Attention机制(语义分割) ~ 从经典去噪算法Non-local mean(NLM)到 Non-local neural network 到 CCNet
1. Non-local Means
非局部化(Non-local Means)滤波算法原理:
非局部化图像修复算法是近来新兴的图像处理算法,其原理是通过寻找整幅图像中与待恢复区域相似的块,再将找出的所有相似块通过某种相似性准则(如K均值聚类)进行聚类后联合滤波,从而减少图像噪声。而对于图像相似性的计算,可以通过比较一个窗口内的各个像素值来得到。
具体参看:NLM原理
2. Non-local neural network
论文地址:https://arxiv.org/abs/1711.079719
文章基于图片滤波领域的非局部均值滤波操作思想(NLM),提出了一个泛化、简单、可直接嵌入到当前网络的非局部操作算子,可以捕获时间(一维时序信号)、空间(图片)和时空(视频序列)的远程依赖(long range dependencies)。
简单讲单纯的一层卷积操作其实都是很local的,因此为了达到non local的效果(也就是文中说的获取 long range dependency),一般就是不断叠加这样的特征提取层,这样高层网络的感受野(receptive field)就越来越大,获取的信息分布广度也越来越高。但是这种不断叠加的方式必然会带来计算量的增加和优化难度的增加,因此就有了本文作者提出的non local机制,作为一个block嵌入在深度CNN中,这是一种自注意力机制,符合人眼观察事物的本质。
优点:
(a)与递归和卷积运算的渐进的操作相比,非本局部运算直接通过计算任意两个位置之间的交互来获取长时记忆,可以不用管其间的距离;
(b)正如他们在实验中所显示的那样,非局部运算效率很高,即使只有几层(比如实验中的5层)也能达到最好的效果;
(c)最后,他们的非局部运算能够维持可变输入的大小,并且能很方便地与其他运算(比如实验中使用的卷积运算)相组合。
思考:针对图片来讲,这种注意力机制其实是增加上下文信息,与ASPP, dilatedd等有相似之处。还有如果feature map size大的话,每个像素点是跟全局关联,造成的内存消耗肯定非常大。

上面是non-local block ,下面是其代码实现,结合代码更容易理解。
def nonlocal_dot(net, depth, embed=True, softmax=False, maxpool=2, scope=None):
""" Implementation of the non-local block in its various forms.
See "Non-local Neural Networks" by
Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He
https://arxiv.org/pdf/1711.07971.pdf
Args:
- `net`: The symbolic input into the block, a (B,H,W,C) Tensor.
- `depth`: The number of channels in which to execute the non-local operation.
- `embed`: Whether or not use the "embedded version" as in Sec.3.2
- `softmax`: Whether or not to use the softmax operation which makes it
equivalent to soft-attention.
- `maxpool`: How large of a max-pooling (Sec.3.3) to use to help reduce
the computational burden. Default is 2, use `False` for none.
- `scope`: An optional scope for all created variables.
Returns:
The symbolic output of the non-local block operation.
Note:
The final BatchNorm's gamma is initialized to zero, so as to make this a
no-op (skip) at initialization, as described in Sec.4.1.
