好好学习,天天向上
本文已收录至我的Github仓库DayDayUP:github.com/RobodLee/DayDayUP,欢迎Star,更多文章请前往:目录导航
- 畅购商城(一):环境搭建
- 畅购商城(二):分布式文件系统FastDFS
- 畅购商城(三):商品管理
- 畅购商城(四):Lua、OpenResty、Canal实现广告缓存与同步
- 畅购商城(五):Elasticsearch实现商品搜索
- 畅购商城(六):商品搜索
品牌统计
当我们在京东上搜索智能手机的时候,会将相关品牌罗列出来供用户选择
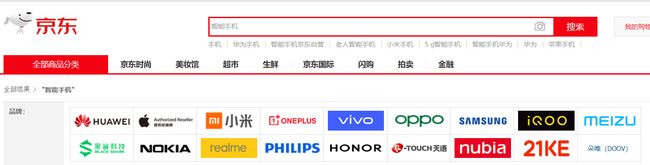
我们要实现的也是这个功能,就是将搜索结果中的品牌进行分类统计
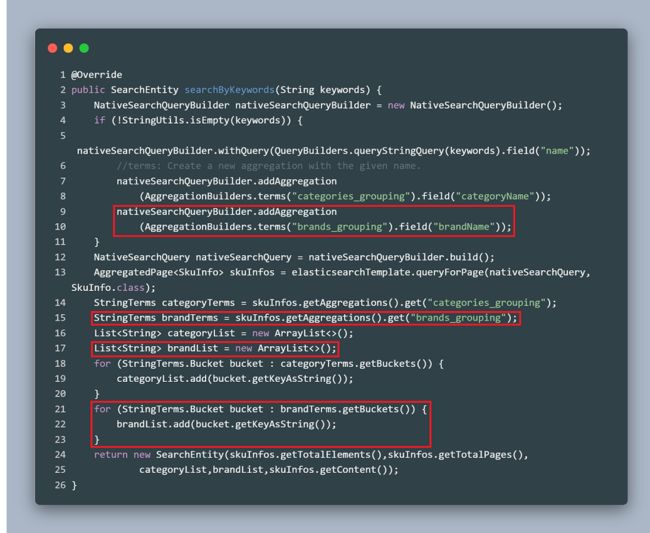
这个功能和上一篇文章中提到的分类统计是一毛一样的,所以添加几行代码就搞定了。
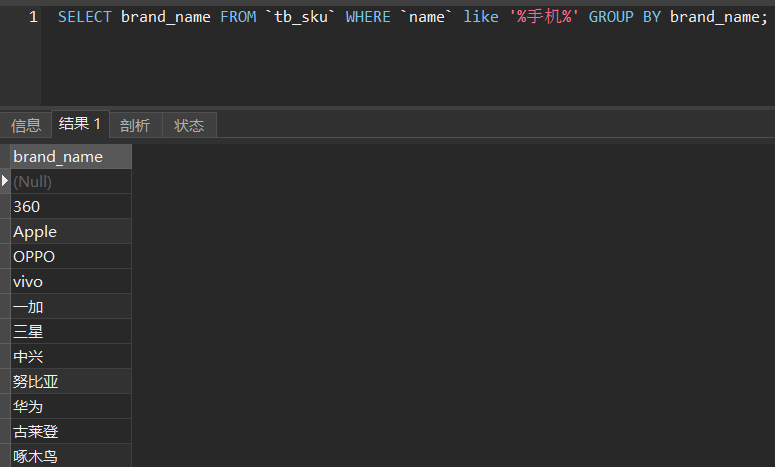
但是我在搜索“智能手机”的时候,品牌只出现了两个,这显然和实际不符。原因很简单,就是“ik_smart”并没有将“智能手机”拆分成“智能”和“手机”,所以将分词模式改成“ik_max_word”就好了。将SkuInfo中name字段从“ik_smart”改成“ik_max_word”,然后重新导入数据,再来测试一下:
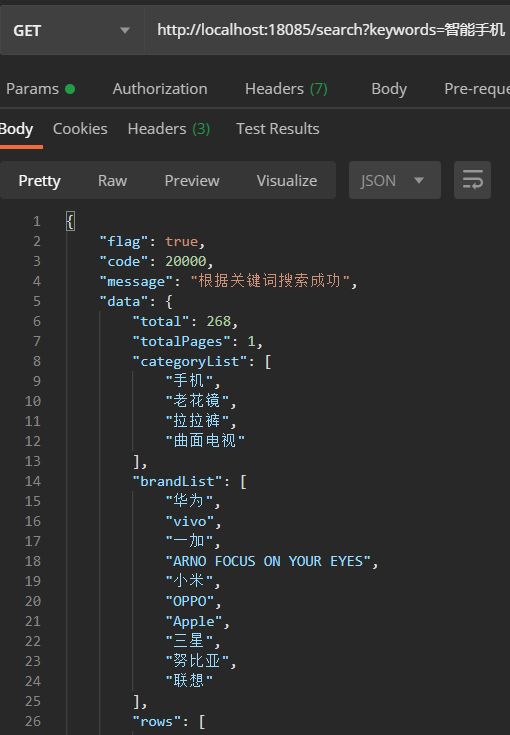
这样就对了。
规格统计
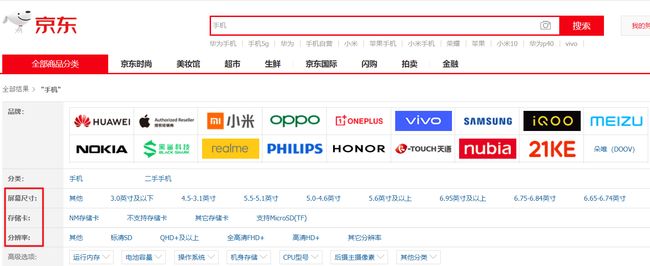
当我们在京东上面搜索的时候,会将规格信息罗列出来用户选择。在我们的ES中也有规格信息,但这些信息都是json字符串,我们要做的就是把这些json字符串转换成Map集合从而实现和京东相同的功能。

在SkuEsServiceImpl的searchByKeywords方法中添加以下代码:
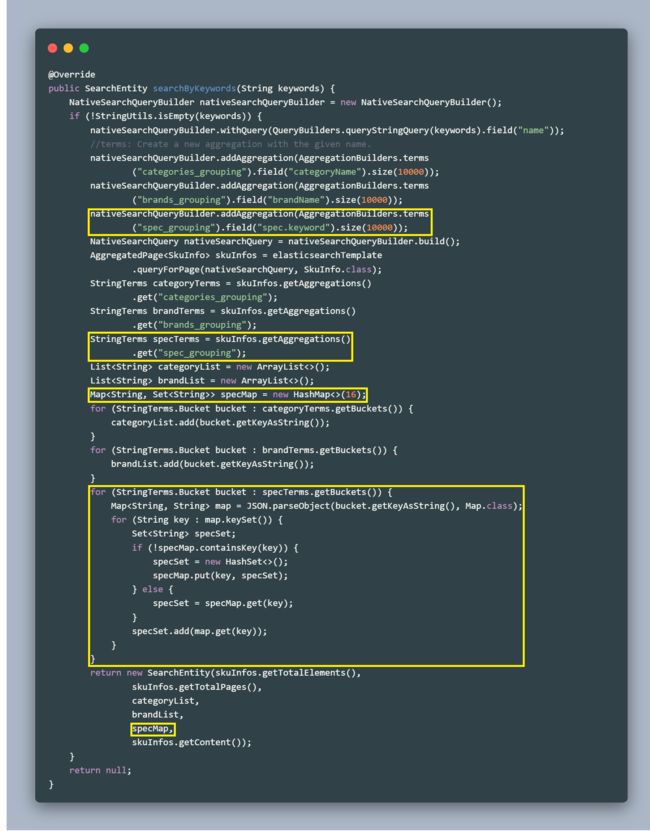
从代码中可以看出,先是添加搜索条件,然后从搜索结果中取出spec的集合,遍历存放进specMap里面。因为搜索结果是一条条的json字符串,所以每次将json字符串转换成map集合,再遍历map,从map中依次取出数据放入specSet。如果specMap中没有对应的specSet就直接new一个并存入进去,有的话就直接从specMap取出。最后将specMap放入SearchEntity返回给前端即可。

条件筛选
分类和品牌过滤
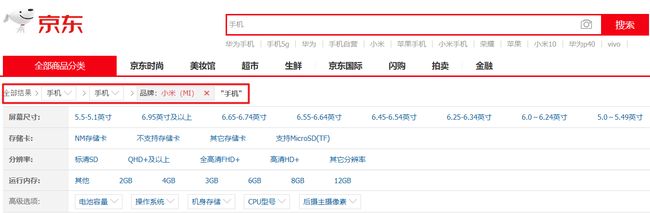
当我们把品牌或分类作为条件搜索的时候,就不用去处理品牌和分类统计了。之前只有一个keywords参数我就直接写在了地址栏里,但现在参数多了,还是封装进SearchEntity吧,然后参数写在请求体里面。
private String keywords; //前端传过来的关键词信息
private String brand; //前端传过来的品牌信息
private String category; //前端传过来的分类信息
然后在SkuEsServiceImpl的searchByKeywords方法中添加代码,我现在的searchByKeywords已经写得很臃肿了,先不管这个问题,最后再去优化代码。
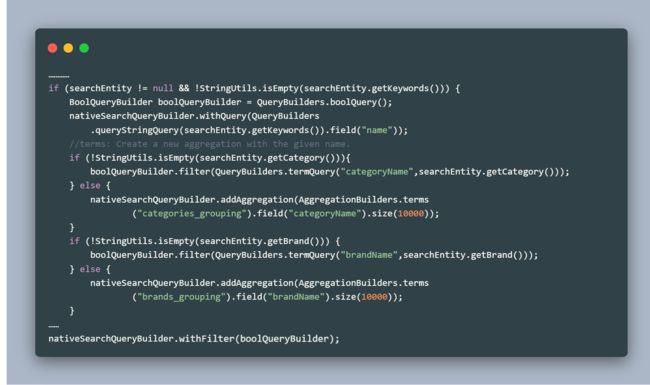
