作者:吴双桥 腾讯云数据库工程师
出处:腾云阁文章
----------------------------------------------------
一 、背景介绍
近年来,TokuDB作为MySQL的大数据(Big Data)存储引擎受到人们的普遍关注。其架构的核心基于一种新的叫做分形树(Fractal Trees)的索引数据结构,该结构是缓存无关的,即使索引数据大小超过内存性能也不会下降,也即没有内存生命周期和碎片的问题。
特别引人注意的是,TokuDB拥有很高的压缩比(官方称最大可达25倍),可以在很大的数据上创建大量的索引,并保持性能不下降。同时,TokuDB支持ACID和MVCC,还有在线修改表结构(Live Schema Modification)以及增加的复制性能等特性,使其在某些特定的应用领域(如日志存储与分析)有着独特的优势。
在TokuDB的应用场景中,通常是数据库插入操作的量远远大于读取的量,因而本此测试主要针对TokuDB的插入性能以及压缩比,以InnoDB作为参考基准。
二、测试环境搭建
测试使用的机器为高配机型,内存大于100G,CPU型号为Intel(R) Xeon(R) CPU E5系列,数据盘使用的是SSD硬盘。
MySQL TokuDB版本使用的是 5.6.28-76.1,按照Percona网站上的安装方法使用插件的方式进行安装,见官网教程。使用MySQL命令查看:
+--------------------+---------+--------------+------+------------+ | Engine | Support | Transactions | XA | Savepoints | +--------------------+---------+--------------+------+------------+ | InnoDB | YES | YES | YES | YES | | CSV | YES | NO | NO | NO | | MyISAM | YES | NO | NO | NO | | BLACKHOLE | YES | NO | NO | NO | | MEMORY | YES | NO | NO | NO | | TokuDB | DEFAULT | YES | YES | YES | | MRG_MYISAM | YES | NO | NO | NO | | ARCHIVE | YES | NO | NO | NO | | FEDERATED | NO | NULL | NULL | NULL | | PERFORMANCE_SCHEMA | YES | NO | NO | NO | +--------------------+---------+--------------+------+------------+
可以看到TokuDB引擎已经就绪,并被设置为了默认的存储引擎。
三、测试工具与变量
1、测试工具选择
现在开源可用的MySQL基准测试工具有很多,如mysqlslap,MySQL Benchmark Suite,Super Smack,Database Test Suite,TPCC和sysbench等。综合工具的功能、易用性还有流行程度,最终选定操作简单但功能强大的sysbench作为测试工具。在sysbench 0.5版本中,已经开始支持Lua脚本,使用修改起来非常灵活。另外,测试压缩比直接使用的mysqldump工具。
2、测试变量
插入性能相关的变量
除去根据机器硬件特性配置的常规优化参数,对于存储引擎插入性能影响最大的是:是否将事务和binlog同步刷新到硬盘。
需要特别说明的是,还有一个比较重要的指标,即是否开启了DIRECT IO功能,由于在测试环境InnoDB开启了DIRECT IO,并能提高整体的性能,而TokuDB在测试机型上无法开启DIRECT IO功能,所以在这点上InnoDB有相对的优势。
InnoDB 相关
对于InnoDB来说,控制这个功能的参数为innodb_flush_log_at_trx_commit和sync_binlog。innodb_flush_log_at_trx_commit参数指定了InnoDB在事务提交后的日志写入频率。具体来说:
当
innodb_flush_log_at_trx_commit取值为 0 时,log buffer 会 每秒写入到日志文件并刷写(flush)到硬盘。但每次事务提交不会有任何影响,也就是 log buffer 的刷写操作和事务提交操作没有关系。在这种情况下,MySQL性能最好,但如果 mysqld 进程崩溃,通常会导致最后 1s 的日志丢失。当取值为 1 时,每次事务提交时,log buffer 会被写入到日志文件并刷写到硬盘。这也是默认值。这是最安全的配置,但由于每次事务都需要进行硬盘I/O,所以也最慢。
