目录
- 1 JAVA.IO字节流
- 2 JAVA.IO字符流
- 3 乱码问题和字符流
- 4 字符集和字符编码的概念区分
- 5 URI概念的简单介绍
- 6 URL概念及与URL的区别
- 7 Spring资源获取方式与Resource
- 8 ResourceLoader获取资源介绍
- 9 JAVA.Properties了解一下
- 10 yml配置资源的读取
- 11 优雅地关闭资源,try-with-resource语法和lombok@Cleanup
- 12 资源不关闭,会导致什么最坏的结果
- 关注公众号,一起交流
- 参考文章
1 JAVA.IO字节流
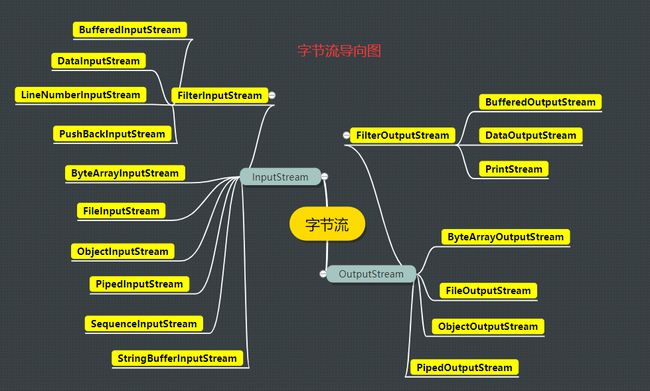
- LineNumberInputStream和StringBufferInputStream官方建议不再使用,推荐使用LineNumberReader和StringReader代替
- ByteArrayInputStream和ByteArrayOutputStream
- 字节数组处理流,在内存中建立一个缓冲区作为流使用,从缓存区读取数据比从存储介质(如磁盘)的速率快
ByteArrayOutputStream data = new ByteArrayOutputStream(1024);
data.write(System.in.read());
ByteArrayInputStream in = new ByteArrayInputStream(data.toByteArray());
- FileInputStream和FileOutputStream
- 访问文件,把文件作为InputStream,实现对文件的读写操作
- ObjectInputStream和ObjectOutputStream
- 对象流,构造函数需要传入一个流,实现对JAVA对象的读写功能;可用于序列化,而对象需要实现Serializable接口
FileOutputStream fileStream = new FileOutputStream("example.txt");
ObjectOutputStream out = new ObjectOutputStream(fileStream);
Example example = new Example();
out.writeObject(example);
FileInputStream fileStream = new FileInputStream("example.txt");
ObjectInputStream in = new ObjectInputStream(fileStream);
Example = (Example) in.readObject();
- PipedInputStream和PipedOutputStream
- 管道流,适用在两个线程中传输数据,一个线程通过管道输出流发送数据,另一个线程通过管道输入流读取数据,实现两个线程间的数据通信
Sender sender = new Sender();
Receiver receiver = new Receiver();
PipedOutputStream outputStream = sender.getOutputStream();
PipedInputStream inputStream = receiver.getInputStream();
outputStream.connect(inputStream);
sender.start();
receiver.start();
- SequenceInputStream
- 把多个InputStream合并为一个InputStream,允许应用程序把几个输入流连续地合并起来
InputStream in1 = new FileInputStream("example1.txt");
InputStream in2 = new FileInputStream("example2.txt");
SequenceInputStream sequenceInputStream = new SequenceInputStream(in1, in2);
int data = sequenceInputStream.read();
- FilterInputStream和FilterOutputStream 使用了装饰者模式来增加流的额外功能,子类构造参数需要一个InputStream/OutputStream
ByteArrayOutputStream out = new ByteArrayOutputStream(2014);
DataOutputStream dataOut = new DataOutputStream(out);
dataOut.writeDouble(1.0);
ByteArrayInputStream in = new ByteArrayInputStream(out.toByteArray());
DataInputStream dataIn = new DataInputStream(in);
Double data = dataIn.readDouble();
- DataInputStream和DataOutputStream (Filter流的子类)
- 为其他流附加处理各种基本类型数据的能力,如byte、int、String
- BufferedInputStream和BufferedOutputStream (Filter流的子类)
- PushBackInputStream (FilterInputStream子类)
- 推回输入流,可以把读取进来的某些数据重新回退到输入流的缓冲区之中
- PrintStream (FilterOutputStream子类)
2 JAVA.IO字符流
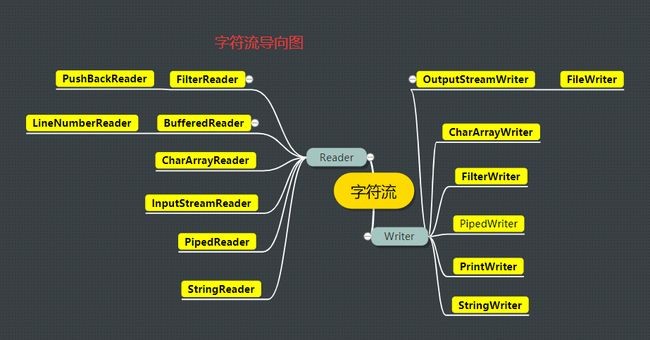
