Top 100论文导读(一):纯干货!深度神经网络中的理解,泛化以及迁移学习
更多深度文章,请关注:https://yq.aliyun.com/cloud
作者:Adrian Colyer, 著名阿克赛尔合伙公司(Accel Partners)的投资合伙人,该公司致力于帮助杰出的企业家创建世界级的高科技企业,在加入Accel之前,Adrian拥有20年技术人员工作经验,如担任Pivota , VMware, SpringSource的CTO。如果你对科技企业感兴趣,可以和他联系。邮箱:[email protected]. 他的领英主页。
前言:作者从top 100 优秀深度学习论文中选取第一组论文为大家进行纯干货总结,该组包含6篇论文,所以阅读所需时间可能偏长,本文主要讲解使用可视化技术分析深度神经网络DNNs(大多是卷积神经网络CNNs)学习的东西,泛化性以及迁移学习。
1.Visualizing and understanding convolutional networks, Zeller & Fergus 2013
卷积神经网络在诸如手写数字分类和人脸检测任务上性能优异。但人们并未完全洞悉这些复杂模型的内部操作以及行为。从科学的角度来说,这非常让人不满意。
如果想了解卷积神经网络是如何运作的,我们需要将图像特征映射到隐藏层,然后再传回输入像素空间(使用ImageNet数据集进行训练)。Zeiler和Fergus使用一个名为反卷积的巧妙结构,以相反的顺序使用卷积神经网络的结构。当然,某些部分需要略微增强以便获取在颠倒的过程中需要用到的额外信息。如下图所示,左边是反卷积层,右边是卷积层。
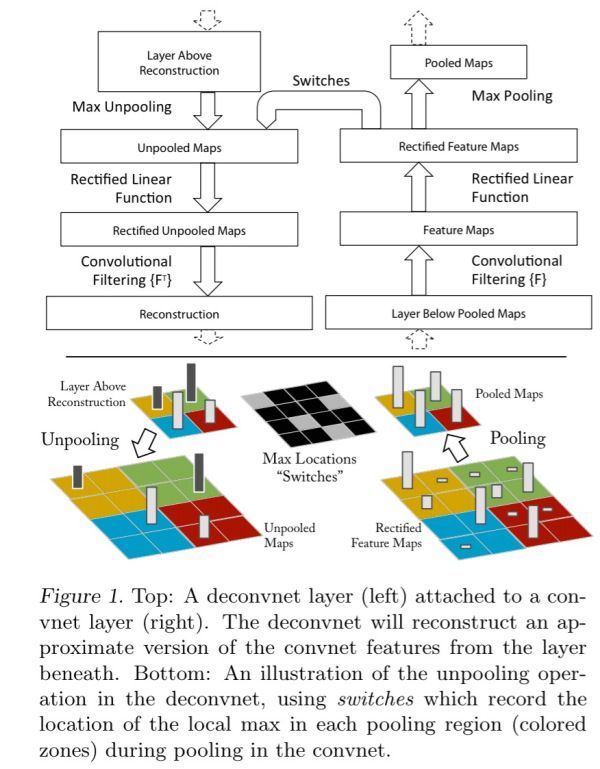
反卷积层会重构下方卷积层恰当的特征。可以使用switches记录池化过程中每个池化区域局部最大值的坐标位置。然后在反池化的时候,只把池化过程中最大值所在的位置坐标的值激活,其它值置为0。
既然能够将每层都投影到像素空间,我们就能看到卷积神经网络学到了什么,如下图所示:

第二层展示了物体的边缘轮廓和颜色,第三层展示了相似的纹理,第四展示得更加细节化,比如狗脸,第五层展示了具有重要形态特征的完整对象。使用这些可视化技术可以看到在训练过程中他们是怎样变化的。上图表明,经过相对较少的周期,底层特征会趋于收敛,而高层则需要更长的时间才能收敛。输入图像的小的变化对底层会有重大影响,但是对高层影响很小。
观察这些可视化结果并加以理解和学习能够帮助提升模型性能。例如,第二层可视化结果说明大跨度会带来噪声,降低跨度大小可以提升分类性能。
同时,实验结果也说明网络的深度比模型的其他部分对整个模型性能影响更大。
2.DeCAF: A deep convolutional activation feature for generic visual recognition
很多视觉识别的挑战性任务都只有相对小的数据集。作者探究能否将一个由ImageNet (一个很大的数据集)训练来的卷积神经网络DeCAF泛化到其他可用数据较少的任务。
