【2020年数据分析岗面试题】不断更新...(含自己的理解、思考和简答)
【更新日志】
| 日期 | 内容 |
|---|---|
| 2020.03.20 | 扑克牌54张,平均分成2份,求这2份都有2张A的概率;男生点击率增加,女生点击率增加,总体为何减少?;参数估计;假设检验;置信度、置信区间;协方差与相关系数的区别和联系;中心极限定理; p值的含义;时间序列分析;怎么向小孩子解释正态分布;下面对于“预测变量间可能存在较严重的多重共线性”的论述中错误的是?;PCA为什么要中心化?PCA的主成分是什么?;极大似然估计 |
| 2020.03.21 | 事务是什么?事务的四大特性?事务的使用;并发事务带来的问题;事务的隔离级别;常用的表的存储引擎;MySQL中索引的优点和缺点和使用原则;mysql联合索引;为什么使用数据索引能提高效率;B+树索引和哈希索引的区别;B树和B+树的区别;为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?;Mysql中的myisam与innodb的区别;一张表里面有ID自增主键,当insert了17条记录之后,删除了第15,16,17条记录,再把mysql重启,再insert一条记录,这条记录的ID是18还是15 ?;mysql为什么用自增列作为主键;MySQL分区;行级锁定的优点;行级锁定的缺点;mysql优化;key和index的区别 |
| 2020.03.22 | 归一化的定义、公式、优缺点;标准化的定义、公式、与归一化对比;什么是交叉验证;为什么需要交叉验证;什么是网格搜索(Grid Search);线性回归应用场景、定义、公式;线性回归经常使用的两种优化算法;梯度下降和正规方程的对比;回归的选择;梯度下降的种类;回归性能评估;欠拟合和过拟合定义、解决办法;正则化的定义和类别;12.正则化线性模型;13.sklearn模型的保存和加载API;逻辑回归的应用场景;逻辑回归的原理;“那像你提到有用到Xgboost,你有测试过Xgboost和GBDT的效果区别吗?你认为在你的项目上是什么导致原因导致了这个区别”;“xgboost对缺失值是怎么处理的?”;“那你知道在什么情况下应该使用Onehot呢?”;“你能讲一下Xgboost和GBDT的区别吗?;LGB比xgboost快且精度高的原因;分类的评估方法 |
| 2020.04.02 | 索引失效的情况;脏读是什么;什么情况下会脏读;事务的隔离级别;sql语句的优化;sql的优化;python的迭代器生成器;二分查找是什么;快速排序是什么;怎么样处理垃圾邮件;怎么样实现论文的查重系统;手写sigmod激活函数;什么是主从复制;mysql怎么实现负载均衡;knn算法解释;推荐系统需要采集用户的哪些特征 |
| 2020.04.09 | 更新阿里数据分析面试题 |
文章目录
- ==统计理论知识==
- ==1. 扑克牌54张,平均分成2份,求这2份都有2张A的概率。==
- ==2.男生点击率增加,女生点击率增加,总体为何减少?==
- ==3. 参数估计==
- ==4. 假设检验==
- ==5. 置信度、置信区间==
- ==6. 协方差与相关系数的区别和联系。==
- ==7. 中心极限定理==
- ==8. p值的含义。==
- ==9.时间序列分析==
- ==10.怎么向小孩子解释正态分布==
- ==11. 下面对于“预测变量间可能存在较严重的多重共线性”的论述中错误的是?==
- ==12. PCA为什么要中心化?PCA的主成分是什么?==
- ==13. 极大似然估计==
- ==业务思维逻辑==
- ==数据库==
- ==11.事务是什么?事务的四大特性?事务的使用==
- ==12.并发事务带来的问题==
- ==13.事务的隔离级别==
- ==12.常用的表的存储引擎==
- ==13.MySQL中索引的优点和缺点和使用原则==
- ==14.mysql联合索引==
- ==15.为什么使用数据索引能提高效率==
- ==16.B+树索引和哈希索引的区别==
- ==17.B树和B+树的区别==
- ==18.为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?==
- ==19.Mysql中的myisam与innodb的区别==
- ==20.一张表里面有ID自增主键,当insert了17条记录之后,删除了第15,16,17条记录,再把mysql重启,再insert一条记录,这条记录的ID是18还是15 ?==
- ==21.mysql为什么用自增列作为主键==
- ==22.MySQL分区==
- ==23.行级锁定的优点==
- ==24.行级锁定的缺点==
- ==25.mysql优化==
- ==25.key和index的区别==
- ==26.delete、drop、truncate区别==
- ==27.与Oracle相比,Mysql有什么优势?==
- ==28.如何区分FLOAT和DOUBLE?==
- ==29.区分CHAR_LENGTH和LENGTH?==
- ==30.mysql 的主从复制==
- ==浅拷贝和深拷贝==
- ==31.数据库的第一范式到第四范式==
- ==机器学习==
- ==1.归一化的定义、公式、优缺点==
- ==2.标准化的定义、公式、与归一化对比==
- ==3.什么是交叉验证==
- ==3.为什么需要交叉验证==
- ==4.什么是网格搜索(Grid Search)==
- ==5.线性回归应用场景、定义、公式==
- ==6.线性回归经常使用的两种优化算法==
- ==7.梯度下降和正规方程的对比==
- ==7.回归的选择==
- ==8.梯度下降的种类==
- ==9.回归性能评估==
- ==10.欠拟合和过拟合定义、解决办法==
- ==11.正则化的定义和类别==
- ==12.正则化线性模型==
- ==13.sklearn模型的保存和加载API==
- ==14.逻辑回归的应用场景==
- ==15.逻辑回归的原理==
- ==“那像你提到有用到Xgboost,你有测试过Xgboost和GBDT的效果区别吗?你认为在你的项目上是什么导致原因导致了这个区别”==
- ==“xgboost对缺失值是怎么处理的?”==
- ==“那你知道在什么情况下应该使用Onehot呢?”==
- ==“你能讲一下Xgboost和GBDT的区别吗?”==
- ==LGB比xgboost快且精度高的原因==
- ==分类的评估方法==
- ==请说明随机森林较一般决策树稳定的几点原因==
- ==数据清理中,处理缺失值的方法是?==
- ==余弦距离与欧式距离求相似度的差别。==
- ==什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。==
- ==SVM的优缺点==
- ==深度学习==
- ==爬虫==
- ==数据分析项目==
- ==人事==
- ==python基础==
- ==闭包==
- ==爬虫==
- ==scrapy==
- 【一次模拟面试】
- 【索引失效的情况】
- 【sql语句的优化】
- 【阿里数据分析面试题】
- 【bagging和boosting的区别】
- 【python编码规范】
- 【聚类分析有哪几种,区别】
- 【kmeans的优缺点】
- 【机器学习模型评估指标】
- 【阿里数据库】
- 问题一:mysql 锁机制 ?
- 问题二:排它锁 & 共享锁?
- 共享锁与排它锁区别
- 问题三:Mysql 索引是怎么实现的?
- 问题一:缓存可能会遇到的问题?
- 【SQL面试题】
- 【drop delete trucate 区别】
- 【in 和 exists的区别】
- 【20200409模拟面试题】
- 【`==`和is的区别】
- 【python基础题】
- 【解释深拷贝和浅拷贝】
- 【list、str、字典、元组这些东西是迭代器吗】
- 【创建生成器的方法】
- 【线程进程协程的理解】
- 【io密集型任务和cpu密集型任务,以及应该如何给他们分配进程线程】
- 【如何理解ndarray数据结构】
统计理论知识
1. 扑克牌54张,平均分成2份,求这2份都有2张A的概率。
M表示两个牌堆各有2个A的情况:M=4(25!25!)
N表示两个牌堆完全随机的情况:N=27!27!
所以概率为:M/N = 926/53*17
2.男生点击率增加,女生点击率增加,总体为何减少?
因为男女的点击率可能有较大差异,同时低点击率群体的占比增大。
如原来男性20人,点击1人;女性100人,点击99人,总点击率100/120。
现在男性100人,点击6人;女性20人,点击20人,总点击率26/120。
即那个段子“A系中智商最低的人去读B,同时提高了A系和B系的平均智商。”
3. 参数估计
用样本统计量去估计总体的参数。
可参考https://vicky.blog.csdn.net/article/details/105131308
4. 假设检验
参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,但推断的角度不同。
参数估计讨论的是用样本估计总体参数的方法,总体参数μ在估计前是未知的。
而在假设检验中,则是先对μ的值提出一个假设,然后利用样本信息去检验这个假设是否成立。
可参考:https://vicky.blog.csdn.net/article/details/105131409
5. 置信度、置信区间
置信区间是我们所计算出的变量存在的范围,置信水平就是我们对于这个数值存在于我们计算出的这个范围的可信程度。
举例来讲,有95%的把握,真正的数值在我们所计算的范围里。
在这里,95%是置信水平,而计算出的范围,就是置信区间。
如果置信度为95%, 则抽取100个样本来估计总体的均值,由100个样本所构造的100个区间中,约有95个区间包含总体均值。
可参考http://www.360doc.com/content/18/0317/16/15033922_737796626.shtml
6. 协方差与相关系数的区别和联系。
协方差:
协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
相关系数:
研究变量之间线性相关程度的量,取值范围是[-1,1]。相关系数也可以看成协方差:一种剔除了两个变量量纲影响、标准化后的特殊协方差。
可参考http://blog.sina.com.cn/s/blog_6aa3b1010102xkp5.html
7. 中心极限定理
中心极限定理定义:
(1)任何一个样本的平均值将会约等于其所在总体的平均值。
(2)不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的平均值周围,并且呈正态分布。
中心极限定理作用:
(1)在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体。
(2)根据总体的平均值和标准差,判断某个样本是否属于总体。
可参考https://www.zhihu.com/question/22913867/answer/250046834
8. p值的含义。
基本原理只有3个:
- 一个命题只能证伪,不能证明为真
- 在一次观测中,小概率事件不可能发生
- 在一次观测中,如果小概率事件发生了,那就是假设命题为假
证明逻辑就是:我要证明命题为真->证明该命题的否命题为假->在否命题的假设下,观察到小概率事件发生了->否命题被推翻->原命题为真->搞定。
结合这个例子来看:证明A是合格的投手-》证明“A不是合格投手”的命题为假-》观察到一个事件(比如A连续10次投中10环),而这个事件在“A不是合格投手”的假设下,概率为p,小于0.05->小概率事件发生,否命题被推翻。
可以看到p越小-》这个事件越是小概率事件-》否命题越可能被推翻-》原命题越可信
9.时间序列分析
是同一现象在不同时间上的相继观察值排列而成的序列。

