2.agent追踪
所有的代码分析基于pinpoint 1.6.2
在上篇文章agent启动中最终分析到了织入部分,那么这里分析一下Trace部分。
一、入口
所有的trace的都从plugin进入,也就是说,如果对某个组件不支持的话,是不会进行trace的。
这里以jetty的plugin为例,当一个请求过来时,有类似如下拦截代码(后置拦截在后面):
//前置拦截
public void before(Object target, Object[] args) {
final Trace trace = createTrace(target, args);//创建trace
SpanEventRecorder recorder = trace.traceBlockBegin();//开始trace
recorder.recordServiceType(JettyConstants.JETTY_METHOD);//记录服务类型
}
下面先来看看前置拦截到底发生了什么,先看看createTrace代码:
final TraceId traceId = populateTraceIdFromRequest(request);//从请求中获取之前的trace
if (traceId != null) {
final Trace trace = traceContext.continueTraceObject(traceId);//用之前的traceId,创建新的span
return trace;
} else {
final Trace trace = traceContext.newTraceObject();//创建新的trace
return trace;
}
populateTraceIdFromRequest即如果header中存在Pinpoint-TraceID,Pinpoint-SpanID,Pinpoint-pSpanID等信息,则继续使用这些信息进行trace,否则认为时新的trace。
那么,traceContext.newTraceObject()是如何创建trace对象的。
二、创建trace对象
trace对象是由TraceContext创建的,TraceContext的实现为DefaultTraceContext,类图:
而具体的创建操作会委托给内部的TraceFactory:
![]()
1、TraceFactory
由于pinpoint配置相当灵活,一项配置往往有好多选项。
所以实际做事的TraceFactory会有好多不同的实现,如下:
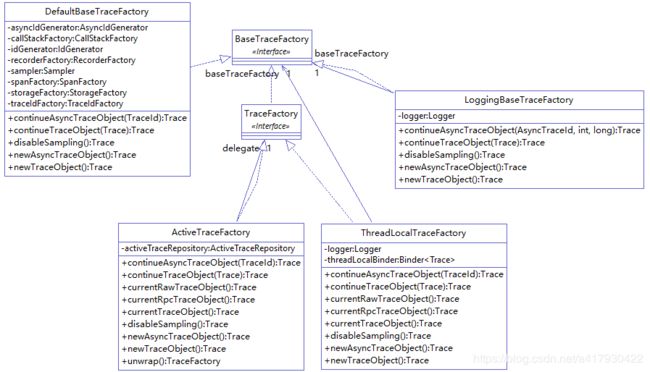
这里来介绍一下各个子factory的实现:
-
DefaultBaseTraceFactory
默认实现类,后边进行详细讲解。
-
LoggingBaseTraceFactory
用于trace日志调试,如果DefaultBaseTraceFactory的日志级别设置为debug,则自动启用该类。
该类只用于每步trace的日志记录。
-
ActiveTraceFactory
用于实时活跃线程统计,其实内部统计的是活跃trace对象,因为一次trace完成,trace对象会被移除,所以,活跃trace对象可以看作是活跃线程(用于dashboard实时线程图展示)。
-
ThreadLocalTraceFactory
用于将trace对象绑定到当前thread上,便于往下一级调用传递。
这些factory子类使用装饰者模式来进行一级一级封装,从而实现不同的需求,代码如下:
public TraceFactory get() {
BaseTraceFactory baseTraceFactory = new DefaultBaseTraceFactory(callStackFactory, storageFactory, sampler, traceIdFactory, idGenerator,
asyncIdGenerator, spanFactory, recorderFactory);
if (isDebugEnabled()) {//启用log相关
baseTraceFactory = LoggingBaseTraceFactory.wrap(baseTraceFactory);
}
TraceFactory traceFactory = new ThreadLocalTraceFactory(baseTraceFactory);
if (this.activeTraceRepository != null) {//启用实时线程统计相关
this.logger.debug("enable ActiveTrace");
traceFactory = ActiveTraceFactory.wrap(traceFactory, this.activeTraceRepository);
}
return traceFactory;
}
2、创建过程
下面来看一下DefaultBaseTraceFactory的trace创建代码:
public Trace newTraceObject() {
final boolean sampling = sampler.isSampling();//采样率校验
if (sampling) {
final Storage storage = storageFactory.createStorage();//创建存储对象
final TraceId traceId = traceIdFactory.newTraceId();//创建trace id
final long localTransactionId = traceId.getTransactionSequence();
