分布式数据库-CrateDB架构分析与源码阅读之总体概述与架构分析
CrateDB是一个开源的HTAP(事务、分析混合型数据库)数据库,主页在crate.io ,项目开源在了github上(地址:https://github.com/crate/crate),支持SQL语言查询,支持基本的增删改查,能够快速对大规模数据进行准实时的分布式和分析。我会在这个专栏里详细介绍CrateDB的架构、常用命令、最佳实践等,并从源码角度对CrateDB的运行流程进行分析,对分布式数据库感兴趣的朋友可以了解和试用下。
CrateDB引入elastic search以及es更底层依赖的lucene模块的方式其实是抽取项目源码到crateDB中,而不是常用的通过引入jar包来依赖,这样的好处其实是保持足够的独立性和稳定性,不会因为底层依赖包的变动而造成自身的不稳(我好像默默黑了一把我厂),但是也存在可能与社区分裂的风险,如果es或者lucene出了一个crate很想要的特性,可能吸收起来就会很痛苦。
大家如果想对CreateDB有一些深入了解的话,可以看一下我的CrateDB系列文章:
分布式数据库-CrateDB架构分析与源码阅读之总体概述与架构分析 https://blog.csdn.net/u013970710/article/details/103219791
分布式数据库-CrateDB架构分析与源码阅读之常用命令 https://blog.csdn.net/u013970710/article/details/103219825
分布式数据库-CrateDB架构分析与源码阅读之搭建部署 https://blog.csdn.net/u013970710/article/details/103219820
分布式数据库-CrateDB架构分析与源码阅读之源码阅读 https://blog.csdn.net/u013970710/article/details/103219804
分布式数据库-CrateDB架构分析与源码阅读之最佳实践 https://blog.csdn.net/u013970710/article/details/103219797
分布式数据库-CrateDB架构分析与源码阅读之空间存储与空间计算 https://blog.csdn.net/u013970710/article/details/103226889
架构

CrateDB架构如上图所示,底层的storage层其实主要是基于lucence的支持,通信和分布式能力方面基于netty和elastic search,SQL层是crateDB社区自主开发的(当然也会包括一些开源组件,比如anltr parser),交互支持方面主要是添加了支持pg协议等,Enterprise层是一些企业级特性和license鉴定等。
