Scrapy爬取天眼查首页热门公司信息,可视化分析这些热门公司
Scrapy爬取天眼查
- 1. 分析目标网页
- 2. 爬取思路
- 3. 爬取信息
- 3.1 创建scrapy工程
- 3.2 创建CrawlSpider
- 3.3 数据模型item.py
- 3.4 编写spider
- 3.5 数据库pipelines.py
- 3.6 对于反爬的分析
- 3.7 爬取的结果图与数据库中的结果图
- 4. 数据的可视化
- 4.1 提取公司地址,可视化城市分布数量
- 4.2 公司注册资金对比
- 4.3 公司简介词云图
1. 分析目标网页
url = 'http://www.tianyancha.com/'
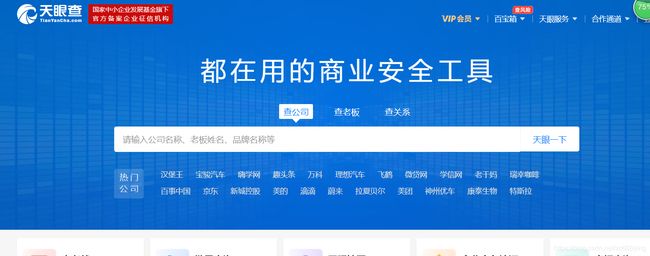
1.可以看到主页有显示的热门公司,直观的看有22个,查看源码,查看其页面的跳转连接:
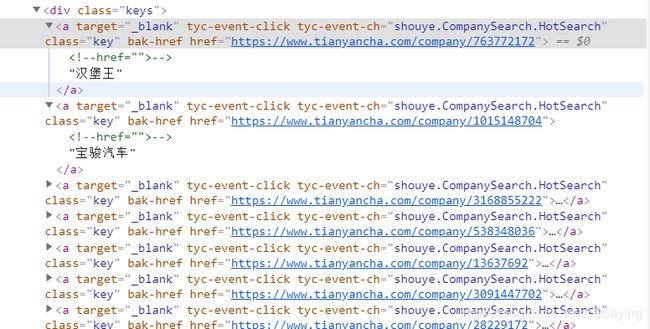
2.可以很轻松的找到整体的热门公司的跳转链接都封装在class为keys下的a标签中
3.随机点击进入某一个热门公司的页面
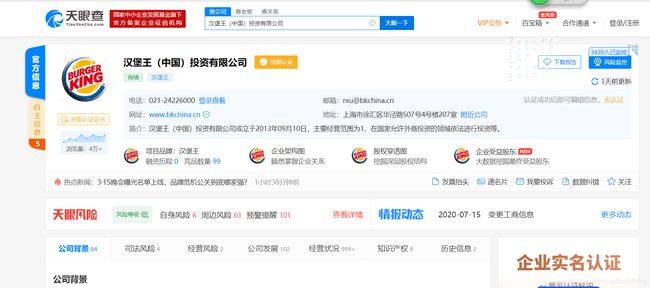
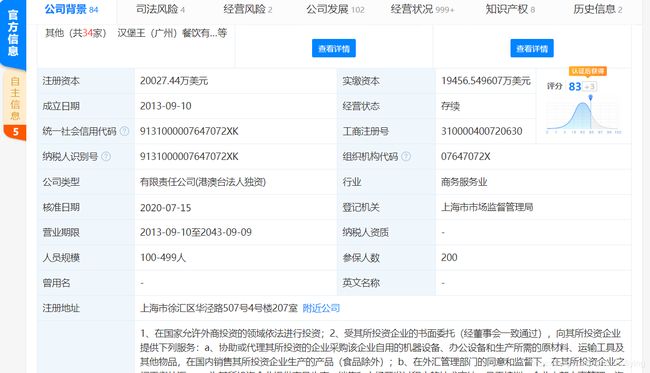
4.可以看到,页面的最上端显示的是公司的名称,电话,邮箱,地址等基本信息,下端具体显示了公司的注册资本,法人等详细的信息,我想将这些信息全部提取,并存入数据库当中,以便可以更好的进行数据的提取和可视化,需要查看这些信息的源码的位置,F12:
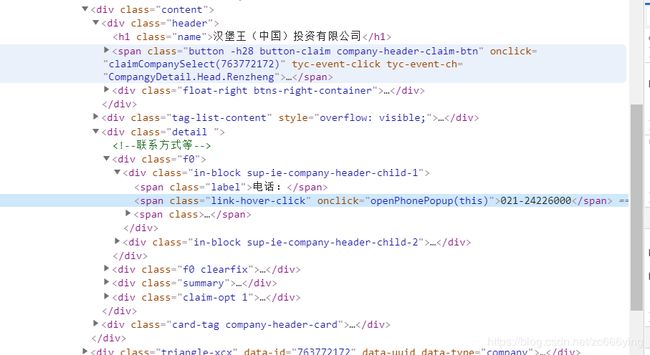
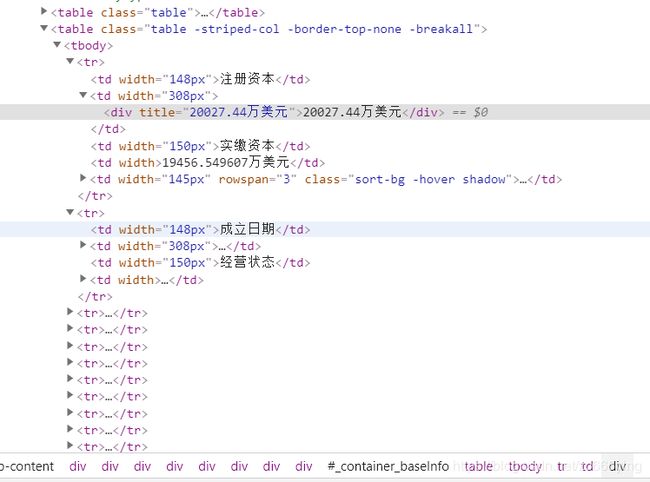
对于公司的基本信息,存放的方式大都是按指定给的标签的形式存放的,但对于公司的详细信息,可以很明显的看出是存放在表格当中的,这也方便了爬虫时候对于该部分信息的提取。
2. 爬取思路
- 是对一个网站中的不同链接下的内容进行爬取,故首选Scrapy框架,这里我使用CrawlSpider,根据rule来跟进不同的链接,发起请求
- 首先通过rule获取主页热门公司的跳转链接
- 设置相应的通用的item即可对公司的信息进行爬取
- 设置数据库,将数据存入数据当中
- 分析网页的反爬,设置相应的信息,调整爬取速度(下文会提到)
3. 爬取信息
3.1 创建scrapy工程
scrapy startproject tianyancha
3.2 创建CrawlSpider
使用pycharm打开刚才创建的Scrapy项目,在Terminal中输入创建的命令:
scrapy genspider -t crawl tianyan www.tianyancha.com
3.3 数据模型item.py
class TianyanchaItem(scrapy.Item):
image_url = Field()
company_name = Field()
html_url = Field()
company_phone = Field()
company_mailbox = Field()
company_url = Field()
company_address = Field()
company_introdution = Field()
company_boss_name = Field()
company_info = Field()
3.4 编写spider
class TianyanSpider(CrawlSpider):
name = 'tianyan'
allowed_domains = ['www.tianyancha.com']
