Spark中的groupByKey,reduceByKey,combineBykey,和aggregateByKey的比较和区别
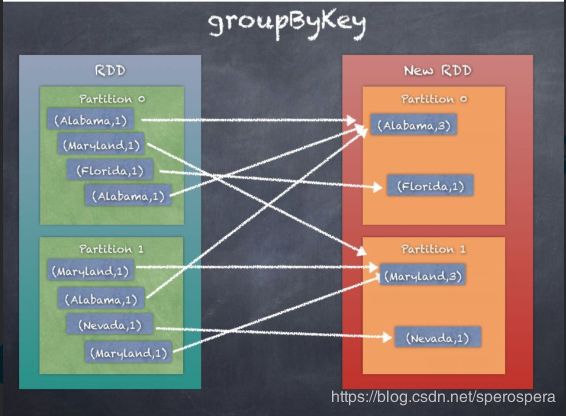
- groupByKey 按照key进行分组,得到相同key的值的sequence,可以通过自定义partitioner,完成分区,默认情况下使用的是HashPartitioner,分组后的元素的顺序不能保证,可能每一次的执行得到的结果都不相同。所有的数据需要进行shuffler,消耗资源。key-value键值对需要加载到内存中,若某个key有太多的value,可能发生OutOfMemoryError。
def groupByKey(partitioner:Partitioner) :RDD[(K,Iterable[V])]
def groupByKey(numPartitions:Int):RDD[(K,Iterable[V])]
2. reduceByKey 与groupByKey相比,通过使用local combiner先做 一次聚合运算,减少数据的shuffler,此过程和Hadoop MapReduce中的combiner作用相似。有三种方式调用:
def reduceByKey(partitioner:Partitioner,func:(V,V)=>V):RDD[(K,V)] 可以自定义partitioner,默认情况下是Hash Partitioner
def reduceByKey(func:(V,V)=>V,numPartitions:Int):RDD[(K,V)]
def reduceByKey(func:(V,V)=>V):RDD[(K,V)]

3.aggregateByKey 和reduceByKey类似,但更具灵活性,可以自定义在分区内和分区间的聚合操作,有三种调用方式:
def aggregateByKey[U:ClassTag](zeroValue:U,partitioner:Partitioner)(seqOp:(U,V)=>U,comb:(U,U)=>U):RDD[K,U]
seqOp:(U,V)=>U 和zeroValue 完成分区内计算,分区间计算通过comb:(U,U)=>U完成。
def aggregateByKey[U:ClassTag](zeroValue:U,numPartitions:Int)(seqOp:(U,V)=>U,comb:(U,U)=>U):RDD[K,U]
def aggregateByKey[U:ClassTag](zeroValue:U)(seqOp:(U,V)=>U,comb:(U,U)=>U):RDD[K,U]

4.combineByKey 与aggregateByKey类似,都调用了combineByKeyWithClassTag,在aggregateByKey中的
第一个参数是zero value,此函数的第一个参数需要提供一个初始化函数,通过第一个函数完成分区内计算,通过第二个函数完成分区间计算:
createCombiner:V=>C turns V to C ,C is an element list;
mergeValue:(C,V)=>C merge V to C by appending V to the end of the list.
mergeCombiners:(C,C)=>C to combine two Cs into one.
def combineByKey[C](createCombiner:V=>C,mergeValue:(C,V)=>C,mergeCombiners:(C,C)=>C,numPartitions:Int):RDD[(K,C)]
def combineByKey[C](createCombiner:V=>C,mergeValue:(C,V)=>C,mergeCombiners:(C,C)=>C,partitioner:Partitioner,mapSideCombine:Boolean = true,serializer:Serializer = null):RDD[(K,C)]
