yolov3 训练自己的数据集
历时4天,沐浴着22楼的阳光,围着服务器取暖,终于把权重文件给训练出来了,期间遇到一些问题,下面我会列举,以免大家走太多弯路;然后服务器配置还不正确,对于一个小白来说,简直崩溃,又去网上找了大量教程,终于把cuda版本改成了9.0,GPU能用了,但是opencv还是不能用,一会再去调一下。
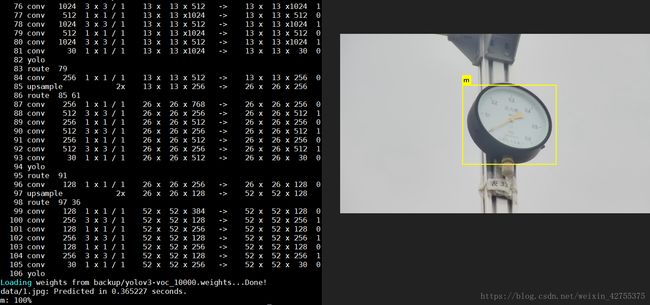
先放最后的测试结果,训练的是表的类型,一共有180张图片(训练集+测试集),有s,m,l,xl,xxl五种类型,这个是m的,由于部分原因,没有训练到最后(所以只生成了yolov3_10000.weight)
1.下载yolov3的工程
git clone https://github.com/pjreddie/darknet cd darknet
cd darknet2.修改配置文件
vi MakefileGPU = 1 #如果想用GPU进行训练
CUDNN = 1
OPENCV = 1
然后保存,
make #记住一定要make才能生效如果服务器配置都是好的,那基本会成功,不成功的话就检查一下cuda,cudnn,opencv这些版本是否兼容吧。
3.darknet里面有一个scripts文件夹,在scripts里面建一个VOCdevkit文件夹,然后在VOCdevkit里面建一个VOC2007文件夹,然后在VOC2007里面建三个文件夹,分别为Annotations,ImageSets,JPEGImages,然后在ImageSets里面建一个Main文件夹(这些是为了和下面的脚本文件路径)
scripts
--VOCdevkit
--VOC2007
--Annotations
--ImageSets
--Main
--JPEGImages
Annotations中放所有的xml文件;JPEGImages中放所有的图片;Main中放train.txt和val.txt。4.生成train.txt和val.txt
#这个小脚本是用来打开图片文件所在文件夹,把前149个用于训练的图片的名称保存在train.txt,后31个用于验证的图片保存在val.txt,这是一个python文件,别忘记自己修改路径,不能完全照搬,先看一下代码,修改好之后运行就会生成两个txt
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/lijintao/darknet/scripts/VOCdevkit/VOC2007/JPEGImages/'#地址是所有图片的保存地点
dest='/home/lijintao/darknet/train.txt' #保存train.txt的地址
dest2='/home/lijintao/darknet/val.txt' #保存val.txt的地址
file_list=os.listdir(source_folder) #赋值图片所在文件夹的文件列表
train_file=open(dest,'a') #打开文件
val_file=open(dest2,'a') #打开文件
for file_obj in file_list: #访问文件列表中的每一个文件
file_path=os.path.join(source_folder,file_obj)
#file_path保存每一个文件的完整路径
file_name,file_extend=os.path.splitext(file_obj)
#file_name 保存文件的名字,file_extend保存文件扩展名
file_num=int(file_name)
#把每一个文件命str转换为 数字 int型 每一文件名字都是由四位数字组成的 如 0201 代表 201 高位补零
if(file_num<150): #保留149个文件用于训练
#print file_num
train_file.write(file_name+'\n') #用于训练前149个的图片路径保存在train.txt里面,结尾加回车换行
else :
val_file.write(file_name+'\n') #其余的文件保存在val.txt里面
train_file.close()#关闭文件
val_file.close()5.修改voc_label.py
sets=[('2007', 'train'), ('2007', 'val')]
classes = ["s", "m", "l", "xl", "xxl"]
os.system("cat 2007_train.txt 2007_val.txt > train.txt") #倒数第二行改成这样,最后一行删掉6.执行voc_label.py
在scripts下生成了2007_train.txt 和 2007_val.txt,分别存放了训练集和测试集图片的路径。
7.下载预训练模型
wget https://pjreddie.com/media/files/darknet53.conv.748.修改cfg/voc.data
classes= 5 #classes为训练样本集的类别总数
train = /home/lijintao/darknet/scripts/2007_train.txt #train的路径为训练样本集所在的路径
valid = /home/lijintao/darknet/scripts/2007_val.txt #valid的路径为验证样本集所在的路径
names = data/voc.names #names的路径为data/voc.names文件所在的路径
backup = backup9.修改data/voc.names
s
m
l
xl
xxl
#这个根据自己需要修改10.修改cfg/yolov3-voc.cfg
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8 #---------------修改
......
[convolutional]
size=1
stride=1
pad=1
filters=30 #---------------修改
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=5 #---------------修改
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0 #---------------修改
......
[convolutional]
size=1
stride=1
pad=1
filters=30 #---------------修改
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=5 #---------------修改
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0 #---------------修改
......
[convolutional]
size=1
stride=1
pad=1
filters=30 #---------------修改
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=5 #---------------修改
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=0 #---------------修改
标记的地方需要修改,classes是你的分类数,filters=3*(classes+5),random=0即关闭多尺度训练如果还不是很清楚,可以看一下这篇blog
11.开始训练
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpus 0,1,2,312.开始测试
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_10000.weights data/1.jpg这样就生成了一开始的图片了。
这中间可能会遇到一些问题,要耐心分析并去网上多搜答案,我也是小白,如果有什么错误,还望大佬们不吝指正,不说了,修理服务器去了。