10.怎么向小孩子解释正态分布
(随口追问了一句小孩子的智力水平,面试官说七八岁,能数数)
拿出小朋友班级的成绩表,每隔2分统计一下人数(因为小学一年级大家成绩很接近),画出钟形。然后说这就是正态分布,大多数的人都集中在中间,只有少数特别好和不够好
拿出隔壁班的成绩表,让小朋友自己画画看,发现也是这样的现象
然后拿出班级的身高表,发现也是这个样子的
大部分人之间是没有太大差别的,只有少数人特别好和不够好,这是生活里普遍看到的现象,这就是正态分布
11. 下面对于“预测变量间可能存在较严重的多重共线性”的论述中错误的是?
A. 回归系数的符号与专家经验知识不符(对)
B. 方差膨胀因子(VIF)<5(错,大于10认为有严重多重共线性)
C. 其中两个预测变量的相关系数>=0.85(对)
D. 变量重要性与专家经验严重违背(对)
12. PCA为什么要中心化?PCA的主成分是什么?
因为要算协方差。单纯的线性变换只是产生了倍数缩放,无法消除量纲对协方差的影响,而协方差是为了让投影后方差最大。
在统计学中,主成分分析(PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。
主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。
主成分分析的原理是设法将原来变量重新组合成一组新的相互无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上处理降维的一种方法。
主成分分析是设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标。最经典的做法就是用F1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Va(rF1)越大,表示F1包含的信息越多。因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来信息,F1已有的信息就不需要再出现再F2中,用数学语言表达就是要求Cov(F1,F2)=0,则称F2为第二主成分,依此类推可以构造出第三、第四,……,第P个主成分。
13. 极大似然估计
利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
参考https://blog.csdn.net/zengxiantao1994/article/details/72787849
业务思维逻辑
- 不用任何公开参考资料,估算今年新生儿出生数量。
采用两层模型(人群画像x人群转化):新生儿出生数=Σ各年龄层育龄女性数量*各年龄层生育比率
数据库
1.select FROM_UNIXTIME(UNIX_TIMESTAMP(),‘Y D M h:i:s x’);
少百分号%
2.mysql分区语句,排错!
3.mysql其他语句排错!
4.mysql rank,dense_rank,row_number 排序有什么区别!
5.mysql truncate 与 delete 的区别!
6.mysql 优化
7.hadoop中hive 和 hbase有什么区别?
8.mysql 死锁的原理,怎么解决
9.给用户更改所有者,所组!
10.谈谈mysql(mysql的高级功能)
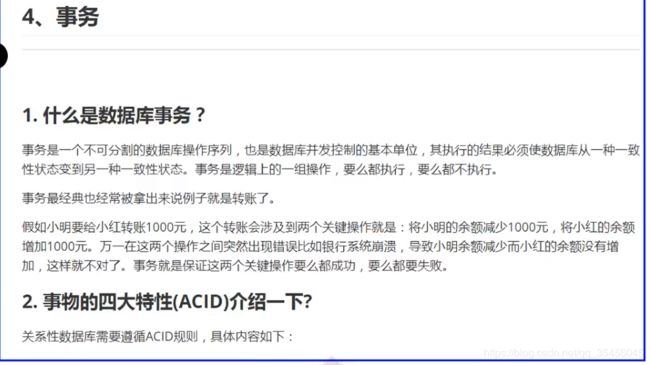
11.事务是什么?事务的四大特性?事务的使用
(1)事务就是用户定义的一系列执行SQL语句的操作, 这些操作要么完全地执行,要么完全地都不执行, 它是一个不可分割的工作执行单元。
(2)事务的四大特性ACID原子性、一致性、隔离性、持久性
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
原子性:
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性
一致性:
数据库总是从一个一致性的状态转换到另一个一致性的状态。(在前面的例子中,一致性确保了,即使在转账过程中系统崩溃,支票账户中也不会损失200美元,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中。)
隔离性:
通常来说,一个事务所做的修改操作在提交事务之前,对于其他事务来说是不可见的。(在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外的一个账户汇总程序开始运行,则其看到支票帐户的余额并没有被减去200美元。)
持久性:
一旦事务提交,则其所做的修改会永久保存到数据库。
**说明:**事务能够保证数据的完整性和一致性,让用户的操作更加安全。
**注意:**在使用事务之前,先要确保表的存储引擎是 InnoDB 类型, 只有这个类型才可以使用事务,MySQL数据库中表的存储引擎默认是 InnoDB 类型。
(3)事务的使用
开启事务:
begin;
或
start transaction;
set autocommit = 0;
insert into students(name) values('刘三峰');
-- 需要执行手动提交,数据才会真正添加到表中, 验证的话需要重新打开一个连接窗口查看表的数据信息,因为是临时关闭自动提交模式
commit
-- 重新打开一个终端窗口,连接MySQL数据库服务端
mysql -uroot -p
-- 然后查询数据,如果上个窗口执行了commit,这个窗口才能看到数据
select * from students;
回滚事务使用 rollback;
pymysql中:
pymysql 里面的 conn.commit() 操作就是提交事务
pymysql 里面的 conn.rollback() 操作就是回滚事务
12.并发事务带来的问题
-
脏读:dirty read
一个事务修改来了数据未提交,另一个数据读取了未提交的数据。 -
丢失修改:lost to modify
两个事务都修改了数据之后,第一个数据修改就会丢失。如数据A=10,事务1:A=A-1;
事务2:A=A-1,最后结果发现为19;
-
不可重复读:Unrepeatable Read
A事务在多次修改数据之间,B事务读取了数据,但是B在A事务执行之间读取的时候,可能会发现读取同一个数据的时候两次读到的不一样; -
幻读:Phantom Read
幻读与不可重复读相同,但是是一个事务多次插入或者删除数据,另一个事务读取的时候会发现多了或者少了数据。
13.事务的隔离级别
-
Read-Uncommitted(读未提交)
最低的隔离级别,允许读取尚未提交的事务,会导致脏读、幻读、不可重复读。 -
Read-Committed(读已提交)
允许并发事务读取已经提交的数据,可以防止脏读,单有可能幻读、不可重复读。 -
Repeatable-Read(可重复读)
mysql的默认隔离级别,对同一字段的多次读取都是相同的,除非数据是被本身事务修改。可以防止脏读与不可重复读,但有可能会有幻读。 -
Serializable(可串行化)
最高的隔离级别,完全按照ACID,所有事务依次执行。

