Spark部分:groupbykey,reducebykey,sortbykey,congroup,join的区别【文字说明+代码示例】
1.reduceByKey(func, numPartitions=None)
Merge the values for each key using an associative reduce function. This will also perform the merginglocally on each mapper before sending results to a reducer, similarly to a “combiner” in MapReduce. Output will be hash-partitioned with numPartitions partitions, or the default parallelism level if numPartitions is not specified.
也就是,reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
对数据集key相同的值,都被使用指定的reduce函数聚合到一起。
# -*- coding:utf-8 -*-
from pyspark import SparkConf
from pyspark import SparkContext
import os
from operator import add
if __name__ == '__main__':
os.environ["SPARK_HOME"] = "/Users/a6/Applications/spark-2.1.0-bin-hadoop2.6"
conf = SparkConf().setMaster('local').setAppName('reduce')
sc = SparkContext(conf=conf)
data = [('tom',90),('jerry',97),('luck',92),('tom',78),('luck',64),('jerry',50)]
rdd = sc.parallelize(data)
print rdd.reduceByKey(add).collect()
sc.close()
# 输出结果
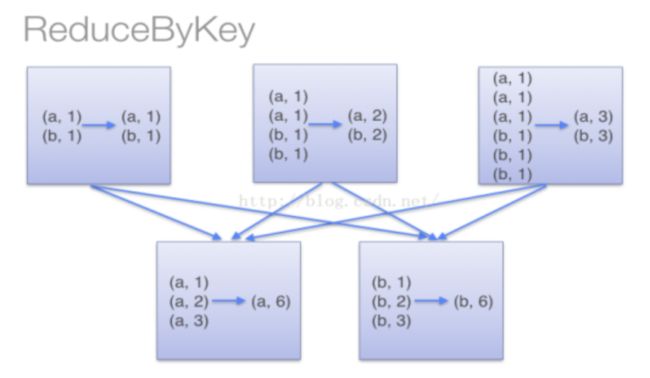
[('jerry', 147), ('luck', 156), ('tom', 168)]当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。
为了确定将数据对移到哪个主机,Spark会对数据对的 key 调用一个分区算法。 当移动的数据量大于单台执行机器内存总量时 Spark 会把数据保存到磁盘上。 不过在保存时每次会处理一个 key 的数据,所以当单个 key 的键值对超过内存容量会存在内存溢出的异常。 这将会在之后发行的 Spark 版本中更加优雅地处理,这样的工作还可以继续完善。 尽管如此,仍应避免将数据保存到磁盘上,这会严重影响性能。
你可以想象一个非常大的数据集,在使用 reduceByKey 和 groupByKey 时他们的差别会被放大更多倍。
2.groupByKey(numPartitions=None)
Group the values for each key in the RDD into a single sequence. Hash-partitions the resulting RDD with numPartitions partitions. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will provide much better performance.
也就是,groupByKey也是对每个key进行操作,但只生成一个sequence。需要特别注意“Note”中的话,它告诉我们:如果需要对sequence进行aggregation操作(注意,groupByKey本身不能自定义操作函数),那么,选择reduceByKey/aggregateByKey更好。这是因为groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
groupByKey是对每个key进行合并操作,但只生成一个sequence,groupByKey本身不能自定义操作函数。
# -*- coding:utf-8 -*-
from pyspark import SparkConf
from pyspark import SparkContext
import os
if __name__ == '__main__':
os.environ["SPARK_HOME"] = "/Users/a6/Applications/spark-2.1.0-bin-hadoop2.6"
conf = SparkConf().setMaster('local').setAppName('group')
sc = SparkContext(conf=conf)
data = [('tom',90),('jerry',97),('luck',92),('tom',78),('luck',64),('jerry',50)]
rdd = sc.parallelize(data)
print rdd.groupByKey().map(lambda x: (x[0],list(x[1]))).collect()
# 输出:
[('tom', [90, 78]), ('jerry', [97, 50]), ('luck', [92, 64])]当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
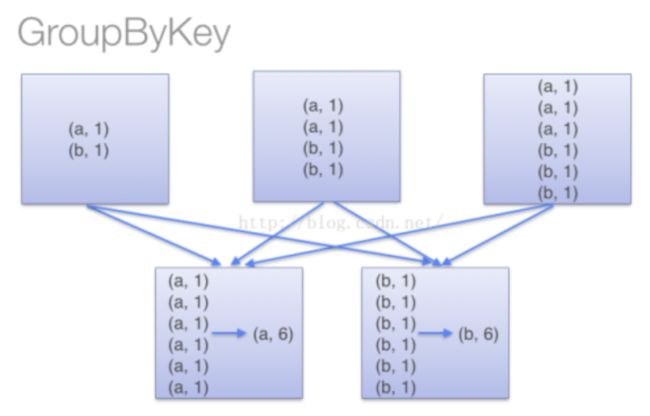
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用
当调用 groupByKey时,所有的键值对(key-value pair) 都会被移动。在网络上传输这些数据非常没有必要。避免使用 GroupByKey。
3.sortbykey