如果category或brand参数不为空就作为条件筛选,不进行统计,否则还是进行统计。需要注意的是这里使用了withFilter()方法,其实withQuery()也是可以的,但是用withQuery()的话高亮搜索就不行了,所以要用withFilter()。
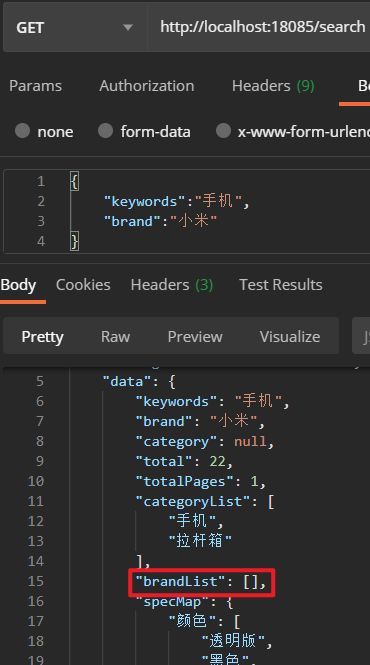
可以看到,现在指定了品牌信息但不指定分类信息,品牌就不会进行统计,分类还是会进行统计,达到了我们预期的效果。
规格过滤
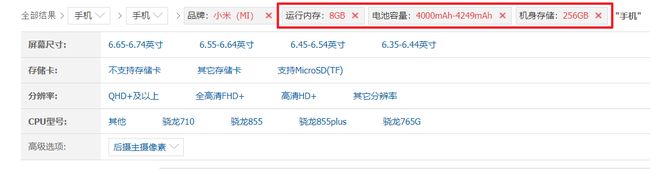
和上面一个一样,当我们把规格作为参数传给后端,同样也不会去进行规格统计。要实现这个功能,首先还得在SearchEntity中加一个字段用来接收规格参数。
private List searchSpec; //前端传过来的规格信息
然后在SkuEsServiceImpl的searchByKeywords方法中添加代码:
……
Map searchSpec = searchEntity.getSearchSpec();
if (searchSpec != null && searchSpec.size() > 0) {
for (String key:searchSpec.keySet()){
//格式:specMap.规格名字.keyword keyword表示不分词
boolQueryBuilder.filter(QueryBuilders.termQuery("specMap."+key+".keyword",searchSpec.get(key)));
}
}
……
获取前端传过来的searchSpec,然后遍历取出规格的内容,再用boolQueryBuilder.filter()进行过滤。
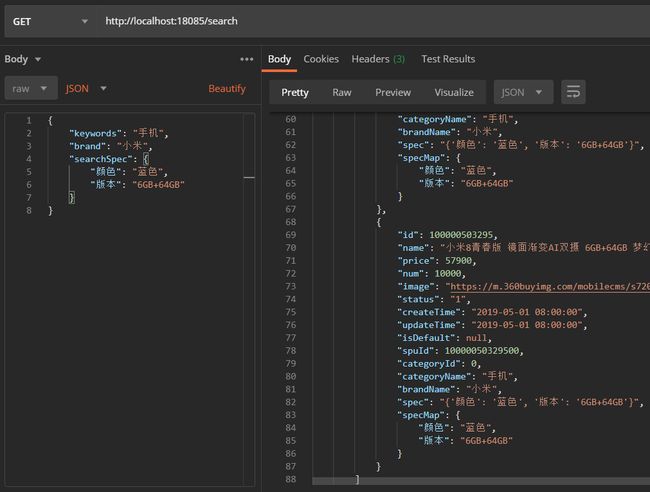
从图中可以看出,当我们指定颜色为蓝色,版本为“6GB+64GB”,结果中就都是我们筛选过的结果。
价格过滤
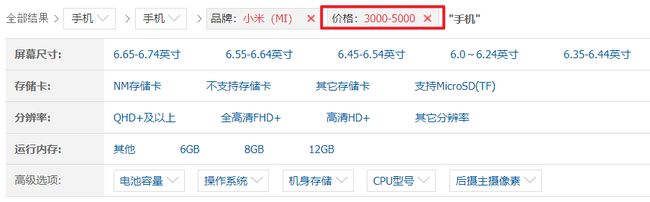
当我们在京东上面搜索产品的时候,可以指定一个价格区间。现在要实现的也是同样的功能。首先,还是要在SearchEntity中添加一个字段用于接收间隔区间参数。
private String price; //前端穿过来的价格区间字符串 300-500元 3000元以上
然后添加实现的代码:
……
if (!StringUtils.isEmpty(searchEntity.getPrice())) {
String[] price = searchEntity.getPrice().replace("元","")
.replace("以上","").split("-");
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(Integer.parseInt(price[0])));
if (price.length>1){
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").lt(Integer.parseInt(price[1])));
}
}
……

这样就可以实现对价格的过滤了。
分页功能
