文章目录
- 1.通过学习曲线—偏差和方差(样本数与准确率)
- 2.通过验证曲线—过拟合和欠拟合 (模型复杂度与准确率)
- 3.模型评估指标之准确率和召回率(混淆矩阵)
- 4.模型评估指标之收益曲线
- 5.模型评估指标之ROC与AUC
- 6.模型评估指标之KS值
运行环境 jupyter notebook
import numpy as np
import pandas as pd
from sklearn.model_selection import learning_curve
from sklearn.model_selection import validation_curve
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
test=%run "./预测Titanic号上的乘客生存概率_03_优化训练集.ipynb"
1.通过学习曲线—偏差和方差(样本数与准确率)
数据感知
train_X.head()
train_y.head()
svc=SVC()
lr=LogisticRegression()
train_sizes,train_scores,
test_scores=learning_curve(estimator=svc,
X=train_X,
y=train_y,
train_sizes=np.linspace(0.1,1.0,10),
cv=5,
n_jobs=1)
train_sizes
train_scores
test_scores
绘制 学习曲线诊断偏差和方差图
train_mean=np.mean(train_scores,axis=1)
train_std=np.std(train_scores,axis=1)
test_mean=np.mean(test_scores,axis=1)
test_std=np.std(test_scores,axis=1)
plt.plot(train_sizes,train_mean,
color='b',marker='o',
markersize=5,label='training accuracy')
plt.fill_between(train_sizes,
train_mean+train_std,
train_mean-train_std,
alpha=0.15,color='b')
plt.plot(train_sizes,test_mean,
color='g',linestyle='-',
marker='s',markersize=5,
label='validation accuracy')
plt.fill_between(train_sizes,
test_mean+test_std,
test_mean-test_std,
alpha=0.15,color='g')
plt.grid()
plt.xlabel('Number of training samples')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.6,1])
plt.tight_layout()
plt.show()
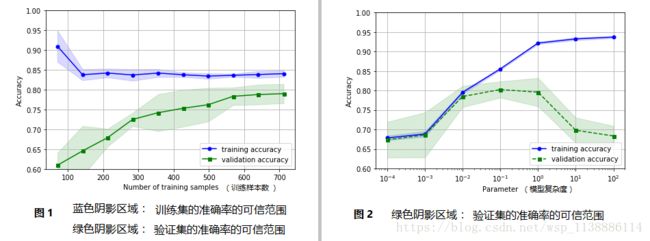
2.通过验证曲线—过拟合和欠拟合 (模型复杂度与准确率)
param_range=[0.0001,0.001,0.01,0.1,1.0,10.0,100.0]
train_scores,test_scores=validation_curve(
estimator=svc,
X=train_X,
y=train_y,
param_name='gamma',
param_range=param_range,
cv=10)
plt.plot(param_range,train_mean,
color='b',marker='o',
markersize=5,label='training accuracy')
plt.fill_between(param_range,
train_mean+train_std,
train_mean-train_std,
alpha=0.15,color='b')
plt.plot(param_range,test_mean,
color='g',linestyle='--',
marker='s',markersize=5,
label='validation accuracy')
plt.fill_between(param_range,
test_mean+test_std,
test_mean-test_std,
alpha=0.15,color='g')
plt.grid()
plt.xscale('log')
plt.xlabel('Parameter')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.ylim([0.6,1])
plt.tight_layout()
plt.show()
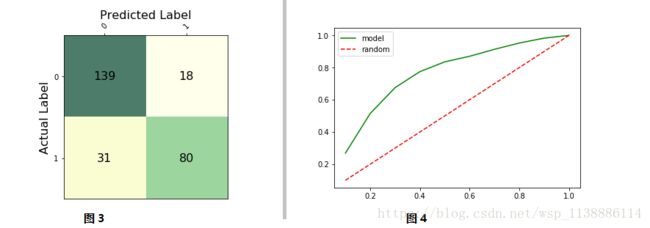
3.模型评估指标之准确率和召回率(混淆矩阵)
test=%run "./预测Titanic号上的乘客生存概率_03_优化训练集.ipynb"
y_test_pred=lr.predict(X_test)
cnf_matrix=metrics.confusion_matrix(y_test,y_test_pred)
cnf_matrix
def show_confusion_matrix(cnf_matrix,class_labels):
plt.matshow(cnf_matrix,cmap=plt.cm.YlGn,alpha=0.7)
ax=plt.gca()
ax.set_xlabel('Predicted Label',fontsize=16)
ax.set_xticks(range(0,len(class_labels)))
ax.set_xticklabels(class_labels,rotation=45)
ax.set_ylabel('Actual Label',fontsize=16,rotation=90)
