【项目】新冠肺炎疫情期间网民情绪识别——Python文本分类
目录
- 任务描述
- 数据描述
- 读取数据
- 数据预处理
- 可视化
- word2vec
- 模型框架及拟合
- 结果展示
- 改进与思考
- 说明
任务描述
2019新型冠状病毒(COVID-19)感染的肺炎疫情发生对人们生活生产的方方面面产生了重要影响,并引发国内舆论的广泛关注,众多网民参与疫情相关话题的讨论。为了帮助政府掌握真实社会舆论情况,科学高效地做好防控宣传和舆情引导工作,针对疫情相关话题开展网民情绪识别的任务。
具体任务是给定微博ID和微博内容,设计算法对微博内容进行情绪识别,判断微博内容是积极的、消极的还是中性的。
数据描述
数据集nCoV_100k.labled.csv包含10万条用户标注的微博数据,包括微博id,发布时间,发布人账号,中文内容,微博图片,微博视频,情感倾向等多条数据,具体格式如下:
- 微博id,格式为整型。
- 微博发布时间,格式为xx月xx日 xx:xx。
- 发布人账号,格式为字符串。
- 微博中文内容,格式为字符串。
- 微博图片,格式为url超链接,[]代表不含图片。
- 微博视频,格式为url超链接,[]代表不含视频。
- 情感倾向,取值为{1,0,-1}。
读取数据
由于文件是GB2312格式编码的文件,需要将其转化为utf-8格式的文件进行读取数据预处理。
//转换编码
def re_encode(path): //定义编码转换函数
with open(path, 'r', encoding='GB2312', errors='ignore') as file:
lines = file.readlines()
with open(path, 'w', encoding='utf-8') as file:
file.write(''.join(lines))
re_encode('nCov_10k_test.csv') //测试集转换编码
re_encode('nCoV_100k_train.labled.csv') //训练集转换编码
将转换好的数据读取进来,以便操作。
//读取网民情绪的文件
data = pd.read_csv('nCoV_100k_train.labled.csv',
encoding='utf-8',
engine ='python')
data.head()
简单查看一下前5条结果,发现读取正确。
微博id 微博发布时间 发布人账号 微博中文内容 微博图片 微博视频 情感倾向
0 4456072029125500 01月01日 23:50 存曦1988 写在年末冬初孩子流感的第五天,我们仍然没有忘记热情拥抱这2020年的第一天。带着一丝迷信,早... ['https://ww2.sinaimg.cn/orj360/005VnA1zly1gah... [] 0
1 4456074167480980 01月01日 23:58 LunaKrys 开年大模型…累到以为自己发烧了腰疼膝盖疼腿疼胳膊疼脖子疼#Luna的Krystallife#? [] [] -1
2 4456054253264520 01月01日 22:39 小王爷学辩论o_O 邱晨这就是我爹,爹,发烧快好,毕竟美好的假期拿来养病不太好,假期还是要好好享受快乐,爹,新年... ['https://ww2.sinaimg.cn/thumb150/006ymYXKgy1g... [] 1
3 4456061509126470 01月01日 23:08 芩r 新年的第一天感冒又发烧的也太衰了但是我要想着明天一定会好的? ['https://ww2.sinaimg.cn/orj360/005FL9LZgy1gah... [] 1
4 4455979322528190 01月01日 17:42 changlwj 问:我们意念里有坏的想法了,天神就会给记下来,那如果有好的想法也会被记下来吗?答:那当然了。... [] [] 1
数据预处理
数据预处理的一般包括:
- 缺失值处理
- 特征规范化
- 离散与连续化
- 去噪
首先查看一下数据集的基本特征:
//查看训练集各个变量的类型,数量等信息,同时查看标签数据
data.info(memory_usage='deep')
data['情感倾向'].value_counts()
| 变量名 | 数据量 | 数据类型 |
|---|---|---|
| 微博id | 100000 |
non-null int64 |
| 微博发布时间 | 100000 |
non-null object |
| 发布人账号 | 99978 |
non-null object |
| 微博中文内容 | 99646 |
non-null object |
| 微博图片 | 100000 |
non-null object |
| 微博视频 | 100000 |
non-null object |
| 情感倾向 | 99919 |
non-null object |
从上表中很明显可以看出共有10000条数据,但是发布人账号、微博中文内容、情感倾向等变量从在明显的缺失值。
同时观察情感倾向这一变量中的统计值如下表:
| 情感倾向 | 数量 |
|---|---|
0 |
57619 |
1 |
25392 |
-1 |
16902 |
10 |
1 |
- |
1 |
-2 |
1 |
9 |
1 |
· |
1 |
4 |
1 |
