论文笔记 AAAI2020 Deep Embedded Complementary and Interactive Information for Multi-view Classification
论文笔记
- 论文阅读
- 内容简介
- 多视图学习
- 拼接
- 投影变换
- 监督扩展
- 深度学习投影变换
- 主要方法和策略
- 模型结构
- 预处理多视图数据
- 成对交互信息
- 融合多种信息
- 多视图损失融合
- 优化过程
- 实验过程和结果
- 代码复现
- 文件下载和读取
- 参数修改
- 训练
- 测试
最近看到了这篇文章,觉得可以拿来参考,先做个阅读笔记记录一下。
论文阅读
先附上论文地址
内容简介
论文背景介绍,如果是熟悉多视图学习的可以跳过。
多视图学习
多视图学习通过充分利用互补视图来进一步改进各种计算机视觉应用的性能,不同视图之间的深入交互信息以及融合。多视图是指对象的多种不同表示形式,并全面地描述了对象的所有信息。在实际应用中,许多对象具有一组以多种视图形式呈现的不同且互补的表示形式。(简单点比喻,一张RGB图片3个通道都能认为是3个视图。)
拼接
一种比较原始直接的做法就是把多个视图数据拼成一个文件然后计算。这样做有两个缺点:
- 忽略了视图间的相互信息
- 没有体现不同视图不同的重要程度
投影变换
除了上面原始的做法之外,还有人提出了投影变换的方法。对于一对(2个)视图,学习两个投影矩阵使两个视图投影后结果互相关性最大,或者以通过最大化所有成对视图的总相关性来获得多个变换。比起直接拼接该方法利用了视图间的相互信息,然而它是无监督的,可能导致获得的转换不利于分类。
监督扩展
针对上述投影无监督的缺点就有人提出了一个改进方向,就是利用LDA(线性判别,可以当做二分类模型,也可以认为是把数据降维到class_num-1维的降维方法)的方法学习线性变换来找到可区分的公共空间。但是,这些基于LDA的方法在某些具有挑战性的方案中无法捕获某些微妙但重要的结构。
深度学习投影变换
研究表明利用更灵活的深度神经网络来学习非线性表示可以实现更高的性能。用深层的神经网络来学习这个投影变换。有深度LDA的,也有共同训练多个网络以让它们相似的,还有借用VAE架构,让视图之间的重构结果相似,以及利用核方法的。

主要方法和策略
该文章的创新思想为:
- 输入基于多个神经网络,从不同实体视图提取的各种特征。从不同实体视图提取的各种特征。(个人感觉像风格迁移从不同网络提取中间输出当输入一样)
- 考虑了由深度共享的互动子网传递的互动信息,其中互动信息是由不同视图之间的属性互相关而产生的,显式地建模视图之间的关系
- 模型框架为多视点计算多个损失,并以自适应加权方式将其融合,在训练过程中可以学习权重并灵活调整权重
模型结构
先把结构图放出来,按照图分部分说明
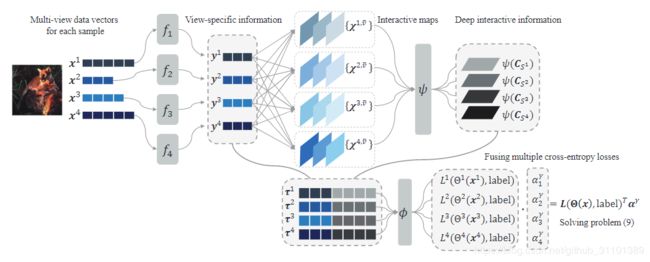
预处理多视图数据

不同视图的原始数据可能不同维度(尺寸),我们用不同的神经网络提取特征的同时可以把他们放到同一维度。也就是模型结构的开头部分。
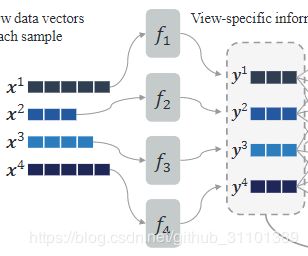
成对交互信息
经过预处理之后,假设每个视图的数据都变成d维了。对于两个不同的视图 v v v和 v ~ \tilde{v} v~产生一个dxd大小的矩阵X当作两者的互信息矩阵。E代表期望
![]()
那么对于每个视图,都会产生M-1个互信息矩阵。示例中4个视图,所以每个视图产生3个矩阵。
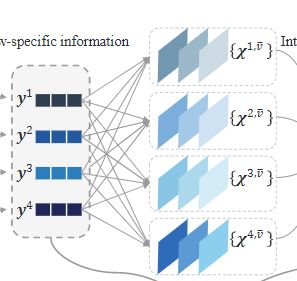
然后我们用同一个网络(下图的 φ \varphi φ)处理这些互信息矩阵,把每个矩阵从dxd压缩到d维。那么一个视图M-1个互信息矩阵就合起来变成了一个M-1 X d大小的矩阵了,把这个矩阵当作一个视图和其他所有视图的互信息。
融合多种信息
把预处理的视图信息和互信息矩阵拼接起来,作为最后的一个输入。