12.常用的表的存储引擎
- 常用的表的存储引擎是 InnoDB 和 MyISAM
- InnoDB 是支持事务的
- MyISAM 不支持事务,优势是访问速度快,对事务没有要求或者以select、insert为主的都可以使用该存储引擎来创建表
13.MySQL中索引的优点和缺点和使用原则
(1)优点
索引的优点是加快数据的查询速度
验证索引性能的操作:
-- 开启运行时间监测:
set profiling=1;
-- 查找第1万条数据ha-99999
select * from test_index where title='ha-99999';
-- 查看执行的时间:
show profiles;
-- 给title字段创建索引:
alter table test_index add index (title);
-- 再次执行查询语句
select * from test_index where title='ha-99999';
-- 再次查看执行的时间
show profiles;
(2)缺点
索引的缺点是创建索引会耗费时间和占用磁盘空间,并且随着数据量的增加所耗费的时间也会增加
(3)使用原则
1.通过优缺点对比,并不是索引越多越好,合理使用
2.常更新的表:避免很多索引
经常用于查询的字段:创建索引
3.数据量少:最好不使用索引,不会产生优化效果
4.同一字段相同值比较多:不要建立索引,比如性别,不同值多的可以建立索引
14.mysql联合索引
-
联合索引是两个或更多个列上的索引。对于联合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a 、 a,b 、 a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
-
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
15.为什么使用数据索引能提高效率
- 数据索引的存储是有序的
- 在有序的情况下,通过索引查询一个数据是无需遍历索引记录的
- 极端情况下,数据索引的查询效率为二分法查询效率,趋近于 log2(N)
16.B+树索引和哈希索引的区别
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且叶子节点的指针相互链接,是有序的
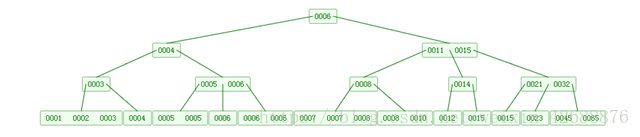
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从跟节点到叶子节点逐级查找,只需要 一次哈希算法即可,是无序的

哈希索引的优势:
等值查询。哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。)
哈希索引不适用的场景:
1.不支持范围查询
2.不支持索引完成排序
3.不支持联合索引的最左前缀匹配规则
17.B树和B+树的区别
1、B树,每个节点都存储key和data,所有的节点组成这可树,并且叶子节点指针为null,叶子节点不包含任何关键字信息
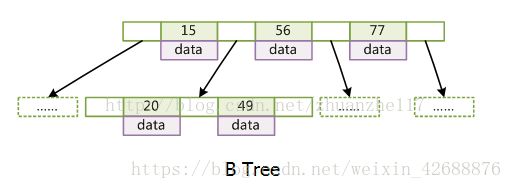
2、B+树,所有的叶子节点中包含全部关键字的信息,及指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小自小到大的顺序链接,所有的非终端节点可以看成是索引部分,节点中仅含有其子树根节点中最大(或最小)关键字

18.为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?
-
B+的磁盘读写代价更低 。B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
-
B+tree的查询效率更加稳定。 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
19.Mysql中的myisam与innodb的区别
1、InooDB支持事务,而MyISAM不支持事务
2、InnoDB支持行级锁,而MyISAM支持表级锁
3、InnoDB支持MVCC,而MyISAM不支持
4、InnoDB支持外键,而MyISAM不支持
5、InnoDB不支持全文索引,而MyISAM支持
20.一张表里面有ID自增主键,当insert了17条记录之后,删除了第15,16,17条记录,再把mysql重启,再insert一条记录,这条记录的ID是18还是15 ?
(1 )如果表的类型是MyISAM ,那么是18。
因为MyISAM表会把自增主键的最大ID记录到数据文件里,重启MySQL自增主键的最大I也不会丢失。
(2)如果表的类型是InnoDB ,那么是15。
InnoDB表只是把自增主键的最大ID记录到内存中,所以重启数据库或者是对表进行OPTIMIZE操作,都会导致最大ID丢失。
21.mysql为什么用自增列作为主键
-
如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
-
数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
-
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
-
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
22.MySQL分区
什么是表分区
表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分。从逻辑上看,只有一张表,但是底层却是由多个物理分区组成。
表分区与分表的区别
分表:指的是通过一定规则,将一张表分解成多张不同的表。比如将用户订单记录根据时间成多个表。
分表与分区的区别在于:分区从逻辑上来讲只有一张表,而分表则是将一张表分解成多张表。
表分区有什么好处?
(1)分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。和单个磁盘或者文件系统相比,可以存储更多数据
(2)优化查询。在where语句中包含分区条件时,可以只扫描一个或多个分区表来提高查询效率;涉及sum和count语句时,也可以在多个分区上并行处理,最后汇总结果。
(3)分区表更容易维护。例如:想批量删除大量数据可以清除整个分区。
(4)可与使用分区表来避免某些特殊的瓶颈,例如InnoDB的单个索引的互斥访问,ext3问价你系统的inode锁竞争等。
分区表的限制因素
1、一个表最多只能有1024个分区
2、MySQL5.1中,分区表达式必须是整数,或者返回整数的表达式。在MySQL5.5中提供了非整数表达式分区的支持。
3、如果分区字段中有主键或者唯一索引的列,那么多有主键列和唯一索引列都必须包含进来。即:分区字段要么不包含主键或者索引列,要么包含全部主键和索引列。
4、分区表中无法使用外键约束
5、MySQL的分区适用于一个表的所有数据和索引,不能只对表数据分区而不对索引分区,也不能只对索引分区而不对表分区,也不能只对表的一部分数据分区。
如何判断当前Mysql是否支持分区?
命令:show variables like ‘%partition%’
Mysql支持的分区类型有哪些?
1、RANGE分区:这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区
2、List分区:这种模式允许系统通过预定义的列表的值来对数据进行分割。按照list中的值分区,与RANGE的区别是,range分区的区间范围值是连续的
3、HASH分区:这种模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表
4、KEY分区:上面Hash模式的一种延伸,这里的Hash Key是Mysql系统产生的
23.行级锁定的优点
1.当在许多线程中访问不同的行时只存在少量锁定冲突
2.回滚时只有少量的更改
3.可以长时间锁定单一的行
24.行级锁定的缺点
1.比页级锁定和表级锁定占用更多的内存
2.当在表的大部分使用的时候 ,比页级或表级的速度慢,因为你必须获得更多的锁
3.进行GROUP BY操作或者必须经常扫描整个表,比其它锁定明显慢很多
4.用高级别锁定,通过支持不同的类型锁定,你也可以很容易地调节应用程序,因为其锁成本小于行级锁定
25.mysql优化
(1)设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。
(2)选择合适的表字段数据类型和存储引擎,适当的添加索引,为搜索字段添加索引。
(3)mysql库主从读写分离。
(4)找规律分表,减少单表中的数据量提高查询速度。
(5)添加缓存机制,比如memcached,apc等。
(6)不经常改动的页面,生成静态页面。
(7)选择正确的存储引擎,以 MySQL为例,包括有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。但是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
(8)书写高效率的SQL。比如 **SELECT *** FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE.固定长度的表会更快;尽可能的使用 NOT NULL, NULL其实需要额外的空间;使用 ENUM 而不是 VARCHAR,ENUM 类型是非常快和紧凑的;优化字段的数据类型,记住一个原则,越小的列会越快。如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。当然,你也需要留够足够的扩展空间。
25.key和index的区别
1、key是数据库的物理结构,它包含两层意义和作用,一是约束(偏重于约束和规范数据库的结构完整性),二是索引(辅助查询用的)。包括primary key,unique key,foregin key等
2、index是数据库的物理结构,它只是辅助查询的,它创建时会在另外的表空间(mysql中的innodb表空间)以一个类似目录的结构存储。索引要分类的话,分为前缀索引、全文本索引等
26.delete、drop、truncate区别
truncate 和 delete只删除数据,不删除表结构 ,drop删除表结构,并且释放所占的空间。
删除数据的速度,drop> truncate > delete
delete属于DML语言(数据操作语句),需要事务管理,commit之后才能生效。drop和truncate属于DDL语言(数据定义语言),操作立刻生效,不可回滚。
使用场合:
当你不再需要该表时, 用 drop;
当你仍要保留该表,但要删除所有记录时, 用 truncate;
当你要删除部分记录时(always with a where clause), 用 delete.
注意: 对于有主外键关系的表,不能使用truncate而应该使用不带where子句的delete语句,由于truncate不记录在日志中,不能够激活触发器
27.与Oracle相比,Mysql有什么优势?
1.mysql开源、随时可用、无需付费
2.mysql便携式的
3.带有命令提示符的GUI
4.使用mysql查询浏览器支持管理
28.如何区分FLOAT和DOUBLE?
float:精度为8,4个字节
double:精度为16,8个字节
29.区分CHAR_LENGTH和LENGTH?
CHAR_LENGTH:字符数
LENGTH:字节数
Latin字符的这两个数据是相同的,但是对于Unicode和其他编码,它们是不同的。
30.mysql 的主从复制
MySQL复制
保证主服务器(Master)和从服务器(Slave)的数据是一致性的,向Master插入数据后,Slave会自动从Master把修改的数据同步过来(有一定的延迟),通过这种方式来保证数据的一致性,就是Mysql复制
延时性:延时表现为 延迟时间=从库执行SQL完成的时刻-主库开始执行SQL时间;
Mysql 主从复制的好处
1、做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。
2、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
3、读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
主从配置需要注意的点
(1)主从服务器操作系统版本和位数一致;
(2) Master和Slave数据库的版本要一致;
(3) Master和Slave数据库中的数据要一致;
(4) Master开启二进制日志,Master和Slave的server_id在局域网内必须唯一;
主从复制的原理【重要!!!】
1.数据库有个bin-log二进制文件,记录了所有sql语句。
2.我们的目标就是把主数据库的bin-log文件的sql语句复制过来。
3.让其在从数据的relay-log重做日志文件中再执行一次这些sql语句即可。
4.下面的主从配置就是围绕这个原理配置
5.具体需要三个线程来操作:
- 1.binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
- 2.从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
- 3 .从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。
可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
主从复制如图:

原理图2,帮助理解!
步骤一:主库db的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库
步骤三:此时主库创建一个binlog dump thread线程,把binlog的内容发送到从库
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log.
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db.
浅拷贝和深拷贝
浅复制:仅仅是指向被复制的内存地址,如果原地址发生改变,那么浅复制出来的对象也会相应的改变。
深复制:在计算机中开辟一块新的内存地址用于存放复制的对象。
31.数据库的第一范式到第四范式
第一范式:每个表应该有唯一标识每一行的主键。
第二范式:在复合主键的情况下,非主键部分不应该依赖于部分主键。
第三范式:非主键之间不应该有依赖关系。
BC范式
BC范式(BCNF)是Boyce-Codd范式的缩写,其定义是:在关系模式中每一个决定因素都包含候选键,也就是说,只要属性或属性组A能够决定任何一个属性B,则A的子集中必须有候选键。BCNF范式排除了任何属性(不光是非主属性,2NF和3NF所限制的都是非主属性)对候选键的传递依赖与部分依赖。
第四范式
如果满足了BC范式,那么就不再会有任何由于函数依赖导致的异常,但是我们还可能会遇到由于多值依赖导致的异常。
已经是BC范式,并且不包含多值依赖关系。
机器学习
1.归一化的定义、公式、优缺点
(1)定义
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
(2)公式
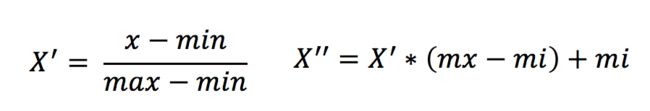
(3)缺点
注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
(4)归一化的好处
1.提升模型的收敛速度
2.提升模型精度
3.防止模型梯度爆炸
2.标准化的定义、公式、与归一化对比
(1)定义
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
(2)公式
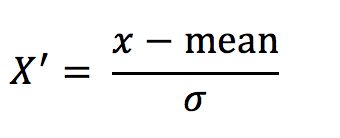
作用于每一列,mean为平均值,σ为标准差
(3)与归一化对比
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
标准变化不会改变分布
所以一般流程为先中心化再标准化。
无量纲:我的理解就是通过某种方法能去掉实际过程中的单位,从而简化计算。
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
3.什么是交叉验证
交叉验证:将拿到的训练数据,分为训练和验证集。比如将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。

3.为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
4.什么是网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
对估计器的指定参数值进行详尽搜索
estimator:估计器对象
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
fit:输入训练数据
score:准确率
结果分析:
bestscore__:在交叉验证中验证的最好结果
bestestimator:最好的参数模型
cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
# 4、KNN预估器流程
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
# 准备要调的超参数
param_dict = {"n_neighbors": [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 4.3 fit数据进行训练
estimator.fit(x_train, y_train)
# 5、评估模型效果
# 方法a:比对预测结果和真实值
y_predict = estimator.predict(x_test)
print("比对预测结果和真实值:\n", y_predict == y_test)
# 方法b:直接计算准确率
score = estimator.score(x_test, y_test)
print("直接计算准确率:\n", score)
然后进行评估查看最终选择的结果和交叉验证的结果
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
5.线性回归应用场景、定义、公式
(1)应用场景
房价预测
销售额度预测
贷款额度预测
(2)定义
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归
(3)公式
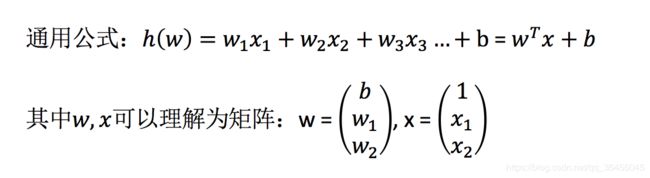
sklearn.linear_model.LinearRegression(fit_intercept=True)
通过正规方程优化
fit_intercept:是否计算偏置
LinearRegression.coef_:回归系数
LinearRegression.intercept_:偏置
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
loss:损失类型
loss=”squared_loss”: 普通最小二乘法
fit_intercept:是否计算偏置
learning_rate : string, optional
学习率填充
'constant': eta = eta0
'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
'invscaling': eta = eta0 / pow(t, power_t)
power_t=0.25:存在父类当中
对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。
SGDRegressor.coef_:回归系数
SGDRegressor.intercept_:偏置
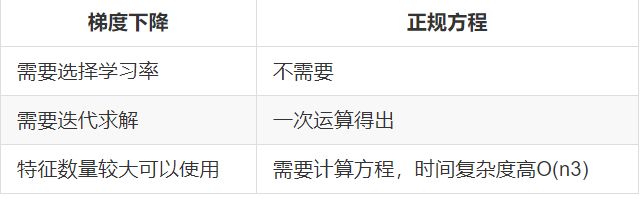
6.线性回归经常使用的两种优化算法
如何去求模型当中的W,使得损失最小?(目的是找到最小损失对应的W值)
(1)正规方程

缺点:当特征过多过复杂时,求解速度太慢并且得不到结果
(2)梯度下降
沿着梯度的反方向一直走,就能走到局部的最低点!
公式:
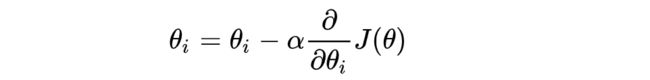
7.梯度下降和正规方程的对比
7.回归的选择
小规模数据:
LinearRegression(不能解决拟合问题)
岭回归
大规模数据:SGDRegressor
8.梯度下降的种类
- 全梯度下降算法(Full gradient descent),
- 随机梯度下降算法(Stochastic gradient descent),
- 随机平均梯度下降算法(Stochastic average gradient descent)
- 小批量梯度下降算法(Mini-batch gradient descent),
它们都是为了正确地调节权重向量,通过为每个权重计算一个梯度,从而更新权值,使目标函数尽可能最小化。其差别在于样本的使用方式不同。
四种梯度下降算法的比较:
(1)FG方法由于它每轮更新都要使用全体数据集,故花费的时间成本最多,内存存储最大。
(2)SAG在训练初期表现不佳,优化速度较慢。这是因为我们常将初始梯度设为0,而SAG每轮梯度更新都结合了上一轮梯度值。
(3)综合考虑迭代次数和运行时间,SG表现性能都很好,能在训练初期快速摆脱初始梯度值,快速将平均损失函数降到很低。但要注意,在使用SG方法时要慎重选择步长,否则容易错过最优解。
(4)mini-batch结合了SG的“胆大”和FG的“心细”,从6幅图像来看,它的表现也正好居于SG和FG二者之间。在目前的机器学习领域,mini-batch是使用最多的梯度下降算法,正是因为它避开了FG运算效率低成本大和SG收敛效果不稳定的缺点。
9.回归性能评估
均方误差(Mean Squared Error)MSE)评价机制:

注:yi为预测值,¯y为真实值
sklearn.metrics.mean_squared_error(y_true, y_pred)
均方误差回归损失
y_true:真实值
y_pred:预测值
return:浮点数结果
10.欠拟合和过拟合定义、解决办法
(1)定义
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
(2)原因以及解决办法
欠拟合原因以及解决办法
原因:学习到数据的特征过少
解决办法:
1)添加其他特征项,有时候我们模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段,无论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。除上面的特征之外,“上下文特征”、“平台特征”等等,都可以作为特征添加的首选项。
2)添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
过拟合原因以及解决办法
原因:原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决办法:
1)重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
3)正则化
4)减少特征维度,防止维灾难
11.正则化的定义和类别
(1)什么是正则化
在解决回归过拟合中,我们选择正则化。但是对于其他机器学习算法如分类算法来说也会出现这样的问题,除了一些算法本身作用之外(决策树、神经网络),我们更多的也是去自己做特征选择,包括之前说的删除、合并一些特征。
在学习的时候,数据提供的特征有些影响模型复杂度或者这个特征的数据点异常较多,所以算法在学习的时候尽量减少这个特征的影响(甚至删除某个特征的影响),这就是正则化
注:调整时候,算法并不知道某个特征影响,而是去调整参数得出优化的结果
2)正则化类别
- L2正则化
作用:可以使得其中一些W的都很小,都接近于0,削弱某个特征的影响
优点:越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象
Ridge回归
- L1正则化
作用:可以使得其中一些W的值直接为0,删除这个特征的影响
LASSO回归
12.正则化线性模型
岭回归(常用)
岭回归是线性回归的正则化版本,即在原来的线性回归的 cost function 中添加正则项(regularization term):

