springboot集成spark,ETL demo
1.依赖
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.1.5.RELEASE
com.springboot.spark
spark
0.0.1-SNAPSHOT
spark
Demo project for Spring Boot
1.8
2.4.5
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-test
test
org.projectlombok
lombok
true
org.apache.spark
spark-core_2.12
${spark.version}
org.slf4j
slf4j-log4j12
org.apache.spark
spark-sql_2.12
${spark.version}
org.apache.spark
spark-streaming_2.12
${spark.version}
mysql
mysql-connector-java
5.1.37
runtime
org.springframework.boot
spring-boot-maven-plugin
2.application.yml
spring:
application:
name: springboot-spark
server:
port: 8088
#sparkconfig配置
spark:
appName: ${spring.application.name}
master: local #spark://192.168.203.132:7077连接不上
sparkHome: 1
3.spring bean配置
package com.springboot.spark.config;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SparkSession;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
*
* Description: TODO
*
*
* @author majun
* @version 1.0
* @date 2020-03-08 02:01
*/
@Configuration
public class SparkConfig {
@Bean
@ConfigurationProperties(prefix = "spark")
public SparkConf getSparkConfig() {
return new SparkConf()
.set("spark.executor.memory","512m")
.set("spark.driver.memory","512m");
}
@Bean
public JavaSparkContext getSparkContext() {
return new JavaSparkContext(getSparkConfig());
}
@Bean
public SparkSession sqlContext() {
return new SparkSession(getSparkContext().sc());
}
}
4.抽象job
package com.springboot.spark.core;
import lombok.extern.slf4j.Slf4j;
import org.apache.spark.api.java.JavaSparkContext;
import org.springframework.beans.factory.annotation.Autowired;
@Slf4j
public abstract class AbstractSparkJob{
@Autowired
private JavaSparkContext sparkContext;
protected abstract void execute(JavaSparkContext sparkContext, String[] args);
protected void close(JavaSparkContext javaSparkContext) {
javaSparkContext.close();
}
public void startJob(String[] args) {
this.execute(sparkContext, args);//继承并实现该方法
this.close(sparkContext);
}
}
5.WordCount demo & ELT demo
package com.springboot.spark.job;
import com.springboot.spark.core.AbstractSparkJob;
import org.apache.spark.api.java.JavaSparkContext;
import org.mortbay.util.ajax.JSON;
import org.springframework.stereotype.Component;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
@Component
public class WordCountJob extends AbstractSparkJob {
@Override
public void execute(JavaSparkContext sparkContext,String[] args) {
//读取文件wordcount后输出
List> topK = sparkContext.textFile(args[1])
.flatMap(str -> Arrays.asList(str.split("\n| ")).iterator())
.mapToPair(word -> new Tuple2(word, 1))
.reduceByKey((integer1, integer2) -> integer1 + integer2)
.filter(tuple2 -> tuple2._1.length() > 0)
.mapToPair(tuple2 -> new Tuple2<>(tuple2._2, tuple2._1)) //单词与频数倒过来为新二元组,按频数倒排序取途topK
.sortByKey(false)
.take(10);
for (Tuple2 tuple2 : topK) {
System.out.println(JSON.toString(tuple2));
};
sparkContext.parallelize(topK).coalesce(1).saveAsTextFile(args[2]);
}
}
package com.springboot.spark.core;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions;
import org.apache.spark.storage.StorageLevel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.Properties;
@Component
public class ETLServiceDemo {
@Autowired
private SparkSession session;
@PostConstruct
public void etl() throws Exception {
//原表
Properties prod = new Properties();
prod.put("user", "root");
prod.put("password", "123456");
prod.put("driver", "com.mysql.jdbc.Driver");
// 落地表配置
Properties local = new Properties();
local.put("user", "root");
local.put("password", "123456");
local.put("driver", "com.mysql.jdbc.Driver");
writeLive(prod, local, session);
}
public void writeLive(Properties prod, Properties local, SparkSession session) {
long start = System.currentTimeMillis();
Dataset d1 = session.read().option(JDBCOptions.JDBC_BATCH_FETCH_SIZE(), 1000).jdbc("jdbc:mysql://192.168.203.132:3306/test1?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8", "user", prod)
.selectExpr("id", "user_name", "password")
.persist(StorageLevel.MEMORY_ONLY_SER());
d1.createOrReplaceTempView("userTemp");
//从临时表中读取数据
Dataset d2 = session.sql("select * from userTemp");
//讲读取到内存的表处理后再次写到mysql中 local 配置为 目的库配置
d2.write().mode(SaveMode.Append).option(JDBCOptions.JDBC_BATCH_INSERT_SIZE(), 1000).jdbc("jdbc:mysql://192.168.203.132:3306/test2?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8", "user", local);
long end = System.currentTimeMillis();
System.out.println("耗时--->>>>" + (end - start) / 1000L);
//运行完后释放内存
d1.unpersist(true);
d2.unpersist(true);
}
}
6.如何启动,启动implements CommandLineRuner ,run方法接受到main方法启动参数
的args[0] 即bean name从bean容器找到job对象执行startJob方法。启动时会先初始化spring 容器,然后运行CommandLineRuner.run()运行完后退出jvm. 即ELT demo->Word Count demo ->退出
package com.springboot.spark;
import com.springboot.spark.core.AbstractSparkJob;
import org.apache.spark.util.Utils;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.support.ApplicationObjectSupport;
@SpringBootApplication
public class SparkApplication extends ApplicationObjectSupport implements CommandLineRunner {
public static void main(String[] args) {
SpringApplication.run(SparkApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
String className = args[0];
Class clazz = Utils.classForName(className);
Object sparkJob = this.getApplicationContext().getBean(clazz);
if (sparkJob instanceof AbstractSparkJob ){
((AbstractSparkJob) sparkJob).startJob(args);
}else {
logger.error("你指定的启动job类"+className+"不存在");
}
}
}
idea启动指定main方法参数
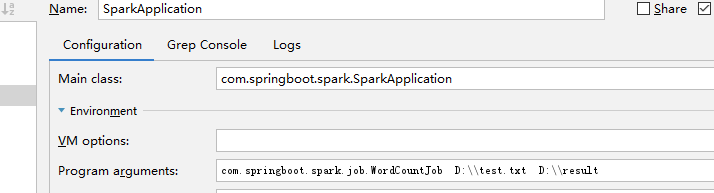
linux启动:java -jar spark-0.0.1-SNAPSHOT.jar com.springboot.spark.job.WordCountJob /root/test.txt /root/result
7.存在的问题
springboot项目使用spark-submit启动不了。使用java -Dspark.master=spark://192.168.203.132:7077 -jar spark-0.0.1-SNAPSHOT.jar com.springboot.spark.job.WordCountJob /root/test.txt /root/result ,指定了spark.master=spark://192.168.203.132:7077以便在dashboard能监控到job执行情况,但是假如该参数后显示连接成功但实际并不能连接成功。netstat -ntlp|grep 7077 可见正常监听,spark进程修改监听0.0.0.0无用
