【Paper】Data Mining:The WEKA data mining software: an update
论文原文
论文下载
论文被引:20211
论文年份:2009
WEKA:Weka是经过实践检验的开源机器学习软件,可以通过图形用户界面,标准终端应用程序或Java API进行访问。它被广泛用于教学,研究和工业应用,包含用于标准机器学习任务的大量内置工具,并且可以透明地访问scikit-learn,R和Deeplearning4j等知名工具箱。
WEKA官网
WEKA下载
The WEKA data mining software: an update
ABSTRACT
More than twelve years have elapsed since the first public release of WEKA. In that time, the software has been rewritten entirely from scratch, evolved substantially and now accompanies a text on data mining [35]. These days, WEKA enjoys widespread acceptance in both academia and business, has an active community, and has been downloaded more than 1.4 million times since being placed on SourceForge in April 2000. This paper provides an introduction to the WEKA workbench, reviews the history of the project, and, in light of the recent 3.6 stable release, briefly discusses what has been added since the last stable version (Weka 3.4) released in 2003.
自从WEKA首次公开发行以来,已经过去了十二年。 在那个时候,该软件已经完全从头开始重写,经过了实质性的发展,现在伴随着有关数据挖掘的文字[35]。 如今,WEKA在学术界和企业界都得到了广泛认可,并拥有活跃的社区,自2000年4月被放置在SourceForge上以来,其下载量已超过140万次。本文介绍了WEKA工作台,回顾了WEKA工作台的历史。 根据最近的3.6稳定版本,该项目简要讨论了自2003年最后一个稳定版本(Weka 3.4)以来增加的内容。
1. INTRODUCTION
威卡托知识分析环境(WEKA)产生于对统一工作台的需求,这将使研究人员可以轻松访问机器学习中的最新技术。 该项目于1992年启动之时,已有各种语言的学习算法可供使用,这些算法可在不同的平台上使用,并能以多种数据格式进行操作。 收集学习计划以对数据集进行比较研究的任务充其量是艰巨的。 可以预见,WEKA不仅将提供学习算法的工具箱,而且还将提供一个框架,研究人员可以在该框架内实现新的算法,而不必关心支持数据处理和方案评估的基础架构。
如今,WEKA被公认为数据挖掘和机器学习的标志性系统[22]。 它已在学术界和企业界获得了广泛的接受,并已成为数据挖掘研究的一种广泛使用的工具。 本书[35]是一本流行的数据挖掘教科书,在机器学习出版物中经常被引用。 如果没有将系统作为开源软件发布,那么成功的可能性很小。 让用户自由访问源代码使繁荣的社区能够开发并促进创建许多包含或扩展WEKA的项目。
在本文中,我们简要回顾了WEKA工作台和项目的历史,讨论了最近的3.6稳定版本中的新功能,并重点介绍了基于WEKA的许多项目。
2. THE WEKA WORKBENCH
WEKA项目旨在为研究人员和从业人员提供全面的机器学习算法和数据预处理工具集合。 它使用户可以快速尝试并在新数据集上比较不同的机器学习方法。 其模块化,可扩展的体系结构允许通过提供的大量基础学习算法和工具来构建复杂的数据挖掘过程。 得益于简单的API,插件机制和设施,该工具包的扩展非常容易,它可以自动将新的学习算法与WEKA的图形用户界面集成在一起。
