内存计算平台spark在今年6月份的时候正式发布了spark2.0,相比上一版本的spark1.6版本,在内存优化,数据组织,流计算等方面都做出了较大的改变,同时更加注重基于DataFrame数据组织的MLlib,更加注重机器学习整个过程的管道化。
当然,作为使用者,特别是需要运用到线上的系统,大部分厂家还是会继续选择已经稳定的spark1.6版本,并且在spark2.0逐渐成熟之后才会开始考虑系统组件的升级。作为开发者,还是有必要先行一步,去了解spark2.0的一些特性和使用,及思考/借鉴一些spark2.0做出某些改进的思路。
接下来的几篇blog中,将会逐步的对spark2.0的sparkSql、spark-structured-streaming、spark-ml等组件做入门级的学习。
由于公司的机器使用的java1.6x版本,暂时利用其体验spark2.0的分布式的环境,因此在windows机器上运行其local模式。
下面开始step by step开始我们的体验之旅:
首先创建一个maven项目,在cmd命令行下运行:
mvn archetype:generate -DgroupId=cs.dt.sparkTest -DartifactId=sparkTest -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
org.apache.spark
spark-core_2.10
2.0.0
org.apache.spark
spark-sql_2.10
2.0.0
首先,为了调用spark API 来完成我们的计算,需要先创建一个sparkContext:
String warehouseLocation = System.getProperty("user.dir") + "spark-warehouse";//用户的当前工作目录 SparkConf conf = new SparkConf().setAppName("spark sql test")
.set("spark.sql.warehouse.dir", warehouseLocation)
.setMaster("local[3]"); SparkSession spark = SparkSession
.builder()
.config(conf)
.getOrCreate();- 使用spark sql时需要指定数据库的文件地址,这里使用了一个本地的目录
- spark配置,指定spark app的名称和数据库地址,master url为local 3核
- 使用SparkSession,取代了原本的SQLContext与HiveContext。对于DataFrame API的用户来说,Spark常见的混乱源头来自于使用哪个“context”。现在你可以使用SparkSession了,它作为单个入口可以兼容两者。注意原本的SQLContext与HiveContext仍然保留,以支持向下兼容。这是spark2.0的一个较大的改变,对用户更加友好。
//===========================================1 spark SQL===================
//数据导入方式
Dataset df = spark.read().json("..\\sparkTestData\\people.json");
//查看表
df.show();
//查看表结构
df.printSchema();
//查看某一列 类似于MySQL: select name from people
df.select("name").show();
//查看多列并作计算 类似于MySQL: select name ,age+1 from people
df.select(col("name"), col("age").plus(1)).show();
//设置过滤条件 类似于MySQL:select * from people where age>21
df.filter(col("age").gt(21)).show();
//做聚合操作 类似于MySQL:select age,count(*) from people group by age
df.groupBy("age").count().show();
//上述多个条件进行组合 select ta.age,count(*) from (select name,age+1 as "age" from people) as ta where ta.age>21 group by ta.age
df.select(col("name"), col("age").plus(1).alias("age")).filter(col("age").gt(21)).groupBy("age").count().show();
//直接使用spark SQL进行查询
//先注册为临时表
df.createOrReplaceTempView("people");
Dataset sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
主要关注以下几点:
- 数据来源:spark可以直接导入json格式的文件数据,people.json是我从spark安装包下拷贝的测试数据。
- spark sql:sparkSql语法和用法和mysql有一定的相似性,可以查看表、表结构、查询、聚合等操作。用户可以使用sparkSql的API接口做聚合查询等操作或者用类SQL语句实现(但是必须将DataSet注册为临时表)
- DataSet:DataSet是spark2.0i引入的一个新的特性(在spark1.6中属于alpha版本)。DataSet结合了RDD和DataFrame的优点, 并带来的一个新的概念Encoder当序列化数据时,,Encoder产生字节码与off-heap进行交互,,能够达到按需访问数据的效果,而不用反序列化整个对象。
/**
* 一个描述人属性的JavaBeans
* A JavaBean is a Java object that satisfies certain programming conventions:
The JavaBean class must implement either Serializable or Externalizable
The JavaBean class must have a no-arg constructor
All JavaBean properties must have public setter and getter methods
All JavaBean instance variables should be private
*/
public static class Person implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
} //为自定义的对象创建Dataset
List personpList = new ArrayList();
Person person1 = new Person();
person1.setName("Andy");
person1.setAge(32);
Person person2 = new Person();
person2.setName("Justin");
person2.setAge(19);
personpList.add(person1);
personpList.add(person2);
Encoder personEncoder = Encoders.bean(Person.class);
Dataset javaBeanDS = spark.createDataset(
personpList,
personEncoder
);
javaBeanDS.show(); 同时,可以利用Java反射的特性,来从其他数据集中创建DataSet对象:
//spark支持使用java 反射机制推断表结构
//1 首先创建一个存储person对象的RDD
JavaRDD peopleRDD = spark.read()
.textFile("..\\sparkTestData\\people.txt")