TP能力(增删改查、事务支持)
CrateDB支持增删改查语法,与Mysql语法基本兼容,支持聚合查询groupby,支持排序order by,IN语句,但不支持exists语句,还具有丰富的函数,具有相对完整的TP能力,CrateDB并不支持完整的事务,但是写入和删除过程,会通过lucene写入translog,能够提供一定的事务支持。
AP能力(分布式数据存储、分析能力、准实时写入)
CrateDB是分布式数据库,各个节点之间按raft协议组成集群,属于share nothing架构,通过底层的elastic search和lucene支持准实时写入,能够对大数据进行快速的分析和统计。
CrateDB能够支持数据分片,支持多副本,数据的冷热分离,支持数据分区的概念,适合海量数据的存储和分析,支持通过HTTP和SQL等多种方式进行数据分析。
AdminUI
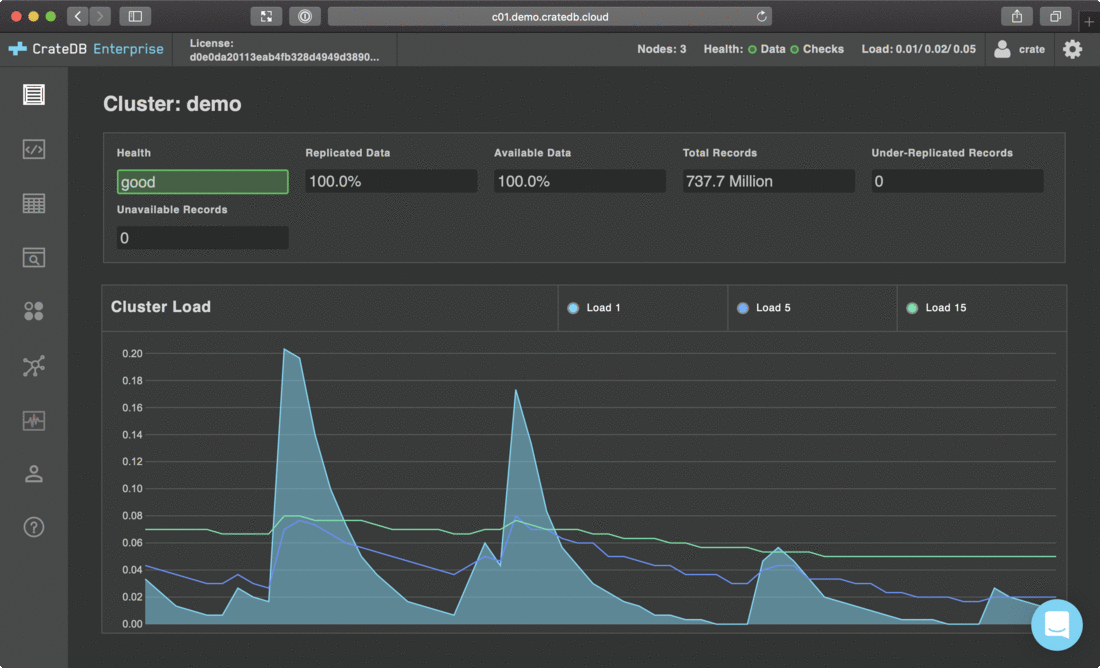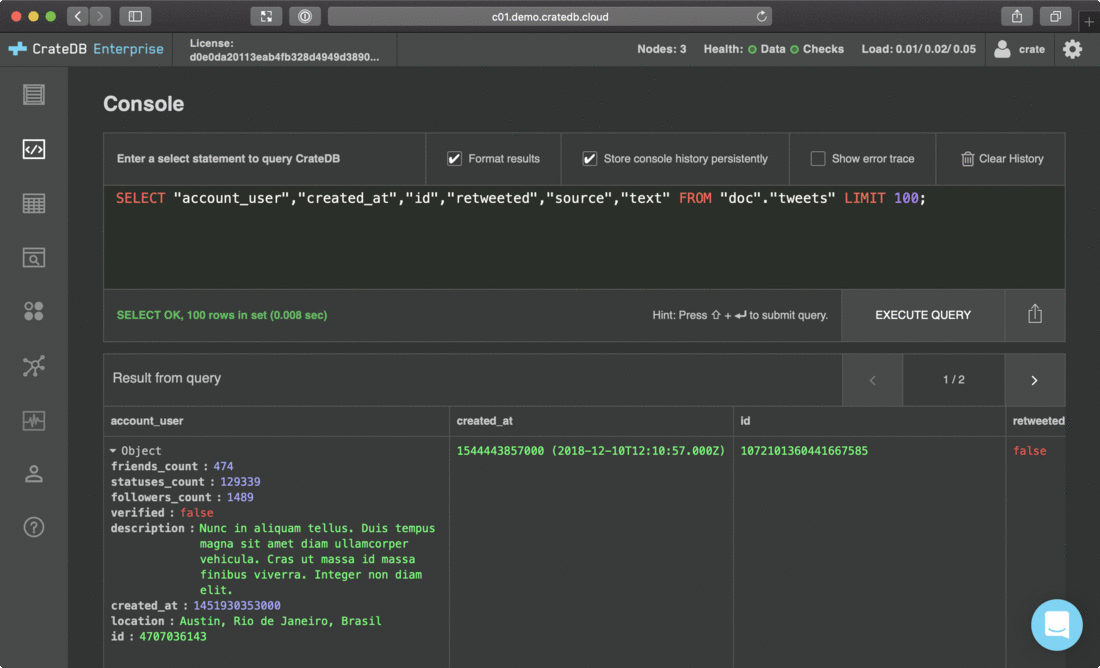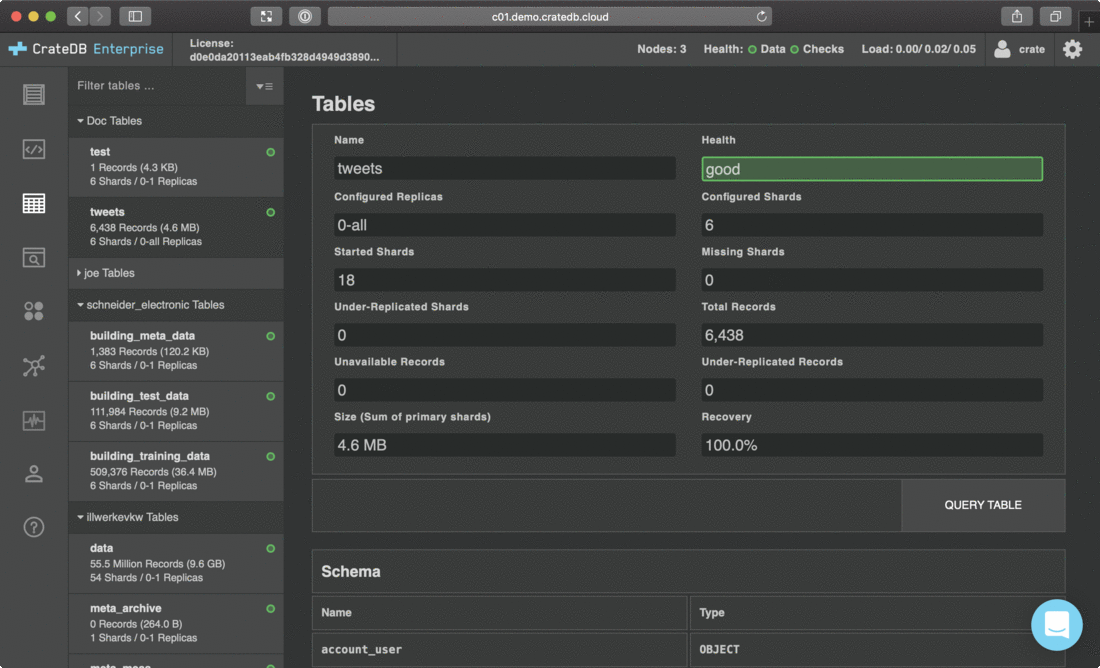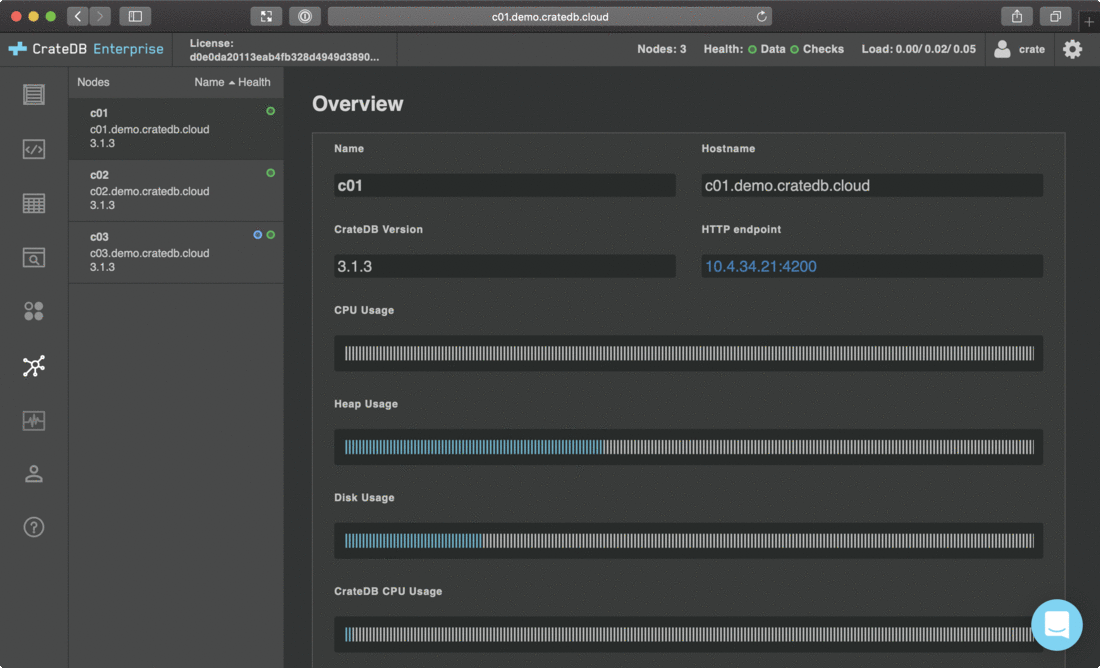
CrateDB自带AdminUI,能够通过页面提交查询,能够实时观测集群状态、堆内存使用、磁盘空间使用,能看到简单数据统计情况,新手友好。
SQL层
SQL层是CrateDB的重要模块,与经典的数据库系统的模块分布一致,包括语法解析器(sql-parser)、分析器(analyzer)、logical plan、RBO、execution plan(physical plan),熟悉数据库的朋友们可以快速上手开发。查询的具体流程也会在后面的博客中详细分析。
CrateDBSQL部分,个人看来相对于经典的SQL引擎其实还有很多不成熟的地方,比如RBO较一些开源的DBMS如postgresql还显得不成熟,比如完全没有CBO的存在。但是不得不说已经有了相对完整的TP和AP的能力,在分布式HTAP领域还是有很大的实用价值的。
存储模型