工作台包括用于回归,分类,聚类,关联规则挖掘和属性选择的算法。数据可视化工具和许多预处理工具可以很好地满足对数据的初步探索。这些与学习方案的统计评估和学习结果的可视化相结合,可支持数据挖掘的过程模型,例如CRISP-DM [27]。
2.1 User Interfaces
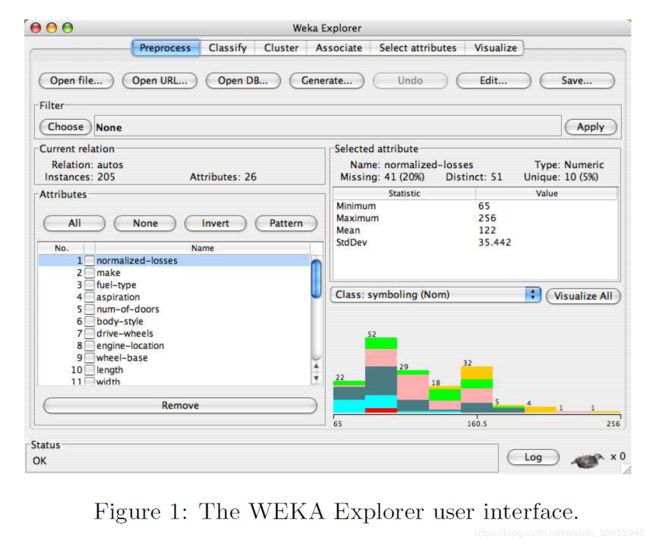
WEKA具有多个图形用户界面,可轻松访问基础功能。 主要的图形用户界面是“资源管理器”。 它具有基于面板的界面,其中不同的面板对应于不同的数据挖掘任务。 在名为“预处理”面板的第一个面板中,可以使用WEKA的数据预处理工具(称为“过滤器”)加载和转换数据。 该面板显示在图1.可以从各种来源加载数据,包括文件,URL和数据库。 支持的文件格式包括WEKA自己的ARFF格式,CSV,LibSVM格式和C4.5格式。 也可以使用人工数据源生成数据,并使用数据集编辑器手动编辑数据。
资源管理器中的第二个面板可访问WEKA的分类和回归算法。 相应的面板称为“分类”,因为回归技术被视为“连续类”的预测变量。 默认情况下,该面板针对在“预处理”面板中准备的数据集运行所选学习算法的交叉验证,以评估预测性能。 它还显示了从完整数据集构建的模型的文本表示形式。 但是,其他评估方式,例如 基于单独的测试集,也受支持。 如果适用,该面板还提供对模型图形表示的访问,例如 决策树。 此外,它可以可视化散点图中的预测误差,还可以通过ROC曲线和其他“阈值曲线”进行评估。 也可以在此面板中保存和加载模型。
除监督算法外,WEKA还支持非监督算法的应用,即聚类算法和关联规则挖掘方法。 可分别通过第三和第四面板在资源管理器中访问它们。 “群集”面板使用户可以对“预处理”面板中加载的数据运行聚类算法。 它提供了用于评估聚类性能的简单统计信息:用于统计聚类算法的基于似然的性能,以及与“真实”聚类成员资格的比较(如果在数据的属性之一中指定的话)。 如果适用,聚类结构的可视化也是可能的,并且必要时可以永久存储模型。
WEKA对聚类任务的支持不像其对分类和回归的支持那样广泛,但是与关联规则挖掘相比,它具有更多的聚类技术,到目前为止,它还是被忽略了。 但是,它确实包含了该领域最知名的算法以及其他一些算法的实现。 可以通过资源管理器中的“关联”面板访问这些方法。
在实际数据挖掘中,最重要的任务之一可能是确定数据中哪些属性是最可预测的属性。 为此,WEKA的资源管理器提供了一个用于选择属性的专用面板,即“选择属性”,该面板提供了用于识别数据集中最重要属性的各种算法和评估标准。 由于可以将不同的搜索方法与不同的评估标准组合在一起,因此可以配置各种可能的候选技术。 可以通过基于交叉验证的方法来验证所选属性集的鲁棒性。
请注意,属性选择面板主要用于探索性数据分析。 应使用WEKA的“ FilteredClassifier”(可通过“分类”面板访问)结合基础分类或回归算法来应用属性选择技术,以避免在获得的性能估算中引入乐观偏差。此警告还适用于“预处理”面板中可用的某些预处理工具(更具体地说,是受监管的工具)。
在许多实际应用中,数据可视化提供了重要的见解。 这些甚至可以避免使用机器学习和数据挖掘算法进行进一步分析。 但是,即使不是这种情况,他们也可能会通知您针对当前问题选择适当算法的过程。 资源管理器中的最后一个面板称为“可视化”,提供了一个颜色编码的散点图矩阵,并提供了通过在矩阵中选择各个图并选择要可视化的数据部分进行向下钻取的选项。 还可以获得有关各个数据点的信息,并以选定的数量随机扰动数据以发现模糊的数据。
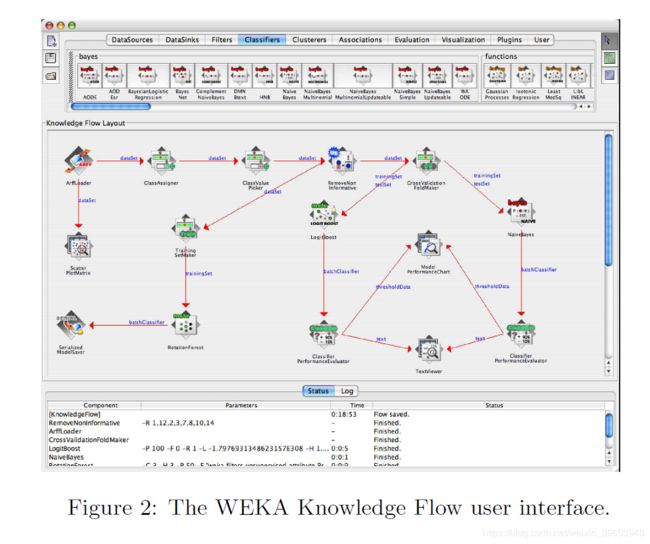
资源管理器设计用于基于批处理的数据处理:将训练数据全部加载到内存中,然后进行处理。 这可能不适用于涉及大型数据集的问题。 但是,WEKA确实具有一些允许增量模型构建的算法的实现,可以从命令行界面以增量模式应用这些算法。 这些算法的增量性质在资源管理器中被忽略,但是可以使用WEKA的一组图形用户界面中的最新功能(即所谓的“知识流”)加以利用,如图2所示。
