Implicit 3D Orientation Learning for 6D Object Detection from RGB Images初级翻译
题目——根据 RGB 图像检测 6 维位姿的隐式三维朝向学习
论文地址Implicit 3D Orientation Learning for 6D Object Detection from RGB Images
代码地址https://github.com/DLR-RM/AugmentedAutoencoder
本文获得ECCV 2018 最佳论文奖,个人能力太low,首次翻译只是为了更好地理解论文。
摘要:我们提出一种针对物体检测和6维姿态估计的RGB图像处理系统。我们新的三维朝向估计器是基于降噪自动编码器的变种,借助的是领域随机化(domain randamization)用三维模型的模拟视角来进行训练。这个所谓的增强自编码相较已存在的方法有数个优点:它不需要真实的、姿态标注的训练数据;它可以泛化到各种测试传感器并且能天然地处理物体和视角的对称性。这个模型学到的并不是从输入图像到物体位姿的显式映射,实际上它会根据图像样本在隐含空间内建立一个隐式的物体位姿表征。基于 T-LESS 和 LineMOD 数据集的实验表明所提的方法不仅比类似的基于模型的方法有更好的表现,而且表现也接近目前顶级的、需要真实的位姿标注图像的方法。
1.介绍
现代计算机视觉系统的应用中如移动机器人的控制和增强现实一个非常重要的成分就是可靠和快速的6维目标检测组件。尽管,最近有很多令人激动人心的结果,然而,一个灵活、泛化、鲁棒并快速的方法并没有出现。造成这个结果的原因是多方面的。最重要的是,针对一些典型的挑战如物体阻隔、不同的背景杂斑和环境的动态改变,当前的方案不够鲁棒,其次,现存的方法经常需要特定的物体特性,如足够的纹理表面结构或非对称的形状避免混乱。最后,当前的方法在运行时间不够有效率并且所需标注训练数据数量上不够。
因此,我们提出一种直接处理这些问题的新方法。具体来说,我们的方法是在单张RGB图像上进行操作,由于没有要求深度信息,这极大地增加了可用性。当然,深度地图也可以作为选择地包含进来调整姿态估计。首先,我们采用SSD(Single Shot Multibox Detector)目标bounding boxes和目标标识。在结果处的scence crops,我们采用我们新的三维朝向估计算法,这个算法基于先前训练过的神经网络框架。尽管深度网络也在现在的方法中使用了,我们的方法区别在于我们不是在训练中显示地从三维姿态标注中学习,而是,我们隐式从表达的三维模型视角学习表征。这由训练一个通用版本的去噪自编码器完成,使用了一种新的领域随机化策略,我们称之为增强自编码器。我们的方法有数个优点:首先,由于训练独立于SO(3)(注:三维旋转群如四元素)内物体方位的具体表征,我们能够处理由对称视角带来的模糊姿态,因为我们避免了从图像到方位一对多的建图。其次,我们学习表征在实现针对物体阻隔、不同的背景杂斑、不同环境的泛化和测试传感器的鲁棒性能上具体编码三维方位。最后,AAE(增强自编码器)不需要任何真实姿态标注训练数据。而是,它训练编码三维模型的视角采用的是自我监督的方式,克服了对大量姿态标注数据的需要。此方法的示意图概述如下图1所示:
2.相关工作
