机器学习之支持向量机(SVM)
上篇博文《机器学习之Rademacher复杂度和VC维》讲述了衡量假设集复杂程度即假设集拟合随机噪声的丰富性的方法,从这一篇博文开始讲述机器学习领域的一个重要算法——支持向量机(SVM)。
支持向量机是一种二分类模型,基本思路是求出特征空间中最大间隔的划分两个样本的超平面。这使得其区别于感知机。也就是支持向量机的核心学习策略就是间隔最大化,其形式上也可以转化为求凸二次规划问题,支持向量机的本质就是求解凸二次规划的优化算法问题。
博文重点:
- 介绍线性可分数据集的分类算法。
- 介绍线性不可分的数据集的分类算法。
- 提出基于间隔(margin)概念的支持向量机的理论基础。
1、线性分类(Linear classification)
考虑一个 N N N维输入空间 X ∈ R N , N ≥ 1 \mathcal{X}\in{\mathbb{R}^N},N \ge{1} X∈RN,N≥1。输出空间 Y = { − 1 , + 1 } \mathcal{Y}=\{-1,+1\} Y={−1,+1},并且 f : X → Y f:\mathcal{X}\to\mathcal{Y} f:X→Y是目标函数。假设集 H H H是二分类 X \mathcal{X} X到 Y \mathcal{Y} Y的映射。训练样本 S = ( ( x 1 , y 1 ) , . . . , ( x m , y m ) ) ∈ ( X × Y ) m S=((x_1,y_1),...,(x_m,y_m))\in(\mathcal{X}\times\mathcal{Y})^m S=((x1,y1),...,(xm,ym))∈(X×Y)m并且 y i = f ( x i ) y_i=f(x_i) yi=f(xi)对任意的 i ∈ [ m ] i\in[m] i∈[m]来自于某个未知分布 D D D。假设集 h ∈ H h\in{H} h∈H的泛化误差为:
R D ( h ) = P x ∼ D [ h ( x ) ≠ f ( x ) ] . R_D(h)=\mathop\mathbb{P}\limits_{x\sim{D}}[h(x)\ne{f(x)}]. RD(h)=x∼DP[h(x)=f(x)].
根据之前的研究,假设集具有更小的 V C VC VC维或Rademacher复杂度将提供更好学习保证,这也符合奥卡姆剃刀原则。那么线性分类器(超平面)自然具有较小的复杂度,定义如下:
H = { x → sgn ( w ⋅ x + b ) : w ∈ R N , b ∈ R } . \mathcal{H}=\{\mathbf{x}\to{\text{sgn}(\mathbf{w}\cdot\mathbf{x}+b)}:\mathbf{w}\in{\mathbb{R}^N},b\in{\mathbb{R}}\}. H={x→sgn(w⋅x+b):w∈RN,b∈R}.
超平面在 R N \mathbb{R}^N RN的一般方程为: w ⋅ x + b = 0 \mathbf{w}\cdot\mathbf{x}+b=0 w⋅x+b=0,并且 w ∈ R N \mathbf{w}\in{\mathbb{R}^N} w∈RN是超平面的非零向量, b ∈ R b\in\mathbb{R} b∈R是一个标量。因此,分离超平面可将特征空间划分为两部分,所有落在超平面一边的点标记为正,落在另一面的标记为负,也就是法向量所指向的一侧为正类,另一侧为负类。
2、可分的情况(Separable case)
这一部分先假定样本集 S S S均是线性可分的,所以我们假定存在一个超平面能够完美地将样本划分为正负两类,如下图所示:
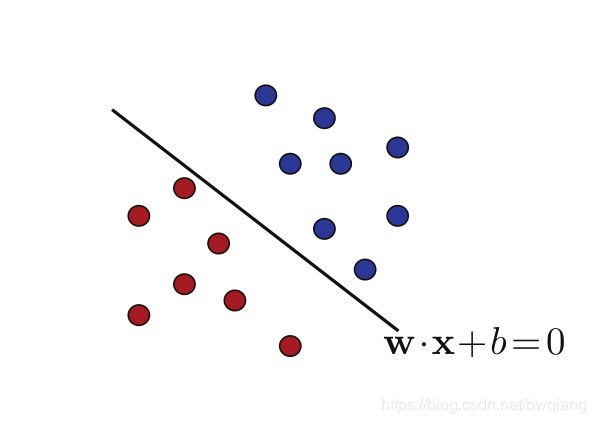
也就是等价于存在着 ( w , b ) ∈ ( R N − { 0 } ) × R (\mathbf{w},b)\in{(\mathbb{R}^N-\{0\})\times{\mathbb{R}}} (w,b)∈(RN−{0})×R满足:
∀ i ∈ [ m ] , y i ( w ⋅ x i + b ) ≥ 0. \forall{i}\in{[m]},y_i(\mathbf{w}\cdot{\mathbf{x}_i}+b)\ge0. ∀i∈[m],yi(w⋅xi+b)≥0.
但是从上幅图我们可以看到,存在着无数个超平面可以将两类样本区分开来。感知机利用误分类最小的策略求得分类超平面,其解也是无穷多个,而线性可分支持向量机利用间隔最大化求最优分离超平面的解是唯一的。
求解SVM的解的方法是以几何间隔概念为基础的。
定义1:几何间隔:线性分类器的几何间隔就是一个点 x \mathbf{x} x到超平面 w ⋅ x + b = 0 \mathbf{w}\cdot{\mathbf{x}}+b=0 w⋅x+b=0的欧氏距离:
ρ h ( x ) = ∣ w ⋅ x + b ∣ ∣ ∣ w ∣ ∣ 2 . \rho_h(x)=\frac{|\mathbf{w}\cdot{\mathbf{x}}+b|}{||\mathbf{w}||_2}. ρh(x)=∣∣w∣∣2∣w⋅x+b∣.
对于线性分类器 h h h的几何间隔 ρ h \rho_h ρh就是所有样本点 S = ( x 1 , . . . , x m ) S=(\mathbf{x_1},...,\mathbf{x_m}) S=(x1,...,xm)中到超平面的最小距离:
ρ h = min i ∈ [ m ] ρ h ( x i ) \rho_h=\min_{i\in[m]}\rho_h(x_i) ρh=i∈[m]minρh(xi),也就是离超平面最近的点。
SVM的解就是寻找最大间隔分离超平面,由于 ρ \rho ρ是能够保证最大间隔地划分两类样本,所以此时的 ρ \rho ρ可以说是最有保障的分离超平面,如下图所示。

2.1 原始优化问题(Primal optimization problem)
通过定义几何间隔,一个分离超平面的最大间隔 ρ \rho ρ如下所示:
ρ = max w , b : y i ( w i ⋅ x + b ) ≥ 0 min i ∈ [ m ] ∣ w ⋅ x i + b ∣ ∣ ∣ w ∣ ∣ = max w , b min i ∈ [ m ] y i ( w ⋅ x i + b ) ∣ ∣ w ∣ ∣ . \begin{aligned} \rho & = \max_{\mathbf{w},b:y_i(\mathbf{w_i}\cdot\mathbf{x}+b)\ge0}\min_{i\in{[m]}}\frac{|\mathbf{w}\cdot{\mathbf{x_i}+b}|}{||\mathbf{w}||} \\ &=\max_{\mathbf{w},b} \min_{i\in{[m]}}\frac{y_i(\mathbf{w}\cdot{\mathbf{x_i}}+b)}{||\mathbf{w}||}. \end{aligned} ρ=w,b:yi(wi⋅x+b)≥0maxi∈[m]min∣∣w∣∣∣w⋅xi+b∣=w,bmaxi∈[m]min∣∣w∣∣yi(w⋅xi+b).