该模型可以被认为是一个基于有监督预训练(pre-training)阶段的迁移学习的深度架构,或者可以简单认为是,在一系列预先定义好的对象识别任务学习到卷积网络权重参数,然后据此定义的一个新的视觉特征DeCAF。
在训练一个深度卷积网络后(使用 Krizhevskey et al.’s competition winning 2012 architecture),从训练好的模型中抽取特征然后作为一般视觉任务的输入。在这些任务上获得成功说明卷积网络学习到普遍有用的图像特征。
█ 用DeCAFn作为CNN第n层隐藏层的激励。DeCAF7是传播到最后一个全连接层产生类别预测之前的最后一个隐藏层,使用CNN特征作为输入,训练logistic Regression或SVM进行分类。
█ 在Caltech-101 数据集上, DeCAF6 + SVM 效果好于以前最好的方法(一种组合5个传统手工设计的图像特征的方法)。
█ Office数据集包含来自Amazon的商品图片和在办公环境下使用网络摄像头(webcam)和单反相机(DSLRs)的到的图片。使用DeCAF特征不但能够较好地进行类别聚类,而且能够聚集不同区域的同一类物体,对于分辨率改变(webcam VS. DSLRs)具有良好鲁棒性。DeCAF + SVM的方法大大超越了基础的SURF特征。
█ 对于子类识别(如使用Caltech-UCSD数据集识别不同类型的鸟),DeCAF6 加上 logistic Regression 又超越了现有方法(就我们所知,这是目前文献里记录的最好的精度)
█ 最后,对于场景识别任务,在SUN-397大规模场景识别数据集上DeCAF + logistic Regression也优于了现有的方法。
训练于大规模图像数据集的卷积神经网络强有力地表明学习有足够代表性和泛化能力的特征能够以当前最先进的水平用于广泛的图像任务。
视觉识别系统要具有在含有稀疏且有标签数据的任务上达到高的分类精确度,这已经被证明是计算机视觉研究领域一个很困难的目标,但是我们的多任务深度学习框架(DeCAF)和彻底的开源实现是这个方向的重要一步。
PS:DeCAF即为现在的Caffe。
3. CNN features off-the-shelf: an astounding baseline for recognition
目前的CNN特征进一步说明我们可以学习到用于图像任务的普遍特征,并成功用于新领域。从经过训练的Overfeat卷积神经网络模型采集到基础特征,在ImageNet大规模视觉识别挑战赛(ILSVRC)已经被充分利用。对各种任务,作者不是使用目前常用的图像处理流程,而是简单地利用源自CNN表征的特征,然后用于SVM。如下图所示。
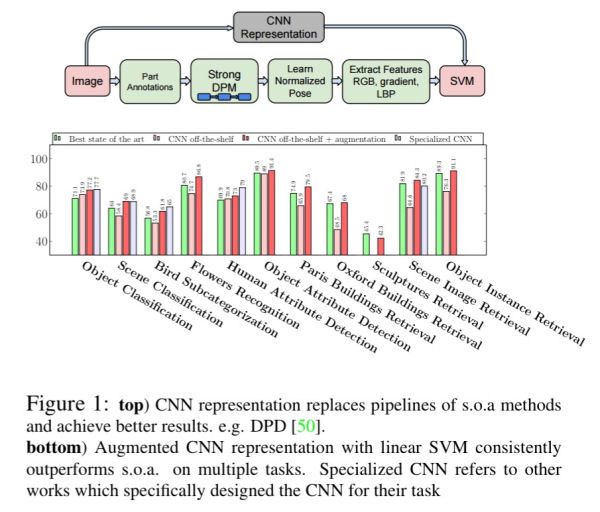
这个任务从完成相当接近原始分类任务开始,然后再到更多的需求。在方法的每一步,CNN特征都证明了它的价值:
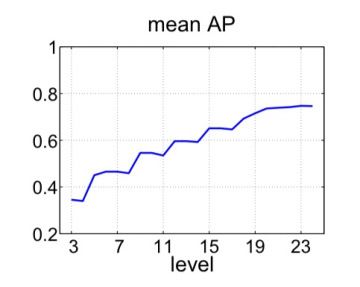
█ Step1. 对象和场景识别:Pascal VOC 2007数据集包含20个动物类别的1000张图像,被认为比ILSVRC具有更大的挑战性。在这个数据集上使用Overfeat CNN特征会产生一个优于先前所有成果的模型,如下图所示,这个图说明了使用原始CNN 不同层的特征作为最后SVM的输入是怎样使分类性能提升的。
