Anchor-free应用一览:目标检测、实例分割、多目标跟踪
作者|杨阳@知乎
来源|https://zhuanlan.zhihu.com/p/163266388
从去年5月开始,我一直对Anchor-free工作保持着一定的关注。本次借组内的paper reading分享的契机,整理了与Anchor free相关的一些工作。一方面是分享近期在目标检测领域中一些工作,另一方面,和大家一起梳理一下去年非常火热的网络模型CenterNet、FCOS,当我们把他们迁移到分割、多目标追踪等其他任务上时,大佬们是如何去设计的。



一、anchor free在目标检测中的应用
首先我们要回答为什么要有 anchor?在前几年,物体检测问题通常都被建模成对一些候选区域进行分类和回归的问题。在单阶段检测器中,这些候选区域就是通过滑窗方式产生的 anchor;在两阶段检测器中,候选区域是 RPN 生成的 proposal,但是 RPN 本身仍然是对滑窗方式产生的 anchor 进行分类和回归。

这里我列出的几种anchor-free 方法,是通过另外一种手段来解决检测问题的。CornetNet通过预测成对的关键点(左上角与右下角)来表征目标框;CenterNet和FCOS通过预测物体中心点及其到边框的距离来表征目标框;ExtremeNet是通过检测物体四个极值点,将四个极值点构成一个物体检测框;AutoAssign也是近期的一篇论文,提出一种在anchor free检测器上,正负样本标签的新的分配策略;Point-Set是近期ECCV 2020的一个工作,提出来一个更加泛化的point-based的anchor表示形式,统一了目标检测、实例分割、姿态估计的三个大任务,后面我们会进一步展开。

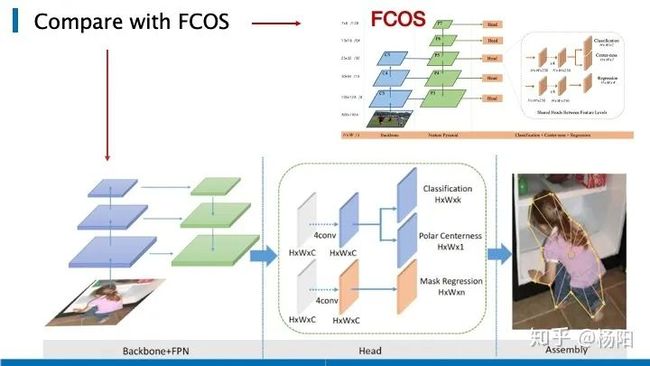
首先我们来简单回顾一下FCOS的网络架构,其中C3, C4, C5表示骨干网络的特征图,P3到P7是用于最终预测的特征级别。这五层的特征图后分别会跟上一个head,head中包括了三个分支,分别用于分类、中心点置信度、回归的预测。整体的架构非常简洁,有很多人通过修改FCOS的输出分支,用于解决实例分割、关键点检测、目标追踪等其他任务。
下边我列出来原作者在更新论文版本时,做出的三点细节上的调整,一是使用了新的中心点采样的方式,在判断正负样本时,考虑了不同阶段的步长值,去调整了正样本所处框的大小。而非像FCOS v1中,直接判断其是否落在gt bbox里。这种新的center sampling方式,使得难判别的样本减少,是否使用center-ness branch造成的精度区别也减小了。二是将回归的loss换成了GIoU loss。三是FCOS v2 的不同特征层在回归参数的时候,使用了不同的reg范围(除以了stride)。(而在FCOS v1中,是用过乘以一个可以学习的参数,该参数在FCOS v2有保留,但重要性减小。)
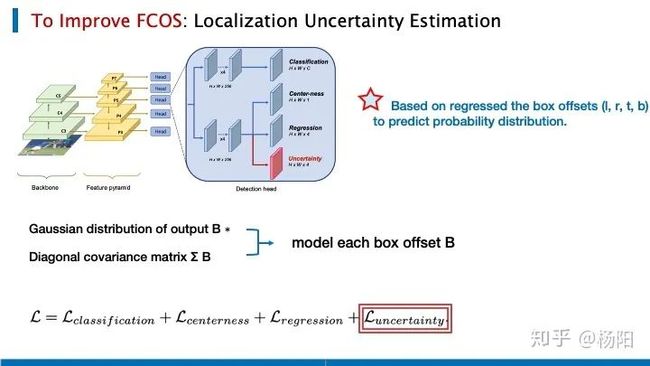
为了提升fcos的效果,特别考虑到一些不稳定环境,由于传感器噪声或不完整的数据,目标探测器需要考虑定位预测的置信度,有人提出加入一个预测bbox的不确定度的分支。
这里的不确定度是通过预测bbox的四个offset的分布得到的。这里假设每一个示例都是独立的,用多元高斯分布的输出与协方差矩阵的对角矩阵去表征每一个bbox的offset。在FCOS的分类、中心点、回归的三个loss上,新增了一个衡量bbox offset的不确定度的loss。下边我们来具体看一下他的实现方式。

