flink学习笔记-如何利用waterMark解决乱序、延迟问题
watermark的作用
watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。
但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark
Watermarks(水位线)就是来处理out-of-order或者说late element的
- 参考google的DataFlow。
- 是event time处理进度的标志。
- 表示比watermark更早(更老)的事件都已经到达(没有比水位线更低的数据 )。
- 基于watermark来进行窗口触发计算的判断。
- 有序的数据流watermark
- 在某些情况下,基于Event Time的数据流是有续的(相对event time)。在有序流中,watermark就是一个简单的周期性标记。

- 在某些情况下,基于Event Time的数据流是有续的(相对event time)。在有序流中,watermark就是一个简单的周期性标记。
- 无序的数据流watermark
- 在更多场景下,基于Event Time的数据流是无续的(相对event time)。
在无序流中,watermark至关重要,她告诉operator比watermark更早(更老/时间戳更小)的事件已经到达, operator可以将内部事件时间提前到watermark的时间戳(可以触发window计算啦)

- 在更多场景下,基于Event Time的数据流是无续的(相对event time)。
- 并行流当中的watermark
- 通常情况下, watermark在source函数中生成,但是也可以在source后任何阶段,如果指定多次 watermark,后面指定的 watermarker会覆盖前面的值。 source的每个sub task独立生成水印。
- watermark通过operator时会推进operators处的当前event time,同时operators会为下游生成一个新的watermark。
- 多输入operator(union、 keyBy、 partition)的当前event time是其输入流event time的最小值
注意:多并行度的情况下,watermark对齐会取所有channel最小的watermark
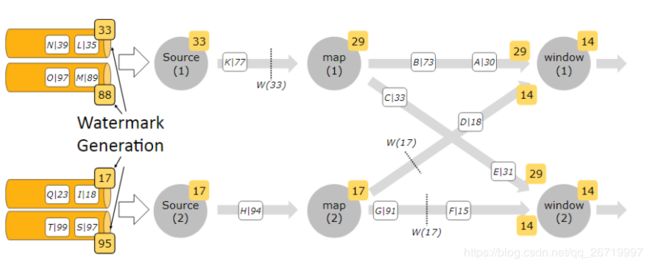
watermark如何生成
- 通常,在接收到source的数据后,应该立刻生成watermark;但是,也可以在source后,应用简单的map或者filter操作,然后再生成watermark。
- 生成watermark的方式主要有2大类:
- 1:With Periodic Watermarks
- 2:With Punctuated Watermarks
watermark处理顺序数据
- 需求:定义一个窗口为10s,通过数据的event time时间结合watermark实现延迟10s的数据也能够正确统计
- 代码实现
import java.text.SimpleDateFormat
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.{AssignerWithPeriodicWatermarks, AssignerWithPunctuatedWatermarks}
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable.ArrayBuffer
import scala.util.Sorting
object FlinkWaterMark2 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
//设置flink的数据处理时间为eventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val tupleStream: DataStream[(String, Long)] = env.socketTextStream("node01", 8000).map(x => {
val strings: Array[String] = x.split(" ")
(strings(0), strings(1).toLong)
})
//注册我们的水印
val waterMarkStream: DataStream[(String, Long)] = tupleStream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] {
var currentTimemillis: Long = 0L
var timeDiff: Long = 10000L
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
/* //获取当前数据的waterMark
override def getNext: Watermark = {
}*/
override def getCurrentWatermark: Watermark = {
val watermark = new Watermark(currentTimemillis - timeDiff)
watermark
}
//抽取数据的eventTime
override def extractTimestamp(element: (String, Long), l: Long): Long = {
val enventTime = element._2
currentTimemillis = Math.max(enventTime, currentTimemillis)
val id = Thread.currentThread().getId
println("currentThreadId:" + id + ",key:" + element._1 + ",eventtime:[" + element._2 + "|" + sdf.format(element._2) + "],currentMaxTimestamp:[" + currentTimemillis + "|" + sdf.format(currentTimemillis) + "],watermark:[" + this.getCurrentWatermark.getTimestamp + "|" + sdf.format(this.getCurrentWatermark.getTimestamp) + "]")
enventTime
}
})
waterMarkStream.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new MyWindowFunction2).print()
env.execute()
}
}
class MyWindowFunction2 extends WindowFunction[(String,Long),String,Tuple,TimeWindow]{
override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = {
val keyStr = key.toString
val arrBuf = ArrayBuffer[Long]()
val ite = input.iterator
while (ite.hasNext){
val tup2 = ite.next()
arrBuf.append(tup2._2)
}
val arr = arrBuf.toArray
Sorting.quickSort(arr) //对数据进行排序,按照eventTime进行排序
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
