开源分布式工作流任务调度系统EasyScheduler使用详解
登录
- 输入http://192.168.xx.xx:8888/view/login/index.html 网址,输入用户名:admin,密码:escheduler123 登录
- 登录之后每个页面的右上角都有用户的身份标识。点击下拉箭头包含用户信息和退出两个按钮
- 点击“用户信息”按钮,如下图:
- 点击”修改”按钮,修改用户信息
- 点击退出按钮则退出系统,返回登录页面
安全中心
- 只有管理员才有安全中心,安全中心的主要功能是给管理员提供管理普通用户的功能。
- 管理员可以有多个,管理员是功能上的管理,不参与具体的业务。也就是说管理员是不能执行具体任务的。
租户管理
> 租户是Linux上的用户,用于作业的提交。
- 创建、编辑租户
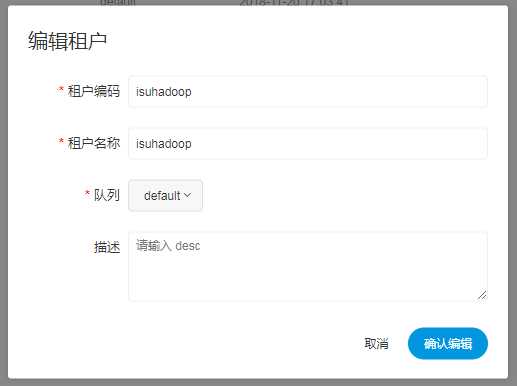
- 租户编码:租户编码是Linux上的用户,唯一,不能重复
- 租户名称:租户的名称
- 队列:租户对应的YARN上的队列,在数据库 t_escheduler_queue 中设置
- 描述:租户的描述信息
用户管理
> 用户是EasyScheduler上的用户,用于EasyScheduler上的功能操作。