发现中文内容和情感倾向两项内容与数据总量不符, 微博中文内容项只有99646条值,说明有些微博是没有文字内容的,很明显,其中0代表中立,1代表积极态度,而-1则代表消极态度,同时表格中存在一些不合理的异常值,例如10,-等值,这些错误的分类标签会影响我们的分类效果,需要对数据进行清洗,由于数据量不是很多,我们考虑将这些值删除。
同时可以看到标签数据的数据类型是object,由于接下来的模型需要,我们考虑将其转化为数值型。
//将异常值去除
data = data[data['情感倾向'].isin(['-1','0','1'])]
//将label转化为整型
data['情感倾向'] = data['情感倾向'].astype(np.int32)
| 变量名 | 数据量 | 数据类型 |
|---|---|---|
| 微博id | 99913 |
non-null int64 |
| 微博发布时间 | 99913 |
non-null object |
| 发布人账号 | 99913 |
non-null object |
| 微博中文内容 | 99560 |
non-null object |
| 微博图片 | 99913 |
non-null object |
| 微博视频 | 99913 |
non-null object |
| 情感倾向 | 99913 |
non-null int32 |
可以发现去除那些异常的标签数据之后,有效数据变为99913条,虽然仍然可以看到有些微博文本内容有缺失值,但文本数据不适合填充,可以考虑将其标签数据设置为0,表示中立态度。
将数据集分割为训练数据集和测试数据集。分割后的数据集有79930条训练集和19983条测试集。
可视化
接下来对数据进行一些简单的可视化操作,便于观察数据的分布和趋势,以便参数选择和结果分析。
主要查看了以下四方面的内容
- 三种情感倾向的分布情况
df_train['情感倾向'].value_counts()/df_train['情感倾向'].count()
(df_train['情感倾向'].value_counts()/df_train['情感倾向'].count()).plot.bar()
plt.show()
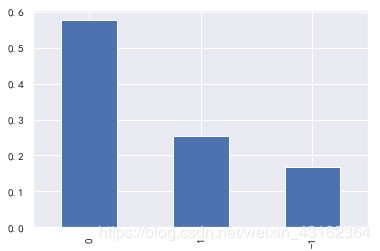
可以看出在10000条微博文本中有大概60%是持中立态度的,25%持积极态度,还有约15%持消极态度。
2. 三种感情倾向的数量变化和占比变化情况
df_train['time'] = pd.to_datetime('2020年' + df_train['微博发布时间'], format='%Y年%m月%d日 %H:%M', errors='ignore')
df_train['date'] = df_train['time'].dt.date //转换日期格式
//对数据按照日期和情感倾向进行分类
date_influence = df_train.groupby(['date','情感倾向'],as_index=False).count()
sns.relplot(x="date", y="微博id",kind='line', hue='情感倾向',palette=["b", "r",'g'],data=date_influence)
plt.xticks(rotation=45,fontsize=12)
plt.xlabel('日期',fontsize=15)
plt.ylabel('数量',fontsize=15)
plt.title('微博数量分布图',fontsize=15)
plt.show()
date_influence = date_influence.merge(df_train.groupby('date',as_index=False)['情感倾向'].count().rename(columns={'情感倾向':'weibo_count'}),how='left',on='date')
date_influence['weibo_rate'] = date_influence['微博id']/date_influence['weibo_count']
sns.relplot(x="date", y="weibo_rate", kind="line", hue='情感倾向',palette=["b", "r",'g'],data=date_influence)
plt.xticks(rotation=45,fontsize=12)
plt.xlabel('日期',fontsize=15)
plt.ylabel('数量',fontsize=15)
plt.title('微博情感占比分布图',fontsize=15)
plt.show()


从上图可以直观的看到三种数据在数量上都有不同程度的增加,在1月中旬的时候三种评论都有显著增加,推测可能是有新的疫情数据或大事件发布,例如武汉公开瞒报数据等情况,但是在比例上三种评论的比例基本没有变化。
3. 评论的长度分布
df_train['char_length'] = df_train['微博中文内容'].astype(str).apply(len) #计算每条微博评论的长度
sns.distplot(df_train['char_length'],kde=False)
plt.xlabel('长度',fontsize=15)
plt.ylabel('数量',fontsize=15)
plt.title('评论长度分布',fontsize=15)
plt.show()
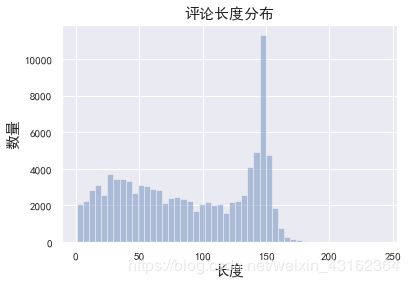
