转载来源:https://www.jianshu.com/p/c869feb5581d
Redis集群的原理和搭建
前言
Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用。单节点的Redis已经就达到了很高的性能,为了提高可用性我们可以使用Redis集群。本文参考了Rdis的官方文档和使用Redis官方提供的Redis Cluster工具搭建Rdis集群。
注意 :Redis的版本要在3.0以上,截止今天,Redis的版本是3.2.9,本教程也使用3.2.9作为教程
Redis集群的概念
介绍
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施(installation)。
Redis 集群不支持那些需要同时处理多个键的 Redis 命令, 因为执行这些命令需要在多个 Redis 节点之间移动数据, 并且在高负载的情况下, 这些命令将降低 Redis 集群的性能, 并导致不可预测的错误。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis 集群提供了以下两个好处:
- 将数据自动切分(split)到多个节点的能力。
- 当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力。
数据分片
Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分哈希槽。 举个例子, 一个集群可以有三个哈希槽, 其中:
- 节点 A 负责处理 0 号至 5500 号哈希槽。
- 节点 B 负责处理 5501 号至 11000 号哈希槽。
- 节点 C 负责处理 11001 号至 16384 号哈希槽。
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
我现在想设置一个key,叫my_name:
set my_name zhangguoji
按照Redis Cluster的哈希槽算法,CRC16('my_name')%16384 = 2412 那么这个key就被分配到了节点A上
同样的,当我连接(A,B,C)的任意一个节点想获取my_name这个key,都会转到节点A上
再比如
如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
增加一个D节点的结果可能如下:
- 节点A覆盖1365-5460
- 节点B覆盖6827-10922
- 节点C覆盖12288-16383
- 节点D覆盖0-1364,5461-6826,10923-1228
与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
所以,Redis Cluster的模型大概是这样的形状
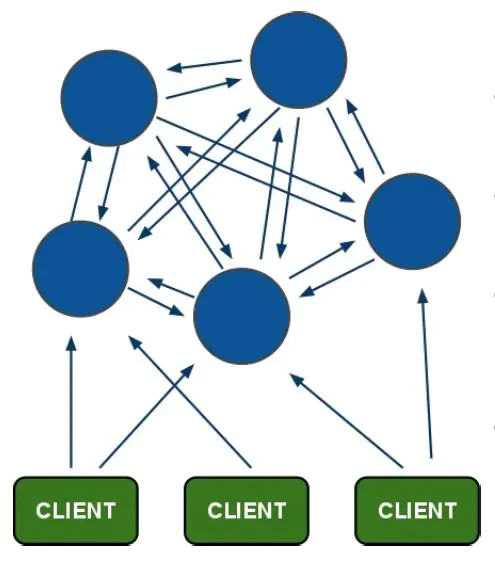
主从复制模型
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
在之前列举的节点 A 、B 、C 的例子中, 如果节点 B 下线了, 那么集群将无法正常运行, 因为集群找不到节点来处理 5501 号至 11000号的哈希槽。
另一方面, 假如在创建集群的时候(或者至少在节点 B 下线之前), 我们为主节点 B 添加了从节点 B1 , 那么当主节点 B 下线的时候, 集群就会将 B1 设置为新的主节点, 并让它代替下线的主节点 B , 继续处理 5501 号至 11000 号的哈希槽, 这样集群就不会因为主节点 B 的下线而无法正常运作了。
不过如果节点 B 和 B1 都下线的话, Redis 集群还是会停止运作。
Redis一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作:
第一个原因是因为集群是用了异步复制. 写操作过程:
- 客户端向主节点B写入一条命令.
- 主节点B向客户端回复命令状态.