基于深度的方法(如使用点对特性(Point Pair Features)已经在各样的数据集上展示了鲁棒性的姿态估计表现,赢得了2017年的SIXD挑战塞。然而,这些方法经常依赖于很多姿态假设昂贵的计算评估,更多的,现存的深度传感器比RGB相机对光照和镜面反射更敏感。
卷积神经网络革新了RGB图像的二维物体检测。但是,相比于二维bounding box的标注,标注真实图像的6维物体姿态的努力大幅增高,这要求一定的专家知识和复杂的安装过程。尽管这样,然而大部分基于学习的姿态估计方法使用真实标注的的图像,但也因此所限于姿态标注的数据集。
因此,一些工作提出从三维模型处理过的合成图上训练,放弃了大量具有姿态标签分文不取的数据资源。然而,在合成数据上的简单训练不能典型地泛化到真实的测试数据。因此,一个主要的挑战就是连通隔开模拟视角和真实相机记录的区域隔离。
2.1模拟到真实的转换
存在三种主要的策略来实现从合成数据到真实数据的转换
图片真实化处理(Photo-Realistic Rendering)物体视角和背景已经展示了混合的泛化表现,针对像物体检测和视角估计的任务。它适用于简单的环境并能表现得很好如果能用一部分相对少量的真实标注图像联合训练。然而,图片真实化建模总是并不完美并且需要大量的努力。
领域自适应(Domain Adaptation (DA))指的是将训练数据从源领域改变为目标领域,在其中小部分标注数据(监督DA)或未标注数据(非监督DA)可以适用。生成对抗网络(GANs)靠从合成图像到训练分类器、三维姿态估计和抓去点算法真实地生成已经应用于非监督DA。然而,建立一种可靠的方法,GANs经常受限于脆弱的训练结果。监督DA能降低对真实标注数据的需要,但并不能完全脱离真实标注的数据。
领域随机化(Domain Randomization (DR))建立在一个假设上,假设模型是在各种半真实的设定(用随机光照条件、背景、饱和度等来进行增强)上处理后的视角上训练的,这也会泛化到真实图像。Tobin等证实了DR范例对使用CNNs三维形状检测的可能性。Hinterstoisser等展示了用有组织三维模型的随机合成视角来只训练FasterRCNN的头部网络,这也能很好地推广到真实图像。值得注意的是,他们的处理基本上是图片真实化处理,因为有组织的三维模型具有很高的质量。最近,Kehl等开创了一种端到端的CNN,叫做“SSD6D”,采用适度的DR策略来使用合成的训练数据以进行6维物体检测。作者处理具有组织的三维物体视角,物体是在MS COCO背景图像的上面按照随机的视角当亮度和对比度不同时重构的。这让网络推广到真实图像并能按照10HZ的频率进行6维目标检测。像我们一样,为了非常精确的距离估计他们依靠深度数据迭代最近点(ICP)来进行后处理。与之相较,我们不把三维方向估计作为一个分类问题。
2.2学习三维方位的表征
我们描述训练固定SO(3)参数化的困难将会刺激特定目标表征的学习。
回归 由于旋转存活在连续的空间,似乎很自然地直接回归固定的SO(3)参数像四元素。然而,代表性约束和姿态模糊能导致收敛问题。事实上,全三维物体方位估计的直接回归方法并没有太成功。
分类 三维目标方位需要离散化SO(3)。即使粗略地以5度为间隔也会有超过50,000可能的类别。由于每种类别在训练数据上很稀疏,这就阻碍了收敛。在SSD6D中,三维方位是被分别地分类离散化的视角和平面内的旋转来学习的。因此把复杂度减到了 。然而,对于非标准视角,例如,当一个物体从上面被观察时,视角的转换几乎可以等价于平面内旋转的改变,这就导致模棱两可的分类组合。大体上来说,当采用one-hot(一个长度为n的数组,只有一个元素是1.0,其他元素是0.0)分类时,不同方位之间的联系被忽略了。
