由人脸图片重建出三维人脸网格
预备知识。
人脸的参数化模型
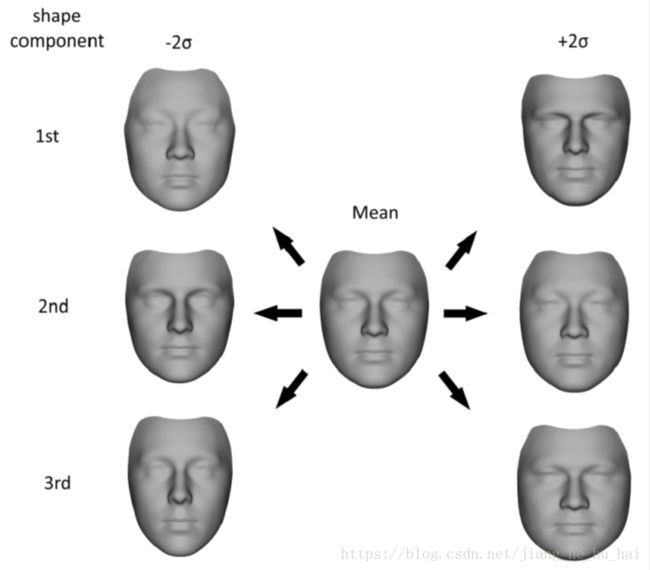
对数据库中的人脸,提取特征点,把每一张人脸的特征点转化成一个高维向量,计算所有向量的均值。用人脸向量减去均值向量,得到向量进行主成分分析,取特征值模长最大的几个方向作为形状主元。
同样的道理,利用PCA(主成分分析)对于同一个人脸的不同表情或者纹理也可以构建类似的模型。
人脸表情模型
表现人脸表情:混合模型

人脸纹理模型
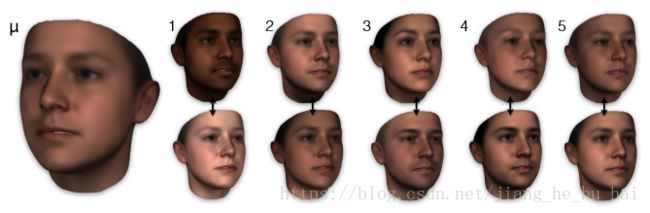
那么我们要表现不同人的不同表情和纹理,怎么办呢?一个简答的做法就是把他们都加起来:
这里
ET∙E∙=diag(⋯,[σ∙k]2,⋯) E ∙ T E ∙ = d i a g ( ⋯ , [ σ k ∙ ] 2 , ⋯ )

三维的旋转平移
整体旋转矩阵:
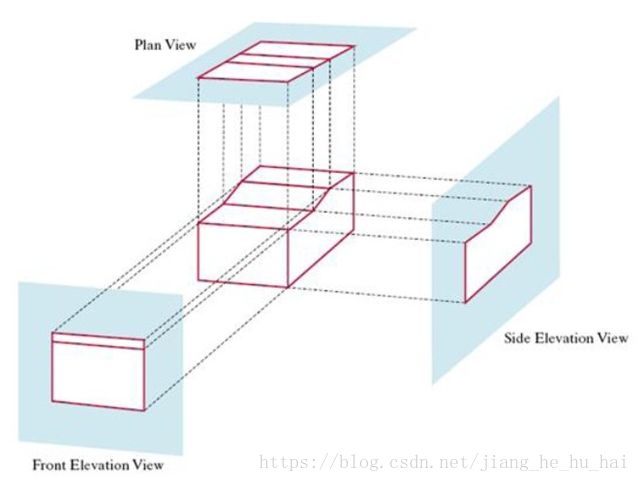
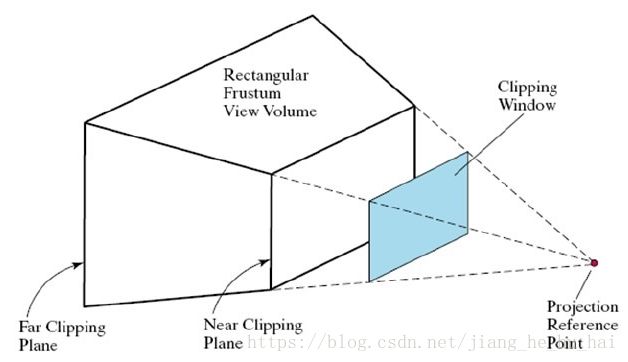
投影
假设投影变换将 (x,y,z)∈R3 ( x , y , z ) ∈ R 3 变换为 (u,v)∈R2 ( u , v ) ∈ R 2
平行投影: u=x,v=y u = x , v = y
透视投影:
球谐函数
在2001年,Basri和Jacobs证明了曲面上的像素值可以使用9维的球谐基函数进行线性表示,这种光照模型只需要估计球谐基函数前面的权值,不需要光源的方向,大大简化了光照的估计。点p处的像素值等于p处的反射率乘以球谐基函数的线性组合,用数学公式表示一下就是:
第一篇文章
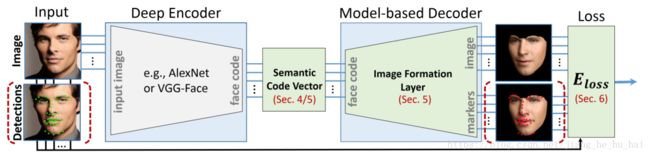
MoFA:Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
这篇文章将一张人脸照片通过深度学习的方法学习到各个参数从而重建出三维人脸模型。

算法框架
参考文献
[1] Tewari A, Zollhöfer M, Kim H, et al. Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction[C]//The IEEE International Conference on Computer Vision (ICCV). 2017, 2(3): 5.
[2] Tewari A, Zollhöfer M, Garrido P, et al. Self-supervised multi-level face model learning for monocular reconstruction at over 250 hz[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2549-2559.
致谢
7月16日中国科学技术大学某位周同学的论文汇报