资源管理器也可以处理大多数任务,这些任务也可以由知识流来处理。 但是,除了基于批次的训练外,它的数据流模型还可以通过处理节点进行增量更新,这些处理节点可以在将各个实例加载到适当的增量学习算法之前对其进行加载和预处理。 它还提供了可视化和评估节点。 一旦配置了互连处理节点的设置,就可以将其保存以备后用。
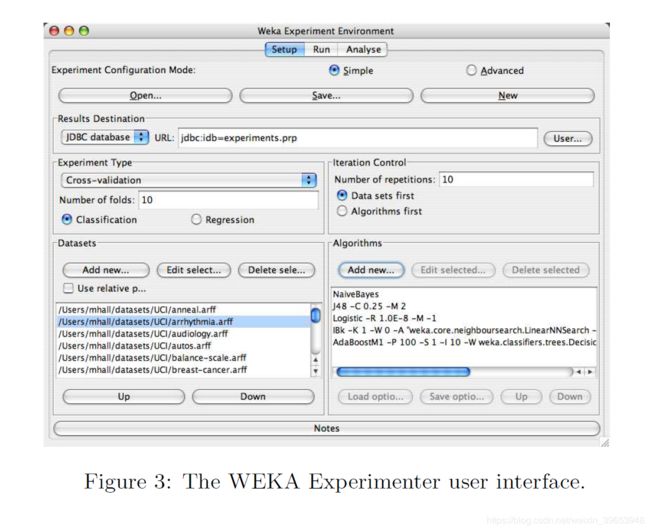
WEKA中的第三个主要图形用户界面是“ Experimenter”(参见图3)。 该接口旨在方便基于WEKA中可用的许多不同评估标准对算法的预测性能进行实验比较。 实验可以涉及跨多个数据集运行的多种算法。 例如,使用重复的交叉验证。 实验还可以分布在网络中的不同计算节点上,以减少单个节点的计算负荷。 设置实验后,可以将其保存为XML或二进制形式,以便在必要时可以重新访问。 配置和保存的实验也可以从命令行运行。
与WEKA的其他用户界面相比,数据挖掘从业者使用此实验仪的频率可能更低。但是,一旦在资源管理器中执行了初步实验,使用此替代接口为特定数据集或数据集的集合识别合适的算法通常会容易得多。
在此,我们要结束对WEKA主要图形用户界面的简要说明,并指出,无论需要哪种用户界面,重要的是要提供用于运行WEKA的Java虚拟机并具有足够的堆空间。 需要预先规定所需的内存量(应将其设置为低于所用计算机的物理内存量,以避免交换),这可能是在实践中成功应用WEKA的最大绊脚石。 另一方面,考虑到运行时间,与用C编写的程序相比,它不再具有明显的劣势,因为现代的实时编译器非常复杂,因此用C编写的程序经常反对Java来处理数据密集型处理任务。 Java虚拟机。
3. HISTORY OF THE WEKA PROJECT
WEKA项目由新西兰政府自1993年起资助,直到最近。 原始的资金申请于1992年末提交,并说明了该项目的目标:
“该计划旨在建立最先进的设施,用于开发机器学习技术,并研究其在新西兰经济的关键领域中的应用。具体来说,我们将创建一个用于机器学习的工作台,确定有助于其在农业行业中成功应用的因素,并开发新的机器学习方法和评估其有效性的方式。”
该项目的前几年专注于工作台的界面和基础架构的开发。 大多数实现都是用C语言完成的,其中一些评估程序用Prolog编写,而用户界面则使用TCL / TK生成。 在此期间,创建了WEKA1首字母缩写词,并创建了系统使用的属性关系文件格式(ARFF)。
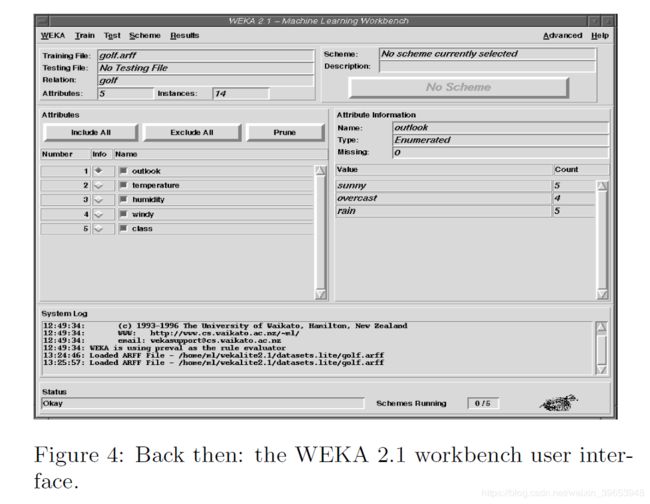
WEKA的第一版是内部发行的,发行于1994年。该软件处于测试阶段。 首次公开发行(版本2.1)于1996年10月发布。图4显示了WEKA 2.1的主要用户界面。 1997年7月,发布了WEKA 2.2。 它包括八种学习算法(其实现由原作者提供),使用基于外壳脚本的包装器和用C编写的数据预处理工具集成到WEKA中。WEKA2.2还具有基于Unix Makefiles的功能,用于 根据这些算法配置和运行大规模实验。
到现在为止,维护软件变得越来越困难。 诸如更改支持库,依赖性管理和配置复杂性等因素使开发人员难以完成这项工作,而安装体验也使用户感到沮丧。 大约在这个时候,决定完全用Java重写系统,包括学习算法的实现。 鉴于Java当时还不到两年,所以这是一个比较激进的决定。 此外,Java的运行时性能使其成为实现计算密集型机器学习算法的可疑选择。然而,人们决定,诸如“一次编写,随处运行”以及简单的打包和分发之类的优势超过了这些缺点,并将促进软件的广泛接受。
1998年5月,基于TCL / TK的系统(WEKA 2.3)最终发布了,并在1999年中期发布了100%Java WEKA 3.0。 WEKA的非图形版本伴随着Witten和Frank [34]的第一版数据挖掘书。 2003年11月,稳定版的WEKA(3.4)发行了,预计该书的第二版将出版[35]。 在3.0到3.4之间,开发了三个主要的图形用户界面。
4. NEW FEATURES SINCE WEKA 3.4
