从零开始实现Pixiv爬虫
新学期学的Python数据分析(笑)搞了个期末作业,作为绅士自然不可能进行常规操作,于是本着se图是第一生产力去搞了个Pixiv的爬虫,然后又本着给后代的诸位绅士们指路(没错我也成为了光)的心情,来搞了个博客,由于是第一次写博客这玩意,很多功能还不是很清楚,有错漏的地方还请和我联系。
前提材料:实现科学上网

文章目录
- 1.从零开始实现模拟登录
- 1.1 登录前的数据分析
- 1.2 从数据分析开始的数据提取
- 1.3 从数据提取开始实现模拟登录
- 1.4从模拟登录开始的一些展望
- 2.从零开始实现排行榜图片爬取
- 2.1 排行榜的数据分析
- 2.2 从图片id到图片url获取
- 2.3 排行榜图片下载
- 3. 代码优化及结尾
- 3.1 加入多线程
- 3.2 创建类、整合变量、优化代码格式、封装函数和修复BUG
- 3.3 结尾
- 3.4 完整代码
- 3.5 结果截图
1.从零开始实现模拟登录
1.1 登录前的数据分析
直接上图:Pixiv登录界面链接
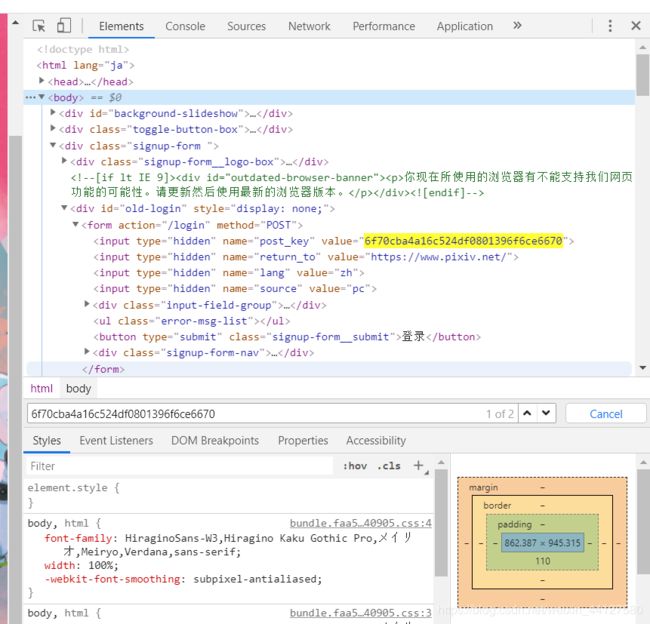
进入登录页面,然后F12进入开发者选项——选择Network——选择XHR,然后直接点登录,查看抓到的POST包:login?lang=zh,直接看Headers往下拉到底查看Form Date,看到有一堆的东西,这就是我们点击登录后主机向Pixiv发送的登录数据,其中最重要的是post_key,这玩意是我们登录的时候必须要有的,但是经多次检查发现这玩意是随机生成的,于是将其复制到网页源代码查找,发现post_key直接放在了源代码里面。
1.2 从数据分析开始的数据提取
既然post_key直接放在了源代码中,我们提取起来就很方便了。从源代码中提取数据的方法有很多种,我选择用BeautifulSoup 进行网页分析。
from bs4 import BeautifulSoup as bs
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'referer': 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index'
# 注意校验码referer,不添加会被反爬403错误,可以在抓包里找
}
url = 'https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page'
html = requests.get(url, headers=headers).text
key_soup = bs(html, 'lxml')
post_key = key_soup.find('input')['value'] # 查找post_key
这样post_key就获取到了,当然除了这种方法还有用正则啊什么的,自行探索。
1.3 从数据提取开始实现模拟登录
首先要理解,直接使用requests的get是不行的,因为模拟登录后没有保持登录等于没登。所以我使用requests.session,让请求变成会话,这样就能保证登录状态了。
将代码整合一下。
from bs4 import BeautifulSoup as bs
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'referer': 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index'
# 注意校验码referer,不添加会被反爬403错误,可以在抓包里找
}
accounts_url = 'https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page'
login_url = 'https://accounts.pixiv.net/api/login?lang=zh' # 登录URL
se = requests.session()