。然而,对于非标准视角,例如,当一个物体从上面被观察时,视角的转换几乎可以等价于平面内旋转的改变,这就导致模棱两可的分类组合。大体上来说,当采用one-hot(一个长度为n的数组,只有一个元素是1.0,其他元素是0.0)分类时,不同方位之间的联系被忽略了。
对称性 依赖固定的三维方位表征时,由于会导致姿态的模棱两可(图2),对称性是一个严重的问题。如果不人为处理,同样的训练图像可能会有不同的方位标签,这将会严重地打乱学习过程。为了处理模棱两可的物体,大部分文献中的方法采用手工的方法。这种策略先是根据物体采用离散化后忽略一个轴的转动,再是训练一个额外的CNN来预测对称性。这种描述乏味,手工的方法来过滤物体对称性是很先进的,但在对待由于自遮挡(self-occlusions)和遮挡(occlusions)导致的模棱两可就很难处理了。对称性不仅影响回归和分类的方法,同样也影响任何仅仅靠固定SO(3)表征区分物体视角的基于学习的算法。
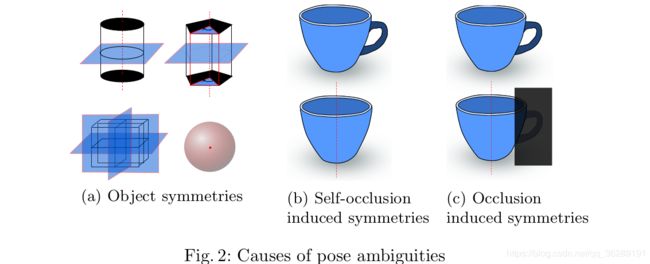
描述符学习 它能被应用于学习低维空间与物体视角相关联的表征。Wohlhart等介绍了一种使用三重损失来最小化/最大化相似/不相似物体方位之间欧式距离的基于CNN描述符学习方法。尽管混入了合成数据,训练同样以来于姿态标注的传感器数据。进一步来说,这种方法并不对对称性免疫,因为损失受控于模棱两可的看上去相同但方位相反的视角。Baltnas等靠加强描述符和姿态距离之间的特性扩展了这个工作。他们用物体在考虑姿态的深度差异性来加权姿态距离损失进而来处理物体的对称性问题。这种启发式的方法增强了对称性物体的精度。我们的工作也是基于学习描述符的方法,但是我们训练自监督增强自编码器(AAEs),它的学习过程独立于任何固定的SO(3)表征。这意味着描述符仅仅基于物体视角的外观来学习,因此,对称性的模棱两可天然地被考虑到了。分配描述符三维方位的任务只发生在训练之后。更多的,我们能禁绝使用真实标注的数据来进行训练。
Kehl等在随机RGB—D场景小块从LineMOD数据集训练了子编码器框架。在测试时,场景和目标物体小块的描述符被作为比较来查找6维姿态。由于这种方法要求很多小块的评估,每个预测大概要花670ms。进一步的,使用局部小块意味着忽略物体特征之间的整体联系,如果没有组织性,这就很致命。然而,我们是在整体物体视角上训练并显示地学习区域的不变性。
3.方法
下面,我们主要集中基于AAE的新三维方位估计技术。
3.1自编码器
原始的AE是由Hinton等介绍的,是一种对于高维数据如图像、音频或深度维度减少的技术。它包括编码器和解码器,都是可任意学习的函数逼近器,常用的就是神经网络。训练的目标是在经过低维瓶颈重建输入![]() ,作为一种隐式表示
,作为一种隐式表示![]() 。这里
。这里![]() :
:
![]() (1)
(1)
每个样本的损失简单的用像素级别的L2距离来求和。
![]() (2)
(2)
结果的隐式空间能用于非监督聚类。去噪自编码器有一个修饰的训练过程。这里,人工的随机噪声应用于输入图像,但重建目标仍要保持没有噪音,这个训练模型能应用于重建去噪测试图像。但是隐式表示是怎样被影响的呢?
