构造函数与复制构造函数
本来,第二章的标题是“The Semantics of Constructors (构造函数语意学)”,晦涩难懂,但实际很简单,讲的就是constructor和copy constructor在编译阶段的构造规则。
1. 构造函数(Constructor)
首先,有两个问题,绝大多数人会认为它们是正确的:
- 对于任何class,如果没有定义default constructor,那么编译器便会自动合成(构造)一个出来?
- 编译器自动合成(构造)的default constructor会显式设定好类中每个data member的初始值?
当然,上面两个问题都不是正确的。我们先看第一个问题,如果没有定义default constructor,那么编译器什么时候会合成出一个constructor?
答案是:在编译器需要的时候。
程序的需要 vs 编译器的需要
我们现在的问题是,编译器需要default constructors的时候是什么时候?看下面的代码:
class Foo
{
public:
int val;
Foo *pnext;
};
void foo_bar()
{
// PROGRAM need bar's members zeroed out
Foo bar;
if(bar.var || bar.pnext)
// ... do something
// ...
}实际运行的结果是,if语句几乎永远不会执行,因为虽然Global object的内存会保证程序运行的时候清零,但Foo bar对象是local object,它只会在堆栈中,未必会清零。
那么编译器会自动生成constructor吗?不会!原因就是Foo的构造函数是程序需要的(程序需要bar的data members来判断),而不是编译器需要的。
编译器生成默认构造函数的情况有4种,如下,
1)一个class的成员中包含了另外一个class的object
class Foo
{
public:
Foo();
// ...
};
class Bar
{
public:
Foo foo;
char *str;
};像这样,编译器必须为Bar初始化一个default constructor,来为其member foo提供class Foo的构造调用,可能会有如下的形式:
/* compiler synthesized */
inline Bar::Bar() { foo.Foo::Foo(); }为什么会用内联的形式来定义呢?我们接着看,假如程序员也定义了一个Bar的构造函数,如下:
/* programmer synthesized */
Bar::Bar(){ str = 0; }“如果编译器含有一个以上的member class objects(类成员对象),那么它就必须调用每个default constructor”;所以编译器最终扩张生成的代码,可能会按照声明顺序(可能有多个其他类的对象成员),在用户的explicit user code之前加上自动生成的代码,以进行必要的初始化:
Bar::Bar()
{
foo.Foo::Foo(); // added compiler code
str = 0; // explicit user code
}从这里也可以看出,对于Bar::foo的初始化是编译器的责任(即编译器需要的),而对于Bar::str的初始化是程序员的责任,两者不会互相干预,编译器只管自己的那部分,不会对Bar::str做初始化。
2)一个class的父类有default constructor
编译器调用default constructor的顺序是:父类的constructor --> 对象成员的constructor(如果存在) --> 用户的constructor初始化代码;像上面 1)一样,如果程序员自己定义了constructor,那么编译器会在user code之前扩展其代码(调用其它constructor),而不是生成。
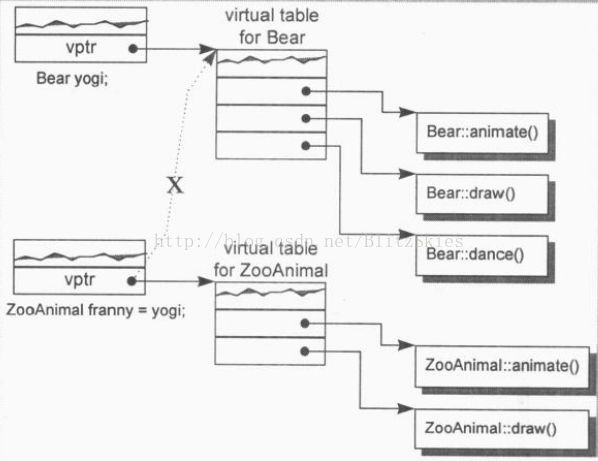
3)一个class中含有virtual function
看如下代码:
class Widge
{
public:
virtual void flip() = 0;
// ...
};
void flip(const Widge& widge) {widge.flip();}
// 假设Bell和Whistle都派生自Widge
void foo()
{
Bell b;
Whistle w;
flip(b);
flip(w);
}- 编译器产生一个virtual function table,来存放virtual functions的地址;
- 编译器为每一个object中产生一个pointer member(即vptr),指向virtual function table;
4)一个class有virtual base class(虚基类),即一个class以virtual方式继承父类
关于virtual base class,不同编译器之间的实现方式有很大差异,但它们有一个共同点:
- 在执行期时,每个子类对象的virtual base class必须能够使用。
class X { public: int i };
class A : public virtual X { public: int j; };
class B : public virtual X { public: double d; };
class C : public A, public B { public: int k; };
//无法再编译期间决定 pa-> X::i 的位置
void foo(const A* pa) { pa->i = 1024 }
main()
{
foo(new A);
foo(new B);
// ...
}对于初学者来说,虽然复制构造函数看似用处不多,但也是很重要的,我们常见到如下形式的复制构造函数:
/* user-defined copy constructor */
X::X( const X& x);
Y::Y( const Y& y, int = 0);- 一种是copy constructor(也是我们现在关注的);
- 另一种是copy assignment operator(我们会在以后讨论)。
class Word
{
public:
// ... no explicit copy constructor
private:
int cnt;
String str;
};- 一个class中含有member object,而member object的类声明中有copy constructor;
- 一个class继承自一个base class,并且基类中有copy constructor;
- 一个class中有virtual functions;
- 一个class含有一个多多个virtual base class;
X x0;
void foo_bar()
{
X x1(x0); // definition of x1
X x2 = x0; //definition of x2
X x3 = X(x0); //definition of x3
// ...
}- 重写定义,去除初始化操作,定义即内存分配的过程;
- 安插copy constructor代码,进行初始化。
void foo_bar()
{
// 1. 重写定义
X x1;
X x2;
X x3;
// 2. 安插copy constructor调用
x1.X::X(x0);
x2.X::X(x0);
x3.X::X(x0);
}X::X( const X& xx );b. 对象参数传递初始化
void foo(X x0);
X xx;
// ...
foo(xx);X __temp0;
__temp0.X::X(xx);
foo( __temp0 );void foo( X& x0 );X bar()
{
X xx;
// handle xx...
return xx;
}- 加上一个额外的参数,类型是object 的reference,用来取得返回的对象;
- return之前安插一个copy constructor的调用操作。
void bar( X& __result ) //1. 加上一个额外参数
{
X xx;
xx.X::X();
// handle xx ...
// 2. 安插一个copy constructor用于返回
__result.X::X( xx );
return;
}(5)Member Initialization List
class Word{
public:
int name;
int age;
int cnt;
public:
Word::Word()
:cnt(0), name(0)
{
age = 5;
}
};- initialization list的初始化是放在explicit code之前的(即age的顺序是放在最后的);
- initialization list中的顺序是按照class中member的声明顺序来的,与排列顺序无关(即先name后cnt);