大部分分布在150词左右,少于150词的基本维持在2000条,大于150词的微博就很少了。因此在神经网络设定句子长度时,可以设置为200或高于150的数值,以免丢失太多信息。
def label(data):
if data <125:
return '小于125'
elif data<150 and data>125:
return '125-150'
else:
return '大于150'
df_train['length_label']=df_train['char_length'].apply(label)
sns.countplot('情感倾向',hue='length_label',data=df_train)
plt.xlabel('长度',fontsize=15)
plt.ylabel('数量',fontsize=15)
plt.title('评论长度分布',fontsize=15)
plt.legend(loc='upper right')
plt.show()

按照评论种类分别查看长度,可以看出在不同种类的评论中,评论的长度分布并没有很大的区别。
- 词云
import wordcloud
import re
WC = wordcloud.WordCloud(font_path = 'C://Windows//Fonts/simfang.ttf',max_words=2000,height= 400,width=400,background_color='white',repeat=False,mode='RGBA') //设置词云图对象属性
st1 = re.sub('[,。、“”‘ ’]','',str(train_text)) //使用正则表达式将符号替换掉。
conten = ' '.join(jieba.lcut(st1)) //此处分词之间要有空格隔开,联想到英文书写方式,每个单词之间都有一个空格。
con = WC.generate(conten)
plt.imshow(con)
plt.axis("off")
WC.to_file('wordcloud.png')
之前都是对文本的外部属性的分析,比如长度,比例等等,这里主要对文本的内容进行分析,可以通过词频等方法观察到文本的主题。

可以看到内容主要围绕新型冠状肺炎的话题,其中还有一些中国加油,武汉加油的内容,内容大部分比较积极。
word2vec
原理知识可以参考 通俗理解word2vec。
处理文本语言,需要将这些文本转化为计算机能够识别的数据。
第一步对微博文本进行分词,本文采用的是jieba分词库。
对疫情的微博文本进行分词,采用精确模式,以分割数据集后的第一条数据为例:
原文如下:
'#男子解除隔离10天后发病##男子解除隔离10天后发病#【山东日照:一男子解除隔离10天后发病妻孩三人皆为无症状感染者】2月15日,山东省新增的新冠肺炎确诊病例中,一名42岁的日照男子刘某和家人,曾与确诊病例有接触,随后刘某和妻子于某燕(38岁)、女儿(11岁)、儿子(5岁)均被集中隔离医学观察。四人在?展开全文c'
分词后的结果如下,其中每个词都以空格为间隔:
'# 男子 解除 隔离 10 天后 发病 ## 男子 解除 隔离 10 天后 发病 # 【 山东 日照 : 一 男子 解除 隔离 10 天后 发病 妻孩三人 皆 为 无症状 感染者 】 2 月 15 日 , 山东省 新增 的 新冠 肺炎 确诊 病例 中 , 一名 42 岁 的 日照 男子 刘某 和 家人 , 曾 与 确诊 病例 有 接触 , 随后 刘某 和 妻子 于 某燕 ( 38 岁 ) 、 女儿 ( 11 岁 ) 、 儿子 ( 5 岁 ) 均 被 集中 隔离 医学观察 。 四人 在 ? 展开 全文 c'
将这些文本分词后统计其词频放在hash表里,统计这些词在所有的训练样本中的出现次数,并根据词语的出现频率由高到低排序。
//分词取得该词的个数
import jieba
num_index={}
train_texts=[]
for sentence in train_text:
sequences=jieba.lcut(str(sentence),cut_all=False,HMM=True)
train_texts.append(sequences)
for sequence in sequences:
num_index[sequence]=num_index.get(sequence,0)+1
print('found %s words'%len(num_index))
test_texts=[]
for sentence in test_text:
sequences=jieba.lcut(str(sentence),cut_all=False,HMM=True)
test_texts.append(sequences)
//按照词语出现的频率排序
num_index=sorted(num_index.items(),key = lambda x:x[1],reverse = True)
//建立词索引
word_index={}
i=1
for key in num_index:
word_index[key[0]]=i
i+=1
按照词语出现次数的顺序,创建词的索引字典,即对最常出现的词索引为1,例如在以上所有微博文本中词语“的”出现频率最高,则“的”的词索引为1,之后依次增加,最后得到索引字典,由于索引字典很长,下面只展示一部分索引数据:
| 词 | 索引 |
|---|---|
| , | 1 |
| 的 | 2 |
| ? | 3 |
| / | 4 |
| # | 5 |
