一种告诉你图片里马冬梅,冬马梅分别在哪里的算法,YOLO算法2016论文笔记
写在最前面
作者Joseph Redmon是我曾经的男神。作为当时学深度学习时亮到我的文章(他的官网也是“亮”到了我),我决定第一篇论文笔记就写这篇YOLO算法论文。对于一张图像,其中的物体可能很多,如何识别其中物体是什么,在哪里,就要看这篇代表作品了。
论文名
You Only Look Once: Unified, Real-Time Object Detection
作者官网
https://pjreddie.com/
论文地址
https://pjreddie.com/media/files/papers/yolo_1.pdf
摘要渣译
我们提出了一种用于目标检测的新型算法YOLO。以往的研究工作是在目标检测工作中重新使用(训练完成的)分类器进行检测。而我们将目标检测视为一个分离边界框和组合类概率的回归问题。在一次评估中,一个单独的神经网络能直接从完整的图像中预测边界框和类概率。由于整个检测通道是一个单独的网络,可以直接从检测性能上进行端到端优化。
我们整个架构运作非常快。Base YOLO模型以每秒45帧的速度实时处理图像。该网络的一个小版本Fast YOLO处理速度达到了惊人的155帧每秒,同时mAP概念摘出1 仍然达到了其他实时检测器的两倍。与最先进的检测系统相比,YOLO产生更多的定位误差,但不太可能出现背景上的false positive概念摘出2。 最后,YOLO学习了非常一般对象的表示。 当从自然图像推广到其他领域(如艺术品)时,它优于其他检测方法,包括DPM和R-CNN。
前言
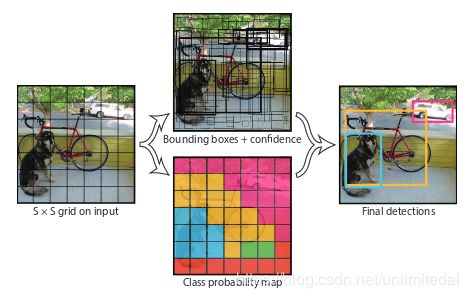
YOLO怎么运作?
The YOLO Detection System.
Processing images with YOLO is simple and straightforward.
(1) resizes the input image to 448×448
(2) runs a single convolutional net-work on the image
(3) Non-max suppression概念摘出3

也就是压缩图像大小,运行卷积神经网络,非极大值抑制。
嗯,从图片上看当时的YOLO还是个萌新方法,狗和马的识别准确度只有0.30哈哈哈
研究现状
Current detection systems repurpose classifiers to perform detection. To detect an object, these systems take a classifier for that object and evaluate it at various locations and scales in a test image.
Systems like deformable parts models (DPM) use a sliding window approach where the classifier is run at evenly spaced locations over the entire image.
More recent approaches like R-CNN use region proposal methods to first generate potential bounding boxes in an image and then run a classifier on these proposed boxes.
也就是DPM等间距地(evenly spaced)用滑窗(sliding window),而R-CNN生成可能的边界框(potential bounding boxes),然后调用分类器。
YOLO优势
(1)YOLO is extremely fast.
(2)YOLO reasons globally about the image when making predictions.
(3)YOLO learns generalizable representations of objects.
更快,更全局,更易推广。
对于第二点:
YOLO makes less than half the number of background errors compared to Fast R-CNN.
YOLO全局分析,而DPM和R-CNN更局部分析,也就是说更容易把无关的背景识别成马冬梅。
正文
网络构建
YOLO的精华之处就在于对图像的处理,进而提取出tensor进行网络的构建。
首先将一张图片分成S×S个区域(grid)。

之后每个区域设置B个边界框(bounding boxes)。每个边界框有5个属性x,y,w,h,and confiden-ce,分别是中心点x,y还有框的长宽w,h,置信度概念摘出4confidence。如果我们希望识别C类目标,那么对于一张图片可以提取成一个S×S×(5×B+C)的tensor。
当时我读到这里感觉 Σ(*゚д゚ノ)ノ CNN还能这么用!!!