当取值为 2 时,每次事务提交会写入日志文件,但并不会立即刷写到硬盘,日志文件会每秒刷写一次到硬盘。这时如果 mysqld 进程崩溃,由于日志已经写入到系统缓存,所以并不会丢失数据;在操作系统崩溃的情况下,通常会导致最后 1s 的日志丢失。
在实际的生产系统中,innodb_flush_log_at_trx_commit会在1和2之间选择。一般来说,对数据一致性和完整性要求比较高的应用场景,会将其值设置为1。
sync_binlog参数指定了 MySQL 的二进制日志同步到硬盘的频率。如果MySQL autocommit开启,那么每个语句都写一次binlog,否则每次事务写一次。
默认值为 0,不主动同步binlog的写入,而依赖于操作系统本身不定期把文件内容flush到硬盘。
设置为 1 时,在每个语句或者事务后会同步一次binlog,即使发生意外崩溃时也最多丢失一个事务的日志,因而速度较慢。
通常情况下,innodb_flush_log_at_trx_commit和sync_binlog配合起来使用,本次性能测试覆盖了同步刷新日志和异步刷新日志两种策略。
TokuDB 相关
TokuDB中与InnoDB类似的指标为tokudb_commit_sync和tokudb_fsync_log_period。与innodb_flush_log_at_trx_commit的含义类似,tokudb_commit_sync指定当事务提交的时候,是否要刷新日志到硬盘上。
默认开启,值为1。也就是每次事务提交时,log buffer 会被写入到日志文件并刷写到硬盘。
如果设置为 0,每次事务提交会写入日志文件,但并不会立即刷写到硬盘,日志文件会每隔一段时间刷写一次到硬盘。这个时间间隔由
tokudb_commit_sync指定。
tokudb_fsync_log_period指定多久将日志文件刷新到硬盘,TukuDB的log buffer总大小为 32 MB且不可更改。默认为 0 秒,此时如果tokudb_commit_sync设置为开启,那么这个值默认为 1 分钟。
tokudb_commit_sync和tokudb_fsync_log_period通常也是配合起来使用,本次性能测试覆盖了两种典型的组合策略。
压缩比相关的变量
大多数选择使用TokuDB的场景,都非常重视它的存储压缩比,因而在实际应用场景中总会配套使用某种压缩算法。当前TokuDB支持的压缩算法有,quicklz, zlib, lzma, snappy,当然还有不压缩uncompressed。关于压缩算法的讨论,可以参考官方博客的一篇分析文章。
本次测试会结合真实的数据来从压缩比、耗时两个方面来检验上面几个不同的压缩算法。TokuDB可以通过在配置文件中设置tokudb_row_format来指定不同的压缩算法,它们的取值分别是:TOKUDB_QUICKLZ, TOKUDB_ZLIB, TOKUDB_LZMA和TOKUDB_SNAPPY。值得注意的是,zlib算法是TokuDB官方最新版本的默认算法,也是现今支持TokuDB的云服务商的默认推荐算法。
sysbench压缩工具相关的变量
sysbench针对mysql压测的参数有很多,这里选取的是与实际应用场景最为相关的两个参数:表数量以及线程数量。表数量对应的是数据库实际在同时写入的表的数量,线程数对应的到MySQL数据库上的连接。其他的参数,如表的大小,是否是事务等可能影响整体的插入性能,但影响并不显著,这里只选取最主要的两个参数进行分析。
3、测试方法
本测试的采用的方式为经典的控制变量法。这里的变量有:采用的存储引擎类型,是否同步刷新日志,采用的压缩算法,以及另外两个与sysbench相关的参数:压测的线程数量和压测的表数量。其中,压缩算法的选择只是在四种算法中选择一种,所以并不与其他变量交叉测试。这样以存储引擎和同步刷新日志来划分测试,可以将整个测试数据分为四个大类:
InnoDB & 同步刷新日志
InnoDB & 异步刷新日志
TokuDB & 同步刷新日志
TokuDB & 异步刷新日志
在每个大类下,对压测线程数量和压测表数量进行交叉测试。压测表数量取值可能为[1, 2, 4, 8, 12, 16],线程数的可能取值为[1, 2, 4, 8, 16, 24, 32, 48, 64, 80],因而每个大类下进行6 * 10 = 60 次压测,每次压测写入2,000,000 条数据,对每次压测进行插入性能统计。
四、测试结果分析
1、InnoDB & 同步刷新日志