ax.set_yticks(range(0,len(class_labels)))
ax.set_yticklabels(class_labels)
ax.xaxis.set_label_position('top')
ax.xaxis.tick_top()
for row in range(len(cnf_matrix)):
for col in range(len(cnf_matrix[row])):
ax.text(col,row,cnf_matrix[row][col],va='center',ha='center',fontsize=16)
class_labels=[0,1]
show_confusion_matrix(cnf_matrix,class_labels)
metrics.precision_score(y_test,y_test_pred)
metrics.recall_score(y_test,y_test_pred)
metrics.f1_score(y_test,y_test_pred)
metrics.accuracy_score(y_test,y_test_pred)
4.模型评估指标之收益曲线
def GainTable(y_true_int,y_pred_prob):
data=pd.DataFrame({'y_true':y_true_int,'prob':y_pred_prob})
data['prob']=1-data['prob']
data['percentile_gp']=pd.qcut(data['prob'],q=10,labels=range(10))
deciles=data.groupby('percentile_gp',sort=True)
def total_count(x):return len(x)
def pos_count(x):return np.sum(x)
def pos_rate(x):return np.sum(x)/float(len(x))
out=deciles['y_true'].agg([total_count,pos_count,pos_rate])
out['neg_count']=out['total_count']-out['pos_count']
out['pos_cumsum']=out['pos_count'].cumsum()
total_sum=out['pos_cumsum'][-1]
out['pos_cover_rate']=out['pos_cumsum']/float(total_sum)
out['percentile']=(out.index.astype(int)+1)/10.0
return out[['percentile','total_count','pos_count','neg_count','pos_rate','pos_cover_rate']]
y_train_prob=lr.predict_proba(X_train)
y_pred_prob=y_train_prob[:,1]
y_train=list(y_train)
y_pred_prob[:10]
y_train[:10]
gaintable=GainTable(y_train,y_pred_prob)
gaintable
def plotGainChart(GainTable):
plt.plot(GainTable['percentile'],GainTable['pos_cover_rate'],'g-')
plt.plot(GainTable['percentile'],GainTable['percentile'],'r--')
plt.legend(['model','random'])
plt.show()
plotGainChart(gaintable)
5.模型评估指标之ROC与AUC
y_train_prob=lr.predict_proba(X_train)
y_pred_prob=y_train_prob[:,1]
fpr,tpr,thresholds=metrics.roc_curve(y_train,y_pred_prob)
auc=metrics.auc(fpr,tpr)
plt.plot(fpr,tpr,lw=2,label='ROC curve (area={:.2f})'.format(auc))
plt.plot([0,1],[0,1],'r--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc='lower right')
plt.show()
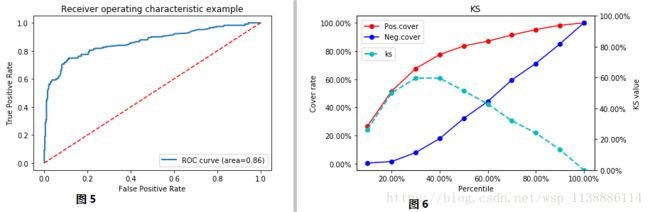
6.模型评估指标之KS值
fig,ax1=plt.subplots()
ax1.plot(gaintable['percentile']*100,gaintable['pos_cover_rate']*100,'ro-',label='Pos.cover')
ax1.plot(gaintable['percentile']*100,gaintable['neg_cover_rate']*100,'bo-',label='Neg.cover')
ax2=ax1.twinx()
ax2.plot(gaintable['percentile']*100,gaintable['ks']*100,'co--',lw=2,label='ks')
ticks=mtick.FormatStrFormatter('%.2f%%')
ax1.xaxis.set_major_formatter(ticks)
ax1.yaxis.set_major_formatter(ticks)
ax2.yaxis.set_major_formatter(ticks)
ax1.set_xlabel('Percentile')
ax1.set_ylabel('Cover rate')
ax2.set_ylabel('KS value')
ax1.legend(loc=(0.02,0.82))
ax2.legend(loc=(0.02,0.71))
ax2.set_ylim(0,100)
plt.title('KS')
plt.show()