- 主节点将写操作复制给他得从节点 B1, B2 和 B3
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项
搭建Redis集群
要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下(为了简单演示都在同一台机器上面)
127.0.0.1:7000
127.0.0.1:7001
127.0.0.1:7002
127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 安装和启动Redis
下载安装包
wget http://download.redis.io/releases/redis-3.2.9.tar.gz
解压安装
tar zxvf redis-3.2.9.tar.gz
cd redis-3.2.9
make && make PREFIX=/usr/local/redis install
这里如果失败的自行yum安装gcc和tcl
yum install gcc
yum install tcl
创建目录
cd /usr/local/redis
mkdir cluster
cd cluster
mkdir 7000 7001 7002 7003 7004 7005
复制和修改配置文件
将redis目录下的配置文件复制到对应端口文件夹下,6个文件夹都要复制一份
cp redis-3.2.9/redis.conf /usr/local/redis/cluster/7000
修改配置文件redis.conf,将下面的选项修改
# 端口号
port 7000
# 后台启动
daemonize yes
# 开启集群 cluster-enabled yes #集群节点配置文件 cluster-config-file nodes-7000.conf # 集群连接超时时间 cluster-node-timeout 5000 # 进程pid的文件位置 pidfile /var/run/redis-7000.pid # 开启aof appendonly yes # aof文件路径 appendfilename "appendonly-7005.aof" # rdb文件路径 dbfilename dump-7000.rdb 6个配置文件安装对应的端口分别修改配置文件
创建启动脚本
在/usr/local/redis目录下创建一个start.sh
#!/bin/bash
bin/redis-server cluster/7000/redis.conf
bin/redis-server cluster/7001/redis.conf
bin/redis-server cluster/7002/redis.conf
bin/redis-server cluster/7003/redis.conf
bin/redis-server cluster/7004/redis.conf
bin/redis-server cluster/7005/redis.conf
这个时候我们查看一下进程看启动情况
ps -ef | grep redis
进程状态如下:
root 1731 1 1 18:21 ? 00:00:49 bin/redis-server *:7000 [cluster]
root 1733 1 0 18:21 ? 00:00:29 bin/redis-server *:7001 [cluster]
root 1735 1 0 18:21 ? 00:00:08 bin/redis-server *:7002 [cluster]
root 1743 1 0 18:21 ? 00:00:26 bin/redis-server *:7003 [cluster]
root 1745 1 0 18:21 ? 00:00:13 bin/redis-server *:7004 [cluster]
root 1749 1 0 18:21 ? 00:00:08 bin/redis-server *:7005 [cluster]
有6个redis进程在开启,说明我们的redis就启动成功了
开启集群
这里我们只是开启了6个redis进程而已,它们都还只是独立的状态,还么有组成集群
这里我们使用官方提供的工具redis-trib,不过这个工具是用ruby写的,要先安装ruby的环境
yum install ruby rubygems -y
执行,报错
[root@centos]# redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': no such file to load -- redis (LoadError)
from /usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `require'
from /usr/local/bin/redis-trib.rb:25
[root@centos]#
原来是ruby和redis的连接没安装好
安装gem-redis
gem install redis
安装到这里的时候突然卡住很久不动,网上搜了下,这里需要或者换镜像
gem source -a https://gems.ruby-china.org
这里可以将镜像换成ruby-china的镜像,不过我好像更换失败,最终还是下载了
[root@centos]# gem install redis
Successfully installed redis-3.2.1
1 gem installed
Installing ri documentation for redis-3.2.1...
Installing RDoc documentation for redis-3.2.1...
等下载好后我们就可以使用了
[root@centos]# gem install redis
Successfully installed redis-3.2.1
1 gem installed
Installing ri documentation for redis-3.2.1...
Installing RDoc documentation for redis-3.2.1...
将redis-3.2.9的src目录下的trib复制到相应文件夹
cp redis-3.2.9/src/redis-trib.rb /usr/local/redis/bin/redis-trib
创建集群:
redis-trib create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 命令的意义如下:
- 给定 redis-trib.rb 程序的命令是 create , 这表示我们希望创建一个新的集群。
- 选项 --replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
之后跟着的其他参数则是实例的地址列表, 我们希望程序使用这些地址所指示的实例来创建新集群。
简单来说,以上的命令的意思就是让redis-trib程序帮我们创建三个主节点和三个从节点的集群
接着, redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中:
>>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 Adding replica 127.0.0.1:7003 to 127.0.0.1:7000 Adding replica 127.0.0.1:7004 to 127.0.0.1:7001 Adding replica 127.0.0.1:7005 to 127.0.0.1:7002 M: bdcddddd3d78a866b44b68c7ae0e5ccf875c446a 127.0.0.1:7000 slots:0-5460 (5461 slots) master M: b85519795fa42aa33d4e88d25104cbae895933a6 127.0.0.1:7001 slots:5461-10922 (5462 slots) master M: b681e1a151890cbf957d1ff08352ee48f6ae39e6 127.0.0.1:7002 slots:10923-16383 (5461 slots) master S: d403713ab9db48aeac5b5393b69e1201026ef479 127.0.0.1:7003 replicates bdcddddd3d78a866b44b68c7ae0e5ccf875c446a S: b7ec92919e5bcffa76c8eee338f8ca5155293c64 127.0.0.1:7004 replicates b85519795fa42aa33d4e88d25104cbae895933a6 S: 8a0d2a3f271b349744a971e1b0a545405de2742e 127.0.0.1:7005 replicates b681e1a151890cbf957d1ff08352ee48f6ae39e6 Can I set the above configuration? (type 'yes' to accept): 按下yes,集群就会将配置应用到各个节点,并连接起(join)各个节点,也即是,让各个节点开始通讯
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join...