自3.4版以来,WEKA已添加了许多新功能-不仅以新的学习算法的形式,而且还包括预处理过滤器,可用性改进和对标准的支持。 截至撰写本文时,3.4代码行包含690个Java类文件,总共271,447行code2;在Java代码中,第2行包含在代码行中。 3.6代码行包含1,081个类文件,总共509,903行代码。 在本节中,我们将讨论WEKA 3.6中一些最重要的新功能。
4.1 Core
WEKA核心课程的最大变化是增加了关系值属性,以直接支持多实例学习问题[6]。 关系值属性允许其每个值引用另一组实例(通常在多实例设置中定义“袋子”)。WEKA数据格式的其他新增功能包括ARFF文件的XML格式,并支持在标准ARFF文件中指定实例权重。
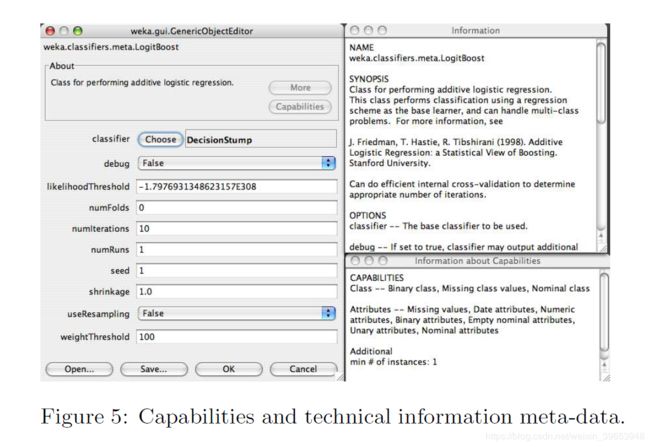
WEKA核心的另一个附加功能是“功能”元数据功能。 该框架允许各个学习算法和过滤器声明它们能够处理的数据特征。 反过来,这使WEKA的用户界面可以显示此信息,并向用户提供有关手头数据方案适用性的反馈。 同样,“ TechnicalInformation”类允许方案为它们实现的算法提供引用细节。 同样,此信息将通过用户界面自动格式化和公开。图5显示了LogitBoost分类器的技术信息和功能。
在WEKA 3.6中,使用ad2As(由Unix命令wc -l计算)也改善了日志记录功能。中央日志文件的位置。 该文件捕获所有写入WEKA中任何图形记录面板的信息,以及任何输出到标准输出和标准错误的信息。
4.2 Learning Schemes
自WEKA 3.4起,添加了许多新的学习算法,并对现有算法进行了改进。 后者的一个例子是基于实例的学习,现在支持可插拔的距离函数和新的数据结构(例如,球树和KD树),以加快对最近邻居的搜索。WEKA 3.6中的一些新分类算法包括:
- •贝叶斯逻辑回归[13]:文本分类的BLR方法,具有高斯先验和拉普拉斯先验。
- •最佳优先决策树[28]:使用最佳优先搜索策略构建决策树。
- •决策表朴素贝叶斯混合[15]:结合决策表和朴素贝叶斯的混合学习器。
- •判别多项式朴素贝叶斯[30]:一个简单的贝叶斯分类器,具有判别性参数学习,可用于文本分类。
- •功能树[12]:决策树在叶子处具有斜裂和线性函数。
- •高斯过程[26]:实现众所周知的高斯过程方法进行回归。
- •Simple CART [3]:决策树学习器,实现最小的成本复杂性修剪。
- •AODE的变体[39,17]:具有包含分解(AODEsr)和加权AODE(WAODE)的平均一依赖估计量。
- Wrapper classifiers:允许LibSVM [5]和LibLINEAR [9]第三方库提供的众所周知的算法在WEKA中使用。
除了这些算法之外,自3.4版以来,WEKA还添加了完整的多实例算法包,其中大多数首先分发在单独的MILK包中,用于多实例学习[37]。WEKA 3.6还具有新的“元”算法(new “meta” algorithms),可以围绕基础学习算法进行包装以扩大适用性或增强性能:
- •嵌套二分法[10; [8]:一种利用两类分类器的层次结构处理多类分类问题的方法。
- •Dagging [32]:类似于Bagging的元分类器,它将分类的训练数据子集提供给所选的基础学习算法。
- •旋转森林[24]:通过在已经使用主成分分析旋转的输入数据的随机选择子空间上训练基础学习者,来生成整体分类器。
聚类算法集也得到了以下的扩展:
- •CLOPE聚类器[38]:一种用于事务数据的快速聚类方案。
- •顺序信息瓶颈群集器[29]:主要用于文档群集的群集器。
4.3 Preprocessing Filters
正如WEKA中学习计划的清单在增加一样,预处理工具的数量也在增加。 WEKA 3.6中的一些新的过滤器包括:
- •添加分类:将分类器的预测添加到数据集。
- •添加ID:将ID属性添加到数据集-用于跟踪实例。
- •添加值:如果缺少标签,则将给定列表中的标签添加到属性中。
- •属性重新排序:更改数据集中属性的顺序。
- •四分位间距:根据四分位间距将实例标记为包含离群值和极值。
- •内核过滤器[2]:将给定的一组预测变量转换为内核矩阵。
- •数值清除器:用用户提供的默认值替换数值,以“清除”超出阈值或太接近特定值的数值。