pixiv_key_html = se.get(accounts_url, headers=headers).text
pixiv_key_soup = bs(pixiv_key_html, 'lxml')
post = pixiv_key_soup.find('input')['value']
data = {
'pixiv_id': '', # 你的用户名
'password': '', # 你的登陆密码
'post_key': post,
"ref": "wwwtop_accounts_index",
"source": "pc",
'return_to': 'https://www.pixiv.net/'
}
dare = se.post(login_url, data=data, headers=headers).text # 登录
da = json.loads(dare)
print(da)
当然现在这样登录会被要求google v3验证,就是该死的人机验证(请选择你的消防栓),模拟登陆到此战败。
1.4从模拟登录开始的一些展望
那么有没有解决方法?有,使用 selenium/splinter+requests吧,上一段基本完整的代码。
注意:食用以下代码需要下载chormdrver
import time
from splinter.browser import Browser
browser = None
browser_name = "chrome" # 浏览器名
driver_path = "chromedriver.exe" # 打开浏览器的驱动
base_url = "https://www.pixiv.net/ranking.php" # pixiv排行榜页面
browser = Browser(driver_name=browser_name, executable_path=driver_path) # 打开浏览器
browser.visit(base_url) # 访问页面
time.sleep(2) # 暂停两秒,等待浏览器加载完成
print(".......请在打开的浏览器中登录........")
browser.find_link_by_text('登录').click() # 点击登录
username = ''
password = ''
if username is not None:
browser.find_by_xpath('//input[@autocomplete="username"]').fill(username)
if password is not None:
browser.find_by_xpath('//input[@autocomplete="current-password"]').fill(password)
browser.find_by_text('登录').last.click()
那为什么我还要写这些呢,因为除了Pixiv,也许我们还要爬其他的一些要登录的网页,那么至少我们掌握了模拟登陆的开发流程。
而且我所爬取的排行榜并不需要模拟登陆,如果我模拟登陆成功那么到结题展示的时候我很可能会社会性死亡,所以我最终放弃了模拟登陆。
2.从零开始实现排行榜图片爬取
2.1 排行榜的数据分析
我们进入排行榜页面,继续F12——Network——XHR
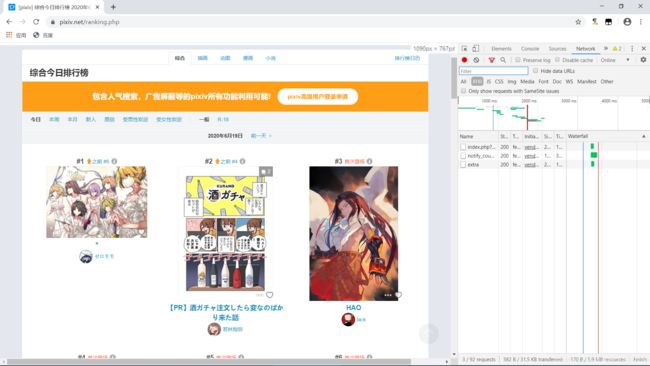
好像没有什么数据包?那我们把页面往下拉,直到第51位,这时候传来了新的数据包

我们点进去,将里面的Request URL复制然后新页面打开,会得到满屏幕的数据,但是这些数据是不能直接读取的,我们需要进行解析,ctrl+a将内容全部复制到www.json.cn,这样数据就清晰明了了。
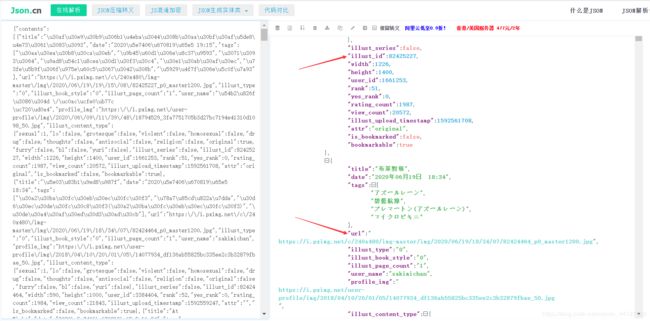
注意到url和illust_id,我们直接点击url很大概率是403或者是小图,所以这里的url并没有太大作用,我们需要的是illust_id,再通过id来构建真正的url。