val result = "聚合数据的key为:"+keyStr + "," + "窗口当中数据的条数为:"+arr.length + "," + "窗口当中第一条数据为:"+sdf.format(arr.head) + "," +"窗口当中最后一条数据为:"+ sdf.format(arr.last)+ "," + "窗口起始时间为:"+sdf.format(window.getStart) + "," + "窗口结束时间为:"+sdf.format(window.getEnd) + "!!!!!看到这个结果,就证明窗口已经运行了"
out.collect(result)
}
}
- 测试程序
- 注意:如果需要触发flink的窗口调用,必须满足两个条件 1:waterMarkTime > eventTime,2:窗口内有数据
# 顺序计算:
# 触发数据计算的条件依据为两个
# 第一个waterMark时间大于数据的eventTime时间,第二个窗口之内有数据
# 我们这里的waterMark直接使用eventTime的最大值减去10秒钟
0001 1585015882000 数据eventTime为:2020-03-24 10:11:22 数据waterMark为 2020-03-24 10:11:12
0001 1585015885000 数据eventTime为:2020-03-24 10:11:25 数据waterMark为 2020-03-24 10:11:15
0001 1585015888000 数据eventTime为:2020-03-24 10:11:28 数据waterMark为 2020-03-24 10:11:18
0001 1585015890000 数据eventTime为:2020-03-24 10:11:30 数据waterMark为 2020-03-24 10:11:20
0001 1585015891000 数据eventTime为:2020-03-24 10:11:31 数据waterMark为 2020-03-24 10:11:21
0001 1585015895000 数据eventTime为:2020-03-24 10:11:35 数据waterMark为 2020-03-24 10:11:25
0001 1585015898000 数据eventTime为:2020-03-24 10:11:38 数据waterMark为 2020-03-24 10:11:28
0001 1585015900000 数据eventTime为:2020-03-24 10:11:40 数据waterMark为 2020-03-24 10:11:30 触发第一条到第三条数据计算,数据包前不包后,不会计算2020-03-24 10:11:30 这条数据
0001 1585015911000 数据eventTime为:2020-03-24 10:11:51 数据waterMark为 2020-03-24 10:11:41 触发2020-03-24 10:11:20到2020-03-24 10:11:28时间段的额数据计算,数据包前不包后,不会触发2020-03-24 10:11:30这条数据的计算
watermark处理乱序数据
#乱序数据
0001 1585015948000 数据eventTime为:2020-03-24 10:12:28 数据waterMark为 2020-03-24 10:12:18
0001 1585015945000 数据eventTime为:2020-03-24 10:12:25 数据waterMark为 2020-03-24 10:12:18
0001 1585015947000 数据eventTime为:2020-03-24 10:12:27 数据waterMark为 2020-03-24 10:12:18
0001 1585015950000 数据eventTime为:2020-03-24 10:12:30 数据waterMark为 2020-03-24 10:12:20
0001 1585015960000 数据eventTime为:2020-03-24 10:12:40 数据waterMark为 2020-03-24 10:12:30 触发计算 waterMark > eventTime 并且窗口内有数据,触发 2020-03-24 10:12:28到2020-03-24 10:12:27 这三条数据的计算,数据包前不包后,不会触发2020-03-24 10:12:30 这条数据的计算
0001 1585015949000 数据eventTime为:2020-03-24 10:12:29 数据waterMark为 2020-03-24 10:12:30 迟到太多的数据,flink直接丢弃,可以设置flink将这些迟到太多的数据保存起来,便于排查问题
比watermark更晚的数据如何解决
- 1:直接丢弃
- 我们输入一个乱序很多的(其实只要 Event Time < watermark 时间)数据来测试下
late element 0001 1585015948000 数据eventTime为:2020-03-24 10:12:28 数据直接丢弃 0001 1585015945000 数据eventTime为:2020-03-24 10:12:25 数据直接丢弃- 注意:此时并没有触发 window。因为输入的数据所在的窗口已经执行过了,flink 默认对这 些迟到的数据的处理方案就是丢弃
- 2:allowedLateness 指定允许数据延迟的时间
- 在某些情况下,我们希望对迟到的数据再提供一个宽容的时间。
Flink 提供了 allowedLateness 方法可以实现对迟到的数据设置一个延迟时间,在指定延迟时间内到达的数据还是可以触发 window 执行的。 - 修改代码
waterMarkStream .keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(10))) .allowedLateness(Time.seconds(2))//允许数据迟到2S //function: (K, W, Iterable[T], Collector[R]) => Unit .apply(new MyWindowFunction).print()- 验证数据迟到性
# 更改代码之后重启我们的程序,然后从新输入之前的数据 0001 1585015882000 0001 1585015885000 0001 1585015888000 0001 1585015890000 0001 1585015891000 0001 1585015895000 0001 1585015898000 0001 1585015900000 0001 1585015911000 0001 1585015948000 0001 1585015945000 0001 1585015947000 0001 1585015950000 0001 1585015960000 0001 1585015949000 验证数据的延迟性:定义数据仅仅延迟2S的数据重新接收,重新计算 0001 1585015948000 数据eventTime为:2020-03-24 10:12:28 触发数据计算 数据waterMark为 2020-03-24 10:12:30 0001 1585015945000 数据eventTime为:2020-03-24 10:12:25 触发数据计算 数据waterMark为 2020-03-24 10:12:30 0001 1585015958000 数据eventTime为:2020-03-24 10:12:38 不会触发数据计算 数据waterMark为 2020-03-24 10:12:30 waterMarkTime < eventTime,所以不会触发计算 将数据的waterMark调整为41秒就可以触发上面这条数据的计算了 0001 1585015971000 数据eventTime为:2020-03-24 10:12:51 数据waterMark为 2020-03-24 10:12:41 又会继续触发0001 1585015958000 这条数据的计算了 - 在某些情况下,我们希望对迟到的数据再提供一个宽容的时间。
- sideOutputLateData 收集迟到的数据