final Trace trace = new DefaultTrace(callStackFactory, storage, traceId, localTransactionId, asyncIdGenerator, true, spanFactory, recorderFactory);//创建trace
return trace;
} else {
return newDisableTrace();
}
}
-
首先需要检测采样率,具体计算如下:
public boolean isSampling() { int samplingCount = MathUtils.fastAbs(counter.getAndIncrement()); int isSampling = samplingCount % samplingRate; return isSampling == 0; } -
创建Storage
-
创建TraceId
这个比较简单,只列出源码:
public TraceId newTraceId() { final long localTransactionId = idGenerator.nextTransactionId(); final TraceId traceId = new DefaultTraceId(agentId, agentStartTime, localTransactionId); return traceId; }其中:
- agentId就是启动时配置的
- agentStartTime即jvm启动时间
- localTransactionId是递增长整数
-
创建Trace
最后将这些对象组装为DefaultTrace对象。
简单的流程图如下:
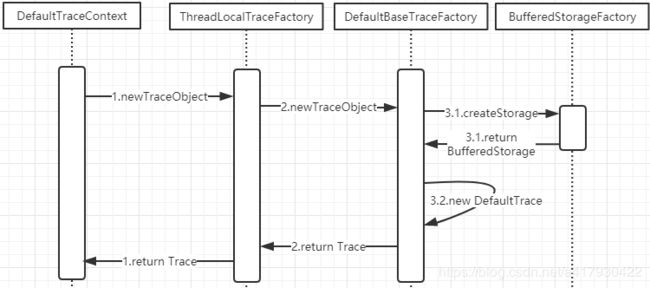
三、trace开启
接着jetty plugin的前置拦截中的代码trace.traceBlockBegin(),那么它做了什么?看下代码:
public SpanEventRecorder traceBlockBegin() {
return traceBlockBegin(-1);
}
public SpanEventRecorder traceBlockBegin(final int stackId) {
final SpanEvent spanEvent = new SpanEvent(span);//创建SpanEvent对象
spanEvent.markStartTime();//记录开始时间
spanEvent.setStackId(stackId);
callStack.push(spanEvent);//推送到栈中,并记录此时调用的深度
return wrappedSpanEventRecorder(spanEvent);
}
这里一步一步来介绍:
-
SpanEvent
SpanEvent持有span对象,除此之外,它还有一些额外的信息来记录:
- span启动消耗的时间
- span结束消耗的时间
- stackId
- 参数
- 异常
- 。。。
-
Span
其创建代码如下:
public Span newSpan() { final Span span = new Span(); span.setAgentId(agentId); span.setApplicationName(applicationName); span.setAgentStartTime(agentStartTime); span.setApplicationServiceType(applicationServiceType.getCode()); span.markBeforeTime(); return span; }其中,创建时间使用的是系统时间。
-
CallStack
CallStack即为调用栈,其内部持有SpanEvent的数组。数组默认配置的最大长度为
profiler.callstack.max.depth=64
四、trace结束
接着jetty中的后置拦截代码:
//后置拦截
public void after(Object target, Object[] args, Object result, Throwable throwable) {
final Trace trace = traceContext.currentRawTraceObject();//从当前线程获取到trace对象
try {
SpanEventRecorder recorder = trace.currentSpanEventRecorder();//获取当前SpanEventRecorder
final Request request = getRequest(args);
final String parameters = getRequestParameter(request, 64, 512);
if (parameters != null && parameters.length() > 0) {
recorder.recordAttribute(AnnotationKey.HTTP_PARAM, parameters);//记录http参数
}
recorder.recordApi(methodDescriptor);//记录方法描述
recorder.recordException(throwable);//记录异常
} catch (Throwable th) {
if (logger.isWarnEnabled()) {
logger.warn("after. Caused:{}", th.getMessage(), th);
}
} finally {
traceContext.removeTraceObject();//从各个子TraceFactory移除trace对象