以达到在拟合数据的同时,使模型权重尽可能小的目的,岭回归代价函数:
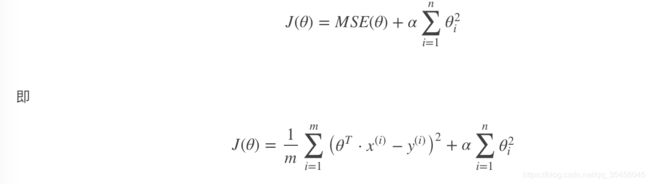
α=0:岭回归退化为线性回归
lasso回归(只有少数特征可用,输出稀疏矩阵)
asso 回归是线性回归的另一种正则化版本,正则项为权值向量的ℓ1范数。
Lasso回归的代价函数 :
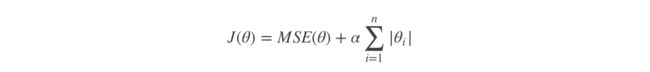
Lasso Regression 有一个很重要的性质是:倾向于完全消除不重要的权重。
例如:当α 取值相对较大时,高阶多项式退化为二次甚至是线性:高阶多项式特征的权重被置为0。
也就是说,Lasso Regression 能够自动进行特征选择,并输出一个稀疏模型(只有少数特征的权重是非零的)。
Elastic Net (弹性网络)
弹性网络在岭回归和Lasso回归中进行了折中,通过 混合比(mix ratio) r 进行控制:
r=0:弹性网络变为岭回归
r=1:弹性网络便为Lasso回归
弹性网络的代价函数 :
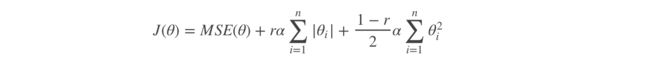
一般来说,我们应避免使用朴素线性回归,而应对模型进行一定的正则化处理,那如何选择正则化方法呢?
常用:岭回归
假设只有少部分特征是有用的:
弹性网络
Lasso
一般来说,弹性网络的使用更为广泛。因为在特征维度高于训练样本数,或者特征是强相关的情况下,Lasso回归的表现不太稳定。
api:
from sklearn.linear_model import Ridge, ElasticNet, Lasso
13.sklearn模型的保存和加载API
from sklearn.externals import joblib
保存:joblib.dump(estimator, 'test.pkl')
加载:estimator = joblib.load('test.pkl')
14.逻辑回归的应用场景
- 广告点击率
- 是否为垃圾邮件
- 是否患病
- 金融诈骗
- 虚假账号
看到上面的例子,我们可以发现其中的特点,那就是都属于两个类别之间的判断。逻辑回归就是解决二分类问题的利器
15.逻辑回归的原理
1.输入
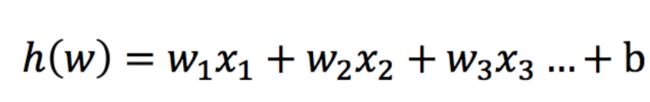
逻辑回归的输入就是一个线性回归的结果。
2.激活函数sigmod函数

判断标准
回归的结果输入到sigmoid函数当中
输出结果:[0, 1]区间中的一个概率值,默认为0.5为阈值
逻辑回归最终的分类是通过属于某个类别的概率值来判断是否属于某个类别,并且这个类别默认标记为1(正例),另外的一个类别会标记为0(反例)。(方便损失计算)
“那像你提到有用到Xgboost,你有测试过Xgboost和GBDT的效果区别吗?你认为在你的项目上是什么导致原因导致了这个区别”
“是的,我们有试过,Xgboost的精度要比GBDT高而且效率也要更高。我认为精度高的最大原因是大部分的CTR特征中,我们会将一些高基类别的离散值转化为连续值,会产生很多含有缺失值的稀疏特征,而Xgboost会对缺失值做一个特殊的处理。效率高是因为建树时采用了更好的分割点估计算法”
“xgboost对缺失值是怎么处理的?”
“在普通的GBDT策略中,对于缺失值的方法是先手动对缺失值进行填充,然后当做有值的特征进行处理,但是这样人工填充不一定准确,而且没有什么理论依据。而Xgboost采取的策略是先不处理那些值缺失的样本,采用那些有值的样本搞出分裂点,然后在遍历每个分裂点的时候,尝试将缺失样本划入左子树和右子树,选择使损失最优的情况。”
“那你知道在什么情况下应该使用Onehot呢?”
“对于non-ordered特征来说需要做一个onehot,实践中我发现在线性模型中将连续值特征离散化成0/1型特征效果会更好(线性模型拟合连续特征能力弱,需要将连续特征离散化 成one hot形式提升模型的拟合能力)。所以对于稠密的类别型特征,可以对离散特征做一个OneHot变化,对于高基类别特征我们最好还是采用bin count或者embedding的方法去处理”
“你能讲一下Xgboost和GBDT的区别吗?”
“Xgboost是GBDT算法的一种很好的工程实现,并且在算法上做了一些优化,主要的优化在一下几点。首先Xgboost加了一个衰减因子,相当于一个学习率,可以减少加进来的树对于原模型的影响,让树的数量变得更多;其次是在原GBDT模型上加了个正则项,对于树的叶子节点的权重做了一个约束;还有增加了在随机森林上常用的col subsample的策略;然后使用二阶泰勒展开去拟合损失函数,加快优化的效率;然后最大的地方在于不需要遍历所有可能的分裂点了,它提出了一种估计分裂点的算法。在工程上做了一个算法的并发实现,具体我并不了解如何实现的”
LGB比xgboost快且精度高的原因
LGB(LightGBM,下文均采用此缩写)不需要通过所有样本计算信息增益了,而且内置特征降维技术,所以更快。XGB虽然每次只需要遍历几个可能的分裂节点,然后比较每个分裂节点的信息增益,选择最大的那个进行分割,但比较时需要考虑所有样本带来的信息增益。而LGB只需采用少量的样本计算信息增益,所以速度会快很多。
至于LGB为什么比XGB的精度高这一点,我的理解是选择梯度大(残差大)样本来进行特征分裂生成的树,借鉴了Adaboost的更改样本权重的思想。每棵树针对某些特定训练样本有着较好的划分能力,导致每棵树之间的异质性较大,对于效果近似但异质性大的模型加权往往会带来更大的提升。
分类的评估方法
1.精准率 召回率
精确率:预测结果为正例样本中真实为正例的比例(了解)
召回率:真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)