假设1:去噪AE产生的隐式表征不随噪音改变,因为它促进了去噪图像的重建。
我们会证明这种训练策略不仅加强了随噪音的不变性,而且针对很多不同的输入增强也具有不变性。最后,这允许我们连通了模拟和真实数据之间的区域间隔。
3.2增强自编码器
AAE背后的动机是控制隐式表征编码和被哪些属性被忽略。我们对输入图像![]() 应用随机增强
应用随机增强![]() ,这个过程中编码应该具有不变性,重建目标方程(2)不变,(1)改为
,这个过程中编码应该具有不变性,重建目标方程(2)不变,(1)改为
![]() (3)
(3)
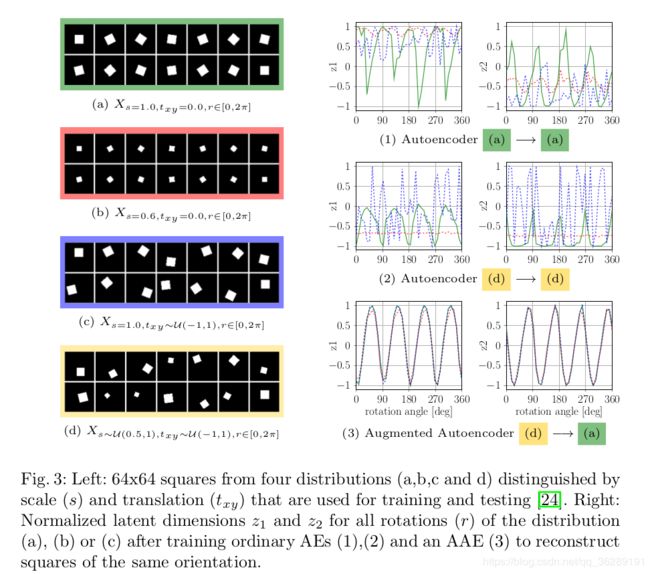
为了证明假设1适用于几何变换,我们学习二值图像的隐式表征来描述二维正方形的不同尺度,平面内的移动和旋转。我们的目标是在二维的隐式空间独立于尺度和移动只编码平面内的旋转。图3描述了在训练与图5类似的基于CNN的AE框架的结果。能观测到在固定尺度和移动上重构正方形的AE训练(1)随机尺度和移动(2)没有清楚地单独编码转动,但也同样对其他隐式因素敏感。(3)然而,AEE的编码对移动和的尺度具有不变性,所有随机方位被编码成相同的码。更多的,隐式表征更平滑,隐式维度分别模仿了一个频率为f = 2π变换的正余弦函数。原因是因为正方形有两个相互垂直的对称轴。转动90度后,正方形和之前是一样的。这种根据物体外表而不是固定参数表征方位的特点很有价值,当学习三维物体方位时避免了由于对称性造成的模棱两可。
3.3从合成物体视角中学习三维方位
我们的玩具问题展示了我们能用几何增强技术显示地学习物体平面内转动的表征。应该同样的几何输入增强手段,我们能三维物体模型(CAD或三维重建)视角的整个SO(3)空间,并能对不精确的物体检测具有鲁棒性。然而,编码器仍旧不能从真实RGB传感器关联图像crops,因为(1)三维模型和真实物体具有差异,(2)模拟和真实光线条件有差异,(3)网络不能从背景聚类和前景阻隔中区分物体。而不是在模拟中试图模仿每个真实传感器记录细节,我们在AAE框架中提出了一种区域随机化(DR)技术来使不重要环境和传感器差异的编码具有编码不变性。目标是训练后的编码器把与真实相机图像的差异当作是另一类无关的差异。因此,当保持重建目标干净,我们随机地对输入训练视角采用额外的增强技术:(1)用随机光线位置、随机散射和镜面反射处理(OpenGL中简单的Phong模型),(2)从Pascal VOC数据集插入随机的背景图像,(3)采用不同的图像对比度、亮度、高斯模糊和颜色扭曲,(4)采用随机的物体面具或黑正方形进行阻隔。图4描述了T-LESS中物体5合成视角的事例性训练过程。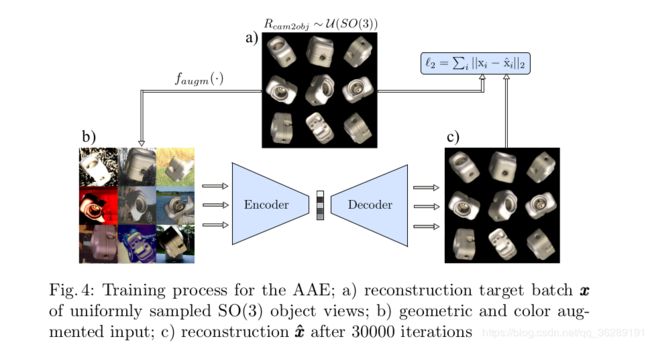
3.4网络框架和训练细节
我们实验中用到的卷集自编码框架描述在图5中,我们使用一个从像素方面引导的L2损失,它用最大误差只在像素方面计算(每张图片的引导因素b=4)。因此,好的细节要重建并且训练并不能收敛到局部最小。使用OpenGL,我们对每个物体沿着相机轴随机的三维方位和恒定距离(700mm)上处理了20,000个视角。最后的图片被平方剪裁调整为128x128x3.所有几何和颜色输入增强,除了用随机光线处理之外,都是在以均匀强度进行随机训练时在线被应用的,这些参数见附录。我们使用学习率为2x10-4的Adam优化器,Xavier初始化,batch size为64,30000次迭代耗费大约4个小时在单个Nvidia Geforce GTX 1080上。

