mq消息队列
mq消息队列本质上是一个文件系统,我主要介绍一下kafka,顺便和我司的jmq对比一下,因为我司是自研的消息系统,在网上也有开源的(https://github.com/chubaostream/joyqueue),但是对于kafka这种大家所熟知的消息队列,阿里的rocketmq,我司的jmq都能看到kafka设计的影子,聊kafka更容易理解,感兴趣的可以京东技术的关注公众号。
1:kafka的文件设计


kafka的每个topic都可以创建多个partition,每个partition可以有多个segment,partition是kafka并行操作的最小单元,每个partition可以接受消息的推送和消费,我们可以通过num.partition设置,也可以在创建topic的时候进行制定,并不是越多的partition就越好,partition越多,那么打开的文件句柄会越多,系统的压力也越大,反而吞吐量上不去,具体多少,大家可以看下别的帖子,容量规划这里就不说了,每个partition都有一个index,也就是每隔segment对应一个index,index是consumer进行消费可以查询的依据,值得称赞的是kafka并不是每个message都构建索引,大约4kb进行构建索引,Kafka采用稀疏索引的,查找消息时,首先根据文件名找到所在的索引文件,然后二分法遍历索引文件里找到离目标消息最近的索引,再顺序遍历消息文件找到目标消息。一次寻址的时间复杂度为O(log2n)+O(m),其中n为索引文件中的索引个数,m为索引的稀疏程度。可以看到,寻址过程还是需要一定时间。一旦找到消息后位置后,就可以批量顺序读取,不必每条消息都要进行一次寻址。kafka的数据文件log file的写入是filechannel,采用的是GrowableBufferSupplier,也就是HeapByteBuffer,没采用DirectByteBuffer,因为是scala写的,具体原因我就不得而知了,有而index file的写入是mmap,很多人说这个是kafka快的原因:

但是从压测的情况来看的话,其实并没有太突出,上面的是ms,可以看到DirectBuffer的优势还是很明显的,另外logFile需要频繁的flush,用mmap也不太合适,那么看下我司的mq的文件系统。

对于单个broker上,我们的jmq的每个topic在单个broker上有N个partition,为了解决每个partition的log file都是1个文件的开销问题,N个partition组成了一个partition group,这个log file对应N个index file,解决了文件的太多的开销问题,比较折中,也不影响消费,JMQ采用定长稠密索引设计,每个索引固定长度。定长设计的好处是,直接根据索引序号就可以计算出索引在文件中的位置:
索引位置 = 索引序号 * 索引长度
这样,消息的查找过程就比较简单了,首先计算出索引所在的位置,直接读取索引,然后根据索引中记录的消息位置读取消息。这两种设计各自擅长的场景不同,无所谓优劣。Kafka更加适合批量消费,JMQ更适合单条数据的消费。
2:kafka的选举和数据复制
2.1:kafka的选举

/brokers/ids/[id] 记录集群中的broker id
/brokers/topics/[topic]/partitions 记录了topic所有分区分配信息以及AR集合
/brokers/topics/[topic]/partitions/[partition_id]/state记录了某partition的leader副本所在brokerId,leader_epoch, ISR集合,zk 版本信息
/controller_epoch 记录了当前Controller Leader的年代信息