分页功能就比较简单了,接收前端传进来的pageNum参数,然后调用nativeSearchQueryBuilder.withPageable()方法就可以实现分页。
int pageNum = 1;
if (!StringUtils.isEmpty(searchEntity.getPageNum())) {
pageNum = Integer.parseInt(searchEntity.getPageNum());
}
nativeSearchQueryBuilder.withPageable(PageRequest.of(pageNum-1,SEARCH_PAGE_SIZE));
代码很简单,给pageNum一个默认值,如果前端没有传参数过来就显示第一页,每页的条数是10条。我定义的一个常量SEARCH_PAGE_SIZE去表示10。
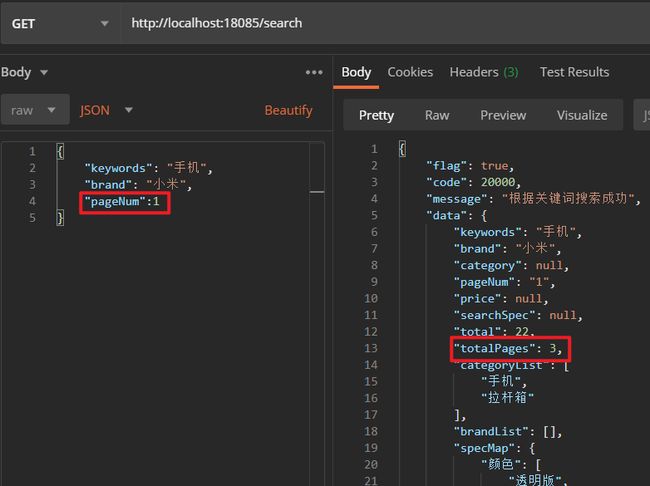
可以看到,一共搜索到22条数据,10条一页的话就是3页,分页是正确的。
排序

排序功能比较简单,就是将要排序的域和排序方式传到对应的方法里面即可。
String sortField = searchEntity.getSortField();
String sortRule = searchEntity.getSortRule();
if (!StringUtils.isEmpty(sortField) && !StringUtils.isEmpty(sortRule)) {
nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort(sortField).order(SortOrder.valueOf(sortRule)));
}
sortField是要排序的域,sortRule是要排序的方式,如果这两个参数都不为空的话就调用withSort方法添加搜索条件即可。这样就可以了。
高亮显示
我们平时在京东或者淘宝搜索的时候,关键词都会高亮显示。
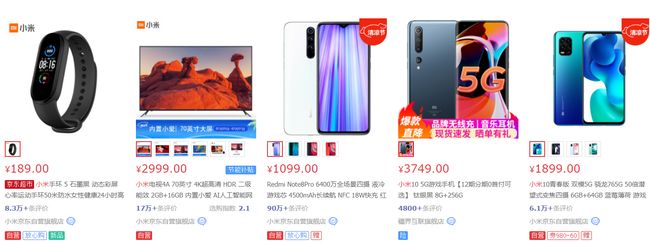
其实实现起来也很简单,只要将搜索词用html包裹起来,样式改为红色即可。
首先需要配置高亮,也就是指定高亮的域:
HighlightBuilder.Field field = new HighlightBuilder.Field("name"); //指定域
field.preTags(""); //指定前缀
field.postTags(""); //指定后缀
nativeSearchQueryBuilder.withHighlightFields(field);
在这段代码中,我们指定了要高亮搜索的域,并为其添加了高亮显示的html代码。
指定完需要高亮显示的域后,就需要进行高亮搜索,将非高亮数据替换成高亮数据。之前搜索的时候用的是queryForPage(SearchQuery query, Class方法,现在改成queryForPage(SearchQuery query, Class方法。
AggregatedPage skuInfos = elasticsearchTemplate
.queryForPage(nativeSearchQuery, SkuInfo.class, new SearchResultMapper() {
@Override
public AggregatedPage mapResults(SearchResponse response, Class clazz, Pageable pageable) {