通过key进行排序。
#-*- coding:utf-8 -*-
if __name__ == '__main__':
os.environ["SPARK_HOME"] = "/Users/a6/Applications/spark-2.1.0-bin-hadoop2.6"
conf = SparkConf().setMaster('local').setAppName('reduce')
sc = SparkContext(conf=conf)
data = [(5,90),(1,92),(3,50)]
rdd = sc.parallelize(data)
print rdd.sortByKey(False).collect()
print rdd.sortByKey(True).collect()
sc.close()
# print rdd.sortByKey(False).collect() 的输出为
[(5, 90), (3, 50), (1, 92)]
# print rdd.sortByKey(True).collect() 的输出为
[(1, 92), (3, 50), (5, 90)]4.congroup
代码:
object joinDemo {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setMaster("local").setAppName("cogroup Demo")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.parallelize(Array(("aa",1),("bb",2),("cc",6)))
val rdd2 = sc.parallelize(Array(("aa",3),("dd",4),("aa",5)))
val rdd3 = rdd1.cogroup(rdd2).collect()
for (i <- 0 to rdd3.length-1){
println(rdd3(i))
}
}
}输出结果:
(aa,(CompactBuffer(1),CompactBuffer(3, 5)))
(dd,(CompactBuffer(),CompactBuffer(4)))
(bb,(CompactBuffer(2),CompactBuffer()))
(cc,(CompactBuffer(6),CompactBuffer()))5.join:
代码:
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("test").
master("local[2]").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
/**
* id name
* 1 zhangsan
* 2 lisi
* 3 wangwu
*/
val idName = sc.parallelize(Array((1, "zhangsan"), (2, "lisi"), (3, "wangwu")))
/**
* id age
* 1 30
* 2 29
* 4 21
*/
val idAge = sc.parallelize(Array((1, 30), (2, 29), (4, 21)))
println("cogroup")
/**
* (1,(CompactBuffer(zhangsan),CompactBuffer(30)))
* (2,(CompactBuffer(lisi),CompactBuffer(29)))
* (3,(CompactBuffer(wangwu),CompactBuffer()))
* (4,(CompactBuffer(),CompactBuffer(21)))
*/
idName.cogroup(idAge).collect().foreach(println)
println("join")
// fullOuterJoin于cogroup的结果类似, 只是数据结构不一样
/**
* (1,(Some(zhangsan),Some(30)))
* (2,(Some(lisi),Some(29)))
* (3,(Some(wangwu),None))
* (4,(None,Some(21)))
*/
idName.fullOuterJoin(idAge).collect().foreach(println)
/**
* id score
* 1 100
* 2 90
* 2 95
*/
val idScore = sc.parallelize(Array((1, 100), (2, 90), (2, 95)))
println("cogroup, 出现相同id时")
/**
* (1,(CompactBuffer(zhangsan),CompactBuffer(100)))
* (2,(CompactBuffer(lisi),CompactBuffer(90, 95)))
* (3,(CompactBuffer(wangwu),CompactBuffer()))
*/
idName.cogroup(idScore).collect().foreach(println)
println("join, 出现相同id时")
/**
* (1,(Some(zhangsan),Some(100)))
* (2,(Some(lisi),Some(90)))
* (2,(Some(lisi),Some(95)))
* (3,(Some(wangwu),None))
*/
idName.fullOuterJoin(idScore).collect().foreach(println)
}
}join和congroup都需要讲个rdd才可以操作
join和congroup能达到相同的效果,都是将两个rdd按照相同 的key进行组合,join使用的是some关键字,congroup使用的是compactbuffer关键字。
groupbykey是按照相同的key,将value的值聚合起来,而reducebykey是安装相同的key,将value的值作以处理
groupbykey不能定义函数,reducebykey可以定义函数
sortbykey是按照key,将value的值排序