/controller 记录了当前Controller Leader的id,也用于Controller Leader的选择
/admin/reassign_partitions 记录了需要进行副本重新分配的分区
/admin/preferred_replica_election:记录了需要进行"优先副本"选举的分区,优先副本在创建分区的时候第一个副本
/admin/delete_topics 记录删除的topic
/isr_change_notification 记录一段时间内ISR列表变化的分区信息
/config 记录的一些配置信息
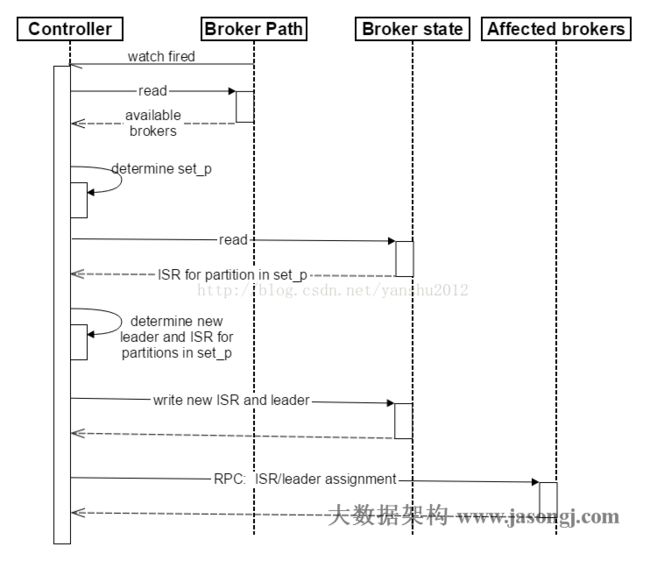
1.Controller在Zookeeper注册Watch,一旦有Broker宕机(这是用宕机代表任何让系统认为其die的情景,包括但不限于机器断电,网络不可用,GC导致的Stop The World,进程crash等),其在Zookeeper对应的znode会自动被删除,Zookeeper会fire Controller注册的watch,Controller读取最新的幸存的Broker
2.Controller决定set_p,该集合包含了宕机的所有Broker上的所有Partition
3.对set_p中的每一个Partition
3.1 从/brokers/topics/[topic]/partitions/[partition]/state读取该Partition当前的ISR
3.2 决定该Partition的新Leader。如果当前ISR中有至少一个Replica还幸存,则选择其中一个作为新Leader,新的ISR则包含当前ISR中所有幸存的Replica(选举算法的实现类似于微软的PacificA)。否则选择该Partition中任意一个幸存的Replica作为新的Leader以及ISR(该场景下可能会有潜在的数据丢失)。如果该Partition的所有Replica都宕机了,则将新的Leader设置为-1。
3.3 将新的Leader,ISR和新的leader_epoch及controller_epoch写入/brokers/topics/[topic]/partitions/[partition]/state。注意,该操作只有其version在3.1至3.3的过程中无变化时才会执行,否则跳转到3.1
4. 直接通过RPC向set_p相关的Broker发送LeaderAndISRRequest命令。Controller可以在一个RPC操作中发送多个命令从而提高效率。
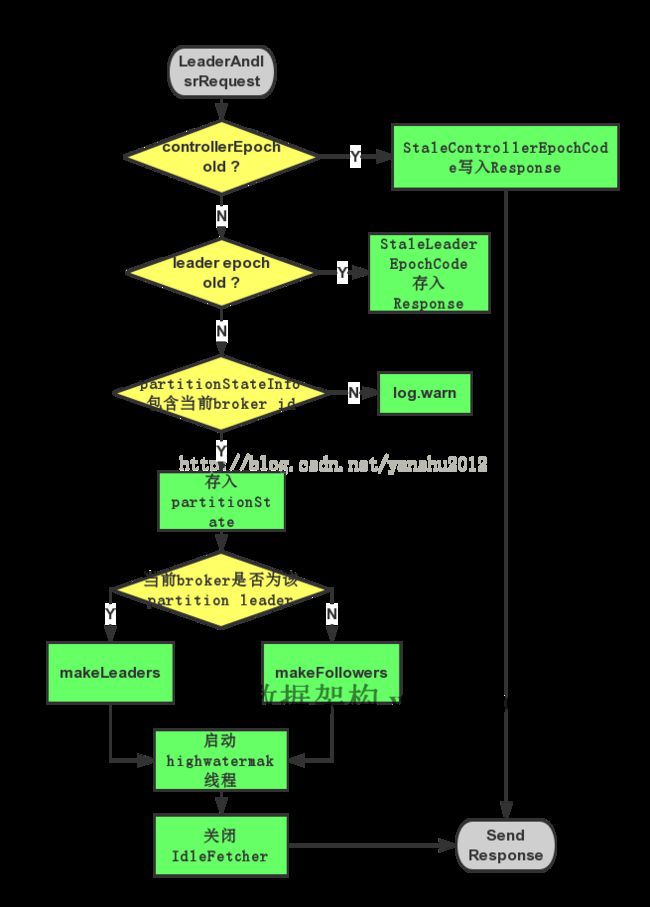
- 检查 Controller 的 epoch,如果是来自旧的 Controller,那么就拒绝这个请求;
- 获取请求的 Partition 列表的 PartitionState 信息,在遍历的过程中,会进行一个检查,如果 leader epoch 小于缓存中的 epoch 值,那么就过滤掉这个 Partition 信息,如果这个 Partition 在本地不存在,那么会初始化这个 Partition 的对象(这时候并不会初始化本地副本);
- 获取出本地副本为 leader 的 Partition 列表(partitionsTobeLeader);
- 获取出本地副本为 follower 的 Partition 列表(partitionsToBeFollower);
- 调用
makeLeaders()方法将 leader 的副本设置为 leader; - 调用
makeFollowers()方法将 leader 的副本设置为 follower; - 检查 HW checkpoint 的线程是否初始化,如果没有,这里需要进行一次初始化;
- 检查 ReplicaFetcherManager 是否有线程需要关闭(如果这个线程上没有分配要拉取的 Topic Partition,那么在这里这个线程就会被关闭,下次需要时会再次启动);