上述公式的含义就是最大化几何间隔,也就是以一个充分大的确信度对数据集进行分类,不仅将正负类分开,对于某些难以区分的示例点也具有足够大的能力将其分开。那么则有 y i ( w ⋅ x i + b ) ≥ 0 y_i(\mathbf{w}\cdot{\mathbf{x_i}}+b)\ge{0} yi(w⋅xi+b)≥0恒成立,我们可以假定 min i ∈ [ m ] y i ( w ⋅ x i + b ) = 1 \min_{i\in{[m]}}y_i(\mathbf{w}\cdot{\mathbf{x_i}}+b)=1 mini∈[m]yi(w⋅xi+b)=1:
ρ = max w , b : min i ∈ [ m ] y i ( w ⋅ x i + b ) = 1 1 ∣ ∣ w ∣ ∣ = max w , b : ∀ i ∈ [ m ] , y i ( w i ⋅ x + b ) ≥ 1 1 ∣ ∣ w ∣ ∣ . \rho=\max_{\mathbf{w},b:\min_{i\in{[m]}}y_i(\mathbf{w}\cdot{\mathbf{x_i}}+b)=1}\frac{1}{||\mathbf{w}||}=\max_{\mathbf{w},b:\forall{i}\in{[m]},y_i(\mathbf{w_i}\cdot{\mathbf{x}}+b)\ge1}\frac{1}{||\mathbf{w}||}. ρ=w,b:mini∈[m]yi(w⋅xi+b)=1max∣∣w∣∣1=w,b:∀i∈[m],yi(wi⋅x+b)≥1max∣∣w∣∣1.
下图,间隔超平面与分离超平面平行,并且通过最近的正负样本,间隔超平面的方程是 w ⋅ x + b = ± 1 \mathbf{w}\cdot{\mathbf{x}}+b=\pm1 w⋅x+b=±1。
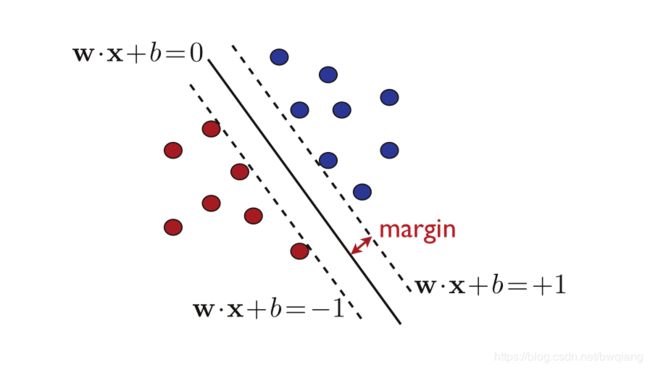
由于最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||\mathbf{w}||} ∣∣w∣∣1等价于最小化 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||\mathbf{w}||^2 21∣∣w∣∣2,则求解SVM线性可分超平面的解的方法转变为如下的凸优化问题:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 subject to : y i ( w ⋅ x + b ) ≥ 1 , ∀ i ∈ [ m ] \min_{\mathbf{w},b}\frac{1}{2}||\mathbf{w}||^2 \\ \text{subject to}: y_i(\mathbf{w}\cdot{\mathbf{x}}+b)\ge1,\forall{i}\in{[m]} w,bmin21∣∣w∣∣2subject to:yi(w⋅x+b)≥1,∀i∈[m]
目标函数 F : w → 1 2 ∣ ∣ w ∣ ∣ 2 F:\mathbf{w}\rightarrow{\frac{1}{2}}||\mathbf{w}||^2 F:w→21∣∣w∣∣2是光滑并可微的。它的梯度 ∇ F ( w ) = w \nabla{F(\mathbf{w})}=\mathbf{w} ∇F(w)=w,海森(Hessian)矩阵 ∇ 2 F ( w ) = I \nabla^2F(\mathbf{w})=\mathbf{I} ∇2F(w)=I,并且矩阵的特征值严格为正,因此目标函数是严格凸函数。限制函数 g i : ( w , b ) → 1 − y i ( w ⋅ x + b ) g_i:(\mathbf{w},b)\rightarrow1-y_i(\mathbf{w}\cdot{\mathbf{x}}+b) gi:(w,b)→1−yi(w⋅x+b)是仿射函数。上述凸优化问题成为凸二次规划问题(convex QP problems),上述问题便会有唯一解。
2.2 支持向量(Support vectors)
为了求解线性可分支持向量机的最优化问题,可将原始问题(primal problems)应用拉格朗日对偶性转化为对偶问题(dual problems)。对偶问题往往更加方便求解并且方便引入核函数,推广到非线性分类问题(下篇文章讲述)。
引入拉格朗日变量 α i ≥ 0 , i ∈ [ m ] \alpha_i\ge0,i\in{[m]} αi≥0,i∈[m],将 α \alpha α表示为向量的形式为: α = ( α 1 , . . . , α m ) T \mathbf{\alpha}=(\alpha_1,...,\alpha_m)^T α=(α1,...,αm)T,因此,对于所有的 w ∈ R N , b ∈ R , α ∈ R + N \mathbf{w}\in{\mathbb{R}^N},b\in{\mathbb{R}},\alpha\in{\mathbb{R}_+^N} w∈RN,b∈R,α∈R+N,
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 m α i [ y i ( w ⋅ x i + b ) − 1 ] . \mathcal{L}(\mathbf{w},b,\mathbf{\alpha})=\frac{1}{2}||\mathbf{w}||^2-\sum_{i=1}^m\alpha_i[y_i(\mathbf{w}\cdot{\mathbf{x}_i}+b)-1]. L(w,b,α)=21∣∣w∣∣2−i=1∑mαi[yi(w⋅xi+b)−1].