文中举例,将上图分为7×7个区域,每区域两个边界框,目标种类20种,那么就可以形成一个7×7×30的tensor。网络的初始卷积层从图像中提取特征,而完全连接的层预测输出概率和坐标。
网络结构如图:
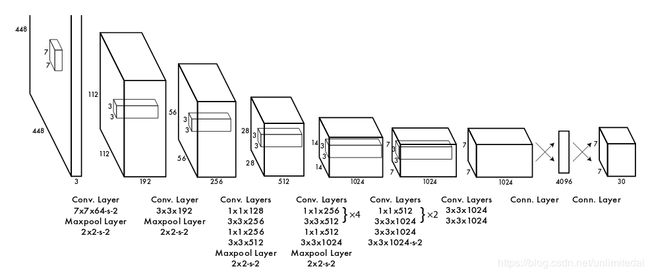
网络训练
在ImageNet 1000级竞赛数据集上预先训练网络卷积层,大约一周。网络最后一层预测类概率和边界框坐标,高低长宽(x,y,h,w)设置0-1之间,即相对区域中心点的偏移量和相对区域长宽的长度百分比。使用线性激活函数(a linear activation function)处理最终层。
在每个图像中,许多区域都不包含任何对象。这将这些单元格的“置信度”分数推向零,通常会压制包含对象的单元格的渐变。 这可能导致模型不稳定,导致训练早期出现分歧。为了解决这个问题,增加了边界框坐标预测的损失,减少了不包含对象的框的置信度预测损失。作者使用了λ去表示这个损失。
求和误差也同样可以加大大边界框和小边界框中的误差。 我们的误差度量应该反映出大边界框中的小偏差小于小边界框。 为了解决这个问题,直接预测边界框宽度和高度的平方根而不是宽度和高度.YOLO预测每个网格单元的多个边界框。在训练时间,作者只希望一个边界框预测器负责每个对象。 根据哪个预测在真实背景下具有最高当前IOU,将一个预测器指定为“负责”以预测对象。 这导致边界框预测变量之间的特化。 每个预测变量都能更好地预测某些大小,宽高比或对象类别,从而提高整体召回率。
多部分损失函数:
位置损失,大小损失,有目标的置信度损失,没目标的置信度损失,有目标的类型损失求和。
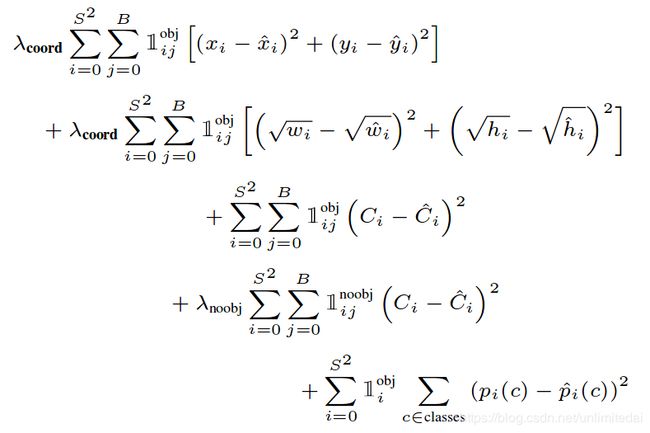
训练学习率:
Our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from 103 to 102.If we start at a high learning rate our model often diverges due to unstable gradients. We continue training with 102 for 75 epochs, then 103for 30 epochs, and finally 104for 30 epochs. To avoid overfitting we use dropout and extensive data augmentation. 没看这篇文章前,我写了第一篇论文,里面是以这个为创新点的,哎,丢人。不过他的结论确实验证了我当时实验的问题,为什么直接高学习率有时会效果很差
损失率:
dropout = 0.5
数据增强:
For data augmentation we introduce random scaling and translations of up to 20% of the original image size. We also randomly adjust the exposure and saturation of the image by up to a factor of 1.5 in the HSV color space.
网络训练集:
http://host.robots.ox.ac.uk/pascal/VOC/
推论
1.YOLO is extremely fast at test time since it only requires a single network evaluation, unlike classifier-based methods.
2.While not critical to performance as it is for R-CNN or DPM, non-maximal suppression adds 2-3% in mAP.
模型快和非极大抑制作用的推论。
限制
1.YOLO imposes strong spatial constraints on bounding box predictions.This spatial constraint limits the number of nearby objects that our model can predict.
2.A small error in a large box is generally benign but a small error in a small box has a much greater effect on IOU.Our main source of error is incorrect localizations.
相邻的目标在检测数量上的限制和小边界框中出错问题的严重性。
后文
后续内容是对比其他算法的记录,和在具体数据集上测试的结果。
对比的现有算法很多,可以看一下分析。
测试用了VOC2007,VOC2012,一些画作,野外实时监测。测试贴出了和其他算法对比的结果。
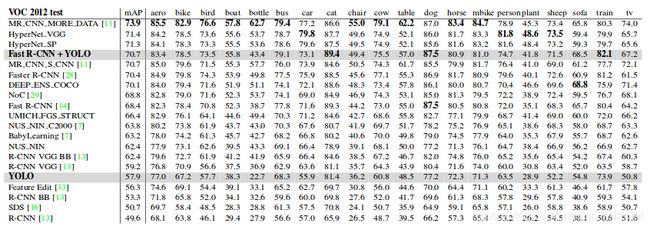
有的种类(plant)都低,有的种类(cat)都高,Fast R-CNN+YOLO的使用也很有意思。
YOLO makes far fewer background mistakes than Fast R-CNN. By using YOLO to eliminate background detections from Fast R-CNN we get a significant boost in performance. For every bounding box that R-CNN predicts we check to see if YOLO predicts a similar box. If it does, we give that prediction a boost based on the probability predicted by YOLO and the overlap between the two boxes.
