YOLOv3 解读:小改动带来的性能大提升
Title: YOLOv3: An Incremental Improvement(2018)
Link: Paper Website
Tips:
- YOLOv3 的改进有哪些,模型融合形成新网络
Summary:
YOLOv3 在 YOLOv2 基础上做了一些小改进,文章篇幅不长,核心思想和 YOLOv2、YOLO9000差不多。
但是这些小改动确带来了不错的性能提升,改动包括为边界框预测分数,多标签分类,预测多尺寸的边界框,替换骨干网络。
文中的各种尝试无论是否 work,都值得我们了解学习,它们能给我们提供思路。
相关文章:
一文读懂 YOLOv1,v2,v3,v4 发展史
YOLOv1 解读:使用 unified system/ one-stage 实现目标检测
YOLOv2 解读:使 YOLO 检测更精准更快,尝试把分类检测数据集结合使用
YOLOv4 解读:CV 同学必读的目标检测技巧大合集
论文目录
- Abstract
- 1. Introduction
- 2. The Deal
- 2.1. Bounding Box Prediction
- 2.2. Class Prediction
- 2.3. Predictions Across Scales
- 2.4. Feature Extractor
- 3. How We Do
- 4. Things We Tried That Didn’t Work
- 5. What This All Means
Abstract
YOLOv3 相比 YOLOv2 检测更准了,而且速度仍然很快。
YOLOv3 在320×320 的图像分辨率上取得了 28.2 mAP,速度在22毫秒内,与SSD一样准确,但速度提高了三倍。
1. Introduction
这是一段风格清奇的 introduction,作者说他比较忙没有太多时间改进 YOLO,但一个项目需要引用 YOLO,所以他对 YOLO 做了一些小改动,这篇论文其实是一篇技术报告,技术报告不需要introduction,所以这部分写得很随意。
报告剩下的部分为:
- YOLOv3 的改进
- 实验结果
- 尝试的一些没效果的做法
- 总结
2. The Deal
如何改进:参考别人的 good idea,训练一个更好的分类器。
2.1. Bounding Box Prediction
继续采用 YOLO9000 使用 anchor box 预测 bounding box 的方法(参考:目标检测中的Anchor)。
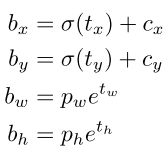
YOLOv3 使用逻辑回归为每个边界框都预测了一个分数 objectness score,打分依据是预测框与物体的重叠度。如果某个框的重叠度比其他框都高,它的分数就是 1,忽略那些不是最好的框且重叠度大于某一阈值(0.5)的框。
2.2. Class Prediction
和 YOLOv2 一样,YOLOv3 仍然采取多标签分类(multilabel classification),因为标签有重叠,比如人和女人。训练中为每个类使用独立的逻辑分类器,使用 binary cross-entropy loss 。
2.3. Predictions Across Scales
YOLOv3 检测时会预测三个尺寸的检测框。因此,卷积层最后输出三维的边界框(4 个偏移量),分数(1个)和类别(80个),所以输出的向量为 N×N× [3 ∗ (4 + 1 + 80)]。
再说一下 k-means 聚类中心当作参考框,我们只是随意选择了9个聚类和3个比例,然后将这些聚类在各个比例之间平均分配。
2.4. Feature Extractor
特征提取使用了新网络。它是 YOLOv2 的 Darknet-19 和残差网络的一个混合网络。它使用了连续的 3×3 和 1×1 卷积层以及 shortcut connections,最后有 53 个卷积层,姑且称为 Darknet-53。
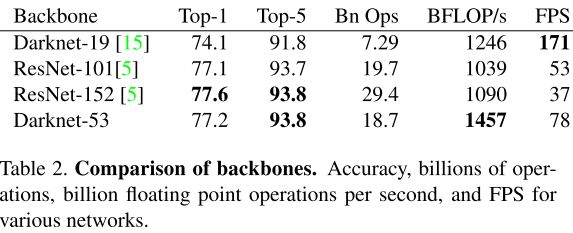
在 ImageNet 和这些网络比较,可以看出 Darknet-53 分类比较有效。
3. How We Do
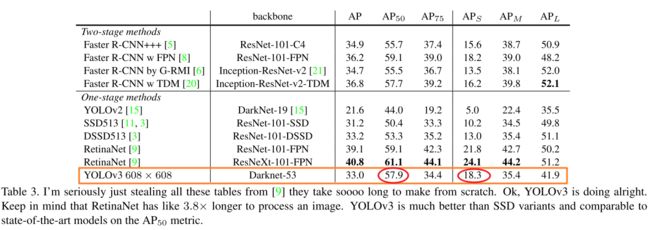
YOLOv3 在 COCO 数据集上的表现和分析如下:
和 SSD 比性能差不多,但速度快 3 倍。从性能看, YOLOv3 和 RetinaNet 这样的模型还有一些差距。
单看 AP50 这个指标(IOU=0.5),YOLOv3 快追上 RetinaNet,远在 SSD 及它的其他版本之上,这体现了 YOLOv3 的潜力。但看其他指标,当 IOU 要求变高 YOLOv3 的性能变低,这说明模型还需要解决对齐的问题。
YOLO 以前的版本检测小物体不理想,但看 YOLOv3 的 APs 指标相对较高,这说明多尺寸训练比较有效。但 APm 和 APL 相对较差。
4. Things We Tried That Didn’t Work
为改进模型的其他没效果的尝试:
Anchor box x, y offset predictions
使用线性激活函数将 x,y 的偏移量预测为框宽度或高度的倍数。
Linear x, y predictions instead of logistic
使用线性激活来直接预测x,y偏移量,而不是逻辑回归。
Focal loss
另一种损失。→ 参考
Dual IOU thresholds and truth assignment
模仿 Faster R-CNN,在训练中使用两个 IOU 阈值。
5. What This All Means
这部分是 conclusion 和 discussion。
YOLOv3 是一个又准又快的目标检测器,实验证明它比 YOLOv2 性能提升不少。
根据实验,YOLOv3 的 AP 在 IOU 为 0.5 到 0.95 的情况下表现不太好,但在 IOU 为 0.5 的情况下表现不错。