Java IO流原理之常用字节流和字符流详解以及Buffered高效的原理
JavaIO流原理之常用字节流和字符流详解以及Buffered高效的原理
转载地址:http://www.cnblogs.com/ygj0930/p/5827509.html
Java的流体系十分庞大,我们来看看体系图:
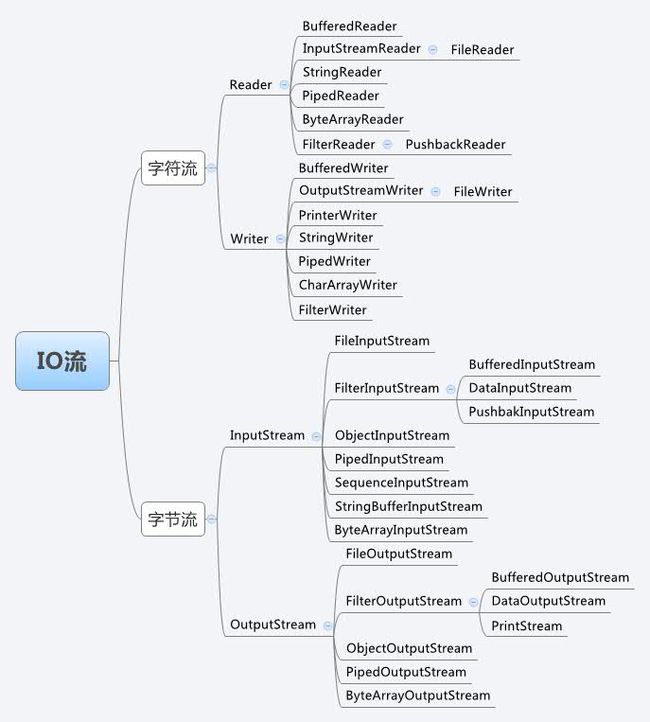
这么庞大的体系里面,常用的就那么几个,我们把它们抽取出来,如下图:

一:字节流
1:字节输入流
字节输入流的抽象基类是InputStream,常用的子类是 FileInputStream和BufferedInputStream。
1)FileInputStream
文件字节输入流:一切文件在系统中都是以字节的形式保存的,无论你是文档文件、视频文件、音频文件...,需要读取这些文件都可以用FileInputStream去读取其保存在存储介质(磁盘等)上的字节序列。
FileInputStream在创建时通过把文件名作为构造参数连接到该文件的字节内容,建立起字节流传输通道。
然后通过 read()、read(byte[])、read(byte[],int begin,int len) 三种方法从字节流中读取 一个字节、一组字节。
2)BufferedInputStream
带缓冲的字节输入流:上面我们知道文件字节输入流的读取时,是直接同字节流中读取的。由于字节流是与硬件(存储介质)进行的读取,所以速度较慢。而CPU需要使用数据时通过read()、read(byte[])读取数据时就要受到硬件IO的慢速度限制。我们又知道,CPU与内存发生的读写速度比硬件IO快10倍不止,所以优化读写的思路就有了:在内存中建立缓存区,先把存储介质中的字节读取到缓存区中。CPU需要数据时直接从缓冲区读就行了,缓冲区要足够大,在被读完后又触发fill()函数自动从存储介质的文件字节内容中读取字节存储到缓冲区数组。
BufferedInputStream 内部有一个缓冲区,默认大小为8M,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源 (譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容返回给用户.由于从缓冲区里读取数据远比直接从存储介质读取速度快,所以BufferedInputStream的效率很高。

public synchronized int read() throws IOException {
if (pos >= count) { // 检查是否有可读缓冲数据
fill(); // 没有缓冲数据可读,则从物理数据源读取数据并填充缓冲区
if (pos >= count) // 若物理数据源也没有多于可读数据,则返回-1,标示EOF
return -1;
}
// 从缓冲区读取buffer[pos]并返回(由于这里读取的是一个字节,而返回的是整型,所以需要把高位置0。如果是读取一组字节,则返回读取长度的字节数组)
return getBufIfOpen()[pos++] & 0xff;
}
2:字节输出流
字节输出流的抽象基类是OutputStream,其具体使用的子类是FileOutputStream和BufferedOutputStream。
1)FileOutputStream
文件字节输出流:作为文件字节输入流的逆过程,其实就是在创建时通过文件名创建输出流连接到要写入的文件处,然后通过 write(int)/write(byte[]) 方法把输出内容写到输出流中。
2)BufferedOutputStream
带缓冲的字节输出流:其优化输出速度的思路也是通过在内存中建立缓冲区,CPU直接把内容写到内存中的缓冲区,这样比较快。之后CPU继续干自己的事,后台并行地进行耗时慢速度的真正输出操作——把缓冲区的数据输出到输出流,写入文件的存储介质中。
在创建BufferedOutputStream时,通过一个outputStream参数(在创建outputStream时通过文件名建立起输出流)把已经建立的输出流包装成带缓冲的输出流,在内存中创建一个默认大小是8M的缓冲数组;
在程序运行过程中,通过write(int)/write(byte[])方法向缓冲数组写入数据,如果某时刻缓冲数组满了,则自动触发压入操作——把数组内容写到真正的输出流去,传输到文件中。
如果你想在某些write操作后确保内容能及时输出而不等到数组满时自动输出,则可以调用 flush() 方法强行刷新数组,把缓冲数组的内容全部写入输出流。
二:字符流
字符流是专门用来读写文档文件的高速输入输出流。
为何要有字符流:上面我们说到了文件字节流是可以读写一切文件的,包括文档文件,那为何还要多创造一个字符流呢?