CrateDB很大程度上可以看做elastic search加上了一层sql层的封装,所以他在底层的存储模型上与elastic search基本一致。crateDB表的每个partition会存储为一个独立的文件路径,而这个partition下的多个shard与elastic search中的shard概念完全一致存储在这个partition的路径之下。每个shard在代码上对应源码里面InternalEngine,InternalEngine封装了操作lucene索引的基本操作(索引创建,flush,translog恢复等)。也就是说每个shard其实就是互相独立运行的lucene索引,它是ES处理的基本单位,可以提高并行性。
CrateDB执行查询请求时,会把查询请求下发到所有的shard上,每个shard执行自己的查询,最后汇总所有shard的执行结果。
数据在各个Shard的分配方式是:shardID = hash(routing)%shards数,其中routing代表做shards操作的路由列,cluster by routing;在cluster by操作不指定的时候,默认以_id作为路由列,进行hash。由于生成的_id往往具有足够的随机性,所以在默认情况下shard分配其实是比较均匀的,没有太大必要指定shard分配的路由列。
层次结构
这部分会介绍CrateDB的层次结构,其实与elastic search非常类似:
集群(cluster):多个单机CrateDB节点(node)通过分布式协议(raft)组成的数据库集群;
节点(node):单个CrateDB节点,可以支持完成的数据库操作;
schema:这个词我不太知道怎么翻译,就直接用英文了,有些类似于database的含义,把数据表隔离开,一个schema可以包含多个数据表;
数据表(table):CrateDB中数据表的概念,一个表可以划分为多个数据分区(partition);
数据分区(partition):可以看做是一个table被分成了多个逻辑上独立的字表。多个partition可以分布在集群的不同节点中;一个数据分区在物理上由多个数据分片(shard)组成。分区方式通过建表时通过partition by语句指定;
分片(shard):每个数据分区内部根据routing策略进一步划分为多个shards,这些shards可以分布在多个node上,在集群模式下,即使仅指定向单节点写入数据也会把数据均匀的写入到多个节点中。shards个数与并发能力、可扩展性相关。
副本(replica):crateDB同样存在副本的概念,通过在建表中指定副本个数,可以在集群中为shard建立多个副本,极大地提升了数据安全性。
大对象存储(BLOB)
CrateDB支持对于大对象的存储,用户可以通过HTTP协议上传和下载大对象。大对象(blob)存储支持http协议访问,多分片(shard),多副本,但不支持用户指定文件名存储,需要用hash值来读写。blob的存储和更新是通过底层的blobstore支持的。