假如我们把url的p值改为1,那么我们就得到了第一页的数据,以此推类。
python提供了关于json操作的库,库名就是json,我们可以使用json库对json数据进行提取。
import json
list_id = []
url_rank = 'https://www.pixiv.net/ranking.php?' # 排行榜url
params_rank = { # 排行榜url接口,通过分析url链接构建
'mode': moder, # 榜名,可以日榜:daily、周榜:weekly、月榜:monthly
'content': 'illust', # 搜索类型,可根据自己需要更改,见pixiv排行榜链接头
'p': '1', # 页数,最大为10页,每页50条
'format': 'json'
}
url_get = requests.get(url_rank, headers=headers, params=params_rank).text
url_json = json.loads(url_get)
# 注意json返回后是一个字典,我门通过索引字典取得illust_id
for dict1 in url_json['contents']: # 获取图片id
list_id.append(dict1['illust_id'])
2.2 从图片id到图片url获取
到此我们应该可以想到如何构建真正的图片url了,即通过修改小图的url实现真正的url,但这样并不能获取到所有的图片,因为有的图片存在多页,排行榜提供的url仅能让我们下载上榜的一页,那我们如何实现获取所有的图片url?
随便点进一张图片进行数据分析,我们会发现并没有得到有用的数据,于是我们找到一个存在多页的排行榜图片进行分析,我们开启抓包后再点击查看全部,发现一个新数据包。

打开该包的url提取数据进行json分析,我们发现:

这样我们的所有url就可以通过json提取获取到了。
list_url = []
ID = list_id.pop(0) # 提取列表第一个URL并删除
url_page = 'https://www.pixiv.net/ajax/illust/' + str(ID) + '/pages?lang=zh' # 查询真实ID包
url_text = requests.get(url_page, headers=headers).text
url_testjson = json.loads(url_text)
for dict2 in url_testjson['body']: # 获取url
list_url.append(dict2['urls']['original'])
url = dict2['urls']['original']
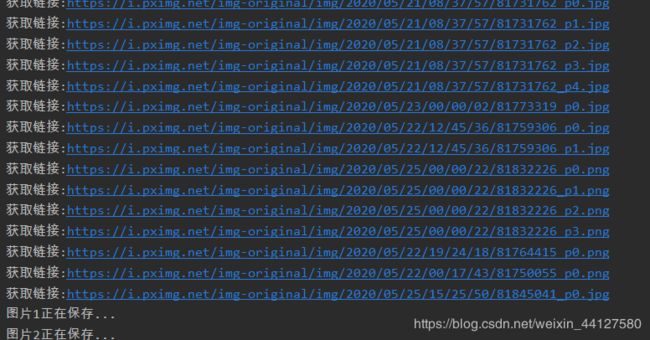
print(f'获取链接:{url}')
2.3 排行榜图片下载
到这里基本上可以知道接下来的代码怎么写了,不多说了,直接上代码。
import os
j = 1 # 图片编号
for i in list_url:
headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=monthly' # 注意添加防盗链
pixiv_test = requests.get(i, headers=headers)
path = params_rank['mode'] + '/' + str(j) + '.jpg' # 文件名创建
if not os.path.exists(params_rank['mode']): # 如果没有文件夹,则创建文件夹
os.mkdir(params_rank['mode'])
with open(path, 'wb') as f:
f.write(pixiv_test.content) # 以二进制保存图片
j += 1
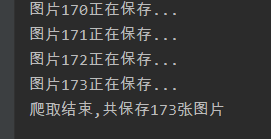
print(f'图片{j}正在保存...')