2.F1-score
F1-score,反映了模型的稳健型

3.分类评估报告
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
y_true:真实目标值
y_pred:估计器预测目标值
labels:指定类别对应的数字
target_names:目标类别名称
return:每个类别精确率与召回率
请说明随机森林较一般决策树稳定的几点原因
bagging的方法,多个树投票提高泛化能力
bagging中引入随机(参数、样本、特征、空间映射),避免单棵树的过拟合,提高整体泛化能力
数据清理中,处理缺失值的方法是?
由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法有:估算,整例删除,变量删除和成对删除。
估算(estimation)。最简单的办法就是用某个变量的样本均值、中位数或众数代替无效值和缺失值。这种办法简单,但没有充分考虑数据中已有的信息,误差可能较大。另一种办法就是根据调查对象对其他问题的答案,通过变量之间的相关分析或逻辑推论进行估计。例如,某一产品的拥有情况可能与家庭收入有关,可以根据调查对象的家庭收入推算拥有这一产品的可能性。
整例删除(casewise deletion)是剔除含有缺失值的样本。由于很多问卷都可能存在缺失值,这种做法的结果可能导致有效样本量大大减少,无法充分利用已经收集到的数据。因此,只适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
变量删除(variable deletion)。如果某一变量的无效值和缺失值很多,而且该变量对于所研究的问题不是特别重要,则可以考虑将该变量删除。这种做法减少了供分析用的变量数目,但没有改变样本量。
成对删除(pairwise deletion)是用一个特殊码(通常是9、99、999等)代表无效值和缺失值,同时保留数据集中的全部变量和样本。但是,在具体计算时只采用有完整答案的样本,因而不同的分析因涉及的变量不同,其有效样本量也会有所不同。这是一种保守的处理方法,最大限度地保留了数据集中的可用信息。
余弦距离与欧式距离求相似度的差别。
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
(1)例如,统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为(1,0);此时二者的余弦距很大,而欧氏距离很小;我们分析两个用户对于不同视频的偏好,更关注相对差异,显然应当使用余弦距离。
(2)而当我们分析用户活跃度,以登陆次数(单位:次)和平均观看时长(单:分钟)作为特征时,余弦距离会认为(1,10)、(10,100)两个用户距离很近;但显然这两个用户活跃度是有着极大差异的,此时我们更关注数值绝对差异,应当使用欧氏距离。
什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。
聚类分析是一种无监督的学习方法,根据一定条件将相对同质的样本归到一个类总。
聚类方法主要有:
a. 层次聚类
b. 划分聚类:kmeans
c. 密度聚类
d. 网格聚类
e. 模型聚类:高斯混合模型
k-means比较好介绍,选k个点开始作为聚类中心,然后剩下的点根据距离划分到类中;找到新的类中心;重新分配点;迭代直到达到收敛条件或者迭代次数。 优点是快;缺点是要先指定k,同时对异常值很敏感。
SVM的优缺点
优点:
a. 能应用于非线性可分的情况
b. 最后分类时由支持向量决定,复杂度取决于支持向量的数目而不是样本空间的维度,避免了维度灾难
c. 具有鲁棒性:因为只使用少量支持向量,抓住关键样本,剔除冗余样本
d. 高维低样本下性能好,如文本分类
缺点:
a. 模型训练复杂度高
b. 难以适应多分类问题
c. 核函数选择没有较好的方法论
需要掌握的机器学习算法:
分类算法:逻辑回归,贝叶斯、决策树、随机森林
回归算法:线性回归
聚类算法:K-means
需要掌握的核心技能:
特征工程
模型评价
交叉检验(用已有的数据监测算法的预测力)
1.学过那些算法,处理过什么样的 特征
2.决策树的原理和作用?什么情况下使用比较好?
3.Kmeans算法分了多少个类!分这么多类有什么作用?
4.Pandas,Numpy熟悉吗?
5.机器学习模型的准确度高不高?
6.建立好模型后是不是只要使用就可以,接下来你干了什么?
7.k近邻算法的实现流程
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按距离递增依次排序
(3)选取与当前点距离最小的k个点
(4)统计前k个点所在的类别出现的频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
8.k近邻中k值的选取
K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。对这个简单的分类器进行泛化,用核方法把这个线性模型扩展到非线性的情况,具体方法是把低维数据集映射到高维特征空间。
9.什么是kd树
根据KNN每次需要预测一个点时,我们都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近的k个点进行投票。当数据集很大时,这个计算成本非常高,针对N个样本,D个特征的数据集,其算法复杂度为O(DN^2)。
kd树:为了避免每次都重新计算一遍距离,算法会把距离信息保存在一棵树里,这样在计算之前从树里查询距离信息,尽量避免重新计算。其基本原理是,如果A和B距离很远,B和C距离很近,那么A和C的距离也很远。有了这个信息,就可以在合适的时候跳过距离远的点。
这样优化后的算法复杂度可降低到O(DNlog(N))。
原理:
(1)树的建立
(2)最近领域搜索
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
构造方法:
(1)构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区域;
(2)通过递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。
(3)上述过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
(4)通常,循环的选择坐标轴对空间切分,选择训练实例点在坐标轴上的中位数为切分点,这样得到的kd树是平衡的(平衡二叉树:它是一棵空树,或其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是平衡二叉树)。
KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。在构建KD树时,关键需要解决2个问题:
(1)选择向量的哪一维进行划分;
(2)如何划分数据;
第一个问题简单的解决方法可以是随机选择某一维或按顺序选择,但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。好的划分方法可以使构建的树比较平衡,可以每次选择中位数来进行划分,这样问题2也得到了解决。
10.特征降维
深度学习
1.神经网络
2.tensorflow
爬虫
1.爬虫的分布式管理是怎么实现的
2.这个爬虫爬取的数据的需求方是哪个行业的,爬着些数据做什么
数据分析项目
1.这个数据分析项目中你都做了些什么事
人事
- 为什么学经济要转行(几乎必问)
- 上一家工作为什么离职
- 我们这项工作事这样的(描述工作流程),你觉得你能在这项流程中胜任哪些任务?
- 你希望下一份工作的氛围是怎么样的
- 你希望上司是什么样的人
python基础
闭包
定义:闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境)(想想Erlang的外层函数传入一个参数a, 内层函数依旧传入一个参数b, 内层函数使用a和b, 最后返回内层函数)
爬虫
scrapy
一、使用场景
在需要爬取的数据量极大的情况下,建议使用scrapy框架。性能好。
二、scrapy工作原理
engine 引擎,类似于一个中间件,负责控制数据流在系统中的所有组件之间流动,可以理解为“传话者”
spider 爬虫,负责解析response和提取Item
downloader 下载器,负责下载网页数据给引擎
scheduler 调度器,负责将url入队列,默认去掉重复的url
item pipelines 管道,负责处理被spider提取出来的Item数据
1、从spider中获取到初始url给引擎,告诉引擎帮我给调度器;
2、引擎将初始url给调度器,调度器安排入队列;
3、调度器告诉引擎已经安排好,并把url给引擎,告诉引擎,给下载器进行下载;
4、引擎将url给下载器,下载器下载页面源码;
5、下载器告诉引擎已经下载好了,并把页面源码response给到引擎;
6、引擎拿着response给到spider,spider解析数据、提取数据;
7、spider将提取到的数据给到引擎,告诉引擎,帮我把新的url给到调度器入队列,把信息给到Item Pipelines进行保存;
8、Item Pipelines将提取到的数据保存,保存好后告诉引擎,可以进行下一个url的提取了;
9、循环3-8步,直到调度器中没有url,关闭网站(若url下载失败了,会返回重新下载)。
【一次模拟面试】
【索引失效的情况】
1.有or必全有索引;
2.复合索引未用左列字段;
3.like以%开头;
4.需要类型转换;
5.where中索引列有运算;
6.where中索引列使用了函数;
7.如果mysql觉得全表扫描更快时(数据少);
脏读是什么
什么情况下会脏读
事务的隔离级别
【sql语句的优化】
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
3.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
若要提高效率,可以考虑全文检索。
6.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
select id from t where datediff(day,createdate,'2005-11-30')=0--'2005-11-30'生成的id
应改为:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
13.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
15.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
16.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
18.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
21.避免频繁创建和删除临时表,以减少系统表资源的消耗。
22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
29.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
30.尽量避免大事务操作,提高系统并发能力。
sql的优化
python的迭代器生成器
二分查找是什么
快速排序是什么
怎么样处理垃圾邮件
怎么样实现论文的查重系统
手写sigmod激活函数
什么是主从复制
mysql怎么实现负载均衡
knn算法解释
推荐系统需要采集用户的哪些特征
【阿里数据分析面试题】
【bagging和boosting的区别】
Baggging 和Boosting都是模型融合的方法,可以将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好。
Bagging即套袋法,其算法过程如下:
1.从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
2.每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
3.对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
Boosting:
AdaBoosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)
梯度提升的Boosting方式是使用代价函数对上一轮训练出的模型函数f的偏导来拟合残差。
区别
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
【python编码规范】
编码规范的好处:
好处1:代码风格的统一可以很好地提高代码的可读性。制定一个相同的代码风格,如直接选用Python的PEP8官方风格指南,严格遵守后可以得到美观又统一风格的项目代码,这在多人协作的开发中是很有必要的,每个人编写代码的习惯不一样,特别是有些喜欢用一些奇怪或新奇的写法,这样可读性很差。尤其是灵活的脚本语言Python、JS等,越是灵活越需要规范,代码更多是写给人看,而不是仅仅给机器跑而已。实际上Github上稍微正规的项目都有自己的项目代码规范,如果没有显式标注,那便是默认使用官方的风格指南。Python的PEP8规范很详细,作为语言本身重要的补充,规范是代码简洁美观的有力保障。
好处2:可以发现隐藏的bug。代码风格如果规范得好(像PEP8),是可以发现代码中潜藏的bug的,比如未定义的变量,定义了变量却没使用,变量覆盖等等,当代码量越来越大,况且单元测试不完善的时候,代码规范检查可以发现一些基础的不良写法,发现隐藏的bug。(还是那句话,人都是不可靠的,总会有疏忽)
好处 3:可以稍微提高性能。比如定义的变量未使用,引入的模块未使用等,会造成额外的性能消耗和代码冗余,代码规范可以方便地检查出来。
代码规范的检查最好是做到自动化,最少也要配置快捷使用方式。可以使用flake8和autopep8等检查规范和自动格式化代码的工具,很多IDE和编辑器都可以配置插件和快捷使用方式。Python中最专业最强大的IDE当数Pycharm,可以配置「External Tools」,Sublime之类的编辑器也可以方便地配置插件。
即便有工具可以检查和格式化代码,但自己平时编写代码时最好还是按照规范来编写,第一工具并非万能,不能过分依赖;第二是按照规范来编写本来就是一个习惯问题,养成好习惯,也就离编写漂亮又优雅代码的目标不远了。
具体的规范:
一 代码编排
1 缩进。4个空格的缩进(编辑器都可以完成此功能),不要使用Tap,更不能混合使用Tap和空格。
2 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
3 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
二 文档编排
1 模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
2 不要在一句import中多个库,比如import os, sys不推荐。
3 如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。
三 空格的使用
总体原则,避免不必要的空格。
1 各种右括号前不要加空格。
2 逗号、冒号、分号前不要加空格。
3 函数的左括号前不要加空格。如Func(1)。
4 序列的左括号前不要加空格。如list[2]。
5 操作符左右各加一个空格,不要为了对齐增加空格。
6 函数默认参数的赋值符左右省略空格。
7 不要将多句语句写在同一行,尽管使用‘;’允许。
8 if/for/while语句中,即使执行语句只有一句,也必须另起一行。
四 注释
总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释!
注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。
1 块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。
2 行注释,在一句代码后加注释。比如:x = x + 1 # Increment x
但是这种方式尽量少使用。
3 避免无谓的注释。
五 文档描述
1 为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。
2 如果docstring要换行,参考如下例子,详见PEP 257
“”"Return a foobang
Optional plotz says to frobnicate the bizbaz first.
“”"
六 命名规范
总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。
1 尽量单独使用小写字母‘l’,大写字母‘O’等容易混淆的字母。
2 模块命名尽量短小,使用全部小写的方式,可以使用下划线。
3 包命名尽量短小,使用全部小写的方式,不可以使用下划线。
4 类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。
5 异常命名使用CapWords+Error后缀的方式。
6 全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是__all__机制;二是前缀一个下划线。
7 函数命名使用全部小写的方式,可以使用下划线。
8 常量命名使用全部大写的方式,可以使用下划线。
9 类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。
9 类的属性有3种作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public属性前,前缀一条下划线。
11 类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。
12 为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。
13 类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。
**七 编码建议**
1 编码中考虑到其他python实现的效率等问题,比如运算符‘+’在CPython(Python)中效率很高,都是Jython中却非常低,所以应该采用.join()的方式。
2 尽可能使用‘is’‘is not’取代‘==’,比如if x is not None 要优于if x。
3 使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。
4 异常中不要使用裸露的except,except后跟具体的exceptions。
5 异常中try的代码尽可能少。比如:
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
要优于
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)
6 使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。比如
Yes: if foo.startswith(‘bar’):优于
No: if foo[:3] == ‘bar’:
7 使用isinstance()比较对象的类型。比如
Yes: if isinstance(obj, int): 优于
No: if type(obj) is type(1):
8 判断序列空或不空,有如下规则
Yes: if not seq:
if seq:
优于
No: if len(seq)
if not len(seq)
9 字符串不要以空格收尾。
10 二进制数据判断使用 if boolvalue的方式。
Only action can relieve the uneasiness.
【聚类分析有哪几种,区别】
k-means聚类算法
k-means是划分方法中较经典的聚类算法之一。由于该算法的效率高,所以在对大规模数据进行聚类时被广泛应用。目前,许多算法均围绕着该算法进行扩展和改进。
k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。k-means算法的处理过程如下:首先,随机地选择k个对象,每个对象初始地代表了一个簇的平均值或中心;对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;然后重新计算每个簇的平均值。这个过程不断重复,直到准则函数收敛。通常,采用平方误差准则,其定义如下:
这里E是数据库中所有对象的平方误差的总和,p是空间中的点,mi是簇Ci的平均值[9]。该目标函数使生成的簇尽可能紧凑独立,使用的距离度量是欧几里得距离,当然也可以用其他距离度量。k-means聚类算法的算法流程如下:
输入:包含n个对象的数据库和簇的数目k;
输出:k个簇,使平方误差准则最小。
步骤:
(1) 任意选择k个对象作为初始的簇中心;
(2) repeat;
(3) 根据簇中对象的平均值,将每个对象(重新)赋予最类似的簇;
(4) 更新簇的平均值,即计算每个簇中对象的平均值;
(5) until不再发生变化。
层次聚类算法
根据层次分解的顺序是自底向上的还是自上向下的,层次聚类算法分为凝聚的层次聚类算法和分裂的层次聚类算法。
凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。四种广泛采用的簇间距离度量方法如下:
这里给出采用最小距离的凝聚层次聚类算法流程:
(1) 将每个对象看作一类,计算两两之间的最小距离;
(2) 将距离最小的两个类合并成一个新类;
(3) 重新计算新类与所有类之间的距离;
(4) 重复(2)、(3),直到所有类最后合并成一类。
2.3 SOM聚类算法
SOM神经网络[11]是由芬兰神经网络专家Kohonen教授提出的,该算法假设在输入对象中存在一些拓扑结构或顺序,可以实现从输入空间(n维)到输出平面(2维)的降维映射,其映射具有拓扑特征保持性质,与实际的大脑处理有很强的理论联系。
SOM网络包含输入层和输出层。输入层对应一个高维的输入向量,输出层由一系列组织在2维网格上的有序节点构成,输入节点与输出节点通过权重向量连接。学习过程中,找到与之距离最短的输出层单元,即获胜单元,对其更新。同时,将邻近区域的权值更新,使输出节点保持输入向量的拓扑特征。
算法流程:
(1) 网络初始化,对输出层每个节点权重赋初值;
(2) 将输入样本中随机选取输入向量,找到与输入向量距离最小的权重向量;
(3) 定义获胜单元,在获胜单元的邻近区域调整权重使其向输入向量靠拢;
(4) 提供新样本、进行训练;
(5) 收缩邻域半径、减小学习率、重复,直到小于允许值,输出聚类结果。
2.4 FCM聚类算法
1965年美国加州大学柏克莱分校的扎德教授第一次提出了‘集合’的概念。经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面。为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析。用模糊数学的方法进行聚类分析,就是模糊聚类分析[12]。
FCM算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法。该聚类算法是传统硬聚类算法的一种改进。
算法流程:
(1) 标准化数据矩阵;
(2) 建立模糊相似矩阵,初始化隶属矩阵;
(3) 算法开始迭代,直到目标函数收敛到极小值;
(4) 根据迭代结果,由最后的隶属矩阵确定数据所属的类,显示最后的聚类结果。
【kmeans的优缺点】
k-means的优点有:
1.原理简单,实现方便,收敛速度快;
2.聚类效果较优;
3.模型的可解释性较强;
4.调参只需要簇数k;
k-means的缺点有:
1.k的选取不好把握;
2.对于不是凸的数据集比较难以收敛;
3.如果数据的类型不平衡,比如数据量严重失衡或者类别的方差不同,则聚类效果不佳;
4.采用的是迭代的方法,只能得到局部最优解;
5.对于噪音和异常点比较敏感。
【机器学习模型评估指标】
一、分类问题
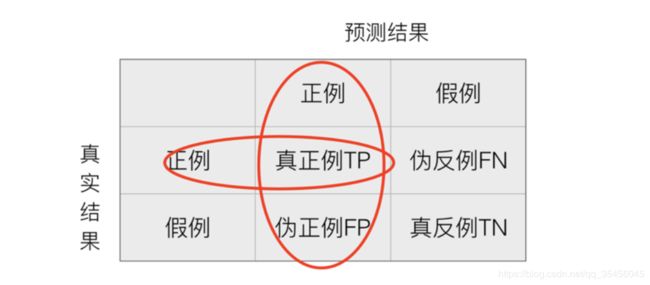
1、混淆矩阵
混淆矩阵是监督学习中的一种可视化工具,主要用于比较分类结果和实例的真实信息。矩阵中的每一行代表实例的预测类别,每一列代表实例的真实类别。
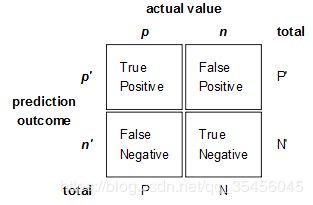
真正(True Positive , TP):被模型预测为正的正样本。
假正(False Positive , FP):被模型预测为正的负样本。
假负(False Negative , FN):被模型预测为负的正样本。
真负(True Negative , TN):被模型预测为负的负样本。
真正率(True Positive Rate,TPR):TPR=TP/(TP+FN),即被预测为正的正样本数 /正样本实际数。
假正率(False Positive Rate,FPR) :FPR=FP/(FP+TN),即被预测为正的负样本数 /负样本实际数。
假负率(False Negative Rate,FNR) :FNR=FN/(TP+FN),即被预测为负的正样本数 /正样本实际数。
真负率(True Negative Rate,TNR):TNR=TN/(TN+FP),即被预测为负的负样本数 /负样本实际数/2
2、准确率(Accuracy)
准确率是最常用的分类性能指标。
Accuracy = (TP+TN)/(TP+FN+FP+TN)
即正确预测的正反例数 /总数
3、精确率(Precision)
精确率容易和准确率被混为一谈。其实,精确率只是针对预测正确的正样本而不是所有预测正确的样本。表现为预测出是正的里面有多少真正是正的。可理解为查准率。
Precision = TP/(TP+FP)
即正确预测的正例数 /预测正例总数
4、召回率(Recall)
召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall = TP/(TP+FN),即正确预测的正例数 /实际正例总数
5、F1 score
F值是精确率和召回率的调和值,更接近于两个数较小的那个,所以精确率和召回率接近时,F值最大。很多推荐系统的评测指标就是用F值的。
2/F1 = 1/Precision + 1/Recall
6、ROC曲线
逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正类,小于阈值为负类。如果我们减小这个阀值,更多的样本会被识别为正类,提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了直观表示这一现象,引入ROC。根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR假正率),纵坐标为True Positive Rate(TPR真正率)。一般情况下,这个曲线都应该处于(0,0)和(1,1)连线的上方,如图:

ROC曲线中的四个点和一条线:
点(0,1):即FPR=0, TPR=1,意味着FN=0且FP=0,将所有的样本都正确分类。
点(1,0):即FPR=1,TPR=0,最差分类器,避开了所有正确答案。
点(0,0):即FPR=TPR=0,FP=TP=0,分类器把每个实例都预测为负类。
点(1,1):分类器把每个实例都预测为正类。
总之:ROC曲线越接近左上角,该分类器的性能越好。而且一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting
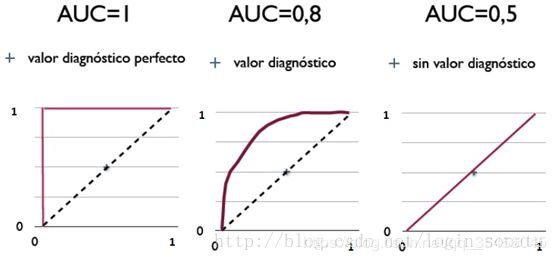
7、AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积(ROC的积分),通常大于0.5小于1。随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。AUC值(面积)越大的分类器,性能越好,如图:
8、PR曲线
PR曲线的横坐标是精确率P,纵坐标是召回率R。评价标准和ROC一样,先看平滑不平滑(蓝线明显好些)。一般来说,在同一测试集,上面的比下面的好(绿线比红线好)。当P和R的值接近时,F1值最大,此时画连接(0,0)和(1,1)的线,线和PRC重合的地方的F1是这条线最大的F1(光滑的情况下),此时的F1对于PRC就好像AUC对于ROC一样。一个数字比一条线更方便调型。
复制代码
有时候模型没有单纯的谁比谁好(比如图二的蓝线和青线),所以选择模型还是要结合具体的使用场景。下面是两个场景:
1,地震的预测 对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了,也不要预测100次对了8次漏了两次。
2,嫌疑人定罪 基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。即时有时候放过了一些罪犯(recall低),但也是值得的。
对于分类器来说,本质上是给一个概率,此时,我们再选择一个CUTOFF点(阀值),高于这个点的判正,低于的判负。那么这个点的选择就需要结合你的具体场景去选择。反过来,场景会决定训练模型时的标准,比如第一个场景中,我们就只看RECALL=99.9999%(地震全中)时的PRECISION,其他指标就变得没有了意义。
当正负样本数量差距不大的情况下,ROC和PR的趋势是差不多的,但是在正负样本分布极不均衡的情况下,PRC比ROC更能真实的反映出实际情况,因为此时ROC曲线看起来似乎很好,但是却在PR上效果一般。
复制代码
二、回归问题
拟合(回归)问题比较简单,所用到的衡量指标也相对直观。假设yi
-
平均绝对误差(MAE)
平均绝对误差MAE(Mean Absolute Error)又被称为l1 -
平均平方误差(MSE)
平均平方误差MSE(Mean Squared Error)又被称为l2
3、均方根误差(RMSE)
RMSE虽然广为使用,但是其存在一些缺点,因为它是使用平均误差,而平均值对异常点(outliers)较敏感,如果回归器对某个点的回归值很不理性,那么它的误差则较大,从而会对RMSE的值有较大影响,即平均值是非鲁棒的。
4、解释变异
解释变异( Explained variance)是根据误差的方差计算得到的:
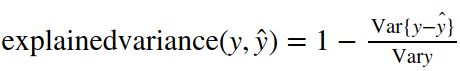
5、决定系数
决定系数(Coefficient of determination)又被称为R2
三、聚类
1 . 兰德指数
兰德指数(Rand index)需要给定实际类别信息C
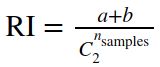
其中![]() 数据集中可以组成的总元素对数,RI取值范围为[0,1]
数据集中可以组成的总元素对数,RI取值范围为[0,1]
对于随机结果,RI并不能保证分数接近零。为了实现“在聚类结果随机产生的情况下,指标应该接近零”,调整兰德系数(Adjusted rand index)被提出,它具有更高的区分度:
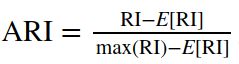
具体计算方式参见Adjusted Rand index。
ARI取值范围为[−1,1]
- 互信息
互信息(Mutual Information)也是用来衡量两个数据分布的吻合程度。假设U