- 检查是否有
__consumer_offsetPartition 的 leaderAndIsr 信息,有的话进行相应的操作。
2.2:kafka的数据复制

1:一开始a的信息是(epoch=0,logStartOffse=0,logEndOffset=2,highWaterMark=1),B的信息是(epoch=0,logStartOffse=0,logEndOffset=2,highWaterMark=0)
2:a贮机,b担任leader,
2.1:如果是0.11之前,是按照HW截断的,这个时候B回截断到0,如果a再回来,那么a会截断到b的HW,a的HW原来为1,
此时为0,这种情况还是好的,如果此时b的HW又重新到3了,那么A的HW=1不会被截断,这就造成了a和b的hw=1上的
数据不一致,此种情况很有问题。
2.2:0.11之后是按照epoch进行截断的,b当选为Leader,此时的(epoch=1,logStartOffset=2),为什么
logStartOffset=0,变成了2,因为epoch增加,leader为保存每个epoch开始的offset,offset会变成logEndOffset,也就是
leo,如果a再到来,就把(epoch=1,logStartOffset=2)返回给a,a只截断到(epoch=0)时,小于logStartOffset的位置,
这里返回的epoch=1,并不是说返回最大的,而是返回比follower大的哪一个,leader保存了所有年代信息,如果a的
epoch=2,就返回epoch=3,以此类推,返回比follower大的哪一个。
3:kafka事务

说到kafka的事务,首先需要说下kafka的幂等性, kafka的幂等性是实现事务的前提。
3.1:kafka的幂等性
Producer 的幂等性指的是当发送同一条消息时,数据在 Server 端只会被持久化一次,数据不丟不重,但是这里的幂等性是有条件的:
- 只能保证 Producer 在单个会话内不丟不重,如果 Producer 出现意外挂掉再重启是无法保证的(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重);
- 幂等性不能跨多个 Topic-Partition,只能保证单个 partition 内的幂等性,当涉及多个 Topic-Partition 时,这中间的状态并没有同步。
如果需要跨会话、跨多个 topic-partition 的情况,需要使用 Kafka 的事务性来实现。
每个 Producer 在初始化时都会被分配一个唯一的 PID,这个pid是server分配的,对于一个给定的 PID,sequence number 将会从0开始自增,每个 Topic-Partition 都会有一个独立的 sequence number。Producer 在发送数据时,将会给每条 msg 标识一个 sequence number,Server 也就是通过这个来验证数据是否重复。这里的 PID 是全局唯一的,Producer 故障后重新启动后会被分配一个新的 PID,这也是幂等性无法做到跨会话的一个原因。
怎么实现幂等性的?
1:每次请求的时候,kafka的produce会把pid + sequence number发送给server端,server端的partition会缓存5个最近的batch请求,例如(pid = 1, seq=0),(pid = 1, seq=1),如果下个请求的(pid = 1, seq=2),就会被接受,如果发送重复,就不用保存,直接跳过,如果下个请求的(pid = 1, seq=5),那么会返回错误。这乍一看没有问题,为什么不能跨partition?为什么仍然不能保证不重?