对于场景识别任务,MIT-67室内场景数据集有67个室内场景类别的15620张图像。CNN+SVM模型明显胜过大多数基础模型,比先前最好的AlexConvNet 模型还要高0.1%精确度。
█ Step2.精细分类:考虑使用鸟(Caltech UCSD 200-2011 dataset)和花(Oxford 102 flowers dataset), 更为普遍的Overfeat特征能够找出相似类别之间的微小差别。在鸟的数据集上,这个模型和目前CNN的结果很接近,并优于所有基础方法(baselines)。而在花的数据集上,CNN+SVM则优于先前所有模型。
█ Step 3.属性检测: Overfeat特征能够对关于人和问题的语义属性的一些东西进行编码,CNN+SVM 在UIUC 64 和H3D 数据集上表现出优秀的性能。
█ Step 4.实例检索:在该领域内目前的方法都是高优化的工程向量(engineered vectors)和中层特征(mid-level features)。与不引入3D几何学信息的方法(表现更好)不同,CNN特征在建筑物数据集上也是非常有竞争力的。
本篇文章全是关于特征的。SIFT和HOG描述子在十年前性能很好,现在深度卷积特征在视觉识别也取得了突破性进展。在CNN表征上使用构造好的计算机视觉程序能够更进一步推进实验结果。任何情况下,如果你为开发出一个识别任务的新算法,必须和深度特征+简单分类器的基础方法进行对比。
4. How transferable are features in deep neural networks?
以前的论文大多集中于将来自预训练(pre-trained)的CNNs的高层作为输入特征。作者系统地研究了每层学到的特征的普遍性,并且可以用于迁移学习。
通常的迁移学习会先训练一个基础网络,然后将前n层复制到目标网络的前n层。目标网络剩余层随机初始化,然后再基于目标任务开始训练。你可以选择将其中的误差反向传播(BP)到基础特征(拷贝来的)然后为新任务进行调优(fine_tune),或者迁移过来的特征层保持不变。
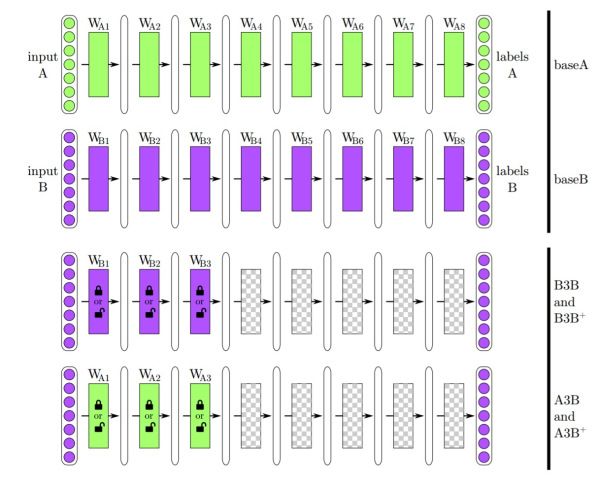
作者设计的实验很巧妙,采用一个8层的CNN模型,将1000个 ImageNet类分为两组,一组训练成baseA,一组训练成baseB。然后定义7个新的网络,A1到A7,分别从baseA拷贝前7层到A1-A7,实验就是要探究从第三层学到的特征迁移性能如何。作者构建了四个网络:
█ B3B:前三层从baseB复制并保持不变,剩下5层随机初始化,在上面训练任务B;
█ A3B:前三层从baseA复制并保持不变,剩下5层随机初始化,在上面训练任务B。如果A3B的效果优于B3B,那么有理由相信前三层的一般性;
█ B3B+:类似B3B,但是训练时会对前三层进行调优;
█ A3B+:类似A3B,但是训练时会对前三层进行调优。
具体如下图所示:
在1层到7层上重复这个过程,实验结果如下:
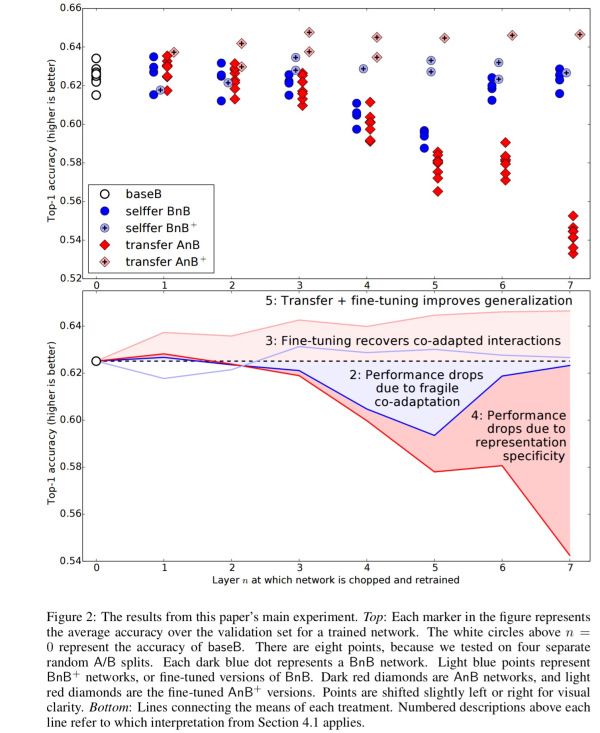