根据拉格朗日的对偶性,原始问题的对偶问题是极大极小问题:
max α min w , b L ( w , b , α ) \max_{\alpha}\min_{\mathbf{w},b}\mathcal{L}(\mathbf{w},b,\alpha) αmaxw,bminL(w,b,α)
所以,为了得到对偶问题的解,需要先求出 L ( w , b , α ) \mathcal{L}(\mathbf{w},b,\alpha) L(w,b,α)对 w , b \mathbf{w},b w,b的极小,再求出对 α \alpha α的极大。
(1)求 min w , b L ( w , b , α ) \min_{\mathbf{w},b}\mathcal{L}(\mathbf{w},b,\alpha) minw,bL(w,b,α):得到KKT条件就是将原始问题中的 w , b \mathbf{w},b w,b的梯度设置为 0 0 0,并再加上一条补充条件,如下所示:
∇ w L = w − ∑ i = 1 m α i y i x i ⇒ w = ∑ i = 1 m α i y i x i ∇ b L = − ∑ i = 1 m α i y i = 0 ⇒ ∑ i = 1 m α i y i = 0 ∀ i , α i [ y i ( w ⋅ x i + b ) − 1 ] = 0 ⇒ α i = 0 or y i ( w ⋅ x i + b ) = 1 \begin{array}{lcl} \nabla_{\mathbf{w}}\mathcal{L}=\mathbf{w}-\sum_{i=1}^m\alpha_iy_i\mathbf{x}_i&\Rightarrow&\mathbf{w}=\sum_{i=1}^m\alpha_iy_i\mathbf{x}_i\\\\ \nabla_{b}\mathcal{L}=-\sum_{i=1}^m\alpha_iy_i=0&\Rightarrow&\sum_{i=1}^m\alpha_iy_i=0\\\\ \forall{i},\alpha_i[y_i(\mathbf{w}\cdot{\mathbf{x_i}}+b)-1]=0&\Rightarrow&\alpha_i=0 \;\text{or}\;y_i(\mathbf{w}\cdot{\mathbf{x}_i}+b)=1 \end{array} ∇wL=w−∑i=1mαiyixi∇bL=−∑i=1mαiyi=0∀i,αi[yi(w⋅xi+b)−1]=0⇒⇒⇒w=∑i=1mαiyixi∑i=1mαiyi=0αi=0oryi(w⋅xi+b)=1
上述公式可以看出,SVM中 w \mathbf{w} w的解就是当且仅当 α ≠ 0 \alpha\ne0 α=0时训练集 x 1 , . . . , x m \mathbf{x}_1,...,\mathbf{x}_m x1,...,xm的线性组合。这些向量就叫做支持向量。上面的第三个式子,如果 α i ≠ 0 \alpha_i\ne0 αi=0,则说明 y i ( w ⋅ x i + b ) = 1 y_i(\mathbf{w}\cdot{\mathbf{x}_i}+b)=1 yi(w⋅xi+b)=1。因此,支持向量存在于间隔超平面上,即 w ⋅ x i + b = ± 1 \mathbf{w}\cdot{\mathbf{x}_i}+b=\pm1 w⋅xi+b=±1。
支持向量机完美地定义了最大间隔超平面的含义,不在间隔超平面上的训练集向量不会对间隔超平面的产生造成影响。换句话说,只有支持向量的改变才会影响SVM的解,支持向量的个数一般不多,但却起着重要的作用。
注意,支持向量机问题的解 w \mathbf{w} w是唯一的,而支持向量则不是。在 N N N维中, N + 1 N + 1 N+1个点足以定义一个超平面。因此,当超过 N + 1 N + 1 N+1个点位于一个间隔超平面上时,对于 N + 1 N + 1 N+1个支持向量可能会有不同的选择。
2.3 对偶优化问题(Dual optimization problem)
将上述KKT条件中的解带入到拉格朗日对偶函数中得:
L = 1 2 ∣ ∣ ∑ i = 1 m α i y i x i ∣ ∣ 2 − ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 m α i y i b + ∑ i = 1 m α i , \mathcal{L}=\frac{1}{2}||\sum_{i=1}^{m}\alpha_iy_i\mathbf{x}_i||^2-\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot{\mathbf{x}_j})-\sum_{i=1}^m\alpha_iy_ib+\sum_{i=1}^m\alpha_i, L=21∣∣i=1∑mαiyixi∣∣2−i,j=1∑mαiαjyiyj(xi⋅xj)−i=1∑mαiyib+i=1∑mαi,
其中 1 2 ∣ ∣ ∑ i = 1 m α i y i x i ∣ ∣ 2 − ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) = − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) \frac{1}{2}||\sum_{i=1}^{m}\alpha_iy_i\mathbf{x}_i||^2-\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot{\mathbf{x}_j})=-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot{\mathbf{x}_j}) 21∣∣∑i=1mαiyixi∣∣2−∑i,j=1mαiαjyiyj(xi⋅xj)=−21∑i,j=1mαiαjyiyj(xi⋅xj)。所示上式可简化为:
L = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) . \mathcal{L}=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot{\mathbf{x}_j}). L=i=1∑mαi−21i,j=1∑mαiαjyiyj(xi⋅xj).
(2)求解 min w , b L ( w , b , α ) \min_{\mathbf{w},b}\mathcal{L}(\mathbf{w},b,\alpha) minw,bL(w,b,α)对 α \alpha α的极大:对于线性可分的SVMs的对偶优化问题转变为:
max α ( ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) ) subject to : α i ≥ 0 and ∑ i = 1 m α i y i = 0 , ∀ i ∈ [ m ] \max_{\alpha}(\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot{\mathbf{x}_j}))\\ \text{subject to}: \alpha_i\ge0\;\text{and}\;\sum_{i=1}^m\alpha_iy_i=0,\forall{i}\in{[m]} αmax(i=1∑mαi−21i,j=1∑mαiαjyiyj(xi⋅xj))subject to:αi≥0andi=1∑mαiyi=0,∀i∈[m]
目标函数 G : α → ( ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) ) G:\alpha\rightarrow(\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot{\mathbf{x}_j})) G:α→(∑i=1mαi−21∑i,j=1mαiαjyiyj(xi⋅xj))是无限可微的。它的海森矩阵 ∇ 2 ( G ) = − A , A = ( y i x i ⋅ y j x j ) \nabla^2(G)=-\mathbf{A},\mathbf{A}=(y_i\mathbf{x}_i\cdot y_j\mathbf{x}_j) ∇2(G)=−A,A=(yixi⋅yjxj), A \mathbf{A} A是格拉姆(Gram)矩阵,因此是半正定的,所以有 ∇ 2 ( G ) ≤ 0 \nabla^2(G)\le0 ∇2(G)≤0,因此 G G G是一个凹函数。因为约束条件是仿射函数和凸函数,上式的最优化问题就是凸优化问题。因为 G G G是 α \alpha α的二次函数,所以这个对偶问题也是一个二次规划问题,在原始优化问题的情况下,同样可以使用通用和专用二次规划问题来获得SVMs的解。
设 α ∗ = ( α 1 ∗ , ⋯ , α m ∗ ) T \alpha^\ast=(\alpha_1^\ast,\cdots,\alpha_m^\ast)^T α∗=(α1∗,⋯,αm∗)T是上述对偶优化问题的解,由KKT条件可得原始最优化问题的解 ( w , b ) (\mathbf{w},b) (w,b)的解 ( w ∗ , b ∗ ) (\mathbf{w}^\ast,b^\ast) (w∗,b∗)解为:
w ∗ = ∑ i = 1 m α i ∗ y i x i \mathbf{w}^\ast=\sum_{i=1}^m\alpha_{i}^\ast y_i\mathbf{x}_i w∗=i=1∑mαi∗yixi
带入到分离超平面中得:
h ( x ) = sgn ( w ⋅ x + b ) = sgn ( ∑ i = 1 m α i y i ( x i ⋅ x ) + b ) h(\mathbf{x})=\text{sgn}(\mathbf{w}\cdot\mathbf{x}+b)=\text{sgn}(\sum_{i=1}^m\alpha_iy_i(\mathbf{x}_i\cdot\mathbf{x})+b) h(x)=sgn(w⋅x+b)=sgn(i=1∑mαiyi(xi⋅x)+b)
由于支持向量存在于间隔超平面中,对于任意的支持向量 x i \mathbf{x}_i xi,都有 w ⋅ x i + b = y i \mathbf{w}\cdot\mathbf{x_i}+b=y_i w⋅xi+b=yi成立,因此:
b ∗ = y j − ∑ i = 1 m α i y i ( x i ⋅ x j ) b^\ast=y_j-\sum_{i=1}^m\alpha_iy_i(\mathbf{x}_i\cdot\mathbf{x_j}) b∗=yj−i=1∑mαiyi(xi⋅xj)
上述的三个公式表明了SVMs的一个重要特性:SVMs的解仅仅取决于向量之间的内积而与向量本身没有直接关系。这个问题会在下一篇博文《核方法》中详细讲解。
将上式等号两边同时乘以 α i y i \alpha_iy_i αiyi,当 α i ≠ 0 \alpha_i\ne0 αi=0时,则有:
∑ i = 1 m α i y i b = ∑ i = 1 m α i y i 2 − ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) . \sum_{i=1}^m\alpha_iy_ib=\sum_{i=1}^m\alpha_iy_i^2-\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x_i}\cdot\mathbf{x}_j). i=1∑mαiyib=i=1∑mαiyi2−i,j=1∑mαiαjyiyj(xi⋅xj).