- 创建、编辑用户
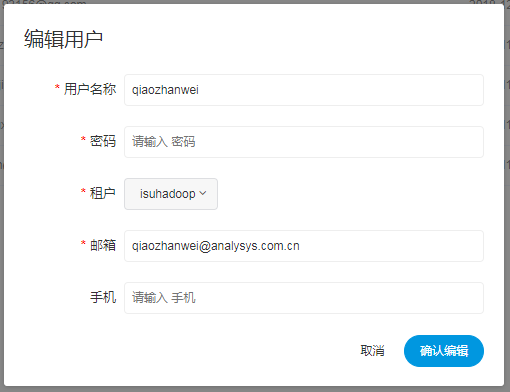
- 用户名称:用户的名称,唯一,不能重复
- 租户:设置该用户所属的租户
- 邮箱:输入用户的邮箱,用来邮件发送和任务告警
- 手机:输入用户的手机号
注意:如果该用户切换了租户,则该用户所在租户下所有资源将复制到切换的新租户下
- 授权
> 管理员可以对普通用户进行非其创建的项目、资源、数据源和UDF函数进行授权。因为项目、资源、数据源和UDF函数授权方式都是一样的,所以以项目授权为例介绍。
- 1.点击指定人的授权按钮,如下图:
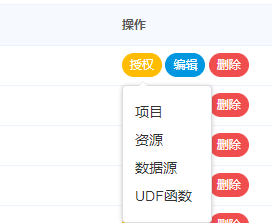
- 2.选中项目按钮,进行项目授权

- 项目列表:是该用户未授权的项目
- 已选项目:是该用户已授权的项目。
- 特别注意:对于用户自己创建的项目,该用户拥有所有的权限。则项目列表和已选项目列表中不会体现。
告警组管理
> 告警组是告警用户抽象出来的组,使用告警组来管理用户。
- 新建、编辑邮件组
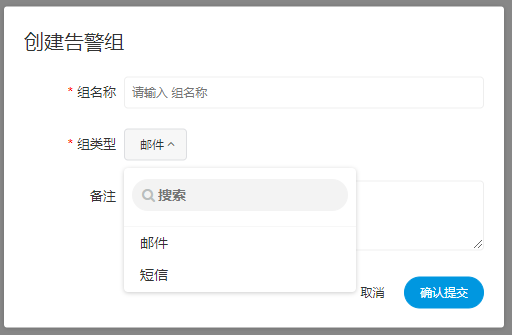
-
组名称:输入组的名称
-
组类型:支持邮件/短信两种
-
备注:输入告警组的备注信息
-
管理用户