这里的box offsets我们用 (l, r, t, b) 来表示, 是网络的可学习的参数,B的维度是4, μ 是bbox的偏置,计算得到的多元高斯分布, 是之前提到的协方差矩阵的对角矩阵,
带入网络设计的衡量bbox offset的不确定度的loss,我们可以着重关注红色线左边的这一项,当预测出的 μ 与真实的bbox的高斯分布 相差很大时,网络会倾向于得到一个很大的标准差 ,也就是说这个时候的不确定度是很大的。当然它后边还有一个类似正则化的约束 ,去限制 不要过大。
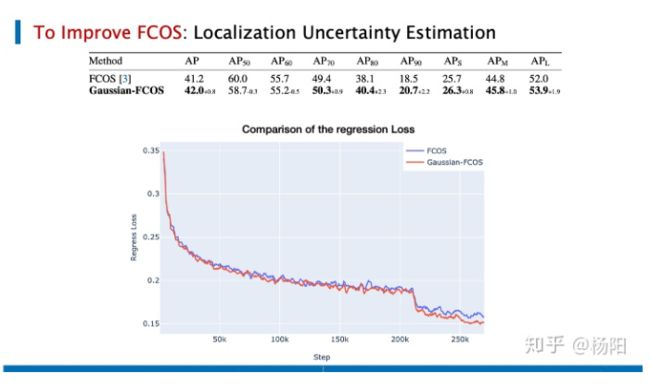
对比FCOS,同样使用ResNet-50的框架,它在coco数据集上AP能提升0.8个点。对比两个loss,其回归情况也是更好的。

下面我们来看看,《Point-Set Anchors for Object Detection, Instance Segmentation and Pose Estimation》这个point-based的网络,是如何使用回归的思路去统一Object Detection, Instance Segmentation,Pose Estimation三个大任务的。作者称这是统一这三大任务的第一人。
作者认为,在object detection领域,无论是若干个IOU大于一定阈值的anchor表示正样本,还是用物体的中心点来表示正样本。不论是anchor based或者anchor-free based的方法,对于正样本在原图的定位,都是基于回归的形式直接回归矩形坐标,或者是矩形长宽+矩形中心点offset。Anchor从某种程度上来说,表示的只是一种先验信息,anchor可以是中心点,也可以是矩形,同时它还可以提供更多的模型设计思路,如正负样本的分配,分类、回归特征的选择。所有作者的思路是,能不能提出更加泛化的anchor,泛化的应用于更多的任务中,而不只是目标检测中,并给出一个更好的先验信息。
对于Instance Segmentation和Object Detection,使用最左边的Anchor,其有两个部分:一个中心点和n个有序锚点,在每个图像位置,我们会改变边界框的比例和长宽比来形成一些anchor,这里和anchor-based的方法一样,涉及到一些超参数的设置。对姿态估计中的anchor,使用训练集中最常见的姿态。Object Detection的回归任务比较简单,用中心点或者左上/右下角点回归即可。对于Instance Segmentation来说,作者使用了特定的匹配准则去匹配右图中绿色的Point-set anchor中的anchor points和黄色的gt实例的points,并且转换为回归任务。
右边的三个图分别是将绿色与黄色的点,最近的相连;将绿色的点与最近的边缘相连;最右侧中时作者优化后的方式,对角点采用最近点的方法,根据角点得到的最近四个点将gt的轮廓划分成4个区域。将上边界与下边界上绿色的点,做垂线对应到有效的gt point(若不在区域内,则无效,例如图中的绿色空心点)。

总的来说,Point-set用它提出的新的anchor的设计方式代替传统的矩形anchor,并在头部附加一个并行的回归分支用于实例分割或姿态估计。图中展示了它的网络架构,和retinanet一样,作者使用了不同尺度的特征层,head包含了用于分类、分割姿态的回归、检测框的回归的子网络。每一个子网络都包含了四个3乘3的、stride为1的卷积层,只在姿态估计任务上使用的FAM模块,和一个输出层。下边的表格中,列出的是输出层的维度,分别对应了三个任务。