- 从字节流和字符流的导向图来,它们之间是相互对应的,比如CharArrayReader和ByteArrayInputStream
- 字节流和字符流的转化:InputStreamReader可以将InputStream转为Reader,OutputStreamReader可以将OutputStream转为Writer
InputStream inputStream = new ByteArrayInputStream("程序".getBytes());
InputStreamReader reader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);
OutputStream out = new FileOutputStream("example.txt");
OutputStreamWriter writer = new OutputStreamWriter(out);
writer.write(reader.read(new char[2]));
- 区别:字节流读取单位是字节,字符流读取单位是字符;一个字符由字节组成,如变字长编码UTF-8是由1~4个字节表示
3 乱码问题和字符流
- 字符以不同的编码表示,它的字节长度(字长)是不一样的。如“程”的utf-8编码格式,由[-25][-88][-117]组成。而ISO_8859_1编码则是单个字节[63]
- 平时工作对资源的操作都是面向字节流的,然而数据资源根据不同的字节编码转为字节时,它们的内容是不一样,容易造成乱码问题
- 两种出现乱码场景
- encode和decode使用的字符编码不一致:资源使用UTF-8编码,而在代码里却使用GBK解码打开
- 使用字节流读取字节数不符合字符规定字长:字符是由字节组成的,比如“程”的utf-8格式是三个字节;如果在InputStream里以每两个字节读取流,再转为String(java默认编码是utf-8),此时会出现乱码(半个中文,你猜是什么)
ByteArrayInputStream in = new ByteArrayInputStream("程序大法好".getBytes());
byte[] buf = new byte[2];
in.read(buf);
System.out.println(new String(buf));
---result----
�
- 乱码场景1,知道资源的字符编码,就可以使用对应的字符编码来解码解决
- 乱码场景2,可以一次性读取所有字节,再一次性编码处理。但是对于大文件流,这是不现实的,因此有了字符流的出现
- 字节流使用InputStreamReader、OutputStreamReader转化为字符流,其中可以指定字符编码,再以字符为单位来处理,可解决乱码
InputStreamReader reader =
new InputStreamReader(inputStream, StandardCharsets.UTF_8);
4 字符集和字符编码的概念区分
- 字符集和字符编码的关系,字符集是规范,字符编码是规范的具体实现;字符集规定了符号和二进制代码值的唯一对应关系,但是没有指定具体的存储方式;
- unicode、ASCII、GB2312、GBK都是字符集;其中ASCII、GB2312、GBK既是字符集也是字符编码;注意不混淆这两者区别;而unicode的具体实现有UTF-8,UTF-16,UTF-32
- 最早出现的ASCII码是使用一个字节(8bit)来规定字符和二进制映射关系,标准ASCII编码规定了128个字符,在英文的世界,是够用的。但是中文,日文等其他文字符号怎么映射呢?因此其他更大的字符集出现了
- unicode(统一字符集),早期时它使用2个byte表示1个字符,整个字符集可以容纳65536个字符。然而仍然不够用,于是扩展到4个byte表示一个字符,现支持范围是U+010000~U+10FFFF
- unicode是两个字节的说法是错误的;UTF-8是变字长的,需要用14个字节存储;UTF-16一般是两个字节(U+0000U+FFFF范围),如果遇到两个字节存不下,则用4个字节;而UTF-32是固定四个字节
- unicode表示的字符,会用“U+”开头,后面跟着十六进制的数字,如“字”的编码就是U+5B57
- UTF-8 编码和unicode字符集
| 范围 |
Unicode(Binary) |
UTF-8编码(Binary) |
UTF-8编码byte长度 |
| U+0000~U+007F |
00000000 00000000 00000000 0XXXXXXX |
0XXXXXX |
1 |
| U+0080~U+07FF |
00000000 00000000 00000YYY YYXXXXXX |
110YYYYY 10XXXXXX |
2 |
| U+0800~U+FFFF |
00000000 00000000 ZZZZYYYY YYXXXXXX |
1110ZZZZ 10YYYYYY 10XXXXXX |
3 |
| U+010000~U+10FFFF |
00000000 000AAAZZ ZZZZYYYY YYXXXXXX |
11110AAA 10ZZZZZZ 10YYYYYY 10XXXXXX |
4 |
- 程序是分内码和外码,java的默认编码是UTF-8,其实指的是外码;内码倾向于使用定长码,和内存对齐一个原理,便于处理。外码倾向于使用变长码,变长码将常用字符编为短编码,罕见字符编为长编码,节省存储空间与传输带宽
- JDK8的字符串,是使用char[]来存储字符的,char是两个字节大小,其中使用的是UTF-16编码(内码)。而unicode规定的中文字符在U+0000~U+FFFF内,因此使用char(UTF-16编码)存储中文是不会出现乱码的