到此代码就基本完成了,但是我们仍然需要进行代码优化,一是为了方便自己和他人阅读,二是Pixivt图片的下载速度实在是龟速。
3. 代码优化及结尾
3.1 加入多线程
在获取图片url和下载图片两处地方,我们可以加入多线程进行优化,提升代码运行速度。这里仅展示获取图片url部分:
import threading
glock = threading.Lock() # 创建一个锁
def url_get():
while True:
glock.acquire() # 加锁
if len(list_id) == 0:
glock.release() # 释放锁
break
else:
ID = list_id.pop(0) # 提取列表第一个URL并删除
glock.release() # 释放锁
url_page = 'https://www.pixiv.net/ajax/illust/' + str(ID) + '/pages?lang=zh'
url_text = requests.get(url_page, headers=headers).text
url_testjson = json.loads(url_text)
for dict2 in url_testjson['body']: # 获取url
list_url.append(dict2['urls']['original'])
url = dict2['urls']['original']
print(f'获取链接:{url}')
for j in range(3): # 多线程并发
urlget = threading.Thread(target=url_get())
urlget.start()
3.2 创建类、整合变量、优化代码格式、封装函数和修复BUG
以上代码仅实现了单页的获取,我们需要修改代码,使其实现多页排行榜获取。
还有各种格式问题,创建类和整合变量能让我们的代码更加清晰明了,封装函数则是让我们的代码更加方便操作以实现不同功能。
3.3 结尾
感谢各位能看到这里,这是凉生真正意义上完成的第一个爬虫,虽然还有很多缺陷,比如懒得实现的自助搜索功能(主要是搜索出来的图片质量参差不齐,让人难受),还有模拟登陆失败导致无法自动爬取某些奇怪的图片(懂的都懂),不过结果终归是好的。不过,不要直接拿代码当做你的作业,鬼知道老师有什么办法查到(笑)。
最后,望诸位绅士共勉。
循循而进,一往无前。
3.4 完整代码
import json
import os
import requests
from bs4 import BeautifulSoup as bs
import threading
class Pixiv:
def __init__(self, moder, pn):
self.pixiv_username = ''
self.pixiv_password = ''
self.accounts_url = 'https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2F&lang=zh&source=pc&view_type=page' # 登录界面连接
self.login_url = 'https://accounts.pixiv.net/api/login?lang=zh' # 登录URL
self.post = [] # 获取登录所需的随机cookie
# 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' Linux请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
'referer': 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index'
# 校验码,不添加会被反扒403错误
}
self.list_id = [] # id列表
self.list_url = [] # 排行榜url列表
self.url_rank = 'https://www.pixiv.net/ranking.php?' # 排行榜url
self.params_rank = { # 排行榜url接口
'mode': moder,
'content': 'illust',
'p': pn,
'format': 'json'
}
self.i = 1 # 图片id
self.glock = threading.Lock() # 锁
def login(self): # 模拟登陆
se = requests.session()
pixiv_key_html = se.get(self.accounts_url, headers=self.headers).text
pixiv_key_soup = bs(pixiv_key_html, 'lxml')
self.post = pixiv_key_soup.find('input')['value']
# print(self.post)
data = {
'pixiv_id': self.pixiv_username,
'password': self.pixiv_password,
'post_key': self.post,
"ref": "wwwtop_accounts_index",
"source": "pc",
'return_to': 'https://www.pixiv.net/'
}
dare = se.post(self.login_url, data=data, headers=self.headers).text # 登录
da = json.loads(dare)
print(da)
se.close()
# Pixiv.test(self)
# Pixiv.url_get(self)
def id_get(self): # 获取rank作品id
if self.params_rank['mode'] == '1':
self.params_rank['mode'] = 'daily' # 日排行
self.headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=daily&content=illust'