List list = new ArrayList<>();
for (SearchHit hit : response.getHits()) { //遍历所有数据
SkuInfo skuInfo = JSON.parseObject(hit.getSourceAsString(), SkuInfo.class);//非高亮数据
HighlightField highlightField = hit.getHighlightFields().get("name"); //高亮数据
//将非高亮数据替换成高亮数据
if (highlightField != null && highlightField.getFragments() != null) {
Text[] fragments = highlightField.getFragments();
StringBuilder builder = new StringBuilder();
for (Text fragment : fragments) {
builder.append(fragment.toString());
}
skuInfo.setName(builder.toString());
list.add((T) skuInfo);
}
}
return new AggregatedPageImpl(list, pageable,
response.getHits().getTotalHits(),response.getAggregations());
}
});
我运行的时候发现过滤搜索的skuInfos.getAggregations()总是报空指针异常,我还以为是高亮搜索和过滤搜索不能在一起用,最后才发现我把这里的response.getAggregations()写丢了,少了一个参数。所以这里要注意一下。
代码优化
之前看视频的时候发现他写得不太好,其实只要查一次就好了,但是却查询了很多次,不过视频的最后也提到了这个问题并改进了代码。所以我之前并没有按照视频中的写,而是挤在一个方法里想着最后再去优化,最后一个方法写了有一百多行,简直太臃肿了,而且《阿里巴巴Java开发手册》里也提到过一个方法不要超过80行。现在搜索功能都已经实现了,可以去优化一下了。下面是我优化过的代码
@Override
public SearchEntity searchByKeywords(SearchEntity searchEntity) {
if (searchEntity != null && !StringUtils.isEmpty(searchEntity.getKeywords())) {
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
//配置高亮
HighlightBuilder.Field field = new HighlightBuilder.Field("name");
field.preTags("");
field.postTags("");
nativeSearchQueryBuilder.withHighlightFields(field);
//条件筛选或者分组统计
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (!StringUtils.isEmpty(searchEntity.getCategory())) { //分类过滤