- JDK9后,字符串则使用byte[]数组来存储,因为有一些字符一个char已经存不了,如emoji表情字符,使用字节存储字符串更容易拓展
- JDK9,如果字符串的内容都是ISO-8859-1/Latin-1字符(1个字符1字节),则使用ISO-8859-1/Latin-1编码存储字符串,否则使用UTF-16编码存储数组(2或4个字节)
System.out.println(Charset.defaultCharset());
for (byte item : "程序".getBytes(StandardCharsets.UTF_16)) {
System.out.print("[" + item + "]");
}
System.out.println("");
for (byte item : "程序".getBytes(StandardCharsets.UTF_8)) {
System.out.print("[" + item + "]");
}
----result----
UTF-8
[-2][-1][122][11][94][-113]
[-25][-88][-117][-27][-70][-113]
- “程序”的UTF-16编码竟是输出6个字节,多出了两个字节,这是什么情况?再试试一个字符的输出
for (byte item : "程".getBytes(StandardCharsets.UTF_16)) {
System.out.print("[" + item + "]");
}
---result--
[-2][-1][122][11]
- 可以看出UTF-16编码的字节是多了[-2][-1]两个字节,十六进制是0xFEFF。而它用来标识编码顺序是Big endian还是Little endian。以字符’中’为例,它的unicode十六进制是4E2D,存储时4E在前,2D在后,就是Big endian;2D在前,4E在后,就是Little endian。FEFF表示存储采用Big endian,FFFE表示使用Little endian
- 为什么UTF-8没有字节序的问题呢?个人看法,因为UTF-8是变长的,由第一个字节的头部的0、110、1110、11110判断是否需后续几个字节组成字符,使用Big endian易读取处理,反过来不好处理,因此强制用Big endian
- 其实感觉UTF-16可以强制规定用Big endian;但这其中历史问题。。。
5 URI概念的简单介绍
- 既然有了java.io来操作资源流;但是对于网络的资源,该怎么打开,怎么定位呢?答URI-URL
- URI全称是
Uniform Resource Identifier 统一资源标识符
- 通俗说,就是一个类似身份证号码的字符串,只不过它是用来标识资源(如:邮件地址,主机名,文件等)
- URI 具有特定的规则:
[scheme]:[scheme-specific-part][#fragment]
- 进一步细入划分可表示为
[scheme]:[//authority][/path][?query][#fragment],其中模式特定部分为authority和path、query;而authority可以看做域名,如www.baidu.com
- 终极细分则是
[scheme]:[//host:port][/path][?query][#fragment],和日常见到的地址链接一毛一样了
- 模式特定部分(scheme-specific-part)的形式取决于模式,而URI的常用模式如下
- ftp:FTP服务器
- file:本地磁盘上的文件
- http:使用超文本传输协议
- mailto:电子邮件的地址
- telnet:基于Telnet的服务的连接
- Java中还大量使用了一些非标准的定制模式,如rmi、jar、jndi、doc、jdbc等
- 在java中URI抽象为java.net.URI类,下面列举几种常用构造方法
public URI(String str) throws URISyntaxException
public URI(String scheme, String authority,
String path, String query, String fragment)throws URISyntaxException
public static URI create(String str)
public String getScheme()
public String getSchemeSpecificPart()
public String getFragment()
public String getAuthority()
public String getHost()
public int getPort()
public String getPath()
public String getQuery()
6 URL概念及与URL的区别
- URL全称是
Uniform Resource Location,统一资源定位符
- URL就是URI的子集,它除了标识资源,还提供找到资源的路径;在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析,而URL类可以打开一个到达资源的流
- 同属URI子集的URN(统一资源名称),只标识资源名称,却不指定如何定位资源;如:
mailto:[email protected]就是一种URN,知道这是个邮箱,却不知道该怎么查找定位
- 通俗就是,URN告诉你有一个地方叫广州,但没有说怎么去,你可以搭动车,也可以搭飞机;URL会告诉你坐飞机去广州,而另一URL则说搭动车去
- URL的一般语法规则
协议://主机名:端口/路径?查询#片段
[protocol]:[//host:port][/path][?query][#fragment]
public URL(String spec) throws MalformedURLException