其损失函数非常简单,对分类使用focal loss,对回归任务使用L1 loss。
除了目标归一化和将先验知识嵌入anchor的形状之外,作者也提到了我们如何进一步用anchor去聚合特征,以保证特征变换不变性、并拓展到多阶段学习当中。
(1)我们将可变卷积中的可学习偏移量替换为point-based anchor中点的位置。
(2)由于人体形状的这个回归,是相对检测更加困难的。一方面是由于它对特征的提取要求非常大,另一方面是不同的关键点之间存在差异。所以作者提出,可以直接使用第一阶段的姿态预测作为第二阶段的anchor(分类、掩模或位姿回归、边界盒回归),使用额外的细化阶段进行姿态估计。

二、介绍三篇在实例分割领域的模型
它们都参考了FCOS的做法,将目标检测中anchor-free的思想,迁移到了实例分割的任务上。网络的具体细节不会展开讲,这里只会说到他们在解决实例分割任务时,在FCOS的整体架构上做了哪一些调整。
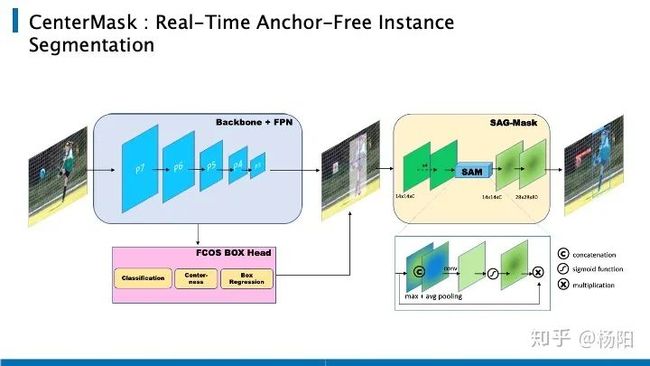
首先讲到的是CenterMask,把这个放在最前面是因为他的想法非常直接,这个结构可以理解成 FCOS + MaskRCNN 的 mask的分支。

我们可以将它和FCOS做一下对比,输入图像通过 FCOS 得到目标框,这一部分是一样的。之后类似 MaskRCNN,用 ROIAlign 把对应的区域 crop 出来,resize 到 14 x14 ,最后经过 mask branch 计算 loss。想法非常简单。

第二篇是EmbedMask,在保证近似精度的基础上,它的最快速度可以达到MaskRCNN的三倍。它采取了one-stage方法,相当于直接使用语义分割得到分割结果之后,在使用聚类或者一些手段将同一个实例的整合到一起,得到最终实例的分割结果。

整个网络的结构如上图所示,还是一个FPN的结构,在分辨率最大的特征曾P3使用pixel的embedding,将每个pixel都embedding成一个D长度的向量,因此最后得到的是H_W_D的特征图。然后依次对每个特征图P3、P4、P5、P6、P7使用proposal head,也就是传统的目标检测的head,再其中的改进就是,对于每个proposal也都embedding成一个D长度的向量。使用一个margin来定义两个embedding之间的关联程度,如果小于这个embedding,就认为这个pixel和这个proposal是同一个instance。但是呢,文中提出使用一个人为定义的margin,会导致一些问题,因此呢,本文就提出了一个learnable margin,让网络自动学习每个proposal的margin,就如结果图中所示的proposal margin那条路径。对比FCOS,EmbedMask加入了图中蓝色的模块。
虽然EmbedMask和CenterMask等工作都是基于一阶段的检测算法,来做实例分割,但是它的核心要点,其实并没有变,都是基于一个足够好的detector来从proposal里面生成mask。事实证明这非常有效,基于一个足够好的detector的实例分割方法不仅仅有利于找到更多的mask,同时这些mask的生成反过来会提升detector本身的效果。所以你可以看到这两个实例分割的box AP都要比FCOS要高,当然这也是必然。
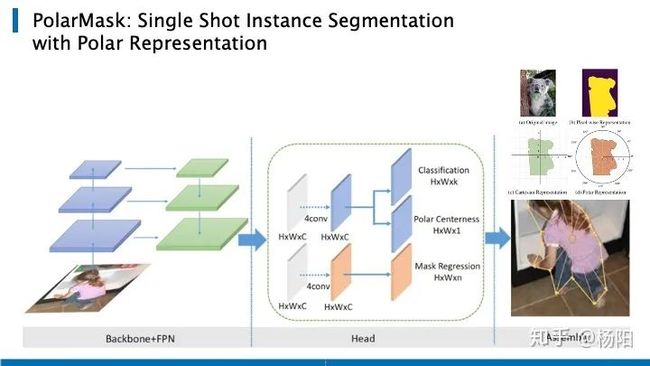
第三篇是PolarMask,它也是基于FCOS,把实例分割统一到了FCN的框架下。PolarMask提出了一种新的instance segmentation建模方式,在将极坐标的360度等分成36分,通过预测这36个方向上,边缘到极坐标中心的距离,从而得到物体的轮廓。