因为 y i 2 = 1 y_i^2=1 yi2=1并且使用KKT条件中的解可以产生:
0 = ∑ i = 1 m α i − ∣ ∣ w ∣ ∣ 2 . 0=\sum_{i=1}^m\alpha_i-||\mathbf{w}||^2. 0=i=1∑mαi−∣∣w∣∣2.
对于 α i ≥ 0 \alpha_i\ge0 αi≥0,我们可以获得关于 α \alpha α的 L 1 L_1 L1范数的间隔 ρ \rho ρ的表达式:
ρ 2 = 1 ∣ ∣ w ∣ ∣ 2 2 = 1 ∑ i = 1 m α i = 1 ∣ ∣ α ∣ ∣ 1 . \rho^2=\frac{1}{||\mathbf{w}||_2^2}=\frac{1}{\sum_{i=1}^m\alpha_i}=\frac{1}{||\mathbf{\alpha}||_1}. ρ2=∣∣w∣∣221=∑i=1mαi1=∣∣α∣∣11.
2.4 留一分析(Leave-one-out analysis)
我们现在使用留一误差的概念来产生以训练集中部分支持向量为基础的SVMs的第一个学习保证。
定义2:留一误差:让 h S h_S hS表示一个训练在固定样本 S S S上的学习算法 A \mathcal{A} A的假设。则在大小为 m m m的样本 S S S上的 A \mathcal{A} A的留一误差是:
R ^ L O O ( A ) = 1 m ∑ i = 1 m 1 h S − { x i } ( x i ) ≠ y i \widehat{R}_{LOO}(\mathcal{A})=\frac{1}{m}\sum_{i=1}^m\mathbf{1}_{h_{S-\{x_i\}}(x_i)\ne y_i} R LOO(A)=m1i=1∑m1hS−{xi}(xi)=yi
因此,对于任意 i ∈ [ m ] i\in[m] i∈[m], A \mathcal{A} A训练在除了 x i x_i xi以外的训练集 S S S上并其它的误差使用 x i x_i xi来计算。留一误差就是这些误差的平均误差。我们将使用留一误差的一个重要特性来陈述下述引理:
引理3: m ≥ 2 m\ge2 m≥2的样本的平均留一误差是大小为 m − 1 m-1 m−1样本的平均泛化误差的一个无偏估计:
E S ∼ D m [ R ^ L O O ( A ) ] = E S ′ ∼ D m − 1 [ R ( h S ′ ) ] , \mathop{\mathbb{E}}\limits_{S\sim\mathcal{D}^m}[\widehat{R}_{LOO}(\mathcal{A})]=\mathop{\mathbb{E}}\limits_{S^\prime\sim\mathcal{D}^\mathcal{m-1}}[R(h_{S^\prime})], S∼DmE[R LOO(A)]=S′∼Dm−1E[R(hS′)],
D \mathcal{D} D是样本的分布。
证明: 由留一误差定义我们能够写出:
E S ∼ D m [ R ^ ( A ) ] = 1 m ∑ i = 1 m E S ∼ D m [ 1 h S − { x i } ( x i ) ≠ y i ] = E S ∼ D m [ 1 h S − { x 1 } ( x 1 ) ≠ y 1 ] = E S ′ ∼ D m − 1 , x 1 ∼ D [ 1 h S ′ ( x 1 ) ≠ y 1 ] = E S ′ ∼ D m − 1 [ E x 1 ∼ D [ 1 h S ′ ( x 1 ) ≠ y 1 ] ] = E S ′ ∼ D m − 1 [ R ( h S ′ ) ] \begin{aligned} \mathop{\mathbb{E}}\limits_{S\sim\mathcal{D}^m}[\widehat{R}(\mathcal{A})]&=\frac{1}{m}\sum_{i=1}^m\mathop{\mathbb{E}}\limits_{S\sim\mathcal{D}^m}[\mathbf{1}_{h_{S-\{x_i\}}(x_i)\ne y_i}]\\ &=\mathop{\mathbb{E}}\limits_{S\sim\mathcal{D}^m}[\mathbf{1}_{h_{S-\{x_1\}}(x_1)\ne y_1}]\\ &=\mathop{\mathbb{E}}\limits_{S^\prime\sim\mathcal{D}^{m-1},x_1\sim\mathcal{D}}[\mathbf{1}_{h_{S^\prime}(x_1)\ne y_1}]\\ &=\mathop{\mathbb{E}}\limits_{S^\prime\sim\mathcal{D}^{m-1}}[\mathop\mathbb{E}\limits_{x_1\sim\mathcal{D}}[\mathbf{1}_{h_{S^\prime}(x_1)\ne y_1}]]\\ &=\mathop{\mathbb{E}}\limits_{S^\prime\sim\mathcal{D}^\mathcal{m-1}}[R(h_{S^\prime})] \end{aligned} S∼DmE[R (A)]=m1i=1∑mS∼DmE[1hS−{xi}(xi)=yi]=S∼DmE[1hS−{x1}(x1)=y1]=S′∼Dm−1,x1∼DE[1hS′(x1)=y1]=S′∼Dm−1E[x1∼DE[1hS′(x1)=y1]]=S′∼Dm−1E[R(hS′)]
一般来说,计算留一误差是比较费时费力的,因为需要对 m − 1 m-1 m−1个样本训练 m m m次。
定理4:让 h S h_S hS表示一个样本 S S S的SVMs的假设,让 N S V ( S ) N_{SV}(S) NSV(S)表示定义 h S h_S hS的支持向量的个数,则:
E S ∼ D m [ R ( h S ) ] ≤ E S ∼ D m + 1 [ N S V ( S ) m + 1 ] \mathop\mathbb{E}\limits_{S\sim\mathcal{D}^m}[R(h_S)]\le\mathop{\mathbb{E}}\limits_{S\sim\mathcal{D}^{m+1}}[\frac{N_{SV}(S)}{m+1}] S∼DmE[R(hS)]≤S∼Dm+1E[m+1NSV(S)]
证明: S S S表示是线性可分的 m + 1 m+1 m+1个样本,如果 x x x不是 h S h_S hS的支持向量,移除它也不会对SVM的解造成影响。因此, h S − { x } = h S h_{S-\{x\}}=h_S hS−{x}=hS并且 h S − { x } h_{S-\{x\}} hS−{x}正确地将 x x x分类。相反,如果 h S − { x } h_{S-\{x\}} hS−{x}错误地对 x x x进行分类, x x x一定是一个支持向量,这表明:
R ^ L O O ( SVM ) ≤ N S V ( S ) m + 1 . \widehat{R}_{LOO}(\text{SVM})\le\frac{N_{SV}(S)}{m+1}. R LOO(SVM)≤m+1NSV(S).不等式两边分别取期望再利用上面的引理,就会产生定理的结果。
上式表明,算法的平均误差的上界就是支持向量在所有示例点的所占比。所以在实践中,我们更希望有更少的点存在于间隔超平面上,这样的平均误差就会更小。但是,这个界限相对较弱,因为它只适用于算法在大小为 m m m的样本上的平均泛化误差,并没有提供任何关于泛化误差方差的信息。在文章的后面,我们将以间隔的概念提出一个更强大的高概率边界。
3、不可分的情况(Non-separable case)
其实在大多数训练集中,训练样本都是线性不可分的,这表明对于任何超平面 w ⋅ x + b = 0 \mathbf{w}\cdot\mathbf{x}+b=0 w⋅x+b=0,总会存在某些特异点 x i ∈ S \mathbf{x}_i\in{S} xi∈S:
y i [ w ⋅ x i + b ] ≱ 1. y_i[\mathbf{w}\cdot\mathbf{x}_i+b]\ngeq1. yi[w⋅xi+b]≱1.