- •数值到标称值:通过简单地将所有观察到的数值添加到标称值列表中,即可将数值属性转换为标称值。
- •分区多过滤器:将提供的过滤器列表应用于相应的属性范围集,并将结果合并为新的数据集。
- •多实例命题,反之亦然:在多实例格式之间进行转换。
- •随机子集:选择属性的随机子集。
- •RELAGGS [19]:使用聚合将关系数据转换为命题数据。
- •储层样本[33]:增量采样实例并执行储层采样,以对不适合主存储器的数据集进行下采样。
- •按表达式子集:根据用户指定的表达式过滤实例。
- •Wavelet [25]:对数据执行小波变换。
4.4 User Interfaces
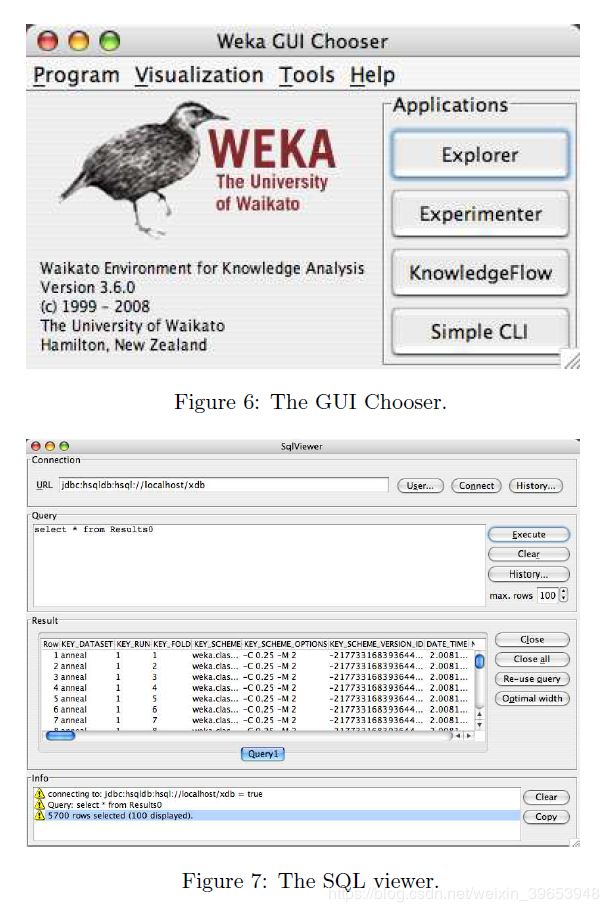
除了上述功能和技术信息元数据的公开内容外,自3.4版以来,WEKA中的GUI进行了进一步的改进和改进。 GUI选择器-WEKA的图形起点-经过重新设计,现在可以访问各种支持的用户界面,系统信息和日志记录信息,以及WEKA中的主要应用程序。 图6显示了经过改进的GUI选择器。
散点图,ROC曲线,树和图形都可以从“可视化”菜单下的条目中访问。 “工具”菜单提供了两个新的支持GUI:
- •SQL查看器:允许对数据库运行用户输入的SQL,并预览结果。 当按下“打开数据库”按钮时,资源管理器中也使用此用户界面从数据库中提取数据。
- •贝叶斯网络编辑器:提供用于构建,编辑和可视化贝叶斯网络分类器的图形环境。
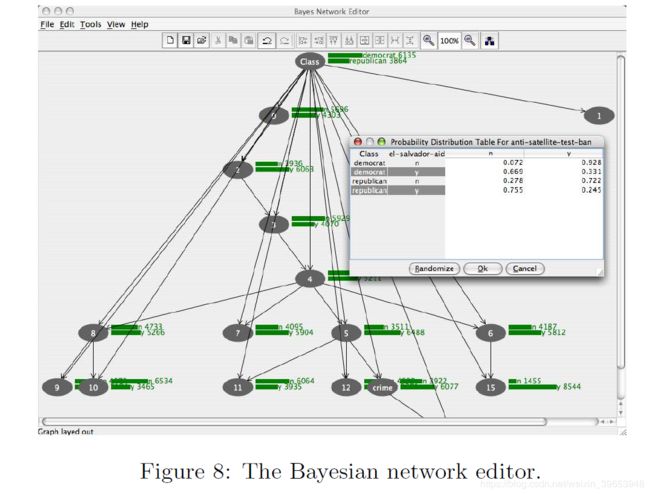
图7和8分别显示了SQL查看器和Bayes网络编辑器。通常,对合成数据评估算法很有用。
如本文前面所述,Explorer的用户界面现在具有WEKA的数据生成器工具。 可以从决策列表,径向基函数网络和贝叶斯网络以及经典的LED24域生成适合分类的人工数据。 可以根据数学表达式生成人工回归数据。 还有一些生成器,用于为聚类目的生成人工数据。知识流界面也得到了改进:它现在包括一个新的状态区域,可以同时提供有关数据挖掘过程中多个组件操作的反馈。 知识流的其他改进包括对关联规则挖掘的支持,对可视化多个ROC曲线的改进的支持以及插件机制。 生成人工数据集的灵活性。
4.5 Extensibility
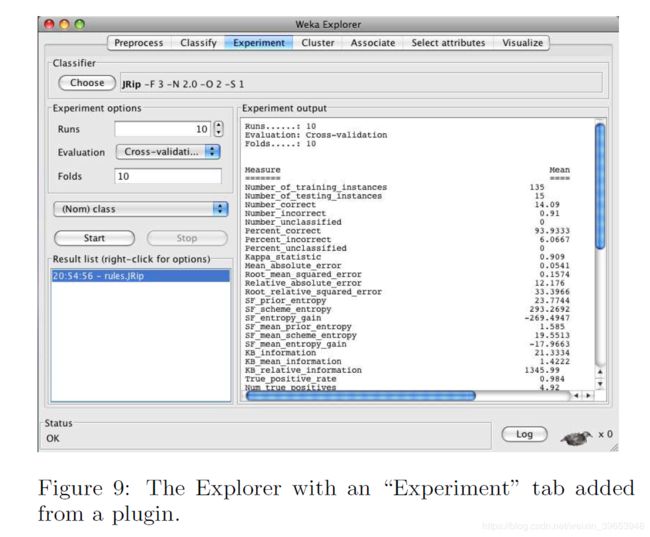
自3.4版以来,已向WEKA添加了许多插件机制。 这些使WEKA可以以各种方式扩展,而不必修改组成WEKA分布的类。通过编写扩展javax.swing.JPanel并实现接口weka.gui.explorer.Explorer.ExplorerPanel的类,可以轻松添加Explorer中的新选项卡。 图9显示了带有一个新选项卡的资源管理器,该选项卡由插件提供,用于运行简单的实验。 类似的机制允许将分类器错误,预测,树和图形的新可视化效果添加到资源管理器“分类”面板的历史记录列表中的弹出菜单中。 Knowledge Flow具有插件机制,只需将其jar文件(以及任何必要的支持jar文件)添加到用户主目录中的.knowledgeFlow / plugins目录中,即可合并新组件。 启动Knowledge Flow时会自动加载这些jar文件,并通过“插件”选项卡提供插件。
4.6 Standards and Interoperability
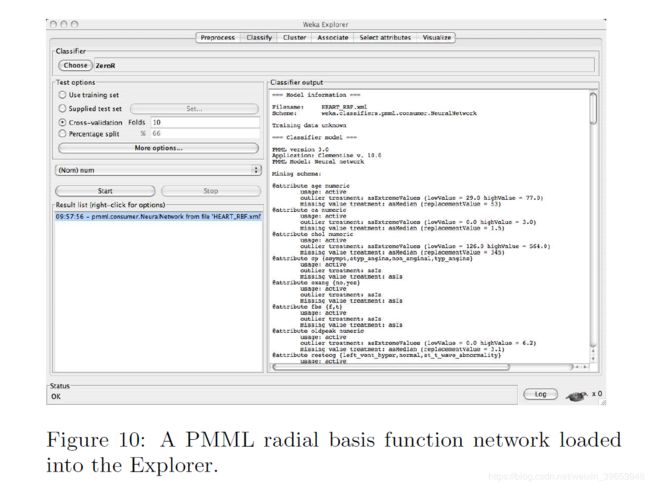
WEKA 3.6包括对导入PMML模型(预测建模标记语言)的支持。 PMML是一种与供应商无关的基于XML的标准,用于表达统计和数据挖掘模型,该标准已获得专有和开源数据挖掘供应商的广泛支持。 WEKA 3.6支持导入PMML回归,通用回归和神经网络模型类型。 WEKA的未来版本中将添加更多模型类型的导入,以及对导出PMML的支持。 图10显示了由Clementine系统创建并加载到资源管理器中的PMML径向基函数网络。
WEKA 3.6的另一个新功能是能够以众所周知的LibSVM和SVM-Light支持向量机实现[5]使用的格式读取和写入数据。 这是对新的LibSVM和LibLINEAR包装器分类器的补充。
5. PROJECTS BASED ON WEKA