首先我们要知道,文档文件在系统中的呈现原理:文件在系统中是以字节形式存在的,那么它在系统中如何表示成字符?因为它从系统中读取出来呈现时经过了系统的某种编码格式进行编码,从而显示成了字符。比如:我们知道的UTF-8或者汉语系统中的GBK编码形式,就可以把中文文档的字节序列读取出来解码成中文呈现。
然后我们需要知道:Java程序是运行在Java虚拟机上面的,Java虚拟机也是一个系统,但是它和文件直接保存的所在系统不一样,有可能双方对文档文件的字节序列的解码格式不一样。所以,如果直接读取字节序列,然后让Java虚拟机来解码呈现的话有可能因为编码格式不一致而导致乱码显示。要解决这个问题,就有了字符流。
字符流的原理:它可以在创建时,指定流的编码形式,使得读取到的字节序列根据其在系统中保存时采用的编码格式进行解码,然后把解析好的字符交给Java虚拟机使用,这样就避免了文件所在的系统与Java虚拟机解码不一致导致乱码。
1:字符输入流
字符输入流的抽象基类是Reader,其常用子类有 InputStreamReader和BufferedReader。
1)InputSreamReader
最基本的字符输入流。
在创建时,通过包装一个连接到文档文件的字节输入流,并指定编码格式(不指定则采用默认字符集)对字节输入流进行解码(底层是通过创建一个相应编码格式的流解码器StreamDecoder实现的,这里就不展开了)。
InputStreamReader(InputStream in)
创建一个使用默认字符集的 InputStreamReader。
InputStreamReader(InputStream in, Charset cs)
创建使用给定字符集的 InputStreamReader。
InputStreamReader(InputStream in, CharsetDecoder dec)
创建使用给定字符集解码器的 InputStreamReader。
InputStreamReader(InputStream in, String charsetName)
创建使用指定字符集的 InputStreamReader。
然后通过
int read()
读取单个字符。
int read(char[] cbuf, int offset, int length)
将字符读入数组中的某一部分。 方法读取字符:因为在读取过程中已经经过解码,所以获得的结果是字符char而不是字节byte。
2)BufferedReader
带缓冲的字符输入流:原理与BufferedInputStream一样,都是在内存中维护一个足够大的缓冲区。每次读时从缓冲区读取数据并解码,缓冲区空了则自动调用fill()填充缓冲区。
唯一区别在于:BufferedRead除了read()、read(char[])两个方法外,多了一个 readLine() 方法:读取一个文本行,通过下列字符之一认为某行已终止:换行 ('\n')、回车 ('\r') 或回车后直接跟着换行。
2:字符输出流
字符输出流的抽象基类是 Writer,其具体子类是OutputStreamWriter和BufferedWriter。
1)OutputStreamWriter
OutputStreamWriter不是简单地从FileOutputStream进行了编码包装,它是有缓冲的,但缓冲不是它自己实现的,而是依赖其组合的流编码类自带的。OutputStreamWriter源码分析如下:
public class OutputStreamWriter extends Writer {
// 流编码类,所有操作都交给它完成。
private final StreamEncoder se;
// 创建使用指定字符的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, String charsetName)
throws UnsupportedEncodingException
{
super(out);
if (charsetName == null)
throw new NullPointerException("charsetName");
se = StreamEncoder.forOutputStreamWriter(out, this, charsetName);
}
// 创建使用默认字符的OutputStreamWriter。
public OutputStreamWriter(OutputStream out) {
super(out);
try {
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
// 创建使用指定字符集的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, Charset cs) {
super(out);
if (cs == null)
throw new NullPointerException("charset");
se = StreamEncoder.forOutputStreamWriter(out, this, cs);
}
// 创建使用指定字符集编码器的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, CharsetEncoder enc) {
super(out);
if (enc == null)
throw new NullPointerException("charset encoder");
se = StreamEncoder.forOutputStreamWriter(out, this, enc);
}
// 返回该流使用的字符编码名。如果流已经关闭,则此方法可能返回 null。
public String getEncoding() {
return se.getEncoding();
}
// 刷新输出缓冲区到底层字节流,而不刷新字节流本身。该方法可以被PrintStream调用。
void flushBuffer() throws IOException {
se.flushBuffer();
}
// 写入单个字符
public void write(int c) throws IOException {
se.write(c);
}
// 写入字符数组的一部分
public void write(char cbuf[], int off, int len) throws IOException {
se.write(cbuf, off, len);
}
// 写入字符串的一部分
public void write(String str, int off, int len) throws IOException {
se.write(str, off, len);
}
// 刷新该流。可以发现,刷新缓冲区其实是通过流编码类的flush()实现的,故可以看出,缓冲区是流编码类自带的而不是OutputStreamWriter实现的。
public void flush() throws IOException {
se.flush();
}
// 关闭该流。
public void close() throws IOException {
se.close();
}
}
每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积(传递给 write() 方法的字符没有缓冲,输出数组才有缓冲)。为了获得最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中,以避免频繁调用转换器。
2)BufferedWriter
带缓冲的字符输出流:与OutputStreamWriter的缓冲不同,BufferedWriter的缓冲是真正由自己创建的缓冲数组来实现的。故此:不需要频繁调用编码转换器进行缓冲,而且,它可以提供单个字符、数组和字符串的缓冲(编码转换器只能缓冲字符数组和字符串)。
BufferedWriter可以在创建时把一个OutputStreamWriter进行包装,为输出流建立缓冲;
然后,通过
void write(char[] cbuf, int off, int len)
写入字符数组的某一部分。
void write(int c)
写入单个字符。
void write(String s, int off, int len)
写入字符串的某一部分。
向缓冲区写入数据。
还可以通过
void newLine()
写入一个行分隔符。
最后,可以手动控制缓冲区的数据刷新:
void flush() 刷新该流的缓冲。