因此,可以对每个样本点引入一个松弛变量 ξ i ≥ 0 \xi_i\ge0 ξi≥0使得:
y i [ w ⋅ x i + b ] ≥ 1 − ξ i . y_i[\mathbf{w}\cdot\mathbf{x}_i+b]\ge1-\xi_i. yi[w⋅xi+b]≥1−ξi.
下图说明了这个情况,所以向量 x i \mathbf{x}_i xi被认为是特异点要满足 0 < y i ( w ⋅ x i + b ) < 1 0< y_i(\mathbf{w}\cdot\mathbf{x}_i+b)<1 0<yi(w⋅xi+b)<1。这种情况的间隔 ρ = 1 ∣ ∣ w ∣ ∣ \rho=\frac{1}{||\mathbf{w}||} ρ=∣∣w∣∣1被称为软间隔,相反线性可分被称为硬间隔。

在不可分的情况下我们如何挑选分离超平面呢?有两个相矛盾的方法:一方面我们希望由特异点造成的松弛总量得到限制,这可以通过 ∑ i = 1 m ξ i \sum_{i=1}^m\xi_i ∑i=1mξi或者是通过 ∑ i = 1 m ξ i p \sum_{i=1}^m\xi_i^p ∑i=1mξip, p ≥ 1 p\ge1 p≥1来衡量;另一方面,我们寻找一个大间隔超平面,较大的间隔可能会存在更多的特异点,这样将会有更大的松弛。
3.1 原始优化问题(Primal optimization problem)
对于线性不可分的问题,定义一个参数 C ≥ 0 C\ge0 C≥0是间隔最大化(或最小化 ∣ ∣ w ∣ ∣ 2 ||\mathbf{w}||^2 ∣∣w∣∣2)和最小化松弛变量 ∑ i = 1 m ξ i p \sum_{i=1}^m\xi_i^p ∑i=1mξip之间的一个权衡:
min w , b , ξ 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i p subject to y i ( w ⋅ x i + b ) ≥ 1 − ξ i and ξ i ≥ 0 , i ∈ [ m ] , \min_{\mathbf{w},b,\mathbf{\xi}}\frac{1}{2}||\mathbf{w}||^2+C\sum_{i=1}^m\xi_i^p\\ \text{subject to}\;\;y_i(\mathbf{w}\cdot\mathbf{x}_i+b)\ge1-\xi_i \;\text{and}\;\xi_i\ge0,i\in{[m]}, w,b,ξmin21∣∣w∣∣2+Ci=1∑mξipsubject toyi(w⋅xi+b)≥1−ξiandξi≥0,i∈[m],其中 ξ = ( ξ 1 , ⋯ , ξ m ) T \xi=(\xi_1,\cdots,\xi_m)^T ξ=(ξ1,⋯,ξm)T。参数 C C C是由 n n n折交叉验证决定的。
与线性可分的情况一样,因为约束条件是仿射的所以是凸的并且目标函数对于对任意 p ≥ 1 p\ge1 p≥1也是凸的,所以上式是一个凸优化问题。
对于 p p p有很多可能的选择会导致或多或少的惩罚松弛项,但选择 p = 1 p=1 p=1和 p = 2 p=2 p=2会得到更好更直接的解。与选择 p = 1 p=1 p=1和 p = 2 p=2 p=2相关的损失函数被叫做铰链损失和二次铰链损失。下图展示了这些损失函数和标准 0 − 1 0-1 0−1损失函数的函数图像:
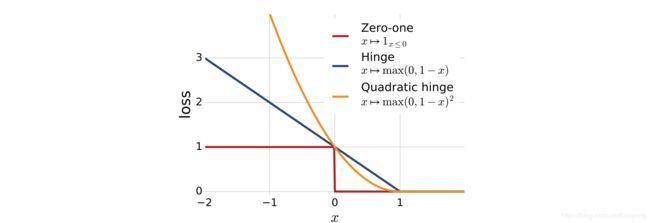
这两个铰链损损失函数都是 0 − 1 0 - 1 0−1损失的凸上界,因此非常适合于优化。接下来分析的是铰链损失( p = 1 p = 1 p=1的情况),这是支持向量机中应用最广泛的损失函数。
3.2 支持向量(Support vectors)
与上一节的线性可分原始优化问题的对偶优化问题一样,线性不可分的对偶优化问题如下:
L ( w , b , ξ , α , β ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ i − ∑ i = 1 m α i [ y i ( w ⋅ x i + b ) − 1 + ξ i ] − ∑ i = 1 m β i ξ i , \mathcal{L}(\mathbf{w},b,\xi,\alpha,\beta)=\frac{1}{2}||\mathbf{w}||^2+C\sum_{i=1}^m\xi_i-\sum_{i=1}^m\alpha_i[y_i(\mathbf{w}\cdot\mathbf{x}_i+b)-1+\xi_i]-\sum_{i=1}^m\beta_i\xi_i, L(w,b,ξ,α,β)=21∣∣w∣∣2+Ci=1∑mξi−i=1∑mαi[yi(w⋅xi+b)−1+ξi]−i=1∑mβiξi,其中 w ∈ R N \mathbf{w}\in{\mathbb{R}^N} w∈RN, b ∈ R b\in{\mathbb{R}} b∈R, ξ , α , β ∈ R + m \xi,\alpha,\beta\in{\mathbb{R}_+^m} ξ,α,β∈R+m。
KKT条件就是将原始优化问题中的 w , b \mathbf{w},b w,b和 ξ \xi ξ相关的拉格朗日对偶优化问题的梯度置零,并加上互补条件:
∇ w L = w − ∑ i = 1 m α i y i x i = 0 ⇒ w = ∑ i = 1 m α i y i x i ∇ b L = − ∑ i = 1 m α i y i = 0 ⇒ ∑ i = 1 m α i y i = 0 ∇ ξ L = C − α i − β i = 0 ⇒ α i + β i = C ∀ i , α i [ y i ( w ⋅ x i + b ) − 1 + ξ i ] = 0 ⇒ α i = 0 or y i ( w ⋅ x i + b ) = 1 − ξ i ∀ i , β i ξ i = 0 ⇒ β i = 0 or ξ i = 0 \begin{array}{lcl} \nabla_{\mathbf{w}}\mathcal{L}=\mathbf{w}-\sum_{i=1}^m\alpha_iy_i\mathbf{x}_i=0&\Rightarrow&\mathbf{w}=\sum_{i=1}^m\alpha_iy_i\mathbf{x}_i\\\\ \nabla_{b}\mathcal{L}=-\sum_{i=1}^m\alpha_iy_i=0&\Rightarrow&\sum_{i=1}^m\alpha_iy_i=0\\\\ \nabla_{\xi}\mathcal{L}=C-\alpha_i-\beta_i=0&\Rightarrow&\alpha_i+\beta_i=C\\\\ \forall i,\alpha_i[y_i(\mathbf{w}\cdot\mathbf{x}_i+b)-1+\xi_i]=0&\Rightarrow&\alpha_i=0 \;\;\text{or}\;\;y_i(\mathbf{w}\cdot\mathbf{x}_i+b)=1-\xi_i\\\\ \forall i,\beta_i\xi_i=0&\Rightarrow&\beta_i=0\;\text{or}\;\xi_i=0 \end{array} ∇wL=w−∑i=1mαiyixi=0∇bL=−∑i=1mαiyi=0∇ξL=C−αi−βi=0∀i,αi[yi(w⋅xi+b)−1+ξi]=0∀i,βiξi=0⇒⇒⇒⇒⇒w=∑i=1mαiyixi∑i=1mαiyi=0αi+βi=Cαi=0oryi(w⋅xi+b)=1−ξiβi=0orξi=0
这里与线性可分的情况就有所区别了,如果 α i ≠ 0 \alpha_i\ne0 αi=0则 y i ( w ⋅ x i + b ) = 1 − ξ i y_i(\mathbf{w}\cdot\mathbf{x}_i+b)=1-\xi_i yi(w⋅xi+b)=1−ξi。如果 ξ i = 0 \xi_i=0 ξi=0,则 y i ( w ⋅ x i + b ) = 1 y_i(\mathbf{w}\cdot\mathbf{x}_i+b)=1 yi(w⋅xi+b)=1, x i \mathbf{x}_i xi存在于间隔超平面上,属于可分的情况。否则 ξ i ≠ 0 \xi_i\ne0 ξi=0, x i \mathbf{x}_i xi是一个特异点。这种情况下表明 β i = 0 \beta_i=0 βi=0,这就需要 α i = C \alpha_i=C αi=C。因此,当 α i = C \alpha_i=C αi=C时, x i \mathbf{x}_i xi是特异点。与可分情况一样,权值向量 w \mathbf{w} w的解是唯一的,但支持向量不唯一。
3.3 对偶优化问题(Dual optimization problem)
将上一小节中的KKT中的解带入到拉格朗日对偶函数中得:
L = 1 2 ∣ ∣ ∑ i = 1 m α i y i x i ∣ ∣ 2 − ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) ⏟ − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 m α i y i b ⏟ 0 + ∑ i = 1 m α i . \mathcal{L}=\begin{matrix}\underbrace{\frac{1}{2}||\sum_{i=1}^m\alpha_iy_i\mathbf{x}_i||^2-\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot\mathbf{x}_j)}\\{-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot\mathbf{x}_j)}\end{matrix}-\begin{matrix}\underbrace{\sum_{i=1}^m\alpha_iy_ib}\\{0}\end{matrix}+\sum_{i=1}^m\alpha_i. L= 21∣∣i=1∑mαiyixi∣∣2−i,j=1∑mαiαjyiyj(xi⋅xj)−21∑i,j=1mαiαjyiyj(xi⋅xj)− i=1∑mαiyib0+i=1∑mαi.
所以我们发现,目标函数与可分情况下的没有区别:
L = ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) . \mathcal{L}=\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot\mathbf{x}_j). L=i=1∑mαi−21i,j=1∑mαiαjyiyj(xi⋅xj).
然而,除了要求 α i ≥ 0 \alpha_i\ge0 αi≥0之外,还要求变量 β i ≥ 0 \beta_i\ge0 βi≥0。由上述的KKT条件,说明 α i ≤ C \alpha_i\le C αi≤C。这将导致不可分情况下的SVMs的对偶优化问题仅仅在限制 α i ≤ C \alpha_i\le C αi≤C下有区别于线性可分的情况:
max α ( ∑ i = 1 m α i − 1 2 ∑ i , j = 1 m α i α j y i y j ( x i ⋅ x j ) ) subject to : 0 ≤ α i ≤ C and ∑ i = 1 m α i y i = 0 , i ∈ [ m ] . \max_{\alpha}(\sum_{i=1}^m\alpha_i-\frac{1}{2}\sum_{i,j=1}^m\alpha_i\alpha_jy_iy_j(\mathbf{x}_i\cdot\mathbf{x}_j))\\ \text{subject to}:0\le\alpha_i\le C \;\text{and}\;\sum_{i=1}^m\alpha_iy_i=0,i\in{[m]}. αmax(i=1∑mαi−21i,j=1∑mαiαjyiyj(xi⋅xj))subject to:0≤αi≤Candi=1∑mαiyi=0,i∈[m].
因此,与线性可分的情况一样,对偶问题的解 α \alpha α可以直接应用到SVMs的假设集的解上来,解得 w = ∑ i = 1 m α i y i x i \mathbf{w}=\sum_{i=1}^m\alpha_iy_i\mathbf{x}_i w=∑i=1mαiyixi:
h ( x ) = sgn ( w ⋅ x + b ) = sgn ( ∑ i = 1 m α i y i ( x i ⋅ x ) + b ) . h(\mathbf{x})=\text{sgn}(\mathbf{w}\cdot{\mathbf{x}}+b)=\text{sgn}(\sum_{i=1}^m\alpha_iy_i(\mathbf{x}_i\cdot\mathbf{x})+b). h(x)=sgn(w⋅x+b)=sgn(i=1∑mαiyi(xi⋅x)+b).