利用基于互信息的方法来衡量聚类效果需要实际类别信息,MI与NMI取值范围为[0,1]
- 轮廓系数
轮廓系数(Silhouette coefficient)适用于实际类别信息未知的情况。对于单个样本,设a

对于一个样本集合,它的轮廓系数是所有样本轮廓系数的平均值。
轮廓系数取值范围是[−1,1]
【阿里数据库】
数据库
问题一:mysql 锁机制 ?
回答:
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
问题二:排它锁 & 共享锁?
回答:
排他锁和共享锁主要是针对的MySQL的InnoDB引擎的
共享锁【S锁】
又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁【X锁】
又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A
共享锁与排它锁区别
1、 加了共享锁的对象,可以继续加共享锁,不能再加排他锁。加了排他锁后,不能再加任何锁。
2、 比如一个DML操作,就要对受影响的行加排他锁,这样就不允许再加别的锁,也就是说别的会话不能修改这些行。同时为了避免在做这个DML操作的时候,有别的会话执行DDL,修改表的定义,所以要在表上加共享锁,这样就阻止了DDL的操作。
3、 当执行DDL操作时,就需要在全表上加排他锁
问题三:Mysql 索引是怎么实现的?
回答:Mysql索引是通过B+tree算法实现的,索引分为聚簇索引与非聚簇索引,InnoDB是聚簇索引数据,MyISAM是非聚簇索引数据,InnoDB将通过主键聚集数据。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。非聚簇索引也是根据主键来作为索引。
聚簇索引叶子节点保存的是具体的数据,根据B+tree的搜索规则可以直接查到值;而非聚簇索引叶子节点保存的是数据所在的物理地址,根据B+tree的搜索规则可以直接查到值的物理地址,然后根据地址进行一次I/O就能够查到值。
缓存
问题一:缓存可能会遇到的问题?
回答:
缓存穿透:
现象:查询一条缓存和数据库都不存在的数据,直接穿透缓存查询数据库,造成数据库压力。
解决:查询不到数据,返回设置一个该数据的缓存,同时设置过期时间;或者采用在缓存之前在加一层 BloomFilter ,在查询的时候先去 BloomFilter 去查询 key 是否存在,如果不存在就直接返回。
缓存击穿:
现象:大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去
解决:我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。
缓存雪崩:
现象:缓存雪崩的情况是说,当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上面。
解决:事前:使用集群缓存,保证缓存服务的高可用;事中:使用本地缓存 +限流&降级,避免MySQL被打死;事后:尽快恢复缓存集群
热点数据失效:
现象:对于一些热点的数据来说,当缓存失效以后会存在大量的请求过来,然后打到数据库去,从而可能导致数据库崩溃的情况。
解决:设置不同的失效时间;加互斥锁
缓存一致性问题:
现象:更新数据库数据的时候,缓存没来得及更新,用户查询的数据为脏数据,缓存数据不一致。
解决:先淘汰缓存再更新数据库,再生成缓存。
问题二:先删缓存还是先更新数据库,为什么?
回答:

【SQL面试题】
事务,索引,引擎区别,锁,sql语句,数据库优化,这几块是吧
【drop delete trucate 区别】
【in 和 exists的区别】



【20200409模拟面试题】
【==和is的区别】
==判断值
is判断地址
可以通过id()检查地址
【python基础题】
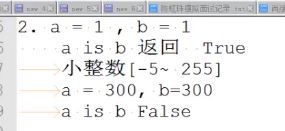
小整数[-5 ,255] 已经分配了内存地址
【解释深拷贝和浅拷贝】
浅拷贝:只拷贝表层元素
深拷贝:只会在内存中重新创建所有元素
【list、str、字典、元组这些东西是迭代器吗】
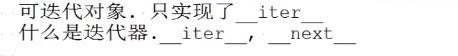
list str dict tuple 是可迭代对象 不是迭代器
迭代器 是指 能实现__iter__ __next__方法
可迭代对象 只实现了__iter__
【创建生成器的方法】

【线程进程协程的理解】
线程 :CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),线程间通信主要通过共享内存,上下文切换很快,资源开销较少
进程 :系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大
协程 :协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
【io密集型任务和cpu密集型任务,以及应该如何给他们分配进程线程】
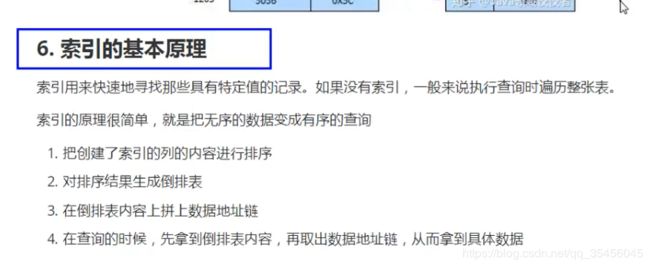
【如何理解ndarray数据结构】
ndarray是numpy中的多维数组,数组中的元素具有相同的类型,且可以被索引
表示数据的一中数据结构,可表示图片等数据,python中列表的优化,查询速度比列表快