发现是有很多没有意义的符号的,可以尝试将这些符号去掉再创建词索引,这里不再展示。
根据刚刚的索引字典,就将微博数据整数化,也就是说将词转化为其索引数字,以便输入到神经网络中去。
train_texts_int=[]
test_texts_int=[]
for sentences in train_texts:
sentence_int=[]
for sentence in sentences:
if word_index[sentence]<10000:
sentence_int.append(word_index[sentence])
else:
sentence_int.append(0)
train_texts_int.append(sentence_int)
print("训练集前五条数据为:\n",train_texts_int[:5])
for sentences in test_texts:
sentence_int=[]
for sentence in sentences:
if word_index.get(sentence,0)<10000 :
sentence_int.append(word_index.get(sentence,0))
else:
sentence_int.append(0)
test_texts_int.append(sentence_int)
print("测试集前五条数据为:\n",test_texts_int[:5])
以上程序分别将训练集和测试集的每一条文本转化成相对应的整形数据,训练集和测试集的第一条文本转化为整型数据分别如下:
训练集:
[1005, 7865, 188, 2, 52, 2586, 37, 257, 1666, 746, 212, 0, 2651, 2, 0, 1842, 230, 4662, 1, 5533, 37, 81, 5979, 4852, 8, 540, 1241]
测试集:
[59, 944, 4613, 8, 5183, 31, 175, 4613, 2046, 84, 29, 352, 0, 0, 2349, 71, 0, 7455, 246, 204, 8, 604, 3090, 0, 115, 944, 3]
由于微博文本的长度不一,需要对文本的长度进行固定,根据之前文本长度的可视化分析,我们将微博文本截取到200的长度,不足的用0补全,超过的截取掉不要。
maxlen=200
x_train = pad_sequences(train_texts_int, maxlen=maxlen)
x_test = pad_sequences(test_texts_int, maxlen=maxlen)
本文对于标签值采用one-hot编码的方式将每一个标签转化为向量。
def to_one_hot(labels, dimension=3):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
// Our vectorized training labels(将训练标签向量化)
one_hot_train_labels = to_one_hot(train_label)
// Our vectorized test labels(将测试标签向量化)
one_hot_test_labels = to_one_hot(test_label)
对于自变量(也就是微博文本)则采用神经网络中的embedding层来训练常出现的前10000个词得到相应的词嵌入向量,embedding层经过训练后得到的是一个(samples,100,200)的三维张量,其中每个词的词嵌入长度是100,每条微博文本有200个词。
模型框架及拟合
模型采用LSTM层来防止早期信号的消失,采用25%随机失活防止过拟合,最后用全连接层作为输出层。
max_words=10000
embedding_dim=100
//模型框架搭建
model = Sequential()
//加入embedding层,设置输入维度为(10000,100)
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
//长短期记忆层
model.add(LSTM(128,recurrent_dropout=0.25))
//随机失活
model.add(Dropout(0.25))
//全连接层
model.add(Dense(3, activation='softmax'))
模型内的参数变化如下:
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 100) 1000000
_________________________________________________________________
lstm_3 (LSTM) (None, 128) 117248
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_3 (Dense) (None, 3) 387
=================================================================
Total params: 1,117,635
Trainable params: 1,117,635
Non-trainable params: 0
_________________________________________________________________
对模型在训练集上进行拟合,在测试集上进行验证。