并且 b b b能够通过任意在间隔超平面上的支持向量 x i \mathbf{x}_i xi( 0 ≤ α i ≤ C 0\le\alpha_i\le C 0≤αi≤C)来确定。对于每一个支持向量都有 w ⋅ x i + b = y i \mathbf{w}\cdot\mathbf{x}_i+b=y_i w⋅xi+b=yi,因此
b = y i − ∑ i = 1 m α i y i ( x j ⋅ x i ) . b=y_i-\sum_{i=1}^m\alpha_iy_i(\mathbf{x}_j\cdot\mathbf{x}_i). b=yi−i=1∑mαiyi(xj⋅xi).
与线性可分的情况一致,假设解只依赖于向量之间的内积而不直接依赖于向量本身。这个事实可以用来扩展支持向量机来定义非线性决策边界,我们将在下篇文章中讲述。
对于软间隔支持向量 x i \mathbf{x}_i xi或者在间隔边界上,或者在间隔边界与分离超平面之间,或者在超平面的负一侧。若 α i < C \alpha_i
4、间隔理论(Margin theory)
本节给出了支持向量机算法的泛化边界为支持向量机算法提供了有力的理论支持。
对二分类问题, R N \mathbb{R}^N RN空间的 V C VC VC维是 N + 1 N+1 N+1。应用 V C VC VC维边界可以推导出:
R ( h ) ≤ R ^ S ( h ) + 2 ( N + 1 ) log e m n + 1 m + log 1 δ 2 m . R(h)\le\widehat{R}_S(h)+\sqrt{\frac{2(N+1)\log{\frac{em}{n+1}}}{m}}+\sqrt{\frac{\log{\frac{1}{\delta}}}{2m}}. R(h)≤R S(h)+m2(N+1)logn+1em+2mlogδ1.
当特征空间 N N N的维数比样本数量 m m m大时,这个界限没有什么意义。但本节中提供的学习保证与维度 N N N无关,因此不考虑特征空间维度。
我们提出的这个边界保证对例如SVMs的解 x → w ⋅ x + b \mathbf{x}\rightarrow\mathbf{w}\cdot\mathbf{x}+b x→w⋅x+b实值函数成立而不是例如 x → sgn ( w ⋅ x + b ) \mathbf{x}\rightarrow\text{sgn}(\mathbf{w}\cdot\mathbf{x}+b) x→sgn(w⋅x+b)解为 + 1 , − 1 +1,-1 +1,−1的分类函数。实值函数是以置信间隔(confidence margin)为基础的。在以标签为 y y y的点 x x x的实值函数的置信间隔是 y h ( x ) yh(x) yh(x)。因此,当 y h ( x ) > 0 yh(x)>0 yh(x)>0, h h h正确地分类 x x x但是我们将 ∣ h ( x ) ∣ |h(x)| ∣h(x)∣的大小解释为 h h h所做预测的置信度。置信间隔的概念与几何间隔不同,不需要假设数据时线性可分性的。但是,下面两个概念在线性可分情况下是有关系的:对于 h : x → w ⋅ x + b h:\mathbf{x}\rightarrow\mathbf{w}\cdot\mathbf{x}+b h:x→w⋅x+b的几何间隔为 ρ geom \rho_{\text{geom}} ρgeom,对任意训练点中标签为 y y y的点 x \mathbf{x} x的置信间隔至少是 ρ geom ∣ ∣ w ∣ ∣ \rho_{\text{geom}}||\mathbf{w}|| ρgeom∣∣w∣∣,也就是 ∣ y h ( x ) ∣ ≥ ρ geom ∣ ∣ w ∣ ∣ |yh(x)|\ge\rho_{\text{geom}}||\mathbf{w}|| ∣yh(x)∣≥ρgeom∣∣w∣∣。
对于置信间隔的定义,对任意 ρ > 0 \rho>0 ρ>0,与 0 − 1 0-1 0−1损失一样,可以当误分类点 x , ( y h ( x ) < 0 ) x,(yh(x)<0) x,(yh(x)<0)时用 1 1 1来表示对 h h h的惩罚。所以可以通过定义 ρ − \rho- ρ−间隔损失函数来表示,但是要注意即使 h h h正确分类 x x x但置信间隔小于等于 ρ ( y h ( x ) ≤ ρ ) \rho\;(yh(x)\le\rho) ρ(yh(x)≤ρ)时也要对 h h h进行惩罚。下面以损失函数的形式给出了本节主要的基于间隔的泛化边界:
定义5:间隔损失函数:对任意 ρ > 0 \rho>0 ρ>0, ρ − \rho- ρ−间隔损失函数是定义在通过 L ρ ( y , y ′ ) = Φ ρ ( y y ′ ) L_\rho(y,y^\prime)=\Phi_{\rho}(yy^\prime) Lρ(y,y′)=Φρ(yy′)对所有的 y , y ′ ∈ R y,y^\prime\in{\mathbb{R}} y,y′∈R的损失函数 L ρ : R × R → R + L_{\rho}:\mathbb{R}\times\mathbb{R}\rightarrow\mathbb{R}_+ Lρ:R×R→R+
Φ ρ ( x ) = min ( 1 , max ( 0 , 1 − x ρ ) ) = { 1 if x ≤ 0 1 − x ρ if 0 ≤ x ≤ ρ 0 if ρ ≤ x . \Phi_\rho(x)=\min\Bigg(1,\max(0,1-\frac{x}{\rho})\Bigg)= \begin{cases} 1 &\text{if}\;x\le0\\ 1-\frac{x}{\rho} & \text{if}\;0\le x\le\rho \\ 0 & \text{if}\;\rho\le x \end{cases}. Φρ(x)=min(1,max(0,1−ρx))=⎩⎪⎨⎪⎧11−ρx0ifx≤0if0≤x≤ρifρ≤x.
下图是对上式的阐述,参数 ρ > 0 \rho>0 ρ>0是对假设集 h h h的置信间隔的解释。经验间隔损失的定义类似于训练样本的间隔损失。

定义6:经验间隔损失:一个样本 S = ( x 1 , ⋯ , x m ) S=(x_1,\cdots,x_m) S=(x1,⋯,xm)和一个假设集 h h h,经验间隔损失可以如下定义:
R ^ S , ρ ( h ) = 1 m ∑ i = 1 m Φ ρ ( y i h ( x i ) ) . \widehat{R}_{S,\rho}(h)=\frac{1}{m}\sum_{i=1}^m\Phi_{\rho}(y_ih(x_i)). R S,ρ(h)=m1i=1∑mΦρ(yih(xi)).
需要知道,对任意的 i ∈ [ m ] i\in{[m]} i∈[m], Φ ρ ( y i h ( x i ) ) ≤ 1 y i h ( x i ) ≤ ρ \Phi_{\rho}(y_ih(x_i))\le\mathbf{1}_{y_ih(x_i)\le\rho} Φρ(yih(xi))≤1yih(xi)≤ρ。因此,经验间隔损失的上界如下:
R ^ S , ρ ( h ) ≤ 1 m ∑ i = 1 m 1 y i h ( x i ) ≤ ρ . \widehat{R}_{S,\rho}(h)\le\frac{1}{m}\sum_{i=1}^m\mathbf{1}_{y_ih(x_i)\le\rho}. R S,ρ(h)≤m1i=1∑m1yih(xi)≤ρ.
