic_df, fill the two missing values with the most occurred # value, which is "S".
titanic_df["Embarked"] =titanic_df["Embarked"].fillna("S")
# plot 绘图分析Embarked与Survived的关系 size,aspect两个参数用于控制图形大小比例
sns.factorplot('Embarked','Survived', data=titanic_df,size=4,aspect=3)fig, (axis1,axis2,axis3) = plt.subplots(1,3,figsize=(15,5))
#sns.factorplot('Embarked',data=titanic_df,kind='count',order=['S','C','Q'],ax=axis1)
#sns.factorplot('Survived',hue="Embarked",data=titanic_df,kind='count',order=[1,0],ax=axis2)
sns.countplot(x='Embarked', data=titanic_df, ax=axis1)
sns.countplot(x='Survived', hue="Embarked", data=titanic_df, order=[1,0], ax=axis2)
# group by embarked, and get the mean for survived passengers for each value in Embarked
embark_perc = titanic_df[["Embarked", "Survived"]].groupby(['Embarked'],as_index=False).mean()
sns.barplot(x='Embarked', y='Survived', data=embark_perc,order=['S','C','Q'],ax=axis3)
# Either to consider Embarked column in predictions,
# and remove "S" dummy variable,
# and leave "C" & "Q", since they seem to have a good rate for Survival.
# OR, don't create dummy variables for Embarked column, just drop it,
# because logically, Embarked doesn't seem to be useful in prediction.
embark_dummies_titanic=pd.get_dummies(titanic_df['Embarked'])
embark_dummies_titanic.drop(['S'],axis=1,inplace=True)
embark_dummies_test = pd.get_dummies(test_df['Embarked'])
embark_dummies_test.drop(['S'], axis=1, inplace=True)
titanic_df=titanic_df.join(embark_dummies_titanic)
test_df=test_df.join(embark_dummies_test)
titanic_df.drop(['Embarked'],axis=1,inplace=True)
test_df.drop(['Embarked'],axis=1,inplace=True)#Fare(机票价格) 字段分析 缺失值处理
# only for test_df, since there is a missing "Fare" values
test_df["Fare"].fillna(test_df["Fare"].median(),inplace=True)
# convert from float to int
titanic_df['Fare']=titanic_df['Fare'].astype(int)
test_df['Fare']=test_df['Fare'].astype(int)
# get average and std for fare of survived/not survived passengers
average_fare=DataFrame([fare_not_survived.mean(),fare_survived.mean()])
std_fare=DataFrame([fare_not_survived.std(),fare_survived.std()])#plot
titanic_df['Fare'].plot(kind='hist', figsize=(15,3),bins=100, xlim=(0,50))
average_fare.index.names = std_fare.index.names = ["Survived"]
average_fare.plot(yerr=std_fare,kind='bar',legend=False)
average_fare.plot(yerr=average_fare,kind='bar',legend=False)

# Age 年龄字段分析
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(15,4))
axis1.set_title('Original Age Values - Titanic')
axis2.set_title('New Age Values - Titanic')
# axis3.set_title('Original Age values - Test')
# axis4.set_title('New Age values - Test')
#Age
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(15,4))
axis1.set_title('Original Age Values - Titanic')
axis2.set_title('New Age Values - Titanic')
# axis3.set_title('Original Age values - Test')
# axis4.set_title('New Age values - Test')
# get average, std, and number of NaN values in titanic_df
average_age_titanic=titanic_df["Age"].mean()
std_age_titanic = titanic_df["Age"].std()
count_nan_age_titanic = titanic_df["Age"].isnull().sum()
# get average, std, and number of NaN values in test_df
average_age_test = test_df["Age"].mean()
std_age_test = test_df["Age"].std()
count_nan_age_test = test_df["Age"].isnull().sum()
# generate random numbers between (mean - std) & (mean + std)
rand_1=np.random.randint(average_age_titanic - std_age_titanic,average_age_titanic + std_age_titanic)
