keras集成学习一
keras集成学习一
- 集成学习的概念
- Individual Learner 个体学习器
- Aggregator 结合模块
- Bagging法集成学习的基本流程
- 生成数据集
- 训练个体学习器神经网络
- 集成方法选择
- 平均法
- 投票法
- 学习法
- scikit_learn中的ensemble
- 运行结果
文档完整位置:https://docs.nn.knowledge-precipitation.site/ji-chu-zhi-shi/guo-ni-he/jichengxuexi-ensemble
- keras集成学习一
- keras集成学习二-回归问题
- keras集成学习三-分类问题
集成学习的概念
当数据集有问题,或者网络学习能力不足,或准确度不够时,我们可以采取集成学习的方法,来提升性能。说得通俗一些,就是发挥团队的智慧,根据团队中不同背景、不同能力的成员的独立意见,通过某种决策方法来解决一个问题。所以集成学习也称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。
下是一个简单的集成学习的示意图。
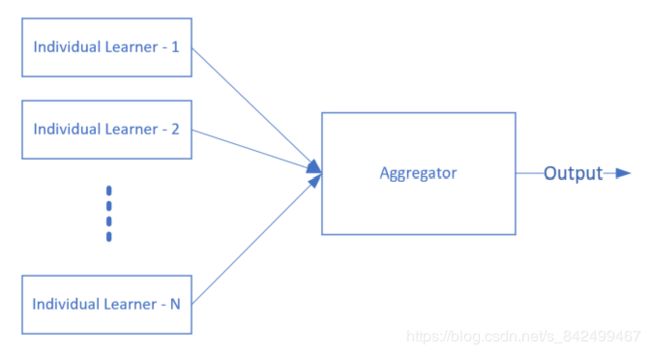
图中有两个组件:
Individual Learner 个体学习器
如果所有的个体学习器都是同一类型的学习器,即同质模式,比如都用神经网路,称为“基学习器”(base learner),相应的学习算法称为“基学习算法”(base learning algorithm)。
在传统的机器学习中,个体学习器可以是不同的,比如用决策树、支持向量机等,此时称为异质模式。
Aggregator 结合模块
个体学习器的输出,通过一定的结合策略,在结合模块中有机结合在一起,可以形成一个能力较强的学习器,所以有时称为强学习器,而相应地称个体学习器为弱学习器。
个体学习器之间是否存在依赖关系呢?这取决于产生个体学习器的方法:
- Boosting系列算法,一系列的个体学习器需要一个个地串行生成,有前后依赖关系。
- Bagging算法和随机森林算法(Random Forest),个体学习器可以独立或并行生成,没有依赖关系。
我们只讨论使用神经网络的同质个体学习方法,和Bagging集成算法。由于神经网络的复杂性,即使使用相同的网络参数,由于初始化的不同或者训练数据的不同,也可以得到差别很大的模型。
Bagging法集成学习的基本流程
下是Bagging集成学习的示意图。
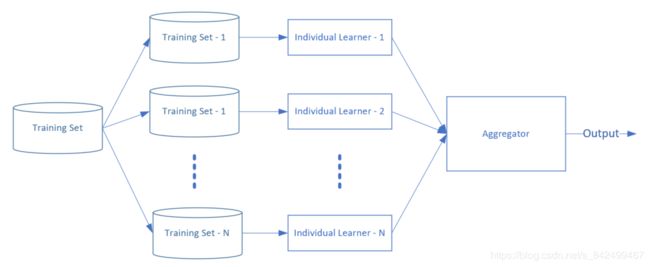
- 首先是数据集的使用,采用自助采样法(Bootstrap Sampling)。假设原始数据集Training Set中有1000个样本,我们从中随机取一个样本的拷贝放到Training Set-1中,此样本不会从原始数据集中被删除,原始数据集中还有1000个样本,而不是999个,这样下次再随机取样本时,此样本还有可能被再次选到。如此重复m次(此例m=1000),我们可以生成Training Set-1。一共重复N次(此例N=9),可以得到N个数据集。
- 然后搭建一个神经网络模型,可以参数相同。在N个数据集上,训练出N个模型来。
- 最后再进入Aggregator。N值不能太小,否则无法提供差异化的模型,也不能太大而带来训练模型的时间花销,一般来说取5到10就能满足要求。
生成数据集
def GenerateDataSet(count=9):
mdr = MnistImageDataReader(train_image_file, train_label_file, test_image_file, test_label_file, "vector")
mdr.ReadLessData(1000)
for i in range(count):
X = np.zeros_like(mdr.XTrainRaw)
Y = np.zeros_like(mdr.YTrainRaw)
list = np.random.choice(1000,1000)
k=0
for j in list:
X[k] = mdr.XTrainRaw[j]
Y[k] = mdr.YTrainRaw[j]
k = k+1
# end for
np.savez("level6_" + str(i)+".npz", data=X, label=Y)