- 通过 sideOutputLateData 可以把迟到的数据统一收集,统一存储,方便后期排查问题
import java.text.SimpleDateFormat
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.datastream.DataStreamSink
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable.ArrayBuffer
import scala.util.Sorting
object FlinkWaterMark {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
//设置time类型为eventtime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//暂时定义并行度为1
env.setParallelism(1)
val text = env.socketTextStream("node01",9000)
val inputMap: DataStream[(String, Long)] = text.map(line => {
val arr = line.split(" ")
(arr(0), arr(1).toLong)
})
//给我们的数据注册waterMark
val waterMarkStream: DataStream[(String, Long)] = inputMap
.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[(String, Long)] {
var currentMaxTimestamp = 0L
//watermark基于eventTime向后推迟10秒钟,允许消息最大乱序时间为10s
val waterMarkDiff: Long = 10000L
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
//获取下一个水印
override def checkAndGetNextWatermark(t: (String, Long), l: Long): Watermark = {
val watermark = new Watermark(currentMaxTimestamp - waterMarkDiff)
watermark
}
//抽取当前数据的时间作为eventTime
override def extractTimestamp(element: (String, Long), l: Long): Long = {
val eventTime = element._2
currentMaxTimestamp = Math.max(eventTime, currentMaxTimestamp)
val id = Thread.currentThread().getId
println("currentThreadId:"+id+",key:"+element._1+",eventtime:["+element._2+"|"+sdf.format(element._2)+"],currentMaxTimestamp:["+currentMaxTimestamp+"|"+ sdf.format(currentMaxTimestamp)+"],watermark:["+this.checkAndGetNextWatermark(element,l).getTimestamp+"|"+sdf.format(this.checkAndGetNextWatermark(element,l).getTimestamp)+"]")
eventTime
}
})
val outputTag: OutputTag[(String, Long)] = new OutputTag[(String,Long)]("late_data")
val outputWindow: DataStream[String] = waterMarkStream
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
// .allowedLateness(Time.seconds(2))//允许数据迟到2S
.sideOutputLateData(outputTag)
//function: (K, W, Iterable[T], Collector[R]) => Unit
.apply(new MyWindowFunction)
val sideOuptut: DataStream[(String, Long)] = outputWindow.getSideOutput(outputTag)
sideOuptut.print()
outputWindow.print()
//执行程序
env.execute()
}
}
class MyWindowFunction extends WindowFunction[(String,Long),String,Tuple,TimeWindow]{
override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = {
val keyStr = key.toString
val arrBuf = ArrayBuffer[Long]()
val ite = input.iterator
while (ite.hasNext){
val tup2 = ite.next()
arrBuf.append(tup2._2)
}
val arr = arrBuf.toArray
Sorting.quickSort(arr)
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
val result = keyStr + "," + arr.length + "," + sdf.format(arr.head) + "," + sdf.format(arr.last)+ "," + sdf.format(window.getStart) + "," + sdf.format(window.getEnd)
out.collect(result)
}
}
```powershell
0001 1585015882000
0001 1585015885000
0001 1585015888000
0001 1585015890000
0001 1585015891000
0001 1585015895000
0001 1585015898000
0001 1585015900000
0001 1585015911000
0001 1585015948000
0001 1585015945000
0001 1585015947000
0001 1585015950000
0001 1585015960000
0001 1585015949000
输入两条迟到的数据,会被收集起来
0001 1585015948000
0001 1585015945000
```
多并行度的watermark机制
- 上面的例子中并行度设置的时1:**env.setParallelism(1);**如果这里不设置的话,代码在运行的时候会默认读取本机 CPU 数量设置并行度。 可以自己整理数据测试,这里就不测试了直接说结论。
- 会发现 window 没有被触发,因为此时,这 7 条数据都是被不同的线程处理的。每个线程都有一个 watermark。因为在多并行度的情况下,watermark 对齐会取所有 channel 最小的 watermark 但是我们现在默认有 8 个并行度,这 7 条数据都被不同的线程所处理,到现在还没获取到最 小的 watermark,所以 window 无法被触发执行。