将innodb_flush_log_at_trx_commit设置为1,sync_binlog设置为1,也即是保证数据最安全:同步刷新log到硬盘,并且针对每个事务同步一次binlog。测试的情况见下表:
| 表数/插入TPS/线程数 | 1 | 2 | 4 | 8 | 12 | 16 |
|---|---|---|---|---|---|---|
| 1 | 5645.54 | 5678.40 | 5711.15 | 5687.44 | 5660.76 | 5708.54 |
| 2 | 10995.42 | 10921.06 | 11023.25 | 11017.88 | 11038.06 | 10902.12 |
| 4 | 18732.14 | 18724.20 | 18882.65 | 18935.62 | 18890.46 | 17997.52 |
| 8 | 33291.35 | 33379.37 | 33372.19 | 33842.15 | 30576.58 | 34048.53 |
| 16 | 54560.36 | 56346.20 | 57358.33 | 57454.11 | 57571.72 | 57989.96 |
| 24 | 66230.44 | 70813.87 | 73871.31 | 68764.22 | 68019.27 | 67538.82 |
| 32 | 66855.54 | 80153.06 | 84885.82 | 84387.96 | 76404.04 | 84920.13 |
| 48 | 56788.96 | 85778.22 | 93914.45 | 97055.96 | 84041.31 | 96790.49 |
| 64 | 55640.96 | 83342.88 | 95736.42 | 92667.25 | 96560.51 | 83598.00 |
| 80 | 58408.18 | 75858.18 | 60683.99 | 60491.26 | 60177.24 | 64290.13 |
用更直观的图表来展示:
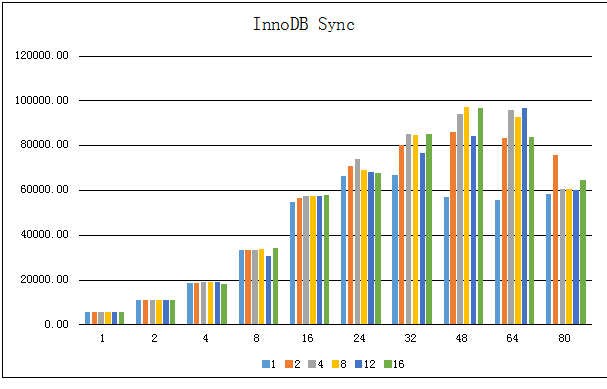
可以看到:
在线程数比较少的时候(不高于24个,即总CPU数目的一半),数据表的个数对整体的性能影响很小;当线程数较多时才显示出区别:相同线程数下,增加表数目可提升数据库整体吞吐量
InnoDB整体性能在48线程时达到顶峰,也即达到CPU的总数目,说明InnoDB能充分利用硬件多CPU的特性
在线程数或者表数量很小的时候,增加线程数或者表数量可以线性地提升性能,在实际环境中值得注意;而在线程数量超过物理CPU数量时,整体插入性能会下降
2、InnoDB & 异步刷新日志
将innodb_flush_log_at_trx_commit设置为2,sync_binlog设置为 0,日志文件会每秒刷写一次到硬盘,并且不主动同步binlog的写入,而依赖于操作系统本身不定期把文件内容flush到硬盘。测试的情况见下表:
| 表数/插入TPS/线程数 | 1 | 2 | 4 | 8 | 12 | 16 |
|---|---|---|---|---|---|---|
| 1 | 7751.83 | 7776.78 | 7741.86 | 7739.29 | 7770.41 | 7662.18 |
| 2 | 15199.98 | 14952.94 | 15252.04 | 15184.54 | 15186.76 | 15176.68 |
| 4 | 29075.83 | 29194.62 | 29228.09 | 29204.63 | 29625.60 | 29406.31 |
| 8 | 53578.10 | 51007.42 | 53116.44 | 54029.60 | 53291.41 | 52173.69 |
| 16 | 61002.65 | 71383.45 | 74656.36 | 75597.66 | 76305.24 | 76412.77 |
| 24 | 52758.54 | 70906.04 | 78472.49 | 81999.99 | 80430.52 | 82896.78 |
| 32 | 51740.38 | 68061.25 | 79936.12 | 82063.79 | 84966.86 | 83667.26 |
| 48 | 50961.62 | 65962.79 | 79952.45 | 85511.97 | 86223.38 | 86718.83 |
| 64 | 53378.76 | 65758.29 | 74224.26 | 76779.63 | 75368.30 | 76614.14 |