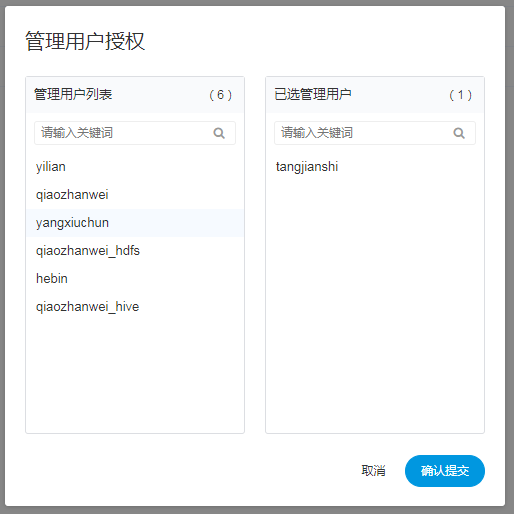
- 管理用户列表:是未添加到该组的用户列表
- 已选管理用户:是已添加到该组的用户列表
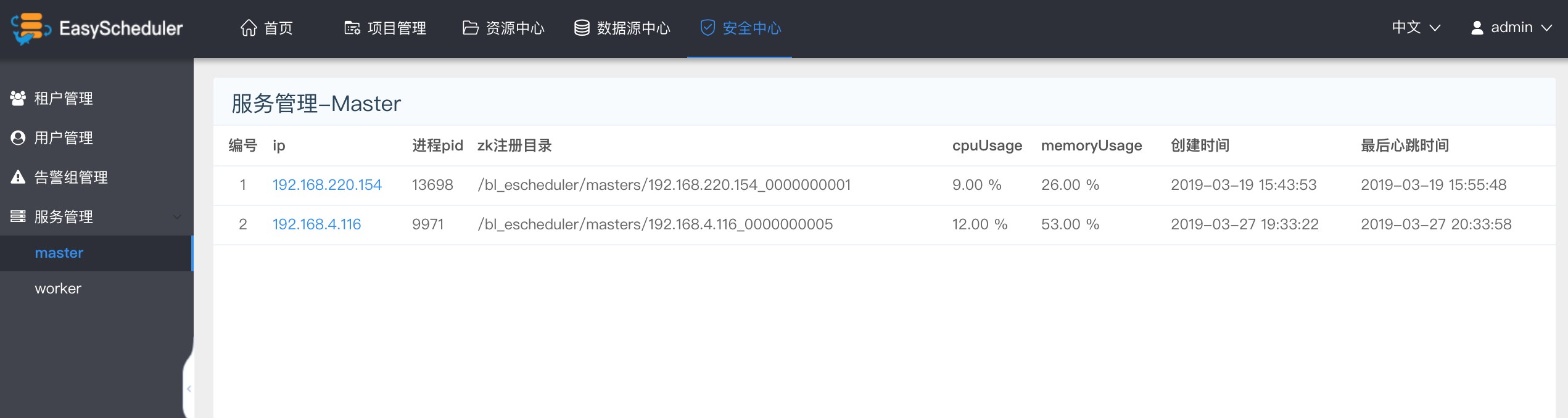
服务管理
> 服务管理是对EasyScheduler的Master、Worker的任务监控
Master
Worker

资源中心
> 资源中心主要分为文件管理和UDF函数管理。 文件管理:主要是用户的程序,脚本和配置文件需要上传到HDFS进行统一管理 UDF函数管理:对用户创建的UDF进行管理
文件管理
创建文件
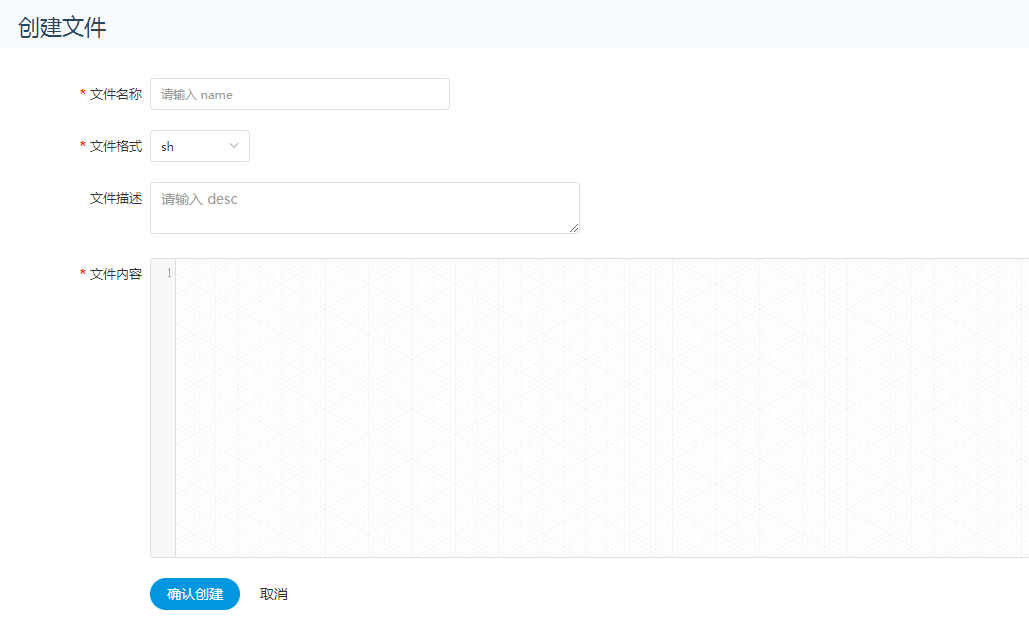
- 文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql
上传文件
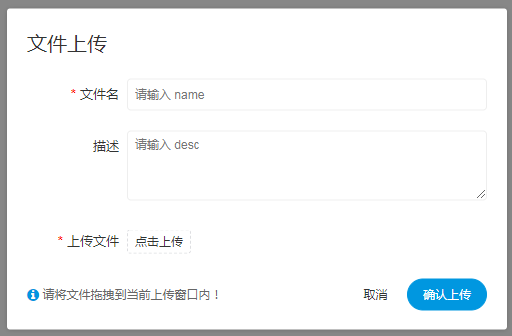
- 文件名:输入文件的名称
- 描述:输入文件的描述信息
- 上传文件:点击上传按钮进行上传,将文件拖拽到上传区域,文件名会自动以上传的文件名称补全
文件查看
> 对可查看的文件类型,点击 文件名称 可以查看文件详情