因为kafka的幂等设计就是针对单个partition的,保存的排重信息也是根据partition维度的,为什么这么做?可以想想我们的场景大多数是单partition有序的,对于单个orderId路由的分片肯定是一样的,我们只需要保证单分片的幂等就可以了。
如果重启,kafka会重新分配,当然,如果连续写入失败,重试,也会进行重置,这个时候pid + seq 和上次的就不一致,pid的路由会被重新计算,单个partition根本就不能防重了,这次的数据会被提交,而上次的数据有可能保存了,有可能没保存,这就是问题所在,没保存还好,保存了就会重复。
3.2:kafka事务性
kafka的事务是为了解决幂等性没有解决的问题,这里kafka主要解决的还是跨分区提交无法解决的问题,这和rocketmq有区别的,场景上不一致,主要kafka的针对批量,复杂性提高太多。
为了实现这种机制,我们需要应用能提供一个唯一 id,即使故障恢复后也不会改变,这个 id 就是 TransactionnalId(也叫 txn.id,后面会详细讲述),txn.id 可以跟内部的 PID 1:1 分配,它们不同的是 txn.id 是用户提供的,而 PID 是 Producer 内部自动生成的(并且故障恢复后这个 PID 会变化),有了 txn.id 这个机制,就可以实现多 partition、跨会话的 EOS 语义。
txn.id是应用指定的,不是由server端分配的,这就保证了txn.id是不会变的,那么这里就说下kafka事务的过程。
3.2.1. Finding a TransactionCoordinator
对于事务性的处理,第一步首先需要做的就是找到这个事务 txn.id 对应的 TransactionCoordinator,Transaction Producer 会向 Broker (随机选择一台 broker,一般选择本地连接最少的这台 broker)发送 FindCoordinatorRequest 请求,获取其 TransactionCoordinator。这个就决定了无论怎么变化,client的partiotion没有变过,这个就好做排重了,因为上面说的pid + seq就是单partition上起作用的。
2. Getting a PID
这个和上面的幂等性完全一致,不做介绍了。这个过程还会做一些别的事情,主要是如果前一个事务的数据状态还是prepare commit,就会置为abort,这样数据就不会重复了,消费端无法消费这个数据,相当于回滚上个异常中断的事务。
3. Starting a Transaction
前面两步都是 Transaction Producer 调用 initTransactions() 部分,到这里,Producer 可以调用 beginTransaction() 开始一个事务操作,
//KafkaProducer
//note: 应该在一个事务操作之前进行调用
public void beginTransaction() throws ProducerFencedException {
throwIfNoTransactionManager();
transactionManager.beginTransaction();
}
// TransactionManager
//note: 在一个事务开始之前进行调用,这里实际上只是转换了状态(只在 producer 本地记录了状态的开始)
public synchronized void beginTransaction() {
ensureTransactional();
maybeFailWithError();
transitionTo(State.IN_TRANSACTION);
}这个过程就相当于初始化事务状态。
4. Consume-Porcess-Produce Loop
1:server端的TransactionManager会初始化本次事务的信息
2:提交data数据
3:把offset信息发送给_transaction_state和_consumer_offsets这二个内部的partition,默认是50个partition,3个副本,这一步相当于保存index的信息
5.Committing or Aborting a Transaction
提交commit数据给TransactionManager,commit通知broker提交数据,主要是GroupCoordinator
GroupCoordinator 在收到相应的请求后,会将 offset 信息持久化到 consumer offsets log 中(包含对应的 PID 信息),但是不会更新到缓存中,除非这个事务 commit 了,这样的话就可以保证这个 offset 信息对 consumer 是不可见的(没有更新到缓存中的数据是不可见的,通过接口是获取的,这是 GroupCoordinator 本身来保证的)。
那么现在说二个问题,1:怎么解决幂等性produce重启导致的重复问题?2:怎么解决跨partition问题?
1:kafka链接到partition的时候,首先做的是回滚,可以让数据看不到。
2:跨partition的问题解决的问题很巧妙,只是换了一个思路,把跨partition写入数据转移到了写入_transaction_state这个内部的partition问题上,由于txn.id没变过,所以总是路由到同一个partition上。
但是实际上考虑到batch的问题,情况会比这简单一些。在producer端发送的时候,同一个TopicPartition的不同transaction的消息是不可能在同一个message batch里的, 而且committed的消息和aborted的消息也不可能在同一batch里。因为在不同transaction的消息之间,肯定会有transaction marker, 而transaction marker是单独的一个batch。这就使得,一个batch要不全部被aborted了,要不全部被committed了。所以过滤aborted transaction时就可以一次过滤一个batch,而非一条消息。
这上面的内容都是基于单分片有序性保证的,上面已经介绍了,这里不多做介绍了,主要是二方面:幂等性解决了单个partition的 Exactly-Once,事务性解决了跨partition的Exactly-Once,mq本质上只是解决了消息一定被发送出去的问题,至于你能不能消费那是另一码事,这篇就到此为止。