用户上传大对象之前,需要预先创建一个关联的blob表,blob与常规的crate表不太一样,它只有两列digest和last_modified,用于记录上传文件的sha1值和最新修改时间,blob表是可以与常规表一起通过SQL进行关联查询的。blob files被上传之后,会被划分到不同的shards中存储,也可以方便地执行多副本防止数据丢失,适合海量数据的存储。写入时首先会根据sha1值计算应该写入哪个shards,如果本机包含该写入的shard,则直接写入,如果本机不包含对应shard,还要发送一个HTTP请求将数据发送到其他节点进行存储,查询过程与写入类似。
CrateDB总结
总体来说,作为一个HTAP数据库,CrateDB在架构上很大程度上可以看做elastic search加上了一层sql层的封装,底层关于分布式和通信的框架是与elastic search保持一致的,而在交互上增加了对于postgresql等协议支持,构建了自己的符合SQL使用方式的Admin UI。
作为一个分布式数据库框架,可以说是可以快速部署,又足够健壮可以用于生产环境。在使用上也比较方便,支持类似MySQL语法,对于大数据的查询也很高效。在大数据分析、IOT领域还是具有较高的实用价值。
大家如果想对CreateDB有一些深入了解的话,可以看一下我的CrateDB系列文章:
分布式数据库-CrateDB架构分析与源码阅读之总体概述与架构分析 https://blog.csdn.net/u013970710/article/details/103219791
分布式数据库-CrateDB架构分析与源码阅读之常用命令 https://blog.csdn.net/u013970710/article/details/103219825
分布式数据库-CrateDB架构分析与源码阅读之搭建部署 https://blog.csdn.net/u013970710/article/details/103219820
分布式数据库-CrateDB架构分析与源码阅读之源码阅读 https://blog.csdn.net/u013970710/article/details/103219804
分布式数据库-CrateDB架构分析与源码阅读之最佳实践 https://blog.csdn.net/u013970710/article/details/103219797
分布式数据库-CrateDB架构分析与源码阅读之空间存储与空间计算 https://blog.csdn.net/u013970710/article/details/103226889