# end for
在上面的代码中,我们假设只有1000个手写数据样本,用np.random.choice(1000,1000)函数来可重复地选取1000个数字,分别取出对应的图像数据X和标签数据Y,命名为level6_N.npz,N=[1,9],保存到9个npz文件中。
假设数据集中有m个样本,这样的采样方法,某个样本在第一次被选择的概率是1/m,那么不被选择的概率就是1-1/m,则选择m次后,不被采样到的概率是 ( 1 − 1 m ) m (1-\frac{1}{m})^m (1−m1)m,取极限值:
lim m → ∞ ( 1 − 1 m ) m ≃ 1 e = 0.368 \lim_{m \rightarrow \infty} (1-\frac{1}{m})^m \simeq \frac{1}{e} = 0.368 m→∞lim(1−m1)m≃e1=0.368
即,对于一个新生成的训练数据集来说,原始数据集中的样本没有被使用的概率为36.8%。
训练个体学习器神经网络
这一步很简单,依然用我们在Level0中的过拟合网络,来训练9个神经网络。为了体现“弱学习器”的概念,我们可以在训练每个神经网络时,只迭代10个epoch。
nets = []
net_count = 9
for i in range(net_count):
dataReader = LoadData(i)
net = train(dataReader)
nets.append(net)
上述代码在一个9次的循环中,依次加载我们在前面生成的9个数据集,把训练好的9个net保存到一个列表中,后面测试时使用。
集成方法选择
平均法
在回归任务中,输出为一个数值,可以使用平均法来处理多个神经网络的输出值。下面公式中的 h i ( x ) h_i(x) hi(x)表示第i个神经网络的输出, H ( x ) H(x) H(x)表示集成后的输出。
- 简单平均法:所有值加起来除以N。 H ( x ) = 1 N ∑ i = 1 N h i ( x ) H(x)=\frac{1}{N} \sum_{i=1}^N h_i(x) H(x)=N1i=1∑Nhi(x)
- 加权平均法:给每个输出值一个人为定义的权重。 H ( x ) = ∑ i = 1 N w i ⋅ h i ( x ) H(x)=\sum_{i=1}^N w_i \cdot h_i(x) H(x)=i=1∑Nwi⋅hi(x)
权重值如何给出呢?假设第一个神经网络的准确率为80%,第二个为85%,我们可以令:
w 1 = 0.8 w1=0.8 w1=0.8
w 2 = 0.85 w2=0.85 w2=0.85
这样准确率高的网络会得到较大的权重值。
投票法
对于分类任务,将会从类别标签集合 c 1 , c 2 , . . . , c n {c_1, c_2, ...,c_n} c1,c2,...,cn中预测出一个值,多个神经网络可能会预测出不一样的值,此时可以采样投票法。
-
绝对多数投票法(majority voting)
当有半数以上的神经网路预测出同一个类别标签时,我们可以认为此预测有效。如果少于半数,则可以认为预测无效。
比如9个神经网络,5个预测图片上的数字为7,则最终结果就是7。如果有4个神经网络预测为7,3个预测为4,2个预测为1,则认为预测失败。
-
加权投票法(weighted voting)
与加权平均法类似。
-
相对多数投票法(plurality voting)
即得票最多的标签获胜。如果有多个标签获得相同的票数,随机选一个。
我们在代码中使用了相对多数投票法,具体过程如下。
假设9个神经网络对于同一张图片的预测结果为表16-5所示。
表16-5 9个神经网络对某张图片的预测结果
| 神经网络ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 预测输出 | 7 | 4 | 7 | 4 | 7 | 7 | 9 | 7 | 7 |
可以看到,在9个结果中,有6个结果预测为7,2个预测为4,1个预测为9,我们选择多数投票法,最终的预测结果为7。
为了验证真实的准确率,我们可以用MNIST的测试集中的10000个样本,来测试这9个模型,得到10000行上面表格中的数据,最后再统计最终的准确率。
此处代码比较复杂,最关键的一行语句是:
ra[i] = np.argmax(np.bincount(predict_array[:,i]))
先使用np.bincount得到9个神经网络的预测结果中,每个结果出现的次数,得到:
[ 0 , 1 , 0 , 0 , 2 , 0 , 0 , 6 , 0 , 1 ] [0,1,0,0,2,0,0,6,0,1] [0,1,0,0,2,0,0,6,0,1]
其含义是:数字0出现了0次,数字1出现了1次,…数字4出现了2次,…,数字7出现了6次,等等。然后再用np.argmax([0,1,0,0,2,0,0,6,0,1])得到最大的数字6的下标,结果为7。这样就可以得到9个神经网络的投票结果为该图片上的数字是7,因为有6个神经网络认为是7,占相对多数。
学习法
学习法,就是用另外一个神经网络,通过训练的方式,把9个神经网路的输出结果作为输入,把图片的真实数字作为标签,得到一个强学习器。
假设9个神经网络的表现如表16-6所示。
表16-6 9个神经网络对于原始数据集中的1000个样本的预测结果
| 神经网络ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 标签值 |
|---|---|---|---|---|---|---|---|---|---|---|
| 预测输出1 | 7 | 4 | 7 | 4 | 7 | 7 | 9 | 7 | 7 | 7 |
| 预测输出2 | 4 | 4 | 7 | 4 | 7 | 4 | 9 | 4 | 7 | 4 |
| 预测输出N | 0 | 9 | 0 | 0 | 5 | 0 | 0 | 6 | 0 | 0 |
| 预测输出1000 | 7 | 2 | 2 | 6 | 2 | 2 | 2 | 5 | 2 | 2 |
接下来我们可以建立一个两层的神经网络,输入层为9,用于接收9个神经网络的预测输出,隐层神经元数量不要大于16,输出层为10分类,标签值为上述表格中的最后一列。
scikit_learn中的ensemble

在keras中可以将模型转换为sklearn的回归或分类模型,传入sklearn的函数中。
from keras.wrappers.scikit_learn import KerasRegressor, KerasClassifier
def build_model1():
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(13, )))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='linear'))
model.compile(optimizer='adam',
loss='mean_squared_error')
return model
def build_model2():
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(784, )))
model.add(Dense(32, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
model = KerasRegressor(build_fn=build_model1, epochs=100, batch_size=64)
model._estimator_type = "regressor"
model = KerasClassifier(build_fn=build_model2, epochs=2, batch_size=64)
model._estimator_type = "classifier"
运行结果
我们使用了相对多数投票法,其测试结果为表16-7所示。
表16-7 9个神经网络的预测准确率
| 神经网络ID | 准确率 |
|---|---|
| 1 | 0.8526 |
| 2 | 0.8482 |
| 3 | 0.8438 |
| 4 | 0.8327 |
| 5 | 0.8410 |
| 6 | 0.8452 |
| 7 | 0.8443 |
| 8 | 0.8397 |
| 9 | 0.8389 |
9个神经网络的准确率如上表所示,最大的为0.8526,最小的为0.8327。用投票法得到的最后的准确率为0.8751,得到了提升,达到了集成学习的目的。
从偏差-方差的角度看,Bagging主要起到降低方差的作用。在前面我们分析过,单个学习器的过拟合是高方差造成的,我们训练多个这样的学习器,随机选择的样本数据如果分布均匀的话,每个学习器在针对单个测试样本时都会有高方差风险,从而产生泛化误差。但是由于我们拥有9个神经网络,采用集成法后,一定程度上缓解了高方差的现象。