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
//拟合模型
history = model.fit(x_train, one_hot_train_labels,
epochs=10,
batch_size=128,
validation_data=(x_test, one_hot_test_labels))
结果展示
对模型进行编译后运行,迭代30次(发现10次后精度下降后改为10次)
Train on 79930 samples, validate on 19983 samples
Epoch 1/30
79930/79930 [==============================] - 182s 2ms/step - loss: 0.7387 - accuracy: 0.6825 - val_loss: 0.6804 - val_accuracy: 0.7175
Epoch 2/30
79930/79930 [==============================] - 177s 2ms/step - loss: 0.6408 - accuracy: 0.7281 - val_loss: 0.6311 - val_accuracy: 0.7275
Epoch 3/30
79930/79930 [==============================] - 176s 2ms/step - loss: 0.6076 - accuracy: 0.7424 - val_loss: 0.6336 - val_accuracy: 0.7243
Epoch 4/30
79930/79930 [==============================] - 176s 2ms/step - loss: 0.5837 - accuracy: 0.7549 - val_loss: 0.6340 - val_accuracy: 0.7287
Epoch 5/30
79930/79930 [==============================] - 176s 2ms/step - loss: 0.5675 - accuracy: 0.7620 - val_loss: 0.6226 - val_accuracy: 0.7361
Epoch 6/30
79930/79930 [==============================] - 178s 2ms/step - loss: 0.5502 - accuracy: 0.7698 - val_loss: 0.6272 - val_accuracy: 0.7352
Epoch 7/30
79930/79930 [==============================] - 177s 2ms/step - loss: 0.5354 - accuracy: 0.7771 - val_loss: 0.6189 - val_accuracy: 0.7297
Epoch 8/30
79930/79930 [==============================] - 178s 2ms/step - loss: 0.5203 - accuracy: 0.7846 - val_loss: 0.6220 - val_accuracy: 0.7282
Epoch 9/30
79930/79930 [==============================] - 178s 2ms/step - loss: 0.5081 - accuracy: 0.7904 - val_loss: 0.6262 - val_accuracy: 0.7351
Epoch 10/30
79930/79930 [==============================] - 177s 2ms/step - loss: 0.4934 - accuracy: 0.7979 - val_loss: 0.6323 - val_accuracy: 0.7297
//损失函数和准确率可视化
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
可以看到虽然训练精度随着迭代次数的增加不断上升,甚至达到了95%的精度,但其在测试集上的效果在迭代大概9-10次左右就开始明显下降,产生了过拟合。

但验证集的精度仍然达到了73%左右,效果有待改进。
改进与思考
- 在模型迭代到10次后发现精度开始下降,损失函数也开始上升,出现了比较严重的过拟合,可以尝试更改学习率,可以让学习率随着迭代次数的增加线性或者倍数减少,效果应该会更好。
- 模型只考虑了文本数据的分析,数据中还提供了图片、视频等数据没有利用,方法暂时没想到。
- 训练集只有8万左右,在自然语言处理上不算多,可以尝试使用Bert等作为预训练模型作为词嵌入的输入,这样既可以提高效率,也能提高精度,同时由于文本是和疫情高度相关的,也需要在预训练模型的基础上微调训练,以便达到更好的效果,但是电脑设备只有CPU,尝试未果。
说明
文章参考了很多github、百度AI和CSDN博客上大牛的思路,以下贴出部分连接,有兴趣的可以直接查看。
利用500万条微博语料对微博评论进行情感分析
网民情绪情感分析 DataFountain
python爬虫爬取微博之战疫情用户评论及详情
机器学习项目(四)网民情绪识别 (一)
基于PaddleHub的网民情绪识别