boolQueryBuilder.filter(QueryBuilders.termQuery("categoryName", searchEntity.getCategory()));
} else {
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms
("categories_grouping").field("categoryName").size(10000));
}
if (!StringUtils.isEmpty(searchEntity.getBrand())) { //品牌过滤
boolQueryBuilder.filter(QueryBuilders.termQuery("brandName", searchEntity.getBrand()));
} else {
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms
("brands_grouping").field("brandName").size(10000));
}
nativeSearchQueryBuilder.addAggregation(AggregationBuilders.terms
("spec_grouping").field("spec.keyword").size(10000));
if (!StringUtils.isEmpty(searchEntity.getPrice())) { //价格过滤
String[] price = searchEntity.getPrice().replace("元", "")
.replace("以上", "").split("-");
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(Integer.parseInt(price[0])));
if (price.length > 1) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").lt(Integer.parseInt(price[1])));
}
}
Map searchSpec = searchEntity.getSearchSpec();
if (searchSpec != null && searchSpec.size() > 0) {
for (String key : searchSpec.keySet()) {
boolQueryBuilder.filter(QueryBuilders.termQuery("specMap." + key + ".keyword", searchSpec.get(key)));
}
}
//分页
int pageNum = (!StringUtils.isEmpty(searchEntity.getPageNum()))
? (Integer.parseInt(searchEntity.getPageNum())) : 1;
nativeSearchQueryBuilder.withPageable(PageRequest.of(pageNum - 1, SEARCH_PAGE_SIZE));
//排序
String sortField = searchEntity.getSortField();
