jiaba库之关键词提取(增量更新自定义语料)
一、提取语句关键词
在自然语言处理中,经常会遇见对文章或者信件进行关键词提取。而jiaba库正给我们提供了两种简单的关键词提取方法(TF-idf与TextRank)。本文不讲这两方式提取关键词的原理,只注重如何实现。在Python中,短短四个语句就能实现关键词的提取,我们所使用的文本数据为《红楼梦》中的某个章节。
第二回 贾夫人仙逝扬州城 冷子兴演说荣国府
诗云
一局输赢料不真,香销茶尽尚逡巡。欲知目下兴衰兆,须问旁观冷眼人。
却说封肃因听见公差传唤,忙出来陪笑启问。那些人只嚷:“快请出甄爷来!”封肃忙陪笑道:“小人姓封,并不姓甄。只有当日小婿姓甄,今已出家一二年了,不知可是问他?”那些公人道:“我们也不知什么。真假,因奉太爷之命来问,他既是你女婿,便带了你去亲见太爷面禀,省得乱跑。”说着,不容封肃多言,大家推拥他去了。封家人个个都惊慌,不知何兆。
那天约二更时,只见封肃方回来,欢天喜地。众人忙问端的。他乃说道:“原来本府新升的太爷姓贾名化,本贯胡州人氏,曾与女婿旧日相交。方才在咱门前过去,因见娇杏那丫头买线,所以他只当女婿移住于此。我一一将原故回明,那太爷倒伤感叹息了一回,又问外孙女儿,我说看灯丢了。太爷说:不妨,我自使番役务必探访回来。说了一回话,临走倒送了我二两银子。”甄家娘子听了,不免心中伤感。一宿无话。至次日,早有雨村遣人送了两封银子,四匹锦缎,答谢甄家娘子,又寄一封密书与封肃,转托问甄家娘子要那娇杏作二房。封肃喜的屁滚尿流,巴不得去奉承,便在女儿前一力撺掇成了,乘夜只用一乘小轿,便把娇杏送进去了。雨村欢喜,自不必说,乃封百金赠封肃,外谢甄家娘子许多物事,令其好生养赡,以待寻访女儿下落。封肃回家无话。
却说娇杏这丫鬟,便是那年回顾雨村者。因偶然一顾,便弄出这段事来,亦是自己意料不到之奇缘。谁想他命运两济,不承望自到雨村身边,只一年便生了一子,又半载,雨村嫡妻忽染疾下世,雨村便将他扶侧作正室夫人了。正是:
偶因一着错,便为人上人。原来,雨村因那年士隐赠银之后,他于十六日便起身入都,至大比之期,不料他十分得意,已会了进士,选入外班,今已升了本府知府。虽才干优长,未免有些贪酷之弊,且又恃才侮上,那些官员皆侧目而视。不上一年,便被上司寻了个空隙,作成一本,参他生情狡猾,擅纂礼仪,大怒,即批革职。该部文书一到,本府官员无不喜悦。那雨村心中虽十分惭恨,却面上全无一点怨色,仍是嘻笑自若,交代过公事,将历年做官积的些资本并家小人属送至原籍,安排妥协,却是自己担风袖月,游览天下胜迹。
那日,偶又游至维扬地面,因闻得今岁鹾政点的是林如海。这林如海姓林名海,表字如海,乃是前科的探花,今已升至兰台寺大夫,本贯姑苏人氏,今钦点出为巡盐御史,到任方一月有余。
原来这林如海之祖,曾袭过列侯,今到如海,业经五世。起初时,只封袭三世,因当今隆恩盛德,远迈前代,额外加恩,至如海之父,又袭了一代;至如海,便从科第出身。虽系钟鼎之家,却亦是书香之族。只可惜这林家支庶不盛,子孙有限,虽有几门,却与如海俱是堂族而已,没甚亲支嫡派的。今如海年已四十,只有一个三岁之子,偏又于去岁死了。虽有几房姬妾,奈他命中无子,亦无可如何之事。今只有嫡妻贾氏,生得一女,乳名黛玉,年方五岁。夫妻无子,故爱如珍宝,且又见他聪明清秀,便也欲使他读书识得几个字,不过假充养子之意,聊解膝下荒凉之叹。
- 利用jieba库对该段文字进行关键词提取
import pandas as pd
from jieba.analyse import extract_tag, textrank
text = pd.read('hongloumeng.csv')
# 使用tfidf进行关键词提取
for keyword, weight in extract_tags(text, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
# 使用textrank进行关键词提取
for keyword, weight in textrank(text, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))
- 结果展示
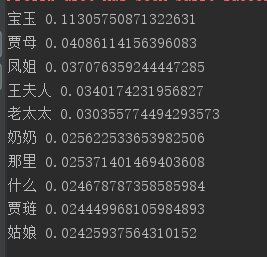
- 常见参数解释
1>topn: 返回关键词的个数,默认为10
2>withWeight: 是否返回权重, 默认为False
3>allowPOS: 对关键词的词性进行限制, 默认为(),即不设限制 - 思考
我们都知道,基于TF-IDF的关键词提取,需要对每个词语计算IDF值,而IDF值是逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到,那么只有一篇文章是如何计算IDF值的呢?
二、自定义语料库
经过上面的思考,发现其实jieba库自带了一些语料库,它是基于自身的语料库来计算IDF值的。那么,如果我们在一些特定的场合,需要自定义语料来提高关键词的合理性,应当如何实现呢?jieba库给我们提供了特定的接口用于自定义语料。
from jieba.analyse import set_idf_path
jieba.analyse.set_idf_path('word_idf.txt')
这个word_idf.txt的形式如下图所示:

第一列为词语,第二列为对应的IDF值。
- 思考
当我们用自定义语料进行关键词提取时, 随着文章数的不断增多,应如何实现word_idf.txt的增量更新呢?