start_urls = ['http://www.tianyancha.com/']
# 设置爬取的速度,最简单的反爬
# 这里的爬取速度指的完成一个item的时间,即从下载,爬取,显示保存,整体的时间为3秒
custom_settings = {
'DOWNLOAD_DELAY':3
}
# 直接使用xpath定位热门公司页面的跳转链接
rules = (
Rule(LinkExtractor(restrict_xpaths='//div[@class="keys"]//a'), callback='parse_item'),
)
# 使用xpath对信息进行提取
def parse_item(self, response):
item = TianyanchaItem()
item['company_name'] = ''.join(response.xpath('//h1[@class="name"]//text()').extract())
item['image_url'] = response.xpath('//img[@class="img"]//@src').extract()
item['company_phone'] = response.xpath('//span[@class="link-hover-click"]//text()').extract()
item['company_mailbox'] = response.xpath('//span[@class="email"]//text()').extract()
item['company_url'] = response.xpath('//a[@class="company-link"]//@href').extract()
item['company_address'] = response.xpath('//script[@id="company_base_info_address"]/text()').extract()
item['company_introdution'] = response.xpath('//div[@class="auto-folder"]/div/text()').extract()[2]
item['company_boss_name'] = response.xpath('//div[@class="name"]/a/text()').extract()
item['company_info'] = ''.join(response.xpath('//table[@class="table -striped-col -border-top-none -breakall"]//td//text()').extract())
item['html_url'] = response.url
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
这里需要注意的是,我选择的保存方式是mysql数据库,并将公司的名字作为主键,而数据库中保存数据的时候,只有string类型才能正确插入到数据中,但对于table类型的数据爬取下来的时候,他每个是分开的,属于list类型,存放不到数据库中,会报如下的错误:

所以这里将主键和公司的info介绍数据使用"".join()进行转换,变为string类型,但这对于数据分析和数据的阅读带来了不好的麻烦。
3.5 数据库pipelines.py
class PyMySqlPipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host = 'localhost',
database = 'tianyancha',
user = 'root',
password = '123456',