public URL(String protocol, String host, int port, String file) throws MalformedURLException
URL systemResource = ClassLoader.getSystemResource(String name)
Enumeration<URL> systemResources = ClassLoader.getSystemResources(String name)
URL resource = Main.class.getResource(String name)
Enumeration<URL> resources = Main.class.getClassLoader().getResources(String name)
public final InputStream openStream() throws java.io.IOException
public URLConnection openConnection() throws java.io.IOException
public final Object getContent() throws java.io.IOException
7 Spring资源获取方式与Resource
- 讲到资源,就得提下Spring获取资源方式,常用的有两种
- 通过Resource接口的子类获取资源
- 通过ResourceLoader接口的子类获取资源
- 先介绍下Resource相关子类的使用
- 1 FileSystemResource:通过文件系统获取资源
Resource resource = new FileSystemResource("D:/example.txt");
File file= new File("example.txt");
Resource resource2 = new FileSystemResource(file);
- 2 ByteArrayResource:获取byte数组表示的资源
- 基于ByteArrayInputStream和字节数组实现,应用场景类似ByteArrayInputStream,缓存byte[]资源
- 3 ClassPathResource:获取类路径下的资源
private final String path;
private ClassLoader classLoader;
private Class<?> clazz;
---使用方式----
Resource resource = new ClassPathResource("test.txt");
- 4 InputStreamResource:接收一个InputStream对象,获取输入流封装的资源
- 5 ServletContextResourse:加载ServletContext环境下(相对于Web应用根目录的)路径资源,获取的资源
- 6 UrlResource:通过URL访问http资源和FTP资源等
8 ResourceLoader获取资源介绍

- ResourceLoader是为了屏蔽了Resource的具体实现,统一资源的获取方式。你即能从ResourceLoader加载ClassPathResource,也能加载FileSystemResource等
public interface ResourceLoader {
String CLASSPATH_URL_PREFIX = ResourceUtils.CLASSPATH_URL_PREFIX;
Resource getResource(String location);
- ResourceLoader接口默认对classpath路径下面的资源进行加载
public interface ResourcePatternResolver extends ResourceLoader {
String CLASSPATH_ALL_URL_PREFIX = "classpath*:";
- ResourcePatternResolver默认会加载所有路径下面的文件,获得ClassPathResource;classpath:只会在class类路径下查找;而classpath*:会扫描所有JAR包及class类路径下出现的文件
ResourcePatternResoler resolver = new PathMatchingResourcePatternResolver();
Resource resources[] = resolver.getResources("com/smart/**/*.xml");
Resource template = ctx.getResource("file:///res.txt");
Resource template = ctx.getResource("https://my.cn/res.txt");
- ResourceLoader方法getResource的locationPattern可设置资源模式前缀来获取非ClassPathResource资源,locationPattern支持Ant风格
| 前缀 |
示例 |
描述 |
| classpath: |
classpath:config.xml |
从类路径加载 |
| file: |
file:///res.txt |
从文件系统加载FileSystemResource |
| http: |
http://my.cn/res.txt |
加载UrlResource |
9 JAVA.Properties了解一下
- Properties是java自带的配置处理类;Properties加载资源的两种方式
public class Properties extends Hashtable<Object,Object>{
....
