大数据实战-callLog项目(通话记录数据分析)之数据采集
文章目录
- 前言
- HBase
- 创建表
- kafka
- 创建topic
- 消费topic
- 控制台消费者
- HBase消费者
- Maven依赖
- 消费者组设置
- 插入方法封装
- 构造rowKey
- main方法
- flume
- 代码
- 运行
- 运行数据生成器
- 运行flume
- 运行kafka控制台消费者
- 运行HBase消费者
- 博客链接
前言
如果你只是想锻炼一下数据采集而不是callLog项目的所有环节,那么可以直接下载我的文件来进行数据采集。
HBase
首先确认dfs和HBase正常运行,然后进入HBase SHELL
创建表
我在创建的时候指定了三个分区点,也就是四个分区。
create 'callLog','info' ,SPLITS=>['00|','01|','02|']

kafka
首先确认zk和kafka都正常运行。
创建topic
--zookeeper node102:2181 --create --topic callLog --partitions 1 --replication-factor 1创建一个新的topic
,注意修改成自己的ip
kafka-topics.sh --zookeeper node102:2181 --describe --topic callLog可以查看一下详细情况

消费topic
控制台消费者
有了topic之后可以先开启控制台消费者,等待着数据,后面测试用的上。也可以之后用的时候再打开。
![]()
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group hbase--reset-offsets --to-offset 0 --topic callLog --execute这个命令也可能在调试的时候用上
HBase消费者
需要自己编写,这也是数据采集中最麻烦的一步了
Maven依赖
确认是否有kafka和hbase的依赖
org.apache.kafka
kafka-clients
0.11.0.3
org.apache.hbase
hbase-server
1.4.5
org.apache.hbase
hbase-client
1.4.5
消费者组设置
为了代码可读性更强,我把设置消费者的代码封装起来了
private static KafkaConsumer setConsumer(){
Properties props = new Properties();
// 定义 kakfa 服务的地址,不需要将所有 broker 指定上
props.put("bootstrap.servers", "node103:9092");
// 制定 consumer group
props.put("group.id", "hbase");
// 是否自动确认 offset
props.put("enable.auto.commit", "true");
// 自动确认 offset 的时间间隔
props.put("auto.commit.interval.ms", "1000");
// key 的序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// value 的序列化类
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 定义 consumer
KafkaConsumer consumer = new KafkaConsumer<>(props);
// 消费者订阅的 topic, 可同时订阅多个
consumer.subscribe(Arrays.asList("callLog"));
return consumer;
}
插入方法封装
//为了利用循环放入Put,我将要插入的数据按顺序排好;针对每个数据得写单独的Put代码量太大
private static void insert(HBaseUtil util,String[] values){
List putList = new ArrayList();
String rowKey = genRowKey(values[4], values);
//columns决定着参数values的顺序
String[] columns = {"call", "call_name", "call2", "call2_name",
"date_time", "date_time_ts", "duration", "flag"};
for(int i=0;i 构造rowKey
这是技巧性非常强的地方,讲究整体分散,局部聚合。
首先整体分散,需要制定合理的分区规则进行分区,避免热点问题,我这里用的规则是
int pid = str.hashCode()&Integer.MAX_VALUE % 3;这样得到的结果应该能较为均匀的分在HBase的三个分区当中
其次局部聚合,最好能通过指定起止位置来获得所有想要的数据,避免全表扫描。
这就决定着上面的str如何选取了,我这里选的是主叫人拼接上日期字符串,例如18481678295_2019-07-11,这样如果我想知道某人一段时间内的通话信息,就可以用其手机号拼接上起止时间字符串作为起止位置来得到数据。
但是得到的只是作为主叫人的信息,作为被叫人的还是得全表扫描,为此每条数据的rowKey会调换主叫人和被叫人再存一次,所以需要添加一个flag区分原纪录和新增记录。
最终的rowKey形式为’pid_call_dataStr_call2_calldurtion_flag’
接着就封装成一个方法,以供调用
private static String genRowKey(String[] values){
String dateStr = values[4];
String str = values[0]+"_"+dateStr.substring(0, 7);
int pid = str.hashCode()&Integer.MAX_VALUE % 3;
DecimalFormat df =new DecimalFormat("00");
String startZeroStr = df.format(pid);
return startZeroStr+"_"+values[0]+"_"+dateStr.substring(0, 10)+"_"+values[2]+"_"+values[6]+"_"+values[7];
}
main方法
由于复杂的几个方法以及单独拿出来,这里只需关注本次业务数据即可
public static void main(String[] args) {
KafkaConsumer consumer = setConsumer();
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = new Date();
HBaseUtil util = new HBaseUtil();
while (true) {
// 读取数据,读取超时时间为 100ms
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records){
String line = record.value();
String[] strs = line.split(",");
//时间戳转日期字符串
date.setTime(Long.valueOf(strs[4]));
String dateStr = format.format(date);
//按顺序排好待插入的values
String[] values1 = {strs[1], strs[0], strs[3], strs[2],
dateStr, strs[4], strs[5], "01"};
String[] values2 = {strs[3], strs[2], strs[1], strs[0],
dateStr, strs[4], strs[5], "02"};
insert(util, values1);
insert(util, values2);
}
}
}
flume
代码
需要修改当中的源文件位置以及沉槽的位置,由于sink是Kafaka,所以需要修改成自己的brokerList和topic
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F -c +0 /home/bduser/callLogs/calllog.csv
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a2.sinks.k2.brokerList = node103:9092
a2.sinks.k2.topic = callLog
a2.sinks.k2.serializer.class=kafka.serializer.StringEncoder
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
运行
都准备好了就可以开始运行了
运行数据生成器
java -cp calllogs-0.0.1-SNAPSHOT.jar product.AutoDataGen ./nam_num.csv ./calllog.csv其中calllogs-0.0.1-SNAPSHOT.jar 就是数据生产环境完成的jar包,可以直接下载

运行flume
如果没有配环境变量flume-ng也需要绝对路径,这里的a2对应代码中的a2
flume-ng agent --conf /opt/modules/flume-1.9.0/conf/ --name a2 --conf-file ./flume-kafka.conf
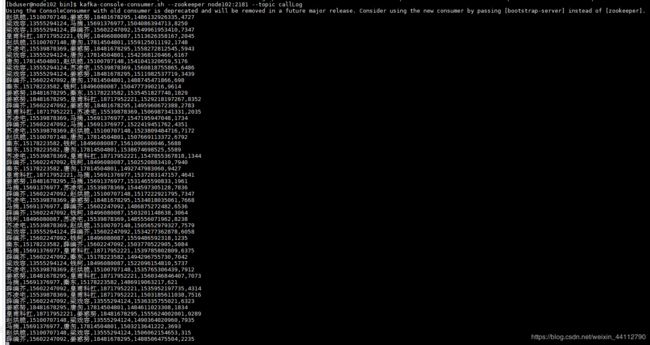
运行kafka控制台消费者
kafka-console-consumer.sh --zookeeper node102:2181 --topic callLog控制台输出了数据,证明flume程序编写正确,数据成功到达kafka。
运行HBase消费者
直接在Eclipse中运行,然后可以在HBase中查看结果。

博客链接
大数据实战-callLog项目(通话记录数据分析)之项目介绍
大数据实战-callLog项目(通话记录数据分析)之数据生产
大数据实战-callLog项目(通话记录数据分析)之数据采集
大数据实战-callLog项目(通话记录数据分析)之数据分析