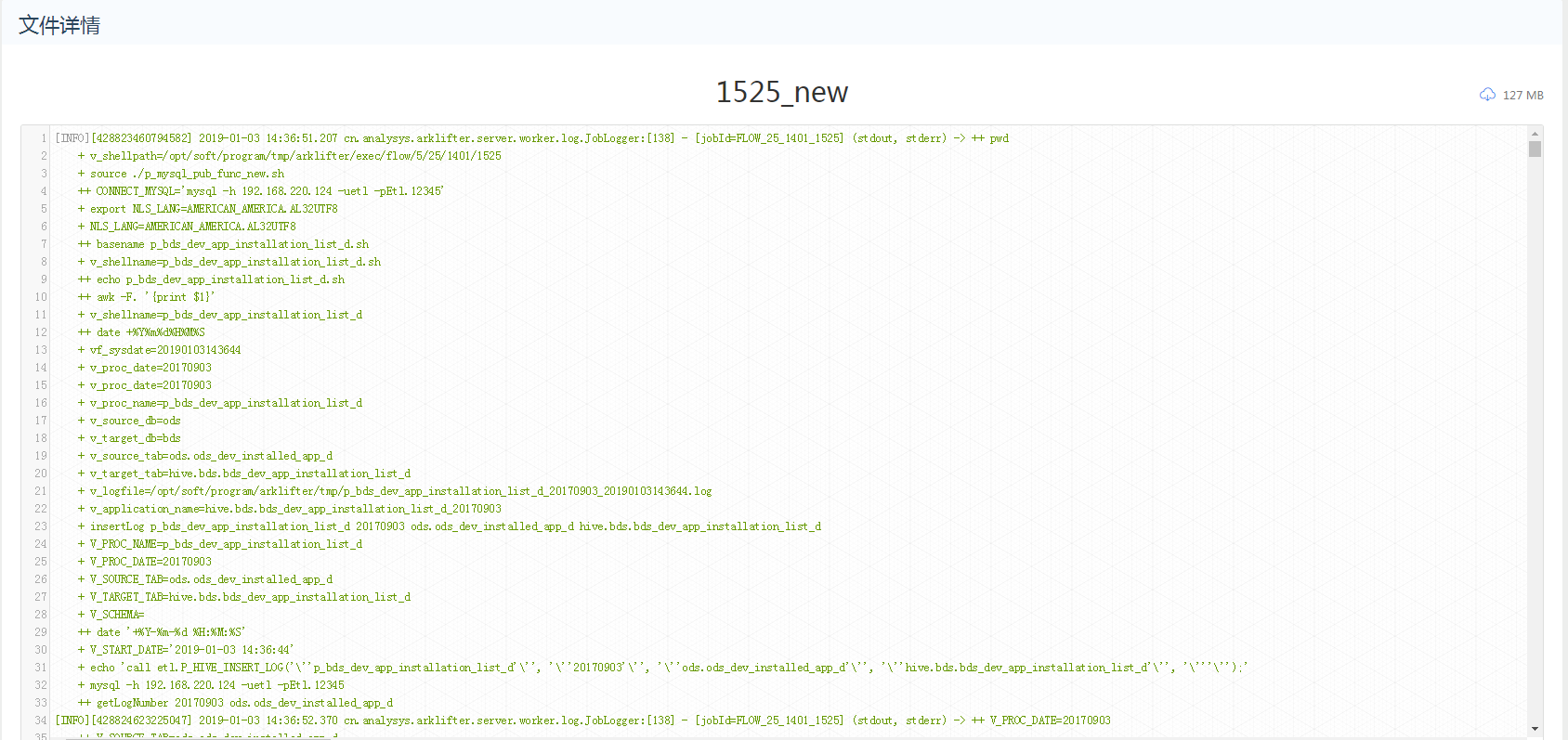
下载文件
> 可以在 文件详情 中点击右上角下载按钮下载文件,或者在文件列表后的下载按钮下载文件
文件重命名
删除
- 文件列表,点击 删除 按钮,删除文件
UDF管理
资源管理
> 资源管理和文件管理功能类似,不同之处是资源管理是上传的UDF函数,文件管理上传的是用户程序,脚本及配置文件
函数管理
创建、编辑UDF函数
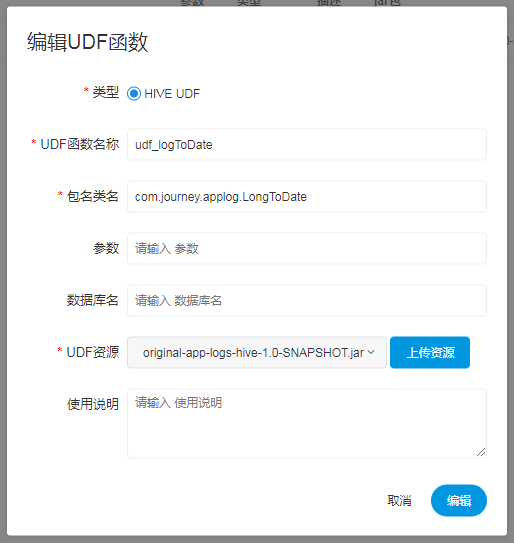
目前只支持HIVE的临时UDF函数
- UDF函数名称:输入UDF函数时的名称
- 包名类名:输入UDF函数的全路径
- 参数:用来标注函数的输入参数
- 数据库名:预留字段,用于创建永久UDF函数
- UDF资源:设置创建的UDF对应的资源文件
数据源中心
> 数据源中心支持MySQL、POSTGRESQL、HIVE及Spark数据源
创建、编辑MySQL数据源
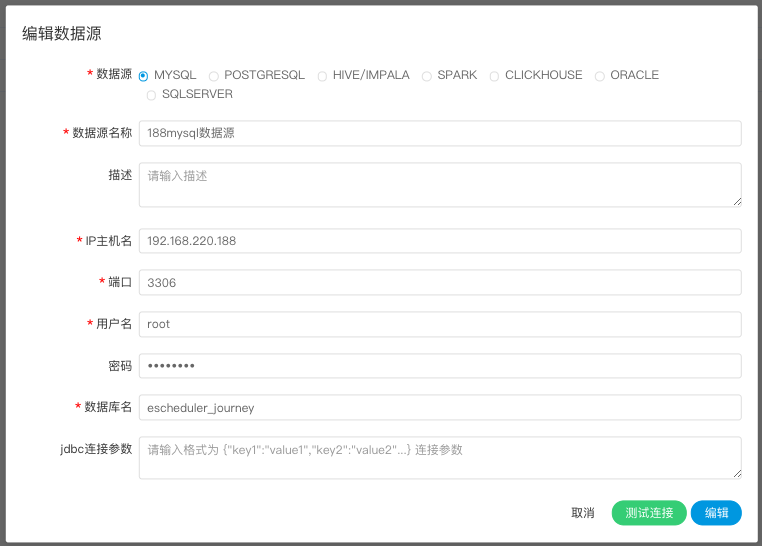
- 数据源:选择MYSQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接MySQL的IP
- 端口:输入连接MySQL的端口