String sortRule = searchEntity.getSortRule();
if (!StringUtils.isEmpty(sortField) && !StringUtils.isEmpty(sortRule)) {
nativeSearchQueryBuilder
.withSort(SortBuilders.fieldSort(sortField).order(SortOrder.valueOf(sortRule)));
}
nativeSearchQueryBuilder
.withQuery(QueryBuilders.queryStringQuery(searchEntity.getKeywords()).field("name"))
.withFilter(boolQueryBuilder); //这两行顺序不能颠倒
AggregatedPage skuInfos = elasticsearchTemplate
.queryForPage(nativeSearchQueryBuilder.build(), SkuInfo.class, new SearchResultMapperImpl());
Aggregations aggregations = skuInfos.getAggregations();
List categoryList = buildGroupList(aggregations.get("categories_grouping"));
List brandList = buildGroupList(aggregations.get("brands_grouping"));
Map> specMap = specGroup(aggregations.get("spec_grouping"));
searchEntity.setTotal(skuInfos.getTotalElements());
searchEntity.setTotalPages(skuInfos.getTotalPages());
searchEntity.setCategoryList(categoryList);
searchEntity.setBrandList(brandList);
searchEntity.setSpecMap(specMap);
searchEntity.setRows(skuInfos.getContent());
return searchEntity;
}
return null;
}
//将过滤搜索出来的StringTerms转换成List集合
private List buildGroupList(StringTerms stringTerms) {
List list = new ArrayList<>();
if (stringTerms != null) {
for (StringTerms.Bucket bucket : stringTerms.getBuckets()) {
list.add(bucket.getKeyAsString());
}
}
return list;
}
//规格统计
private Map> specGroup(StringTerms specTerms) {
Map> specMap = new HashMap<>(16);