三、对多目标追踪领域的一些关注
这里主要对比了两篇基于CenterNet的扩展出的工作。首先简单介绍一下MOT(Multi-Object Tracking)的任务,它需要对视频中的每一帧进行物体检测,并对每一个物体赋予一个id,去追踪这个目标。
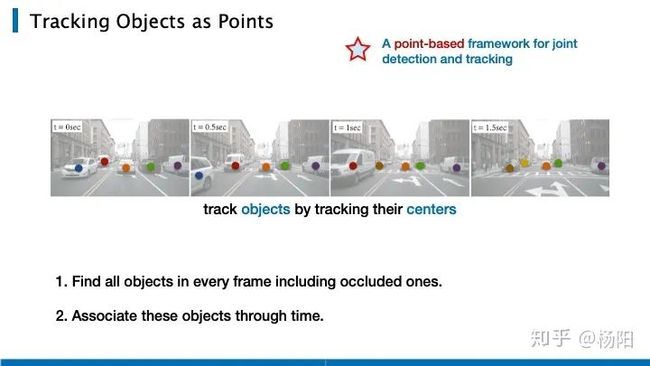
CenterTrack是CenterNet的原作者做的工作,在将目标检测任务扩展到多目标检测上时,作者通过追踪物体的中心点,来解决追踪问题。多目标检测任务有两个关键,一是我们需要把每一帧当中的物体检测出来,这里包括了遮挡物体;二是我们需要在时间维度上,对物体做id的匹配。

下边这张图中的红色区域是为了解决Track任务时,输入了t时刻的图像 、t-1时刻的图像 以及在t-1时刻的检测出的所有物体 ,这里的红色区域是不同于目标检测任务的,新增了四个通道(其中三个通道是图像的输入、还有一个通道的计算会在后边展开)。
在输出部分,网络除了输出检测的中心峰值点的heatmap与预测长宽的特征图之外,网络还输出了一个2通道的offset,这里的offset表示的是两帧之间,物体的移动距离。

左边是网络的输入,右边是网络的输出。在数学上的表示I 为的是图像输入、T中的b表示的是bbox,右边分别是检测的中心峰值点、长宽的特征图、物体移动的偏移量。

以上是在网络训练时,其对应中心峰值点、长宽的特征图、物体移动的偏移量的三个损失函数的具体表现形式。在解决中心点预测的任务是,这里采用的是focal loss,x、y表示了点在heatmap上的位置,c是类别。Y是属于0,1的峰值图, 是渲染了高斯形状的凸起的峰值,对每一个位置,如果它在某个类别数存在中心点,在对应的channel上就会形成一个峰,我们对每个位置取出最大的坡高。其中p表示中心点,q为位置。我们得到这些最大坡高之后,放到1个通道的heatmap中,做为网络输入的一部分。和上一帧的三通道的图片,就组成了前面说的,在解决tracking任务时,新增的4个channel的输入。
对长宽和偏移量的损失计算,用的就是简单的L1 loss。有了足够好的偏移量预测,网络就可以去关联前一时刻的目标。对于每个检测位置p,我们将它与之前最近的物体赋予同一个id,如果在一个半径κ中,没有前一个时刻的目标,我们就生成一个新的追踪。

FairMOT也是基于CenterNet的工作,和CenterTrack是同期的。与CenterTrack引入目标框在前后帧中的移动距离偏置不同,它借鉴了重识别的想法,在检测的分支上,加入了一个Re-ID的分支,它将目标的id识别的embedding作为分类任务。在训练时,所有训练集中具有相同id的所有对象实例都被视为一个类。通过给特征图上的每一个点,附上一个128维的Embedding向量,最后将这个向量映射到每一个类的分数p(k)。其中k是类别数(即出现过的id), 是gt的one-hot的编码,最后用softmax 计算loss。
2020-7-24更新:可能有人会对这里的embedding映射到分类的做法,提出一些质疑,当在后续帧中出现大量新的人的时候,FairMot能给这些新的人赋予一正确的新id吗?作者在解决这个问题的时候,在训练的时候采用的是分类loss,测试阶段采取用cos距离做判断。并且,当reid不可靠的时候,就用bbox IOU来匹配。具体地,对 reid embedding没匹配上bbox,用IOU得到前一帧中可能的追踪框,计算他们之间的相似度矩阵,最后用匈牙利算法得到最后的结果。


最后附上在本次学习梳理的过程中,让我受益的一些技术文链接:
陀飞轮:目标检测:Anchor-Free时代
FY.Wei:利用Point-set Anchor统一物体检测,实例分割,以及人体姿态估计
陈恺:物体检测的轮回:anchor-based 与 anchor-free https://zhuanlan.zhihu.com/p/62372897

觉得有用麻烦给个在看啦~ 