- 用户名:设置连接MySQL的用户名
- 密码:设置连接MySQL的密码
- 数据库名:输入连接MySQL的数据库名称
- Jdbc连接参数:用于MySQL连接的参数设置,以JSON形式填写
创建、编辑POSTGRESQL数据源
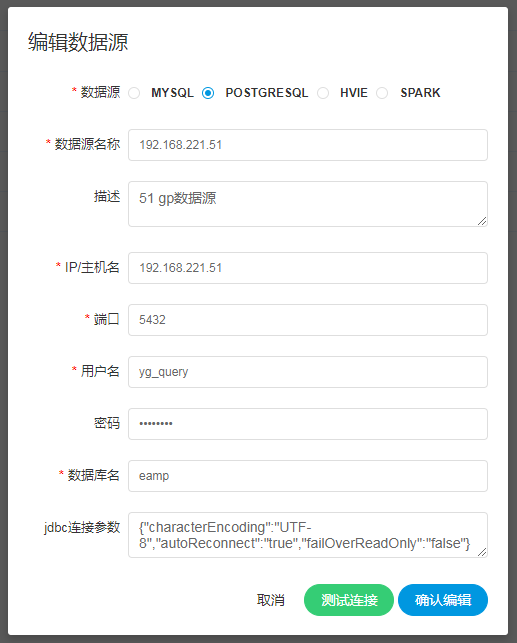
- 数据源:选择POSTGRESQL
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接POSTGRESQL的IP
- 端口:输入连接POSTGRESQL的端口
- 用户名:设置连接POSTGRESQL的用户名
- 密码:设置连接POSTGRESQL的密码
- 数据库名:输入连接POSTGRESQL的数据库名称
- Jdbc连接参数:用于POSTGRESQL连接的参数设置,以JSON形式填写
创建、编辑HIVE数据源
1.使用HiveServer2方式连接

- 数据源:选择HIVE
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接HIVE的IP
- 端口:输入连接HIVE的端口
- 用户名:设置连接HIVE的用户名
- 密码:设置连接HIVE的密码