如图所示,当保持前几层不变,BnB表现出和baseB相近的精确度,但是3,4,5,6(特别是4,5层)性能表现很差,说明原始网络在连续层上含有脆弱的耦合特征(fragile co-adapted features)。最后一层,BnB性能又恢复如初,就好像BnB网络根本就没学到多少有用的东西。“就我们所知,在网络的中间的优化困难比在接近头部和尾部更糟糕,这种现象在以前的文献中并未发现过”。
BnB+经过调优,恢复了性能,并未出现大幅度的性能波动。
迁移学习AnB,前三层中仅有第三层轻微下降,说明从baseA学习到的特征具有一般性.从4层到7层性能急剧降低。参考BnB的点,下降的原因有两方面:层之间相互关系的丢失(lost co-adaptation)导致的下降以及缺乏一般性的特征造成的下降。
而AnB+优于基础方法。一个可能的原因是迁移层有机会学到目标网络自身不能学到的图像特征,因此具有更好的泛化性。
总之,迁移学习能够提高泛化性能,影响迁移学习的两个因素:中间层脆弱的相互关系(fragile co-adaptation of middle layers),高层的特化(specialisation of higher layers)。
5. Learning and transferring mid-level image representations using convolutional neural networks
这篇文章探讨了最大化迁移学习带来好处的训练技术。如下所示:
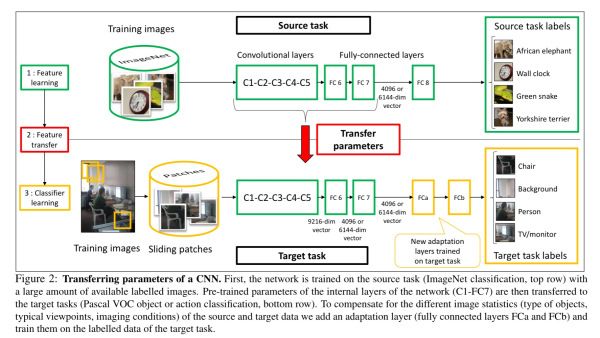
首先网络在源任务(ImageNet分类)上使用大量有标签数据进行训练,然后该网络的C1-FC7层被迁移到目标任务上(Pascal VOC目标或动作分类),为弥补源数据和目标数据的不同统计学信息,作者增加两个适应层FCa和FCb,使用目标任务的有标记数据进行训练。
ImageNet数据集包含单个位于中心的物体图像,而Pascal VOC数据集包含多个对象的复杂场景,其规模不同,背景也比较杂乱。如下图所示:

两个数据集物体的分布和尺寸会有所不同,有些物体可能也并没有同时出现在两个训练集中。作者使用滑动窗口并从每张图片抽取500个方块,通过使用一个整齐的空间网格或者超过50%重合相邻块在8个不同尺度下进行抽样。

为了对训练数据的块进行标注,作者测量了块P的边界框和有标记物体边界框真实值的重合程度。如果对指定类有充分重合,这个块就被标记为该类的正例。
该模型在VOC 2007目标识别任务上的性能能够达到了当前最新水平,在Pascal VOC 2012上也能够达到接近当前最新发展水平。作者也解释到这个网络学习到目标对象的尺寸和位置。
这篇论文表明卷积神经网络能够学习到丰富的中层图像特征,并且能够迁移到各种各样的视觉识别任务。
6. Distilling the knowledge in a neural network
作者首先从昆虫的生命过程带来神经网络的训练和设计的灵感讲起。
很多昆虫的幼年体形式适合从环境中吸取能量和营养,成年体则完全不同,能够适应各种移动和繁育的需求。在大规模机器学习中,尽管部署阶段有很多不同的需求,但人们在训练阶段总是使用很相似的模型。