>>> Performing Cluster Check (using node 127.0.0.1:7000)
M: bdcddddd3d78a866b44b68c7ae0e5ccf875c446a 127.0.0.1:7000 slots:0-5460 (5461 slots) master 1 additional replica(s) S: d403713ab9db48aeac5b5393b69e1201026ef479 127.0.0.1:7003 slots: (0 slots) slave replicates bdcddddd3d78a866b44b68c7ae0e5ccf875c446a S: 8a0d2a3f271b349744a971e1b0a545405de2742e 127.0.0.1:7005 slots: (0 slots) slave replicates b681e1a151890cbf957d1ff08352ee48f6ae39e6 M: b85519795fa42aa33d4e88d25104cbae895933a6 127.0.0.1:7001 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: b7ec92919e5bcffa76c8eee338f8ca5155293c64 127.0.0.1:7004 slots: (0 slots) slave replicates b85519795fa42aa33d4e88d25104cbae895933a6 M: b681e1a151890cbf957d1ff08352ee48f6ae39e6 127.0.0.1:7002 slots:10923-16383 (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. Redis集群的使用
连接集群
这里我们使用reids-cli连接集群,使用时加上-c参数,就可以连接到集群
连接7000端口的节点
[root@centos1 redis]# ./redis-cli -c -p 7000 127.0.0.1:7000> set name zgj -> Redirected to slot [5798] located at 127.0.0.1:7001 OK 127.0.0.1:7001> get name "zgj" 前面的理论知识我们知道了,分配key的时候,它会使用CRC16算法,这里将keyname分配到了7001节点上
Redirected to slot [5798] located at 127.0.0.1:7001
redis cluster 采用的方式很直接,它直接跳转到7001 节点了,而不是还在自身的7000节点。
好,现在我们连接7003这个从节点进入
[root@centos1 redis]# ./redis-cli -c -p 7003 127.0.0.1:7003> get name -> Redirected to slot [5798] located at 127.0.0.1:7001 "zgj" 这里获取name的值,也同样跳转到了7001上
我们再测试一下其他数据
127.0.0.1:7001> set age 20
-> Redirected to slot [741] located at 127.0.0.1:7000
OK
127.0.0.1:7000> set message helloworld
-> Redirected to slot [11537] located at 127.0.0.1:7002 OK 127.0.0.1:7002> set height 175 -> Redirected to slot [8223] located at 127.0.0.1:7001 OK 我们发现数据会在7000-7002这3个节点之间来回跳转
测试集群中的节点挂掉
上面我们建立了一个集群,3个主节点和3个从节点,7000-7002负责存取数据,7003-7005负责把7000-7005的数据同步到自己的节点上来。
我们现在来模拟一下一台matser服务器宕机的情况
[root@centos1 redis]# ps -ef | grep redis root 1731 1 0 18:21 ? 00:01:02 bin/redis-server *:7000 [cluster] root 1733 1 0 18:21 ? 00:00:43 bin/redis-server *:7001 [cluster] root 1735 1 0 18:21 ? 00:00:22 bin/redis-server *:7002 [cluster] root 1743 1 0 18:21 ? 00:00:40 bin/redis-server *:7003 [cluster] root 1745 1 0 18:21 ? 00:00:27 bin/redis-server *:7004 [cluster] root 1749 1 0 18:21 ? 00:00:22 bin/redis-server *:7005 [cluster] root 23988 1 0 18:30 ? 00:00:42 ./redis-server *:6379 root 24491 1635 0 21:55 pts/1 00:00:00 grep redis [root@centos1 redis]# kill 1731 [root@centos1 redis]# bin/redis-trib check 127.0.0.1:7001 >>> Performing Cluster Check (using node 127.0.0.1:7001) M: b85519795fa42aa33d4e88d25104cbae895933a6 127.0.0.1:7001 slots:5461-10922 (5462 slots) master 1 additional replica(s) M: b681e1a151890cbf957d1ff08352ee48f6ae39e6 127.0.0.1:7002 slots:10923-16383 (5461 slots) master 1 additional replica(s) S: b7ec92919e5bcffa76c8eee338f8ca5155293c64 127.0.0.1:7004 slots: (0 slots) slave replicates b85519795fa42aa33d4e88d25104cbae895933a6 S: 8a0d2a3f271b349744a971e1b0a545405de2742e 127.0.0.1:7005 slots: (0 slots) slave replicates b681e1a151890cbf957d1ff08352ee48f6ae39e6 M: d403713ab9db48aeac5b5393b69e1201026ef479 127.0.0.1:7003 slots:0-5460 (5461 slots) master