- 数据库名:输入连接HIVE的数据库名称
- Jdbc连接参数:用于HIVE连接的参数设置,以JSON形式填写
2.使用HiveServer2 HA Zookeeper方式连接
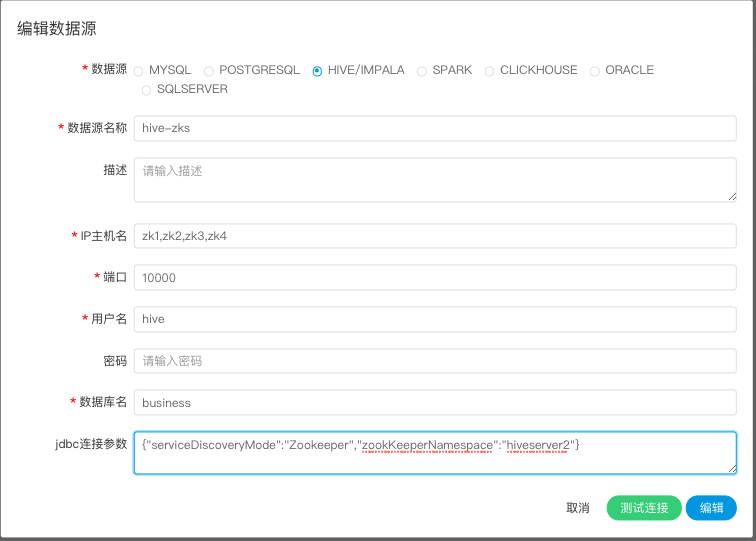
- 数据源:选择HIVE
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接Zookeeper的集群
- 端口:输入连接Zookeeper的端口
- 用户名:设置连接HIVE的用户名
- 密码:设置连接HIVE的密码
- 数据库名:输入连接HIVE的数据库名称
- Jdbc连接参数:用于Zookeeper连接的参数设置,以JSON形式填写
创建、编辑Spark数据源
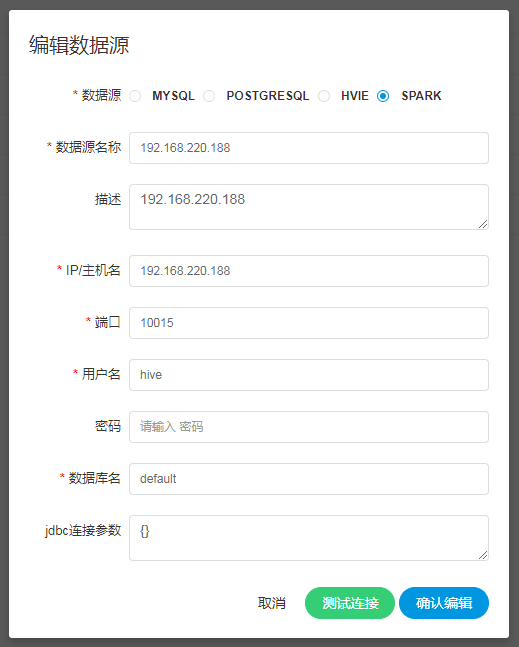
- 数据源:选择Spark
- 数据源名称:输入数据源的名称
- 描述:输入数据源的描述
- IP/主机名:输入连接Spark的IP
- 端口:输入连接Spark的端口
- 用户名:设置连接Spark的用户名
- 密码:设置连接Spark的密码
- 数据库名:输入连接Spark的数据库名称
- Jdbc连接参数:用于Spark连接的参数设置,以JSON形式填写