for (StringTerms.Bucket bucket : specTerms.getBuckets()) {
Map map = JSON.parseObject(bucket.getKeyAsString(), Map.class);
for (String key : map.keySet()) {
Set specSet;
if (!specMap.containsKey(key)) {
specSet = new HashSet<>();
specMap.put(key, specSet);
} else {
specSet = specMap.get(key);
}
specSet.add(map.get(key));
}
}
return specMap;
}
queryForPage里的SearchResultMapper参数被我单独拎了出来:
public class SearchResultMapperImpl implements SearchResultMapper {
@Override
public AggregatedPage mapResults(SearchResponse response, Class clazz, Pageable pageable) {
List list = new ArrayList<>();
for (SearchHit hit : response.getHits()) { //遍历所有数据
SkuInfo skuInfo = JSON.parseObject(hit.getSourceAsString(), SkuInfo.class);//非高亮数据
HighlightField highlightField = hit.getHighlightFields().get("name"); //高亮数据
//将非高亮数据替换成高亮数据
if (highlightField != null && highlightField.getFragments() != null) {
Text[] fragments = highlightField.getFragments();
StringBuilder builder = new StringBuilder();
for (Text fragment : fragments) {
builder.append(fragment.toString());
}
skuInfo.setName(builder.toString());
list.add((T) skuInfo);
}
}
return new AggregatedPageImpl(list, pageable,
response.getHits().getTotalHits(),response.getAggregations());
}
}
虽然代码还是挺多的,但是逻辑清晰了很多。虽然还可以优化一下,但是我觉得没这个必要。现在测试一下:
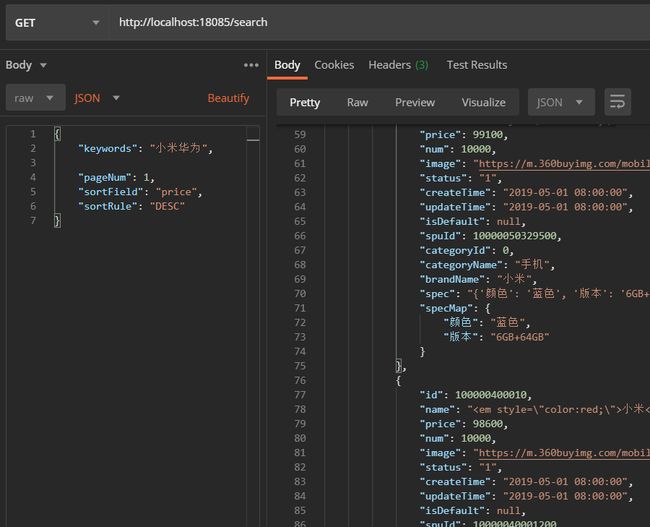
好了,所有功能都正常运行了。
小结
上一篇只是简单地把环境搭建了,并且只做了一个关键词搜索和分类统计的功能。那么这篇文章就是对上一篇文章的补充。实现了品牌统计,规格统计,条件筛选,分页,排序以及高亮显示的功能。至此,商品搜索的功能就全部完成了。
如果我的文章对你有些帮助,不要忘了点赞,收藏,转发,关注。要是有什么好的意见欢迎在下方留言。让我们下期再见!