3.5代码本创建和测试程序
在训练之后,AAE能从很多不同相机传感器的真实场景分割中提取三维物体(图8)。解码器重建的清晰度和方向是编码质量的一种指示。为了从测试场景crops中决定三维物体方位,我们创建了一个代码本(codebook):
(1)距全球体视角同等距离的视点上处理干净、合成的物体视角(基于改良的十二面体)。
(2)在平面内固定的间隔转动每个视角来覆盖整个SO(3)
(3)靠对所有产生图像生成隐码![]() 并分配对应的旋转矩阵
并分配对应的旋转矩阵![]() 来创建codebook
来创建codebook
在测试时,被考虑的物体首先在RGB场景中被检测。区域被平方剪裁并调整尺寸来匹配编码输入尺寸。在编码之后,我们计算从codebook的测试码![]() 和所有码
和所有码![]() 中计算余弦相似性:
中计算余弦相似性:
![]() (4)
(4)
最高的相似性由KNN搜索算法决定,codebook中对应的旋转矩阵返回作为三维物体方位的估计。我们使用余弦相似性是因为:(1)即使对于非常大的codebook,它也能非常有效地在单个GPU上计算。在我们的实验中,我们有2562个等距离的视点x36个平面内的旋转=92232总数个条目。(2)我们观察到,可能由于旋转的循环特性,扩展隐式测试码没有改变解码器重建的物体方位。

3.6扩展到6维物体检测
训练物体检测器。我们调整以VGG16为基础的SSD,使用LineMOD and T-LESS训练数据集提供的不同视点黑色背景的物体记录。我们也训练了用ResNet50为主的RetinaNet,尽管慢一些但精度更高。多个物体在同一场景中按照随机的方位、尺度和移动被复制下来。bounding box的标签相应地做出了调整。至于AAE,黑色背景被Pascal VOC中的图像给替代掉了。在训练的60000场景中,我们使用各种不同的颜色和几何增强手段。
投影距离估计。我们从相机到物体中心估计整个三维移动![]() 。因此,对于每个codebook中的合成物体视角,我们保留它二维bounding box的对角线长度
。因此,对于每个codebook中的合成物体视角,我们保留它二维bounding box的对角线长度![]() 。在测试时,我们计算被检测bounding box的长度
。在测试时,我们计算被检测bounding box的长度![]() 和对应在相似方位codebook对角线长度
和对应在相似方位codebook对角线长度![]() 的比率。针孔相机模型满足距离估计
的比率。针孔相机模型满足距离估计
![]() (5)
(5)
使用合成处理的距离![]() ,和测试传感器和合成视角的焦点长度
,和测试传感器和合成视角的焦点长度![]() ,
,![]() ,我们有
,我们有
(6)
主点![]() ,
,![]() 和bounding box的中心
和bounding box的中心![]() ,