elif self.params_rank['mode'] == '2':
self.params_rank['mode'] = 'weekly' # 周排行
self.headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=weekly&content=illust'
elif self.params_rank['mode'] == '3':
self.params_rank['mode'] = 'monthly' # 月排行
self.headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=monthly&content=illust'
for u in range(int(self.params_rank['p'])):
self.params_rank['p'] = str(u+1)
# print(self.params_rank)
url_get = requests.get(self.url_rank, headers=self.headers, params=self.params_rank).text
url_json = json.loads(url_get)
# print(url_json)
for dict1 in url_json['contents']: # 获取图片id
self.list_id.append(dict1['illust_id'])
# Pixiv.test(self)
def url_get(self): # 多线程获取url
while True:
self.glock.acquire() # 加锁
if len(self.list_id) == 0:
self.glock.release() # 释放锁
break
else:
ID = self.list_id.pop(0) # 提取列表第一个URL并删除
self.glock.release() # 释放锁
test1 = 'https://www.pixiv.net/ajax/illust/' + str(ID) + '/pages?lang=zh' # 查询真实ID包
url_text = requests.get(test1, headers=self.headers).text
url_testjson = json.loads(url_text)
for dict2 in url_testjson['body']: # 获取url
self.list_url.append(dict2['urls']['original'])
url = dict2['urls']['original']
print(f'获取链接:{url}')
# def test(self): # 测试保存
# j = 1
# for i in self.dict_rank:
# self.headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=monthly'
# pixiv_test = requests.get(i, headers=self.headers)
# path = self.params_rank['mode'] + '/' + str(j) + '.jpg'
# if not os.path.exists(self.params_rank['mode']):
# os.mkdir(self.params_rank['mode'])
# with open(path, 'wb') as f:
# f.write(pixiv_test.content)
# j += 1
# print(f'图片{i}正在保存...')
def download(self): # 多线程下载
while True:
self.glock.acquire() # 加锁
if len(self.list_url) == 0:
self.glock.release() # 释放锁
break
else:
if not os.path.exists(self.params_rank['mode']): # 创建文件夹
os.mkdir(self.params_rank['mode'])
url = self.list_url.pop(0) # 提取列表第一个URL并删除
self.glock.release() # 释放锁
# 修改文件名
if url[-3:] == 'jpg':
path = self.params_rank['mode'] + '/' + str(self.i) + '.jpg'
elif url[-3:] == 'png':
path = self.params_rank['mode'] + '/' + str(self.i) + '.png'
pixiv_img = requests.get(url, headers=self.headers)
with open(path, 'wb') as f:
f.write(pixiv_img.content)
print(f'图片{self.i}正在保存...')
self.i += 1
def main():
print('##————Pixiv————##')
moder = input('请输入排行榜的时间(日:1/周:2/月:3):')
pn = input('请输入你想要多少页(50/页):')
pixivc = Pixiv(moder, pn)
pixivc.id_get()
for j in range(3):
urlget = threading.Thread(target=pixivc.url_get())
urlget.start()
for i in range(3):
download = threading.Thread(target=pixivc.download())
download.start()
print(f'爬取结束,共保存{pixivc.i-1}张图片')
if __name__ == "__main__":
main()
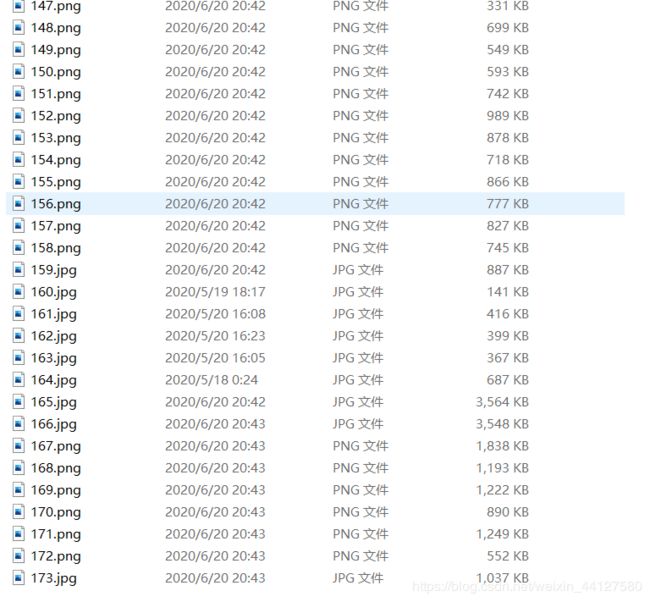
3.5 结果截图