"""
with tf.variable_scope(scope, 'nonlocal', values=[net]) as sc:
with slim.arg_scope([slim.conv2d], normalizer_fn=None):
if embed:
a = conv2d_same(net, depth, 1, stride=1, scope='embA')
b = conv2d_same(net, depth, 1, stride=1, scope='embB')
else:
a, b = net, net
g_orig = g = conv2d_same(net, depth, 1, stride=1, scope='g')
if maxpool is not False and maxpool > 1:
b = slim.max_pool2d(b, [maxpool, maxpool], stride=maxpool, scope='pool')
g = slim.max_pool2d(g, [maxpool, maxpool], stride=maxpool, scope='pool')
# Flatten from (B,H,W,C) to (B,HW,C) or similar
a_flat = tf.reshape(a, [tf.shape(a)[0], -1, tf.shape(a)[-1]])
b_flat = tf.reshape(b, [tf.shape(b)[0], -1, tf.shape(b)[-1]])
g_flat = tf.reshape(g, [tf.shape(g)[0], -1, tf.shape(g)[-1]])
a_flat.set_shape([a.shape[0], a.shape[1] * a.shape[2] if None not in a.shape[1:3] else None, a.shape[-1]])
b_flat.set_shape([b.shape[0], b.shape[1] * b.shape[2] if None not in b.shape[1:3] else None, b.shape[-1]])
g_flat.set_shape([g.shape[0], g.shape[1] * g.shape[2] if None not in g.shape[1:3] else None, g.shape[-1]])
# Compute f(a, b) -> (B,HW,HW)
f = tf.matmul(a_flat, tf.transpose(b_flat, [0, 2, 1]))
if softmax:
f = tf.nn.softmax(f)
else:
f = f / tf.cast(tf.shape(f)[-1], tf.float32)
# Compute f * g ("self-attention") -> (B,HW,C)
fg = tf.matmul(f, g_flat)
# Expand and fix the static shapes TF lost track of.
fg = tf.reshape(fg, tf.shape(g_orig))
# fg.set_shape(g.shape) # NOTE: This actually appears unnecessary.
# Go back up to the original depth, add residually, zero-init.
#with slim.arg_scope([slim.conv2d],
# weights_initializer=tf.zeros_initializer()):
with slim.arg_scope([slim.batch_norm], param_initializers={'gamma': tf.zeros_initializer()}):
fg = conv2d_same(fg, net.shape[-1], 1, stride=1, scope='fgup')
net = net + fg
return slim.utils.collect_named_outputs(None, sc.name, net)3. CCNet( Criss-Cross Attention for Semantic Segmentation)
论文地址:https://arxiv.org/pdf/1811.11721.pdf
CCnet 是用于语义分割,基于non-local-net 提出的交叉纵横网络,见如下对比图:
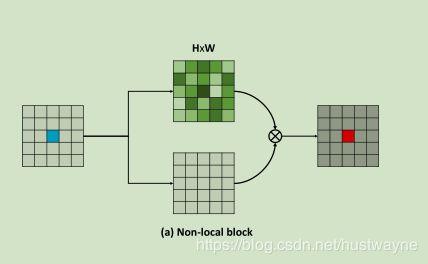
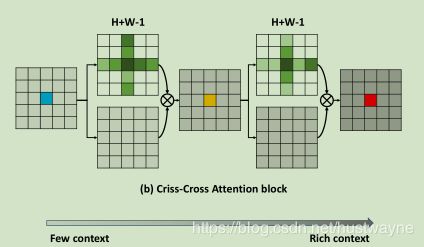
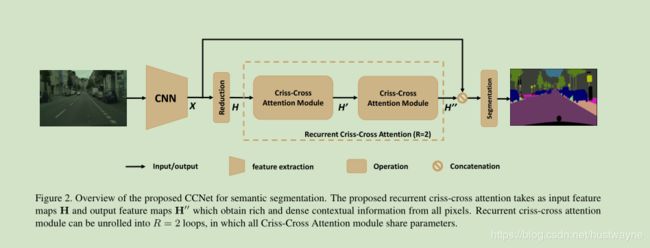
可以看出CC-Attention block 重复了两次,每次只关联当前像素点水平与竖直方向像素,经过复用,就可以从few context 过渡到 rich context。
优点:
(a)减少GPU 内存占用;
(b)针对非局部提取远程依赖减少了85%计算量
(c)start of the art
思考: 在cnn结构中,经常是加入一些blocks,以提升上下文信息,如pspnet, deeplab系列等语义分割网络通过金字塔池化,enoder-decoder等结构增大感受野,融合低层次信息,都有类似之处。同时,我们需要 high-resolution feature map(同时包含相当大的感受野和丰富的空间信息)去上采样得到预测结果,因为尽管最终的特征图( low resolution)包含丰富的语义信息,但精细的图像结构信息丢失了,引导了对象界限周围的不确定性预测。因此,在提出一些新的block时,必须考虑内存计算效率等问题。