trace.traceBlockEnd();
trace.close();
}
}
这里这要说一下trace.traceBlockEnd(),其对应的源码如下:
public void traceBlockEnd() {
traceBlockEnd(DEFAULT_STACKID);
}
public void traceBlockEnd(int stackId) {
final SpanEvent spanEvent = callStack.pop();//从spanEvent栈中弹出首元素
spanEvent.markAfterTime();//记录结束时间
storage.store(spanEvent);//持久化
}
由于在三、trace开启和四、trace结束中涉及到很对对象和结构,这里用类图描述一下他们的关系:
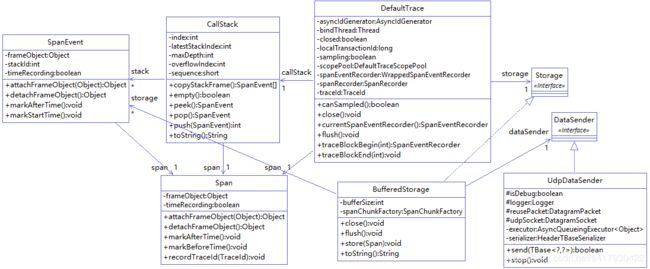
- DefaultTrace就是trace对象的默认实现
- CallStack用于记录SpanEvent的调用栈
- SpanEvent用于记录每次调用的参数,方法,耗时,深度等信息
- Span:一次远程调用
- BufferedStorage:默认20个SpanEvent发送一次
- UdpDataSender:udp协议数据发送,默认数据缓存最大队列为5120。
看完上面的类关系图,依然有些模糊,这里再用一个具体的例子来说明一下他们的组织关系。
span代表一次rpc调用,上面的类主要为了记录这一次span中,发生了哪些事件。
例如 假设有如下调用:
user -> jetty -> A(spring bean) -> B(spring bean)
-> C(spring bean)
pinpoint是怎么来处理的呢?

即线程按顺序调用到jetty,A,B,C,pinpoint会将其依次放入到CallStack中(执行trace.traceBlockBegin()),当方法执行完毕(调用trace.traceBlockEnd()),会从栈中弹出。
此时会产生几个SpanEvent,关于组织其调用关系属性有如下三个:
- spanId:标志这个SpanEvent归属于哪个span
- deepth:标志调用深度,即入栈时的当前数组下标
- sequence:标志调用顺序
而对于例子中的几个SpanEvent其值时什么呢?

根据深度和顺序号,就很容易能够梳理出调用树了。
需要注意一点,上述SpanEvent B和C为什么深度一样?因为B和C是串行的两个方法,B调用完毕,会出栈,C入栈,所以C和B的深度是一样的。
五、跨Span追踪####
上面介绍了单个span内的追踪,跨span的话很简单,pinpoint架构里说的很明白了,如下图:
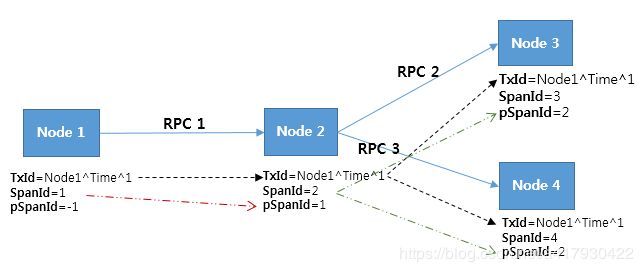
这里只是说明一下,以jetty代码为例:
private TraceId populateTraceIdFromRequest(Request request) {
String transactionId = request.getHeader(Header.HTTP_TRACE_ID.toString());
if (transactionId != null) {
long parentSpanID = NumberUtils.parseLong(request.getHeader(Header.HTTP_PARENT_SPAN_ID.toString()), SpanId.NULL);
long spanID = NumberUtils.parseLong(request.getHeader(Header.HTTP_SPAN_ID.toString()), SpanId.NULL);
short flags = NumberUtils.parseShort(request.getHeader(Header.HTTP_FLAGS.toString()), (short) 0);
final TraceId id = traceContext.createTraceId(transactionId, parentSpanID, spanID, flags);
return id;
} else {
return null;
}
}
即从http协议的header中获取transactionId,parentSpanID等关键信息,然后创建新的Trace。
当然不同的协议埋点不同,例如dubbo的代码:
String transactionId = invocation.getAttachment(DubboConstants.META_TRANSACTION_ID);
// If there's no trasanction id, a new trasaction begins here.
if (transactionId == null) {
return traceContext.newTraceObject();
}
// otherwise, continue tracing with given data.
long parentSpanID = NumberUtils.parseLong(invocation.getAttachment(DubboConstants.META_PARENT_SPAN_ID), SpanId.NULL);
long spanID = NumberUtils.parseLong(invocation.getAttachment(DubboConstants.META_SPAN_ID), SpanId.NULL);
到这里,整个agent跟踪的代码分析完毕