有许多项目以某种方式扩展或包装WEKA。 在撰写本文时,WEKA网站3的“相关项目”网页上列出了46个此类项目。 其中一些包括:
- •自然语言处理系统。 有很多使用WEKA进行自然语言处理的工具:GATE是NLP工作台[11]。Balie执行语言识别,标记化,句子边界检测和命名实体识别[21]; Senseval-2是用于词义消除歧义的系统; Kea是一个自动提取关键短语的系统[36]。
- •生物学知识发现。 已经开发出了几种使用WEKA或基于WEKA的工具来辅助生物学应用中的数据分析:BioWEKA是WEKA的扩展,用于生物学,生物信息学和生物化学方面的任务[14]; Epitopes Toolkit(EpiT)是基于WEKA的平台,用于开发表位预测工具; maxdView和Mayday [7]提供了微阵列数据的可视化和分析。
- •分布式和并行数据挖掘。 有许多项目已将WEKA扩展为分布式数据挖掘。 Weka-Parallel提供了一个分布式交叉验证工具[4]。 GridWeka提供分布式评分和测试以及交叉验证[18]; FAEHIM和Weka4WS [31]使WEKA可以作为Web服务使用。
- •开源数据挖掘系统。 一些著名的开源数据挖掘系统提供了插件,以允许访问WEKA的算法。 康斯坦茨信息矿工(KNIME)和**RapidMiner [20]**是两个这样的系统。 R [23]统计计算环境还通过RWeka [16]包为WEKA提供了接口。
- •科学的工作流程环境。 开普勒Weka(Kepler Weka)项目将WEKA的所有功能集成到开普勒[1]开源科学工作流程平台中。
6. INTEGRATION WITH THE PENTAHO BI SUITE
Pentaho公司是商业开源商业智能软件的提供商。 Pentaho BI套件包括报告,交互式分析,仪表板,ETL /数据集成和数据挖掘。 每个项目都是一个单独的开源项目,由企业级开源BI平台捆绑在一起。 2006年底,WEKA被用作该套件的数据挖掘组件,此后一直集成到该平台中。
WEKA与Pentaho平台之间集成的重点是与Pentaho数据集成(PDI),也称为Kettle项目。 PDI是引擎驱动的流式ETL工具。 它丰富的提取和转换操作集,以及对多种数据库的支持,是WEKA数据过滤器的自然补充。 PDI可以轻松导出WEKA原生ARFF格式的数据集,以立即用于模型创建。
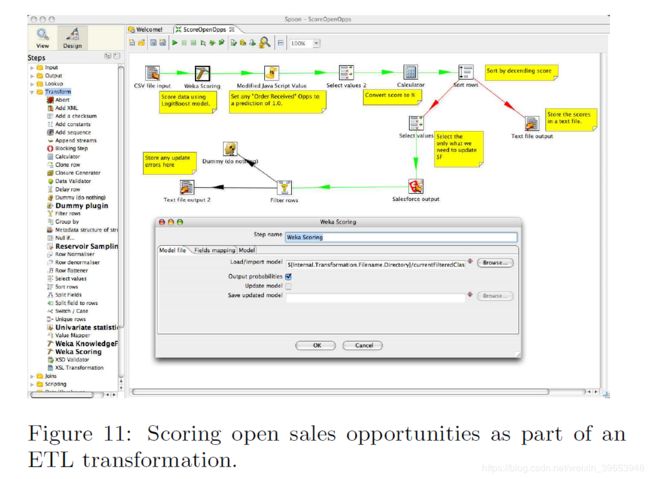
已经创建了几个特定于WEKA的转换步骤,以便PDI可以访问WEKA算法,并且可以用作评分平台和自动创建模型的工具。 其中第一个如图11所示,称为“ Weka评分”。 它使用户能够导入序列化的WEKA模型(分类,回归或聚类)或受支持的PMML模型,并使用它对数据进行评分,作为ETL转换的一部分。 在操作场景中,模型的预测性能可能会随着时间的流逝而降低。

这可能是由于数据基础分布的变化而引起的,有时也称为“概念漂移”。 如图12所示,针对PDI的第二个WEKA特定步骤允许用户执行整个知识流过程,作为转换的一部分。 这可以自动定期重新创建或刷新模型。
由于Pentaho BI服务器可以执行PDI转换并将其用作数据源,因此可以将数据挖掘的结果合并到整个BI流程中,并在报表,仪表板和分析视图中使用。
7. CONCLUSIONS
自从1992年成立以来的16年中,WEKA项目已经走了很长一段路。它所取得的成功证明了其社区和许多贡献者的热情。 释放WEKA作为开源软件并用Java实现它在其成功中起着不小的作用。 这两个因素确保不管任何特定机构或公司的承诺或健康状况,它都可维护和可修改。
8. ACKNOWLEDGMENTS
Many thanks to past and present members of the Waikato machine learning group and the external contributers for all the work they have put into WEKA.
9. REFERENCES