charset = 'utf8',
port = 3306,
)
# 创建游标对象
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
cursor = self.cursor
sql = 'insert into hot_company(company_name,company_phone,company_mailbox,company_url,company_address,company_introdution,company_boss_name,company_info,image_url,html_url) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(
item['company_name'],item['company_phone'],item['company_mailbox'],item['company_url'],item['company_address'],item['company_introdution'],item['company_boss_name'],item['company_info'],item['image_url'],item['html_url']
))
# 提交数据库事务
self.connect.commit()
return item
设置完之后一定要记得在settings.py中开启管道
3.6 对于反爬的分析
我没有进行登陆,只是简单的打开首页中热门公司的链接,并将其对应的信息爬取下来,在实际的代码过程中,仅仅更换user-agent,将ROBOTSTXT_OBEY设置为False,是可以进行爬取的,但当我再次爬取的时候,返回的热门公司的链接全部都被重定向,重定向为登陆的界面。若想再次在首页打开热门公司的链接只需等待两三个小时或者更短的时间,刷新页面即可再次打开。
再次进行爬取的时候,我做了如下的事情:
1.关闭cookies信息:
COOKIES_ENABLED = False
2.设置随机请求的头部
class RandomUserAgentMiddleware():
def __init__(self):
self.user_agenrs = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
]
def process_request(self,request,spider):
request.headers['User-Agent'] = random.choice(self.user_agenrs)
- 设置请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': '*',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36',
}
4.设置每个item的爬取速度
# 设置爬取的速度
custom_settings = {
'DOWNLOAD_DELAY':3
}
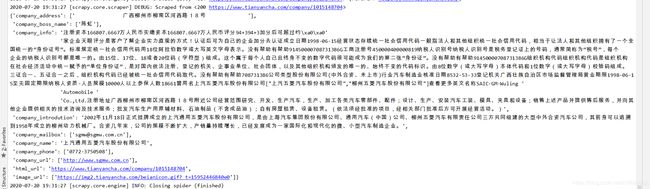
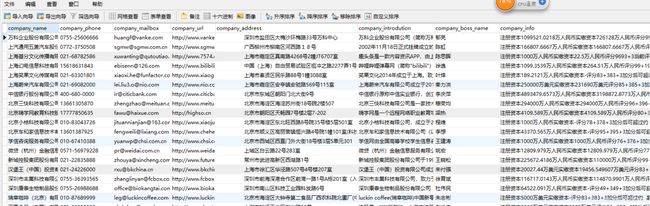
3.7 爬取的结果图与数据库中的结果图
4. 数据的可视化
4.1 提取公司地址,可视化城市分布数量
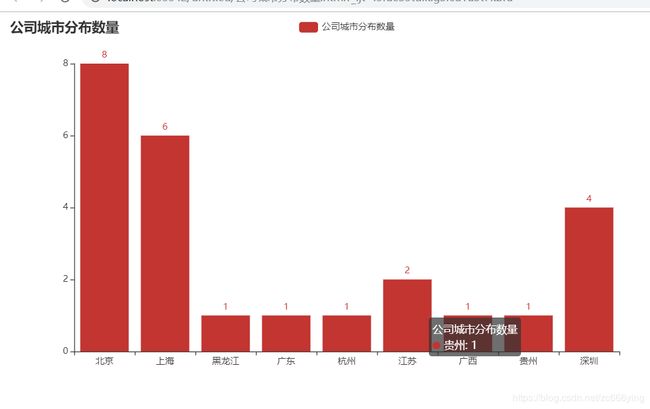
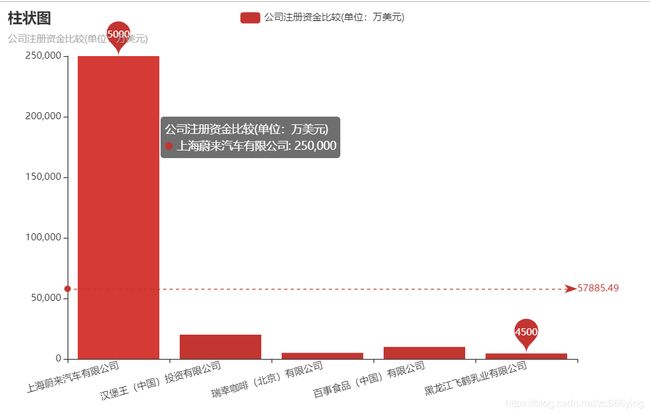
4.2 公司注册资金对比
单位(万人民币)

单位(万美元)
4.3 公司简介词云图
生成美的公司简介的词云图

当然还可以做其它数据的可视化。