首页
> 首页是对所有项目在指定时间范围内的任务状态、流程状态和流程定义的统计。
首页和项目首页的主要区别在于:
- 首页中的图表是没有链接的,项目首页中图表是有链接的
- 首页统计的是所有的项目,项目首页统计的是某一个项目
项目管理
> 项目是调度对用户流程定义DAG分组的一个抽象
创建、编辑项目
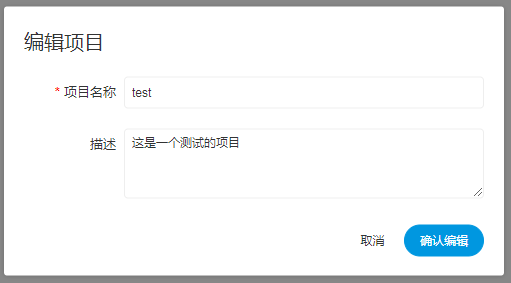
- 项目名称:输入项目的名称
- 描述:输入项目的描述
项目首页
> 点击项目列表中的项目名称,可以跳转到指定的项目首页,如下图:
- 项目首页其中包含四个部分,任务状态统计,流程状态统计、流程定义统计及统计的时间范围
- 任务状态统计:是指在指定时间范围内,统计任务实例中的待运行、失败、运行中、完成、成功的个数
- 流程状态统计:是指在指定时间范围内,统计流程实例中的待运行、失败、运行中、完成、成功的个数
- 流程定义统计:是统计该用户创建的流程定义及管理员授予该用户的流程定义
注意:可以点击图,或者数量跳转到相应的任务实例,流程实例和流程定义列表
工作流
> 工作流分为流程定义、流程实例和任务实例三个功能模块
- 流程定义:是可视化拖拽成的DAG的统称,它是静态的,没有状态