[1] I. Altintas, C. Berkley, E. Jaeger, M. Jones, B. Ludscher, and S. Mock. Kepler: An extensible system for design and execution of scientific workflows. In In SSDBM, pages 21–23, 2004.
[2] K. Bennett and M. Embrechts. An optimization perspective on kernel partial least squares regression. In J. S. et al., editor, Advances in Learning Theory: Methods, Models and Applications, volume 190 of NATO Science Series, Series III: Computer and System Sciences, pages 227–249. IOS Press, Amsterdam, The Netherlands, 2003.
[3] L. Breiman, J. H. Friedman, R. A. Olshen, and C. J.
Stone. Classification and Regression Trees. Wadsworth International Group, Belmont, California, 1984.
[4] S. Celis and D. R. Musicant. Weka-parallel: machine learning in parallel. Technical report, Carleton College, CS TR, 2002.
[5] C.-C. Chang and C.-J. Lin. LIBSVM: a library for support vector machines, 2001. Software available at http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[6] T. G. Dietterich, R. H. Lathrop, and T. Lozano-P´erez.
Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell., 89(1-2):31–71, 1997.
[7] J. Dietzsch, N. Gehlenborg, and K. Nieselt. Maydaya microarray data analysis workbench. Bioinformatics, 22(8):1010–1012, 2006.
[8] L. Dong, E. Frank, and S. Kramer. Ensembles of balanced nested dichotomies for multi-class problems. In Proc 9th European Conference on Principles and Practice of Knowledge Discovery in Databases, Porto, Portugal, pages 84–95. Springer, 2005.
[9] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR: A library for large linear classification. Journal of Machine Learning. Research, 9:1871–1874, 2008.
[10] E. Frank and S. Kramer. Ensembles of nested dichotomies for multi-class problems. In Proc 21st International Conference on Machine Learning, Banff, Canada, pages 305–312. ACM Press, 2004.