| 80 | 55056.88 | 66799.11 | 73969.11 | 62867.60 | 62039.68 | 63572.61 |
用更直观的图表来展示:
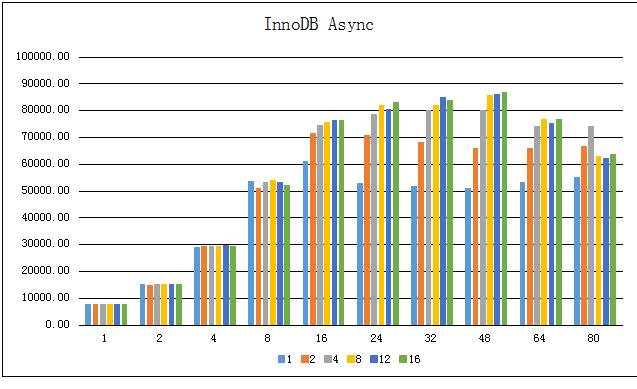
可以看到与InnoDB Sync的情况有所不同:
异步的情况,随着线程数的增加,插入性能提升较快,在16个线程的时候已经接近峰值
插入TPS的峰值比同步情况的峰值低,这个与以往SATA/SAS磁盘环境下的MySQL优化经验不匹配;通过iostat查看SSD盘的使用率很低,只有百分之几,因而SSD硬盘条件下的InnoDB的优化策略需要持续改进
3、TokuDB & 同步刷新日志
将tokudb_commit_sync设置为1,tokudb_fsync_log_period设置为0,也就是每次事务提交时,log buffer 会被写入到日志文件并刷写到硬盘。
| 表数/插入TPS/线程数 | 1 | 2 | 4 | 8 | 12 | 16 |
|---|---|---|---|---|---|---|
| 1 | 6506.16 | 6533.51 | 6514.36 | 6505.52 | 6581.28 | 6588.60 |
| 2 | 12335.72 | 12323.07 | 12494.74 | 12572.37 | 12600.94 | 12623.45 |
| 4 | 22726.24 | 23001.47 | 23331.96 | 23854.47 | 24267.20 | 24060.65 |
| 8 | 34935.53 | 38952.86 | 40093.37 | 41687.61 | 42472.60 | 44021.98 |
| 16 | 30777.25 | 42145.63 | 50293.47 | 55585.24 | 58956.65 | 59804.16 |
| 24 | 28102.26 | 38306.27 | 44420.44 | 47960.77 | 50440.59 | 52436.36 |
| 32 | 26227.49 | 35677.10 | 39627.22 | 40717.32 | 42562.45 | 44657.12 |
| 48 | 23335.33 | 30574.98 | 34961.22 | 34289.79 | 34819.25 | 35367.41 |
| 64 | 28923.69 | 36267.50 | 35228.70 | 35306.85 | 30393.76 | 29644.79 |
| 80 | 28323.74 | 33808.39 | 34203.47 | 35249.88 | 27757.45 | 32269.39 |
用图表来展示:

可以看到:
出乎意料的是,TokuDB在线程数16的时候插入TPS达到峰值,也就是说TokuDB并没有完全利用起多物理CPU的优势
对比InnoDB线程数从1~16的情况可以看到,TokuDB在相同条件下比InnoDB的性能还要高;而在线程数增多的时候,TokuDB的插入TPS在逐渐减小,而InnoDB在线程数超过物理CPU个数的时,插入TPS才开始下降,说明TokuDB还有很大的优化空间
4、TokuDB & 异步刷新日志
| 线程数/插入TPS/表数 | 1 | 2 | 4 | 8 | 12 | 16 |
|---|---|---|---|---|---|---|
| 1 | 6478.74 | 6514.03 | 6571.31 | 6555.92 | 6462.55 | 6588.75 |
| 2 | 12388.24 | 12433.75 | 12417.53 | 12457.83 | 12629.21 | 12597.90 |
| 4 | 22915.61 | 22265.08 | 24002.63 | 24248.57 | 22596.18 | 24323.07 |
| 8 | 35078.08 | 39179.46 | 39583.82 | 39505.79 | 42549.19 | 43493.89 |
| 16 | 30017.06 | 42012.43 | 46019.37 | 58790.76 | 60294.11 | 61057.96 |
| 24 | 27675.70 | 37873.94 | 45151.54 | 45075.48 | 49145.73 | 52417.81 |
| 32 | 26078.90 | 35496.19 | 39891.16 | 38888.13 | 43570.03 | 44882.92 |
