面试经-记汇丰保险部外包技术二面
前言
昨天进行了汇丰银行保险部外包的技术二面,这里我就简单的记录一下我不会的一些技术点(分分钟暴露自己的短处)。还有很多比较简单的问题的,我就不一一记录了,大家可以从其他面试经中看到。
正文
1.ORM是什么?
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
2.Hibernate与MyBatis的区别?
相同点
都是对jdbc的封装,都是持久层的框架,都用于dao层的开发。
不同点
映射关系
- MyBatis 是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单
- Hibernate 是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂
SQL优化和移植性
- Hibernate 对SQL语句封装,提供了日志、缓存、级联(级联比 MyBatis 强大)等特性,此外还提供 HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
- MyBatis 需要手动编写 SQL,支持动态SQL、处理列表、动态生成表名、支持存储过程。开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优化容易。
开发难易程度和学习成本
- Hibernate 是重量级框架,学习使用门槛高,适合于需求相对稳定,中小型的项目,比如:办公自动化系统
- MyBatis 是轻量级框架,学习使用门槛低,适合于需求变化频繁,大型的项目,比如:互联网电子商务系统
总结
- MyBatis 是一个小巧、方便、高效、简单、直接、半自动化的持久层框架,
- Hibernate 是一个强大、方便、高效、复杂、间接、全自动化的持久层框架。
3.什么是对象拷贝?什么是浅拷贝,什么是深拷贝?
基本类型拷贝:
克隆是针对于对象而言的,基本类型(boolean,char,byte,short,float,double.long)已久具备自身克隆的特性.如:
int x=1;
int y=x;
System.out.println(x);//1
System.out.println(y);//1
y=2;
System.out.println(x);//1
System.out.println(y);//2
JVM实现拷贝的目的:
大家先思考一个问题,为什么需要克隆对象?直接 new 一个对象不行吗?
答案是:克隆的对象可能包含一些已经修改过的属性,而 new 出来的对象的属性都还是初始化时候的值,所以当需要一个新的对象来保存当前对象的 “状态” 就靠 clone 方法了。
那么我把这个对象的临时属性一个一个的赋值给我新 new 的对象不也行嘛?
可以是可以,但是一来麻烦不说,二来,大家通过上面的源码都发现了 clone 是一个 native 方法,就是快啊,在底层实现的。
浅拷贝
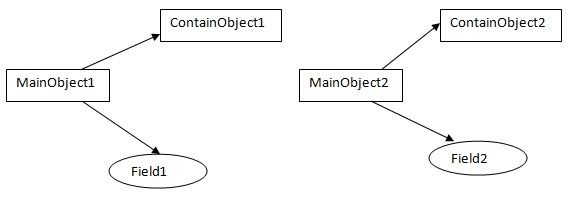
对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
简单点说,就是对象中的基本数据类型(boolean,char,byte,short,float,double.long)进行值传递的,其余的是将字段指向同一个内存地址,从而达到值一样。
如图为引用数据类型的拷贝:

深拷贝
对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
简单的说,引用类型的深拷贝是会先创建一个新的对象,再进行拷贝的。
所以区别在于是否有新对象创建。
4.是否了解MQ?使用过什么MQ?使用场景是什么?
MQ(消息队列)
消息队列就是基础数据结构中的“先进先出”的一种数据机构。想一下,生活中买东西,需要排队,先排的人先买消费,就是典型的“先进先出”。
使用过什么MQ
这个首先你可以说下你们公司选用的是什么消息中间件,比如用的是RabbitMQ,然后可以初步给一些你对不同MQ中间件技术的选型分析。
举个例子:比如说ActiveMQ是老牌的消息中间件,国内很多公司过去运用的还是非常广泛的,功能很强大。
但是问题在于没法确认ActiveMQ可以支撑互联网公司的高并发、高负载以及高吞吐的复杂场景,在国内互联网公司落地较少。而且使用较多的是一些传统企业,用ActiveMQ做异步调用和系统解耦。
然后你可以说说RabbitMQ,他的好处在于可以支撑高并发、高吞吐、性能很高,同时有非常完善便捷的后台管理界面可以使用。
另外,他还支持集群化、高可用部署架构、消息高可靠支持,功能较为完善。
而且经过调研,国内各大互联网公司落地大规模RabbitMQ集群支撑自身业务的case较多,国内各种中小型互联网公司使用RabbitMQ的实践也比较多。
除此之外,RabbitMQ的开源社区很活跃,较高频率的迭代版本,来修复发现的bug以及进行各种优化,因此综合考虑过后,公司采取了RabbitMQ。
但是RabbitMQ也有一点缺陷,就是他自身是基于erlang语言开发的,所以导致较为难以分析里面的源码,也较难进行深层次的源码定制和改造,毕竟需要较为扎实的erlang语言功底才可以。
然后可以聊聊RocketMQ,是阿里开源的,经过阿里的生产环境的超高并发、高吞吐的考验,性能卓越,同时还支持分布式事务等特殊场景。
而且RocketMQ是基于Java语言开发的,适合深入阅读源码,有需要可以站在源码层面解决线上生产问题,包括源码的二次开发和改造。
另外就是Kafka。Kafka提供的消息中间件的功能明显较少一些,相对上述几款MQ中间件要少很多。
但是Kafka的优势在于专为超高吞吐量的实时日志采集、实时数据同步、实时数据计算等场景来设计。
因此Kafka在大数据领域中配合实时计算技术(比如Spark Streaming、Storm、Flink)使用的较多。但是在传统的MQ中间件使用场景中较少采用。
RabbitMQ的使用场景
(1)服务间异步通信
(2)顺序消费
(3)定时任务
(4)请求削峰
具体详解请参考:MQ(消息队列)功能介绍