三、自定义语料word_idf.txt的计算与更新
- 数据预处理
import re
import jieba
# 对文章进行分词
corpus_new['corpus'] = corpus_new['corpus'].apply(jieba.lcut)
# 过滤停用词\长度小于1的词\非中文词
pattern = re.compile(u'[\u4e00-\u9fa5]+') # 判断字符串是不是纯中文
corpus_new['corpus'] = corpus_new['corpus'].apply(
lambda cut_words: [word for word in cut_words if word not in stop_word and len(word) > 1 and pattern.search(word)])
- 计算并增量更新IDF值
# 对每篇文章结果进行去重
add_corpus = corpus_new['corpus'].apply(lambda s: list(set(s)))
# 获取所有的分词结果
add_word = []
for i in add_corpus.index:
add_word += add_corpus[i]
add_word = set(add_word)
# 构造字典用于存放IDF值
path_num = os.path.join(r"C:\Users\asus\Desktop", 'num_dict.txt')
try:
# 先读取上次结果, 若不存在则重新构造
dict_df = pd.read_csv(path_num, encoding='gbk', sep=' ', header=None, names=['word', 'idf'])
dic = dict(zip(dict_df['word'], dict_df['idf']))
except Exception as e:
# 新构造的字典初始值全为0
dic = dict(zip(add_word, [0] * len(add_word)))
# 计算IDF值
# 1.更新出现每个词文章的数目
for i in add_corpus.index:
for word in add_corpus[i]:
try:
dic[word] += 1
except:
dic[word] = 1
# 2.保存次数,用于下一次的增量更新
file = open(path_num, 'w', encoding='utf-8')
for key, value in dic.items():
try:
text = key + ' ' + str(value) + '\n'
file.write(text)
except Exception as e:
print(e)
file.close()
# 3.计算IDF值
path_idf = os.path.join(r"C:\Users\asus\Desktop", "idf_dict.txt")
n = corpus_new.shape[0] # 文章总数
idf_dic = {key: math.log(n / value, 10) for key, value in dic.items()}
# 保存,添加到结巴的提取关键词词库
file = open(path_idf, 'w', encoding='utf-8')
for key, value in idf_dic.items():
try:
text = key + ' ' + str(value) + '\n'
file.write(text)
except Exception as e:
print(e)
file.close()
- 需要注意的点
1.计算出现每个关键词的文章数的时候,需要对文章的分词结果进行去重;但是在之后进行关键词提取的时候,则不能对分词结果去重,因为需要计算TF值;
2.在实现增联更新的时候,不能读取之前存储的word_idf.txt, 而应该读取word_num.txt,因为idf值无法返回到每个关键词出现的文章数,无法进行迭代更新;
3.在写入txt文件时, 字典的值为数值型,应转化为字符型。
四、以上代码整合如下
def get_keyword(corpus_new, stop_word):
"""
按照TFIDF提取关键词
:param corpus_new: 包含文章的数据框
:param stop_word: 停用词
:return: 一个数据框包含文章的关键词
"""
pattern = re.compile(u'[\u4e00-\u9fa5]+') # 判断字符串是不是纯中文
corpus_new['corpus'] = corpus_new['corpus'].apply(jieba.lcut).fillna('')
# 过滤停用词
corpus_new['corpus'] = corpus_new['corpus'].apply(
lambda cut_words: [word for word in cut_words if len(word) > 1 and pattern.search(word)])
# 对每篇文章的分词结果去重
add_corpus = corpus_new['corpus'].apply(lambda s: list(set(s)))
# 获取所有的分词结果
add_word = []
for i in add_corpus.index:
add_word += add_corpus[i]
add_word = set(add_word)
# 构造字典,用于存放包含某个词汇文档的数量
path_num = os.path.join(r"C:\Users\asus\Desktop", 'num_dict.txt')
try:
# 先读取上次结果, 若不存在则重新构造
dict_df = pd.read_csv(path_num, encoding='gbk', sep=' ', header=None, names=['word', 'idf'])
dic = dict(zip(dict_df['word'], dict_df['idf']))
except Exception as e:
dic = dict(zip(add_word, [0] * len(add_word)))
# 更新出现每个词文章的数目
for i in add_corpus.index:
for word in add_corpus[i]:
try:
dic[word] += 1
except:
dic[word] = 1
# 保存次数,用于下一次的增量更新
file = open(path_num, 'w', encoding='utf-8')
for key, value in dic.items():
try:
text = key + ' ' + str(value) + '\n'
file.write(text)
except Exception as e:
print(e)
file.close()
path_idf = os.path.join(r"C:\Users\asus\Desktop", "idf_dict.txt")
# 计算idf值
n = corpus_new.shape[0]
idf_dic = {key: math.log(n / value, 10) for key, value in dic.items()}
# 保存,添加到结巴的提取关键词词库
file = open(path_idf, 'w', encoding='utf-8')
for key, value in idf_dic.items():
try:
text = key + ' ' + str(value) + '\n'
file.write(text)
except Exception as e:
print(e)
file.close()
# 设置自定义语料
jieba.analyse.set_idf_path(path_idf)
# 提取关键词
corpus_new['keyword'] = corpus_new['corpus'].apply(
lambda s: jieba.analyse.extract_tags(' '.join(s), topK=5, allowPOS=()))
return corpus_new
过程有一点繁琐,如果有更好的方法,欢迎大家一起交流呀。