.javaRDD()
.map(new Function() {
public Person call(String line) throws Exception {
String[] parts = line.split(",");
Person person = new Person();
person.setName(parts[0]);
person.setAge(Integer.parseInt(parts[1].trim()));
return person;
}
});
//2 表结构推断
Dataset peopleDF = spark.createDataFrame(peopleRDD, Person.class);
peopleDF.createOrReplaceTempView("people");
//3 定义map 这里对每个元素做序列化操作
Encoder stringEncoder = Encoders.STRING();
Dataset peopleSerDF = peopleDF.map(new MapFunction() {
public String call(Row row) throws Exception {
return "Name: " + row.getString(1) + " and age is " + String.valueOf(row.getInt(0));
}
}, stringEncoder);
peopleSerDF.show();
//==============================================3 从RDD创建Dataset StructType对象的使用
JavaRDD peopleRDD2 = spark.sparkContext()
.textFile("..\\sparkTestData\\people.txt", 1)
.toJavaRDD();
// 创建一个描述表结构的schema
String schemaString = "name age";
List fields = new ArrayList();
for (String fieldName : schemaString.split(" ")) {
StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);
fields.add(field);
}
StructType schema = DataTypes.createStructType(fields);
// Convert records of the RDD (people) to Rows
JavaRDD rowRDD = peopleRDD2.map(new Function() {
//@Override
public Row call(String record) throws Exception {
String[] attributes = record.split(",");
return RowFactory.create(attributes[0], attributes[1].trim());
}
});
// Apply the schema to the RDD
Dataset peopleDataFrame = spark.createDataFrame(rowRDD, schema);
// Creates a temporary view using the DataFrame
peopleDataFrame.createOrReplaceTempView("people");
peopleDataFrame.show();
- RDD:从普通文本文件中解析数据,并创建结构化数据结构的RDD。
- 表结构推断的方式创建DataSet:利用Java类反射特性将RDD转换为DataSet。
- 指定表结构的方式创建DataSet:我们可以使用StructType来明确定义我们的表结构,完成DataSet的创建
//在Spark 2.0中,window API内置也支持time windows!Spark SQL中的time windows和Spark Streaming中的time windows非常类似。
Dataset stocksDF = spark.read().option("header","true").
option("inferSchema","true").
csv("..\\sparkTestData\\stocks.csv");
//stocksDF.show();
Dataset stocks201606 = stocksDF.filter("year(Date)==2016").
filter("month(Date)==6");
stocks201606.show(100,false);
首先读入了csv格式的数据文件,同时将2016年6月份的数据过滤出来,并以不截断的方式输出前面100条记录,运行的结果为:
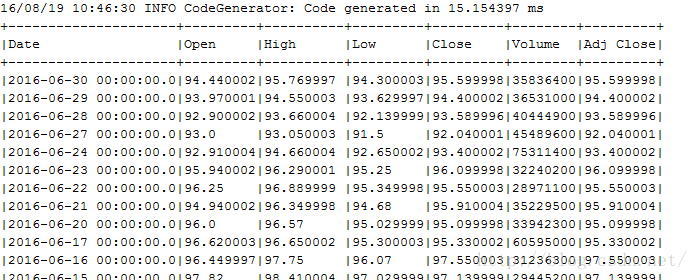
调用window接口做窗口统计:
//window一般在group by语句中使用。window方法的第一个参数指定了时间所在的列;
//第二个参数指定了窗口的持续时间(duration),它的单位可以是seconds、minutes、hours、days或者weeks。
Dataset tumblingWindowDS = stocks201606.groupBy(window(stocks201606.col("Date"),"1 week")).
agg(avg("Close").as("weekly_average"));
tumblingWindowDS.show(100,false);
tumblingWindowDS.sort("window.start").
select("window.start","window.end","weekly_average").
show(false);
其运行结果为:
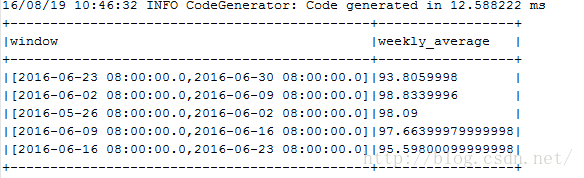
由于没有指定窗口的开始时间,因此统计的开始时间为2016-05-26,并且不是从0点开始的。通常情况下,这样统计就显得有点不对了,因此我们需要指定其开始的日期和时间,但是遗憾的是spark并没有接口/参数让我们明确的指定统计窗口的开始时间。好在提供了另外一种方式,指定偏移时间,上述时间(2016-05-26 08:00:00)做一个时间偏移,也可以得到我们想要的开始时间(2016-06-01 00:00:00)。
//在前面的示例中,我们使用的是tumbling window。为了能够指定开始时间,我们需要使用sliding window(滑动窗口)。
//到目前为止,没有相关API来创建带有开始时间的tumbling window,但是我们可以通过将窗口时间(window duration)
//和滑动时间(slide duration)设置成一样来创建带有开始时间的tumbling window。代码如下:
Dataset windowWithStartTime = stocks201606.
groupBy(window(stocks201606.col("Date"),"1 week","1 week", "136 hour")).
agg(avg("Close").as("weekly_average"));
//6 days参数就是开始时间的偏移量;前两个参数分别代表窗口时间和滑动时间,我们打印出这个窗口的内容:
windowWithStartTime.sort("window.start").
select("window.start","window.end","weekly_average").
show(false);
运行结果为:
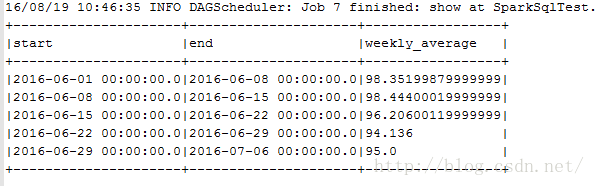
这就得到了我们需要的统计结果了。
关于spark2.0的sparkSql部分,基本就介绍这么多了。
接下来的几篇blog,一起体验spark-structured-streaming、spark-ml等组件的使用。