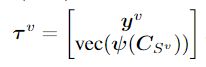
然后用一个共同的两层fc层的网络映射到class_num维度当作输出。(注意有多个视图,所以会有多个label输出结果)
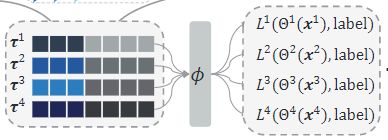
多视图损失融合
多个视图就会有多个视图的输出,代表着有多个损失,那么到底选择什么当作总体损失去优化呢?文章采取了如下一个方法把多个损失带权融合,注意是带上指数 γ \gamma γ>1的,进一步调整权重。
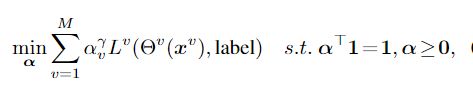
优化过程
模型涉及的3个网络(预处理,互信息,融合输出)都可以反向传播计算。
需要考虑的是损失融合的权重 α \alpha α怎么调整。通过解带约束的最优化问题,得
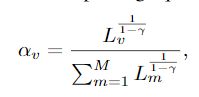
L L L为对应视图得交叉熵损失。先求出这些损失,再更新对应得权重进行融合。
实验过程和结果
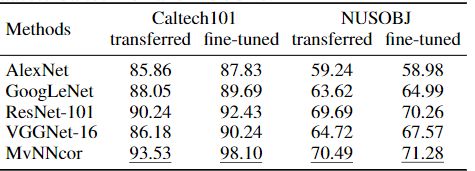
作者在六个数据集上进行对比试验,对比模型为SVMcon、DeepLDA、MvDA、DCCA、DCCAE、GradKCCA、MvNNcor本文模型均取得最好结果。同时作者也进行了网络结构删减和参数调整得实验(用来输入得两层fc网络中间隐节点, γ \gamma γ取值等)详细可以去看原文。
值得一提的是作者进行另外一个实验,利用几个经典的CNN网络架构提取同一图片的不同特征当作不同视图数据处理也得到了不错的结果。
代码复现
作者给出了源码,大家可以直接前往下载,代码不长,结构也比较精简,这里重要记录一下复现过程得一些问题。
文件下载和读取
文章做实验的六组数据比较大,作者就没有传到github上,但是在/mvdata文件夹中作者附上了两个百度网盘链接,大家可以下载前往下载,一个是AWA数据,一个是其余5个数据。
作者在dataset文件夹里面写好6个数据集的读取,在MvNNcor_Test.py里面引用了哪些函数可以根据输入的参数选取读取的数据集,但是MvNNcor_Train.py只有引用了一个AWA的,其他的需要大家手动添加并且根据输入自动选择不同的dataset方法。
参数修改
训练
作者给出了样例
python MvNNcor_Train.py --dataset_dir=./mvdata/AWA/Features --data_name=AWA --num_classes=50 --num_view=6 --gamma=6.0
- dataset_dir:没啥好说的,文件路径,AWA数据到Features文件夹,其他数据到 . m a t .mat .mat文件.
- data_name:一个显示参数告诉程序你要用哪个数据集,用哪个dataset函数,具体值和文件里对应即可。
- num_classes:这个数据集的类别个数,可以看论文里的数据集描述。
- num_view:这个数据集的视图个数,也可以看论文里的数据集描述。
- gamma:模型控制带权融合指数的参数,不建议修改。
测试
作者样例为
python MvNNcor_Test.py --dataset_dir=./mvdata/AWA/Features --data_name=AWA --resume=./results/.../model_best.pth.tar --num_classes=50 --num_view=6 --gamma=6.0
其他和训练一样,就是resume参数需要一下,就是训练完的最优模型存储位置。train后会自动保存,路径为./result/MvNNcor_+ data_name + epochs + gamma/model_best.pth.tar,比如样例中AWA数据训练完之后的存储位置就是./result/MvNNcor_AWA_100_6.0/model_best.pth.tar具体大家可以训练完之后查看一下目录。