[11] R. Gaizauskas, H. Cunningham, Y. Wilks, P. Rodgers, and K. Humphreys. GATE: an environment to support research and development in natural language engineering.
In In Proceedings of the 8th IEEE International Conference on Tools with Artificial Intelligence, pages 58–66, 1996.
[12] J. Gama. Functional trees. Machine Learning, 55(3):219–250, 2004.
[13] A. Genkin, D. D. Lewis, and D. Madigan. Largescale bayesian logistic regression for text categorization.
Technical report, DIMACS, 2004.
[14] J. E. Gewehr, M. Szugat, and R. Zimmer. BioWeka— extending the weka framework for bioinformatics.
Bioinformatics, 23(5):651–653, 2007.
[15] M. Hall and E. Frank. Combining naive Bayes and decision tables. In Proc 21st Florida Artificial Intelligence Research Society Conference, Miami, Florida. AAAI Press, 2008.
[16] K. Hornik, A. Zeileis, T. Hothorn, and C. Buchta.
RWeka: An R Interface to Weka, 2009. R package version 0.3-16.
[17] L. Jiang and H. Zhang. Weightily averaged onedependence estimators. In Proceedings of the 9th Biennial Pacific Rim International Conference on Artificial Intelligence, PRICAI 2006, volume 4099 of LNAI, pages 970–974, 2006.
[18] R. Khoussainov, X. Zuo, and N. Kushmerick. Gridenabled Weka: A toolkit for machine learning on the grid. ERCIM News, 59, 2004.
[19] M.-A. Krogel and S. Wrobel. Facets of aggregation approaches to propositionalization. In T. Horvath and A. Yamamoto, editors, Work-in-Progress Track at the Thirteenth International Conference on Inductive Logic Programming (ILP), 2003.
[20] I. Mierswa, M. Wurst, R. Klinkenberg, M. Scholz, and T. Euler. Yale: Rapid prototyping for complex data mining tasks. In L. Ungar, M. Craven, D. Gunopulos, and T. Eliassi-Rad, editors, KDD ’06: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 935–940, New York, NY, USA, August 2006. ACM.
[21] D. Nadeau. Balie—baseline information extraction : Multilingual information extraction from text with machine learning and natural language techniques. Technical report, University of Ottawa, 2005.
[22] G. Piatetsky-Shapiro. KDnuggets news on SIGKDD service award. http://www.kdnuggets.com/news/ 2005/n13/2i.html, 2005.
[23] R Development Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2006. ISBN 3900051-07-0.
[24] J. J. Rodriguez, L. I. Kuncheva, and C. J. Alonso. Rotation forest: A new classifier ensemble method. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(10):1619–1630, 2006.
[25] K. Sandberg. The haar wavelet transform.
http://amath.colorado.edu/courses/5720/ 2000Spr/Labs/Haar/haar.html, 2000.
[26] M. Seeger. Gaussian processes for machine learning. International Journal of Neural Systems, 14:2004, 2004.
[27] C. Shearer. The CRISP-DM model: The new blueprint for data mining. Journal of Data Warehousing, 5(4), 2000.
[28] H. Shi. Best-first decision tree learning. Master’s thesis, University of Waikato, Hamilton, NZ, 2007. COMP594.
[29] N. Slonim, N. Friedman, and N. Tishby. Unsupervised document classification using sequential information maximization. In Proceedings of the 25th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 129–136, 2002.
[30] J. Su, H. Zhang, C. X. Ling, and S. Matwin. Discriminative parameter learning for bayesian networks. In ICML 2008, 2008.
[31] D. Talia, P. Trunfio, and O. Verta. Weka4ws: a wsrfenabled weka toolkit for distributed data mining on grids.
In Proc. of the 9th European Conference on Principles and Practice of Knowledge Discovery in Databases (PKDD 2005, pages 309–320. Springer-Verlag, 2005.
[32] K. M. Ting and I. H. Witten. Stacking bagged and dagged models. In D. H. Fisher, editor, Fourteenth international Conference on Machine Learning, pages 367–375, San Francisco, CA, 1997. Morgan Kaufmann Publishers.
[33] J. S. Vitter. Random sampling with a reservoir. ACM Transactions on Mathematical Software, 11(1):37–57, 1985.
[34] I. H. Witten and E. Frank. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations.
Morgan Kaufmann, San Francisco, 2000.
[35] I. H. Witten and E. Frank. Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann, San Francisco, 2 edition, 2005.
[36] I. H. Witten, G. W. Paynter, E. Frank, C. Gutwin, and C. G. Nevill-Manning. Kea: Practical automatic keyphrase extraction. In Y.-L. Theng and S. Foo, editors, Design and Usability of Digital Libraries: Case Studies in the Asia Pacific, pages 129–152. Information Science Publishing, London, 2005.
[37] X. Xu. Statistical learning in multiple instance problems.
Master’s thesis, Department of Computer Science, University of Waikato, 2003.
[38] Y. Yang, X. Guan, and J. You. CLOPE: a fast and effective clustering algorithm for transactional data. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 682–687. ACM New York, NY, USA, 2002.
[39] F. Zheng and G. I. Webb. Efficient lazy elimination for averaged-one dependence estimators. In Proceedings of the Twenty-third International Conference on Machine Learning (ICML 2006), pages 1113–1120. ACM Press, 2006.