rand_2 = np.random.randint(average_age_test - std_age_test, average_age_test + std_age_test, size = count_nan_age_test)
# plot original Age values
# NOTE: drop all null values, and convert to int
titanic_df['Age'].dropna().astype(int).hist(bins=70, ax=axis1)
# fill NaN values in Age column with random values generated
titanic_df["Age"][np.isnan(titanic_df["Age"])] = rand_1
test_df["Age"][np.isnan(test_df["Age"])] = rand_2
# convert from float to int
titanic_df['Age'] = titanic_df['Age'].astype(int)
test_df['Age'] = test_df['Age'].astype(int)
# plot new Age Values
titanic_df['Age'].hist(bins=70, ax=axis2)
# test_df['Age'].hist(bins=70, ax=axis4)
#Age
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(15,4))
axis1.set_title('Original Age Values - Titanic')
axis2.set_title('New Age Values - Titanic')
# axis3.set_title('Original Age values - Test')
# axis4.set_title('New Age values - Test')
# get average, std, and number of NaN values in titanic_df
average_age_titanic=titanic_df["Age"].mean()
std_age_titanic = titanic_df["Age"].std()
count_nan_age_titanic = titanic_df["Age"].isnull().sum()
# get average, std, and number of NaN values in test_df
average_age_test = test_df["Age"].mean()
std_age_test = test_df["Age"].std()
count_nan_age_test = test_df["Age"].isnull().sum()
# generate random numbers between (mean - std) & (mean + std)
rand_1=np.random.randint(average_age_titanic - std_age_titanic,average_age_titanic + std_age_titanic)
rand_2 = np.random.randint(average_age_test - std_age_test, average_age_test + std_age_test, size = count_nan_age_test)
# plot original Age values
# NOTE: drop all null values, and convert to int
titanic_df['Age'].dropna().astype(int).hist(bins=70, ax=axis1)
# fill NaN values in Age column with random values generated
titanic_df["Age"][np.isnan(titanic_df["Age"])] = rand_1
test_df["Age"][np.isnan(test_df["Age"])] = rand_2
# convert from float to int
titanic_df['Age'] = titanic_df['Age'].astype(int)
test_df['Age'] = test_df['Age'].astype(int)
# plot new Age Values
titanic_df['Age'].hist(bins=70, ax=axis2)
# test_df['Age'].hist(bins=70, ax=axis4)
#Cabin
# It has a lot of NaN values, so it won't cause a remarkable impact on prediction 空值较多,需要删掉
titanic_df.drop("Cabin",axis=1,inplace=True)
test_df.drop("Cabin",axis=1,inplace=True)#Family
# Instead of having two columns Parch & SibSp,
# we can have only one column represent if the passenger had any family member aboard or not,
# Meaning, if having any family member(whether parent, brother, ...etc) will increase chances of Survival or not.
titanic_df['Family']=titanic_df["Parch"]+titanic_df["SibSp"]
titanic_df['Family'].loc[titanic_df['Family'] > 0] = 1
titanic_df['Family'].loc[titanic_df['Family'] == 0] = 0
test_df['Family'] = test_df["Parch"] + test_df["SibSp"]
test_df['Family'].loc[test_df['Family'] > 0] = 1
test_df['Family'].loc[test_df['Family'] == 0] = 0
# drop Parch & SibSp
titanic_df=titanic_df.drop(['SibSp','Parch'],axis=1)
test_df=test_df.drop(['SibSp','Parch'],axis=1)
#plot
fig,(axis1,axis2)=plt.subplots(1,2,sharex=True,figsize=(10,5))
#sns.factorplot('Family',data=titanic_df,kind='count',ax=axis1)
sns.countplot(x='Family', data=titanic_df, order=[1,0], ax=axis1)
# average of survived for those who had/didn't have any family member
family_perc = titanic_df[["Family", "Survived"]].groupby(['Family'],as_index=False).mean()
sns.barplot(x='Family', y='Survived', data=family_perc, order=[1,0], ax=axis2)
axis1.set_xticklabels(["With Family","Alone"], rotation=0)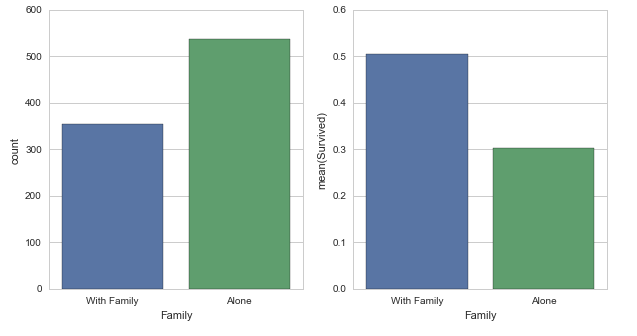