,![]() ,对于不同的测试函数,我们能预测三维移动。
,对于不同的测试函数,我们能预测三维移动。
ICP 细节化。可选的,采用标准的ICP方法用深度数据调整估计花费大约200ms在cpU上,细节见附录。
推理时间。带有VGG16的SSD和31个类别以及大小为92232x128的codebook的AAE超过了表1描述的平均推理时间。我们推断基于RGB系统在Nvidia GTX 1080大约42Hz是实时能行的。这使增强现实和机器人应用成功并为跟踪算法留下了空间。多目标编码并将对应codebooks插入GPU内存,使得多目标姿态估计成为可行。
4.评估
我们在T-LESS和LineMOD数据集上评估AAE和整个6维检测系统。例子能才附录中找到。
4.1测试条件
很少有基于RGB的姿态估计方法仅仅依赖于三维模型信息。大部分方法采用真实姿态标注信息,并经常训练和测试在相同的场景下(在稍微不同的视点下)忽略平面内的转动或仅仅考虑出现在数据集中的目标姿态是通例,但这限制了它的应用性。对称性物体的视角经常单独对待或者忽略。SIXD挑战试图靠禁止使用测试场景的像素来让6维局部算法之间能公平比较。我们根据这些严格的评估指南,但针对更难的6维检测问题,这个问题中并不知道哪个被考虑的物体出现在场景中。这在T-LESS数据集上,由于物体非常相似,使其研究更加困难。
4.2-4.3略
4.4 6维物体检测
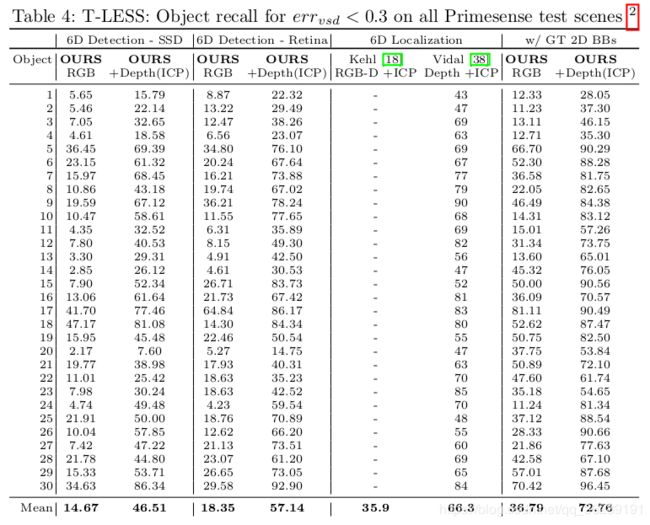
首先,我们给出了仅仅基于RGB的结果,包括2维检测,三维方位估计和投影距离估计。尽管这些结果在外表上看来很吸引人,距离估计采用了一种简单的基于云的ICP结合先进的基于深度的方法来进行调整。表格4展示了T-LESS数据集所有场景的6维检测估计,包含很多姿态不确定性。我们调整的结果比Kehl等最近小部分描述符的方法更为出色。尽管他们只是做了6维局部的部分。Vidal等先进的工作(考虑SIXD挑战的平均精度)表现出一个由于姿态假设消耗时间的搜索算法(平均每个物体4.9s)。我们的方法取得了可比较的精度,并且更具有效率。表格4右边部分展示了ground truth bounding boxes在姿态估计上产生了一个上限的结果。附录展示了一些失败的案例,大部分是由于受到确实检测或强阻隔的影响。在表格5中,我们在LineMOD数据集上比较了我们的方法和最近提出的SSD6D和其他方法。SSD6D也是在三维模型的合成视角上训练的,但是他们的表现非常依赖于精致的occlusion-aware,投影ICP调整步骤。我们基本的ICP有时会在临近区域收敛到具有类似形状的物体。在RGB领域,我们的方法比SSD6D更优异。

5 结论
我们提出了一种新的自监督训练策略,采用的是AE框架,能使在不同RGB传感器的三维物体方位估计具有鲁棒性,在训练的过程中只需要三维模型的合成视角。在AE中采用转换几何和颜色进行输入加强,我们学到表征(1)特别编码三维物体方位(2)对合成和真是RGB图像之间的区域隔离不产生差别(3)天然地处理对称物体视角带来的姿态不确定性。通过这种方法,我们创造了一种实时(42fps),基于RGB的6维物体检测系统,特别适用于姿态标注RGB传感器数据不足的情况。
致谢 略