| 48 | 23340.20 | 32392.89 | 35164.66 | 33858.16 | 34209.27 | 35350.72 |
| 64 | 29522.80 | 36475.76 | 36969.68 | 32381.53 | 32160.18 | 32589.76 |
| 80 | 27976.86 | 33483.40 | 34994.01 | 34977.62 | 30259.96 | 32680.34 |
用图表来展示:
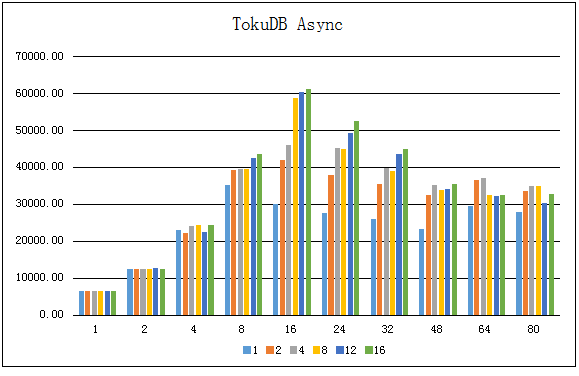
对比之前的图标,可以看到:
与InnoDB不同的是,是否开启log的同步对TokuDB的插入性能影响不大,
TokuDB Sync和TokuDB Async两者的图形形状几乎一样与同步的情况类似,TokuDB在线程数16的时候插入TPS就达到峰值,有很大的优化空间
5、压缩算法选择
压缩算法测试使用的实际的运行数据做测试,原来用InnoDB存储的日志数据为92GB,用mysqldump工具导出后为79GB。测试表是典型的日志存储表,其结构如下:
+-------+--------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra | +-------+--------------+------+-----+---------+----------------+ | a | int(11) | NO | PRI | NULL | auto_increment | | b | bigint(20) | NO | MUL | 0 | | | c | varchar(30) | NO | | | | | d | varchar(20) | NO | | | | | e | varchar(30) | NO | | | | | f | text | NO | | NULL | | | g | varchar(300) | NO | | | | | h | int(11) | NO | | 0 | | | i | int(11) | NO | | 0 | | | j | int(11) | NO | | 0 | | | k | int(11) | NO | | 0 | | +-------+--------------+------+-----+---------+----------------+
依次将TokuDB的tokudb_row_format设置为不同的压缩算法,得到其导入后的实际存储空间以及导入时间,测试结果如下:
| 压缩算法/项目 | 存储大小 | 导入时间 |
|---|---|---|
| snappy | 12GB | 47min40s |
| quicklz | 7.1GB | 47min21s |
| zlib | 5.7GB | 48min9s |
| lzma | 4.7GB | 47min10s |
从表中可以观察到:
几种压缩算法耗时差不多,相差很小
不同的压缩算法的压缩比差异较大,snappy压缩比较小,约为6.6倍;压缩比最大的lzma为16.8倍
zlib作为官方选择的默认压缩算法,在压缩比和CPU消耗上有较好的平衡,压缩比为13.8倍
结合在测试过程中持续观察CPU的使用情况,lzma算法在运行过程中CPU使用率在600%~700%左右,而zlib算法CPU使用率在80%~180%之间摆动。因而,在实际生产环境中,如果没有特殊的考虑,建议使用zlib压缩算法。
五、讨论与结论
本次测试以InnoDB为参考,主要测试TokuDB的写入性能以及存储压缩比。通过不同场景下的对比测试,可以得出几个观点:
InnoDB现阶段插入性能有优势,性能大约高出30%左右
TokuDB虽然没有充分利用硬件的能力,但是已经表现出强大的足够高的性能,考虑到TokuDB的成熟度,后面它还有较大的提升空间,可以持续关注其后续进展
TokuDB选择日志同步或者异步刷新对性能影响不大,建议默认选择同步日志保护数据
TokuDB在数据压缩存储上有绝对的优势,十几倍的压缩比对于冷备数据存储有着极大的吸引力
值得一提的是,InnoDB性能表现优异部分原因可归功于InnoDB的成熟度,可灵活的配置许多参数以适应特定的应用场景,而TokuDB暴露出的优化参数很少,不能根据硬件配置调整一些重要参数。综上,虽然TokuDB在现阶段还没成熟,但已经表现出强大的性能以及突出的特性,应该作为某些特定应用场景的首选。
------------------------------------------
获取更多云计算技术干货,可请前往 腾讯云技术社区
我也会持续同步更新~
微信公众号:腾讯云技术社区( QcloudCommunity)