概念摘出
这一部分是给萌新看的,在我的论文笔记中,每一个概念前三次出现我会给出解释,之后就没了。
1.mean average precision mAP
先说AP,它是average precision的意思,每次一张图片,我们对图中马冬梅的识别概率是precision,一堆图片的准确度当然就要求平均--average precision。那么我们不仅识别马冬梅,还有冬马梅,梅马冬这么多类要识别,是不是应该再平均一下,也就是mean average precision。
2.false positive FP
说它就必须要说它的小伙伴们。
| True Positive | True Negative |
|---|---|
| False Positive | False Negative |
| True Positive | 真阳性 | 神经网络说你有病,你实际真有病,这是真阳性 |
|---|---|---|
| False Positive | 假阳性 | 神经网络说你有病,但你实际没病,这是假阳性 |
| True Negative | 真阴性 | 神经网络说你没病,你实际就没病,这是真阴性 |
| False Negative | 假阴性 | 神经网络说你没病,但实际很不幸,这是假阴性 |
论文常见的是:
True Positive Rate(真正率 , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN)
也就是 诊断出有病且真有病(TP) 在 所有有病的人(TP+FN) 的比重。
True Negative Rate(真负率 , TNR)或特指度(specificity)
TNR = TN /(TN + FP)
也就是 诊断出没病且真没病(TN) 在 所有没病的人(TN+FP) 的比重。
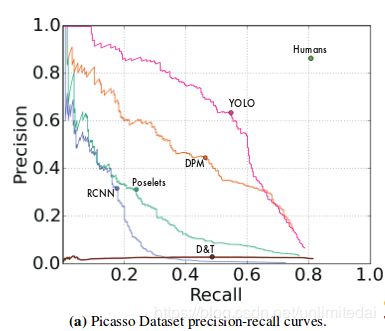
本文就用这两个东西画了个图。
3.non-max suppression 非极大值抑制
我们的神经网络为了识别马冬梅和冬马梅识别了好多框,里面一部分是马冬梅的框,一部分是冬马梅的框,但我们只保留每个目标概率最高的那个框。这个过程就是一种Non-max suppression
详见:https://www.cnblogs.com/makefile/p/nms.html
4.confidence scores or confidence level or confidence 置信度
百度百科说:在统计学中,一个概率样本的置信区间是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一定概率”。这个概率被称为置信水平。
程序复现
程序:
链接: https://pan.baidu.com/s/1FyFV-dttil17Q20jvu9B9g 提取码: utms
数据:
链接: https://pan.baidu.com/s/1qU47PTViTL8y06ldx4XvoA 提取码: 4piv
写在最后面
最后让我们看一下Joseph Redmon的主页吧!
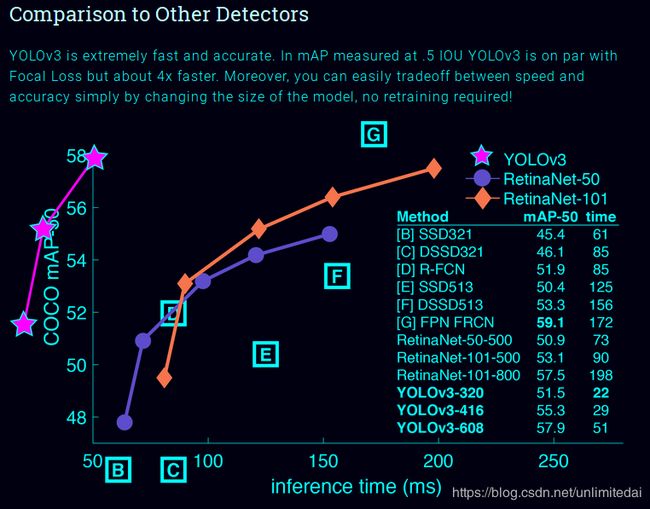
真的不是我浏览器的问题,他图就是这么画的,这粉红的小曲线展现了yolo的速度远远快过其他模型。这真是很好地体现出了摘要中的Our unified architecture is extremely fast.只要我足够快,坐标系就追不上我。



真是洒脱的作风233╮(╯_╰)╭