#Sex
#Sex
# As we see, children(age < ~16) on aboard seem to have a high chances for Survival.
# So, we can classify passengers as males, females, and child
def get_person(passenger):
age,sex=passenger
return 'child' if age<16 else sex
titanic_df['Person']=titanic_df[['Age','Sex']].apply(get_person,axis=1)
test_df['Person']=test_df[['Age','Sex']].apply(get_person,axis=1)
# No need to use Sex column since we created Person column
titanic_df.drop(['Sex'],axis=1,inplace=True)
test_df.drop(['Sex'],axis=1,inplace=True)
# create dummy variables for Person column, & drop Male as it has the lowest average of survived passengers
person_dummies_titanic=pd.get_dummies(titanic_df['Person'])
person_dummies_titanic.columns = ['Child','Female','Male']
person_dummies_titanic.drop(['Male'], axis=1, inplace=True)
person_dummies_test = pd.get_dummies(test_df['Person'])
person_dummies_test.columns = ['Child','Female','Male']
person_dummies_test.drop(['Male'], axis=1, inplace=True)
titanic_df=titanic_df.join(person_dummies_titanic)
test_df=test_df.join(person_dummies_test)
fig, (axis1,axis2) = plt.subplots(1,2,figsize=(10,5))
# sns.factorplot('Person',data=titanic_df,kind='count',ax=axis1)
sns.countplot(x='Person', data=titanic_df, ax=axis1)
# average of survived for each Person(male, female, or child)
person_perc = titanic_df[["Person", "Survived"]].groupby(['Person'],as_index=False).mean()
sns.barplot(x='Person', y='Survived', data=person_perc, ax=axis2, order=['male','female','child'])
titanic_df.drop(['Person'],axis=1,inplace=True)
test_df.drop(['Person'],axis=1,inplace=True)
#PClass
# sns.factorplot('Pclass',data=titanic_df,kind='count',order=[1,2,3])
sns.factorplot('Pclass','Survived',order=[1,2,3], data=titanic_df,size=5)
# create dummy variables for Pclass column, & drop 3rd class as it has the lowest average of survived passengers
pclass_dummies_titanic = pd.get_dummies(titanic_df['Pclass'])
pclass_dummies_titanic.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_titanic.drop(['Class_3'], axis=1, inplace=True)
pclass_dummies_test = pd.get_dummies(test_df['Pclass'])
pclass_dummies_test.columns = ['Class_1','Class_2','Class_3']
pclass_dummies_test.drop(['Class_3'], axis=1, inplace=True)
titanic_df.drop(['Pclass'],axis=1,inplace=True)
test_df.drop(['Pclass'],axis=1,inplace=True)
titanic_df = titanic_df.join(pclass_dummies_titanic)
test_df = test_df.join(pclass_dummies_test)
================================================================================
#define train and testing sets
X_train=titanic_df.drop("Survived",axis=1)
Y_train=titanic_df["Survived"]
X_test=test_df.drop("PassengerId",axis=1).copy()# Logistic Regression
logreg=LogisticRegression()
logreg.fit(X_train,Y_train)
Y_pred=logreg.predict(X_test)
logreg.score(X_train,Y_train)
// 0.8058361391694725# Support Vector Machines
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
svc.score(X_train, Y_train)
//0.85746352413019078#Random Forest
random_forest=RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train,Y_train)
Y_pred=random_forest.predict(X_test)
random_forest.score(X_train,Y_train)
//0.96296296296296291#knn
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train,Y_train)
Y_pred=knn.predict(X_test)
knn.score(X_train,Y_train)
//0.84062850729517391# Gaussian Naive Bayes
gaussian=GaussianNB()
gaussian.fit(X_train,Y_train)
Y_pred=gaussian.predict(X_test)
gaussian.score(X_train,Y_train)
//0.76094276094276092
# get Correlation Coefficient for each feature using Logistic Regression
coeff_df=DataFrame(titanic_df.columns.delete(0))
coeff_df.columns=['Features']
coeff_df["Coefficient Estimate"] = pd.Series(logreg.coef_[0])
//preview
coeff_df
//Features Coefficient Estimate
//0 Age -0.027647
//1 Fare 0.000811
//2 C 0.604322
//3 Q 0.312577
//4 Family -0.274143
//5 Child 1.779651
//6 Female 2.774104
//7 Class_1 2.060579
//8 Class_2 1.126502