结果证明,经验间隔损失能够通过它的上界来取代:如上图所示,损失函数的上界是训练样本点 x x x小于间隔 ρ \rho ρ的一个分数。
下述是基于 V C VC VC维和Rademacher复杂度推导的支持向量机的间隔理论,只给结论,暂不证明。
引理7(Talagrand引理):让 Φ 1 , ⋯ , Φ m \Phi_1,\cdots,\Phi_m Φ1,⋯,Φm是从 R \mathbb{R} R到 R \mathbb{R} R的 l − L i p s c h i t z l-Lipschitz l−Lipschitz函数, σ 1 , ⋯ , σ m \sigma_1,\cdots,\sigma_m σ1,⋯,σm是Rademacher随机变量。对任意实值函数的假设集合 H \mathcal{H} H,下述不等式成立:
1 m E σ [ sup h ∈ H ∑ i = 1 m σ i ( Φ ∘ h ( x i ) ) ] ≤ l m E σ [ sup h ∈ H ∑ i = 1 m σ i h ( x i ) ] = l R ^ S ( H ) . \frac{1}{m}\mathop{\mathbb{E}}\limits_{\sigma}[\sup_{h\in{\mathcal{H}}}\sum_{i=1}^m\sigma_i(\Phi\circ h(x_i))]\le\frac{l}{m}\mathop{\mathbb{E}}\limits_{\sigma}[\sup_{h\in{\mathcal{H}}}\sum_{i=1}^m\sigma_ih(x_i)]=l\widehat\mathfrak{R}_S(\mathcal{H}). m1σE[h∈Hsupi=1∑mσi(Φ∘h(xi))]≤mlσE[h∈Hsupi=1∑mσih(xi)]=lR S(H).
一般来说:如果对于所有的 i ∈ [ m ] i\in{[m]} i∈[m], Φ i = Φ \Phi_i=\Phi Φi=Φ,下述不等式成立:
R ^ S ( Φ ∘ H ) ≤ l R ^ S ( H ) . \widehat{\mathbf{\mathfrak{R}}}_S(\Phi\circ\mathcal{H})\le l\widehat{\mathfrak{R}}_S(\mathcal{H}). R S(Φ∘H)≤lR S(H).
定理8:二分类间隔边界: H \mathcal{H} H是一系列实值函数。对于 ρ > 0 \rho>0 ρ>0,任意 δ > 0 \delta>0 δ>0,至少以 1 − δ 1-\delta 1−δ概率,对 h ∈ H h\in{\mathcal{H}} h∈H,以下两个不等式成立:
R ( h ) ≤ R ^ S , ρ ( h ) + 2 ρ R m ( H ) + log 1 δ 2 m R ( h ) ≤ R ^ S , ρ ( h ) + 2 ρ R ^ S ( H ) + 3 log 2 δ 2 m . R(h)\le\widehat{R}_{S,\rho}(h)+\frac{2}{\rho}\mathfrak{R}_m(\mathcal{H})+\sqrt{\frac{\log{\frac{1}{\delta}}}{2m}}\\ R(h)\le\widehat{R}_{S,\rho}(h)+\frac{2}{\rho}\widehat{\mathfrak{R}}_S(\mathcal{H})+3\sqrt{\frac{\log{\frac{2}{\delta}}}{2m}}. R(h)≤R S,ρ(h)+ρ2Rm(H)+2mlogδ1R(h)≤R S,ρ(h)+ρ2R S(H)+32mlogδ2.
定理9:让 H \mathcal{H} H是一系列实值函数。对固定的 r > 0 r>0 r>0,对任意的 δ > 0 \delta>0 δ>0,至少有 1 − δ 1-\delta 1−δ的概率,对所有的 h ∈ H h\in{\mathcal{H}} h∈H和 ρ ∈ ( 0 , r ] \rho\in{(0,r]} ρ∈(0,r]:
R ( h ) ≤ R ^ S , ρ ( h ) + 2 ρ R m ( H ) + log log 2 2 r ρ m + log 2 δ 2 m R ( h ) ≤ R ^ S , ρ ( h ) + 2 ρ R ^ S ( H ) + log log 2 2 r ρ m + 3 log 4 δ 2 m R(h)\le\widehat{R}_{S,\rho}(h)+\frac{2}{\rho}\mathfrak{R}_m(\mathcal{H})+\sqrt{\frac{\log\log_2{\frac{2r}{\rho}}}{m}}+\sqrt{\frac{\log{\frac{2}{\delta}}}{2m}}\\\\\\\\ R(h)\le\widehat{R}_{S,\rho}(h)+\frac{2}{\rho}\widehat\mathfrak{R}_S(\mathcal{H})+\sqrt{\frac{\log\log_2{\frac{2r}{\rho}}}{m}}+3\sqrt{\frac{\log{\frac{4}{\delta}}}{2m}} R(h)≤R S,ρ(h)+ρ2Rm(H)+mloglog2ρ2r+2mlogδ2R(h)≤R S,ρ(h)+ρ2R S(H)+mloglog2ρ2r+32mlogδ4
定理10:让 S ⊆ { x : ∣ ∣ x ∣ ∣ ≤ r } S\subseteq\{\mathbf{x}:||\mathbf{x}||\le r\} S⊆{x:∣∣x∣∣≤r}是大小为 m m m的样本,让 H = { x → w ⋅ x : ∣ ∣ w ∣ ∣ ≤ Λ } \mathcal{H}=\{\mathbf{x}\rightarrow \mathbf{w}\cdot\mathbf{x}:||\mathbf{w}||\le\Lambda\} H={x→w⋅x:∣∣w∣∣≤Λ},则 H \mathcal{H} H的经验Rademacher复杂度由下述不等式约束:
R ^ S ( H ) ≤ r 2 Λ 2 m . \widehat{\mathfrak{R}}_S(H)\le\sqrt{\frac{r^2\Lambda^2}{m}}. R S(H)≤mr2Λ2.
推论11:让 H = { w ⋅ x : ∣ ∣ w ∣ ∣ ≤ Λ } \mathcal{H}=\{\mathbf{w}\cdot\mathbf{x}:||\mathbf{w}||\le\Lambda\} H={w⋅x:∣∣w∣∣≤Λ}并且假定 χ ⊆ { x : ∣ ∣ x ∣ ∣ ≤ r } \chi\subseteq\{\mathbf{x}:||\mathbf{x}||\le r\} χ⊆{x:∣∣x∣∣≤r}。对固定 ρ > 0 \rho>0 ρ>0,对任意 δ > 0 \delta>0 δ>0,至少有 1 − δ 1-\delta 1−δ在大小为 m m m的样本 S S S下的概率,对任意 h ∈ H h\in{\mathcal{H}} h∈H成立:
R ( h ) ≤ R ^ S , ρ ( h ) + 2 r 2 Λ 2 / ρ 2 m + log 1 δ 2 m . R(h)\le\widehat{R}_{S,\rho}(h)+2\sqrt{\frac{r^2\Lambda^2/\rho^2}{m}}+\sqrt{\frac{\log\frac{1}{\delta}}{2m}}. R(h)≤R S,ρ(h)+2mr2Λ2/ρ2+2mlogδ1.
下篇更新《机器学习中的数学》,再下一篇更新《机器学习之核方法》,to be continued…