public synchronized void load(Reader reader) throws IOException
public synchronized void load(InputStream inStream) throws IOException
username = root
password = password
-------代码示例-------------
InputStream input = ClassLoader.getSystemResourceAsStream("res.properties");
Properties prop = new Properties();
prop.load(inputStream);
String username = prop.getProperty("username");
10 yml配置资源的读取
- 普通java项目如果需要读取yml可引入jackson-dataformat-yaml,而springboot默认配置支持yml的读取
com.fasterxml.jackson.dataformat
jackson-dataformat-yaml
2.9.5
- 基于jackson-dataformat-yaml对yml配置资源的读取
name: chen
params:
url: http://www.my.com
----------代码示例---------------
InputStream input = ClassLoader.getSystemResourceAsStream("res.yml");
Yaml yml = new Yaml();
Map map = new Yaml().loadAs(input, LinkedHashMap.class);;
String name = MapUtils.getString(map,"name");
String url = MapUtils.getString((Map)map.get("params"),"url")
11 优雅地关闭资源,try-with-resource语法和lombok@Cleanup
- 资源的打开就需要对应的关闭,但我们常会忘记关闭资源,或在多处代码关闭资源感到杂乱,有没有简洁的关闭方法呢?
- 自动关闭资源类需实现AutoCloseable接口和配和try-with-resource语法糖使用
public class YSOAPConnection implements AutoCloseable {
private SOAPConnection connection;
public static YSOAPConnection open(SOAPConnectionFactory soapConnectionFactory) throws SOAPException {
YSOAPConnection ySoapConnection = new YSOAPConnection();
SOAPConnection connection = soapConnectionFactory.createConnection();
ySoapConnection.setConnection(connection);
return ySoapConnection;
}
public SOAPMessage call(SOAPMessage request, Object to) throws SOAPException {
return connection.call(request, to);
}
@Override
public void close() throws SOAPException {
if (connection != null) { connection.close(); }
}
}
try (YSOAPConnection soapConnection=YSOAPConnection.open(soapConnectionFactory)){
SOAPMessage soapResponse = soapConnection.call(request, endpoint);
...
} catch (Exception e) {
log.error(e.getMessage(), e);
...
}
- lombok注解@Cleanup,对象生命周期结束时会调用
public void close();对象需实现AutoCloseable接口
import lombok.Cleanup;
@Cleanup
YSOAPConnection soapConnection=YSOAPConnection.open(soapConnectionFactory)
12 资源不关闭,会导致什么最坏的结果
- JDK的原生资源类不关闭,它也不会永远存在。JVM会借助finalize自动关闭它,例如FileInputStream
protected void finalize () throws IOException {
if (guard != null) {
guard.warnIfOpen();
}
if ((fd != null) && (fd != FileDescriptor.in)) {
close();
}
}
- 在JDK9后,用Cleaner机制代替了finalize机制;Cleaner机制自动回收的对象同样需要实现AutoClose接口;Cleaner是基于PhantomReference实现的;对实现细节感兴趣的同学,可自行查阅下相关文档
- 但是使用JDK的提供的资源关闭机制的,那么资源的关闭比手动关闭时要延后很长时间的。据测试,使用try-with-resources关闭资源,并让垃圾回收器回收它的时间在12纳秒。而使用finalizer机制,时间增加到550纳秒
- 不及时关闭资源,就会占用资源,影响其他线程的执行;比如linux的文件资源,linux进程默认能打开的最大文件数是1024(有的是2048,此数值是可配置的);如果一个线程持有十几个文件资源,还要等550纳秒用finalizer机制释放资源,同进程的其他线程都等到花谢了
欢迎指正文中错误
关注公众号,一起交流

参考文章
- 从源码角度理解Java设计模式——装饰者模式
- Java中的管道流
- InputStream乱码问题的解决方法
- 未关闭的文件流会引起内存泄露么?
- char类型与字符编码
- 结合Java详谈字符编码和字符集
- Cleaner 对比 finalize 对比 AutoCloseable