只要复杂模型(如比较深的神经网络,又或者集成方法)能使从训练数据抽取特征变得更简单,并且能够找到一种将训练模型学到的东西迁移或者浓缩(distill)到一个精简的适合部署的形式,在训练的时候使用复杂模型又会怎样?那就要将尽可能多的知识从大模型压缩/提炼(distill)到小模型。
如果复杂模型泛化性能很好,比如是因为采用大量不同模型(ensemble)的预测平均值,以相同方法训练泛化的小模型在测试数据上的表现比用一般方法(训练ensemble模型的方法)训练到的小模型性能更好。
通过使用复杂模型产生的类概率作为软目标(soft targets)能够有效训练小模型。大模型学习到的不仅是目标对象的预测类(target prediction class),还有所有类的概率分布。这种思想(指distilling the knowledge,被称为蒸馏模型或知识提取)的本质就是训练小模型重新生成概率分布,而不仅仅是输出类。
神经网络使用softmax 输出层将每个类别的logit(表示为Zi),转化为概率qi输出,如下所示。通常温度T设为1。T越大,所有类别上的概率分布越趋向缓和。复杂模型在softmax层使用一个较高温度进行训练,在训练蒸馏模型(distilled model)时也使用相同的高温。
![]()
一个有两层隐藏层(包含1200个修正线性单元)的复杂大型神经网络使用dropout在60000个实例上进行训练,然后仿真训练共享权重的集合模型(an ensemble of models),仅仅出现67个测试错误。每层800个修正单元且无正则化的小模型网络发现了146个错误,然而同样大小的蒸馏模型(distilled model)仅有74个错误。
在自动语音识别(Automatic Speech Recognition,ASR)测试中,10个模型被精炼成一个性能良好的模型。如下图:

文章说明了将来自全模型(an ensemble)或者经过高度调整的大模型 (a large highly regularized model)的知识迁移到一个更小的蒸馏模型(distilled model)能够产生很好的效果。此外,一个经过长时间训练的大网络能够通过学习大量的专有网络(specialist nets)提升性能,而这些专有网络(specialist nets)能够学习到从易混淆的类簇中的类。
后记: Top 100 awesome deep learning papers 列表比较长,但是很有趣,作者后面会不断更新对其中的某些/全部论文的解读,如果有兴趣,可以关注作者的博客。
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
以上为译文
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Understanding, generalisation, and transfer learning in deep neural networks》,
作者:Adrian Colyer,译者:东东邪
文章为简译,更为详细的内容,请查看原文,如果原文网页打不开,请下载附件进行浏览。