使用CrawlSpider半通用化、框架式、批量请求“链家网”西安100页租房网页(两种方法实现rules的跟进和几个xpath分享)
csdn上已经有很多的关于CrawlSpider框架的讲解,以及其主要的使用方法,其整体的数据流向和Spider框架的数据流向是大体一样的,因为CrawlSpider是继承自Spider的类,Spider框架的介绍我在之前的博文中写过,
python-Scrapy爬虫框架介绍(整个数据的流程)
CrawlSpider框架的介绍我之后也想写一篇博文来加深自己的理解,这里通过实战来对其整体流程进行理解(半通用化)。
CrawlSpider半通用化抓站
- 1. 新建Scrapy项目
- 2. 创建一个CrawlSpider
- 3. 分析目标网页
- 3.1 目标网址
- 3.2 明确爬虫的目的和步骤思路
- 3.3 分析目标网页
- 3.3.1 查看网页源码,找寻房子的跳转链接
- 3.3.2 查看网页源码,找寻页面的跳转链接(两种方法)
- 3.3.2.1 方法一(直接编写rule):
- 3.3.2.1 方法二(重写parse_start_url方法):
- 4. 编写相应的Item和实现相应的爬取方法
- 4.1 几个xpath提取自己认为实用的方法
- 5. 后台粗暴显示数据
- 6. 该代码存在的问题,望大佬指点
- 7. 希望自己所写可以对大家有用
1. 新建Scrapy项目
scrapy startproject rent_lianjia
2. 创建一个CrawlSpider
使用pycharm打开刚才创建的Scrapy项目,在Terminal中输入创建的命令:
scrapy genspider -t crawl lianjia
3. 分析目标网页
3.1 目标网址
该地址是链家网的定位西安的租房信息的URL:
start_urls = ['https://xa.lianjia.com/zufang/']
# 或
#start_urls = ['https://xa.lianjia.com/zufang/pg1/#contentList']
3.2 明确爬虫的目的和步骤思路
- 获取网页中每一个房子的跳转链接
- 通过链接分别进入其具体的租房信息网页
- 爬取你想获取的房子的相关信息
3.3 分析目标网页
该网页是针对西安租房的:
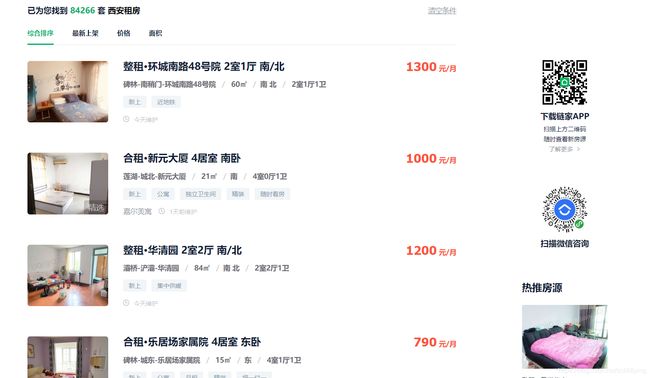
3.3.1 查看网页源码,找寻房子的跳转链接
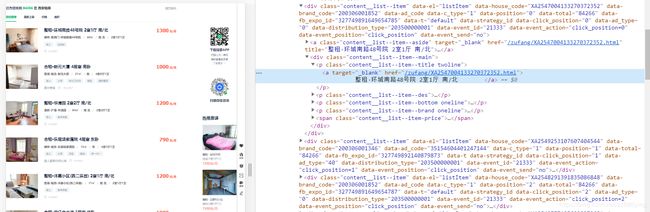
可以很简单的找到每个房子的跳转链接存放在a标签当中的href属性当中,恒容易用xpath提取
3.3.2 查看网页源码,找寻页面的跳转链接(两种方法)
3.3.2.1 方法一(直接编写rule):

可以看到其网页的跳转链接都保存在ul的列表里
rules = (
Rule(LinkExtractor(restrict_xpaths='//p[@class="content__list--item--title twoline"]//a'), callback='parse_item'),
Rule(LinkExtractor(restrict_xpaths='//ul[@style="display:hidden"]//a'))
)
查看后台请求的结果:


按道理来说这样是可以完成所有的网页链接的请求。关于rule的使用方法我会整理成一篇博文来加深自己的印象的,目前csdn上已经有很多相关的文章来介绍。
3.3.2.1 方法二(重写parse_start_url方法):
这种方法是百度查看了crawlspider的源码后,也有人这样实现过自己也想尝试以下:
Scrapy框架CrawlSpiders的介绍以及使用
这个里面介绍了其源码,是如何对url链接进行请求操作的,都使用了什么方法,我感觉对于小白的我来说很好。
自己的尝试:
def parse_start_url(self, response):
for i in range(1,10):
url = 'https://xa.lianjia.com/zufang/pg' + str(i+1) + '/#contentList'
yield scrapy.Request(url)
解释以下 parse_start_url 方法:
它是一个可以重写的方法。当start_urls里对应的Request得到Response时,这个方法会被调用,它会分析Response并返回Item对象或者Request对象。
自己的事件证明方法是可以的,后台的请求结果:

4. 编写相应的Item和实现相应的爬取方法
class HouseItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
price = Field()
rentWay = Field()
size = Field()
floor = Field()
url = Field()
name = Field()
4.1 几个xpath提取自己认为实用的方法
def parse_item(self, response):
item = HouseItem()
item['name'] = response.xpath('//p[@class="content__title"]/text()').extract_first()
item['price'] = ''.join(response.xpath('//div[@class="content__aside--title"]/span/text()').extract_first()) + ''.join(response.xpath('//div[@class="content__aside--title"]/text()').extract()).strip()
item['rentWay'] = ''.join(response.xpath('//ul[@class="content__aside__list"]//text()').extract()).strip().split('\n')[0]
item['size'] = ''.join(response.xpath('//ul[@class="content__aside__list"]//text()').extract()).strip().split('\n')[1]
item['floor'] = ''.join(response.xpath('//ul[@class="content__aside__list"]//text()').extract()).strip().split('\n')[2]
item['url'] = response.url
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
在进行xpath提取的时候,由于框架显示不方便,自己的做法是每次另写一个.py文件,专门对数据进行xpth的编写,调试数据的返回结果和格式,带正确以后再放入框架当中。在使用xpath的时候,用strip()能处理大部分的网页中的空格或者换行,但还得进行一定的分割和拼接,用split()方法,自己得琢磨 “/”和“//”的区别所在,一个是返回直接子节点的信息,一个是返回所有子几点的信息,二者有很大的不同,得在不断的练习当中发现其中的用法。
5. 后台粗暴显示数据

6. 该代码存在的问题,望大佬指点
- 自己也在琢磨这个crawlspider,上述有问题的请大家谅解及时评论或私信指出,我立马修改。
- 当响应的网页变多,网站的服务器会识别是否是人为操作,在后面的返回的网页请求中会打不开,是人机识别的界面,无法获取信息,有什么好的方法或者号的博文链接可以私信或评论,带带小弟我。
- 自己知道的简单的方法有直接粗暴的sleep等待,每次请求完就等待,更换请求的IP地址,有没有好 的免费的ip地址网站提供推荐,多几个请求的头,模拟不同的浏览器。
- 总的来说就是如何更好的去请求网页,让服务器不容易发现,当大规模爬取数据的时候,望大佬指点。