- 流程实例:对流程定义的每次实例化会生成一个流程实例,是动态的,是有状态的
- 任务实例:流程实例DAG中每个Task称为任务实例,是动态的,是有状态的
流程定义
创建工作流
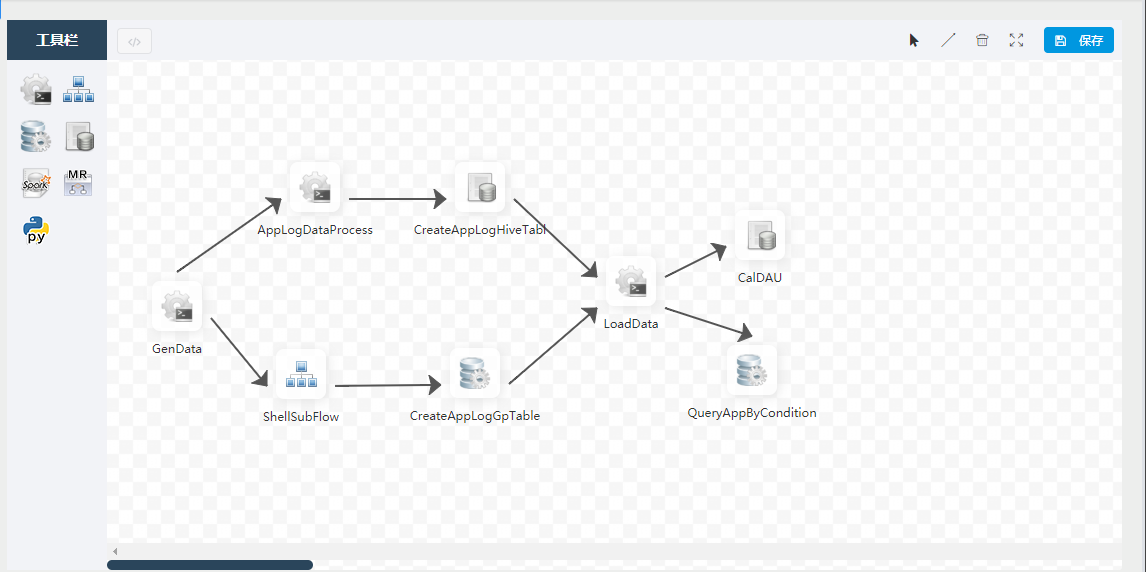
- 左侧工具栏 => 是目前调度支持的任务类型,当前调度支持SHELL、子流程、存储过程、SQL、MR、Spark和Python七种任务类型
- 右上角图标 => 分别是拖动节点和选中项、选择线条连线、删除选中的线或节点、全屏和流程定义保持,其主要功能是DAG的绘制所用
创建 SHELL节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
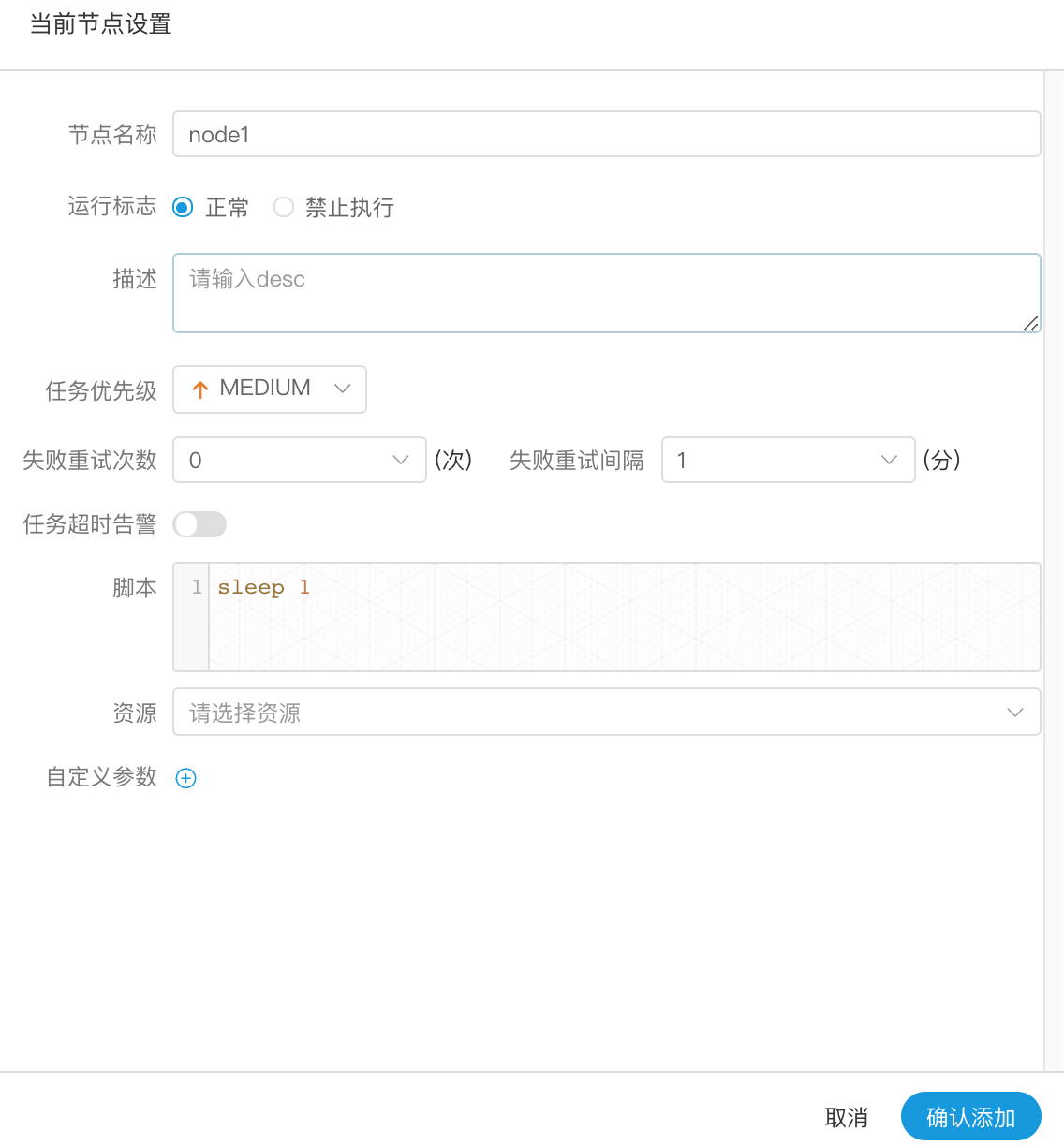
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 脚本:用户开发的SHELL程序
- 资源:是指脚本中需要调用的资源文件列表
- 自定义参数:是SHELL局部的用户自定义参数,会替换脚本中以${变量}的内容
创建 子流程 节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
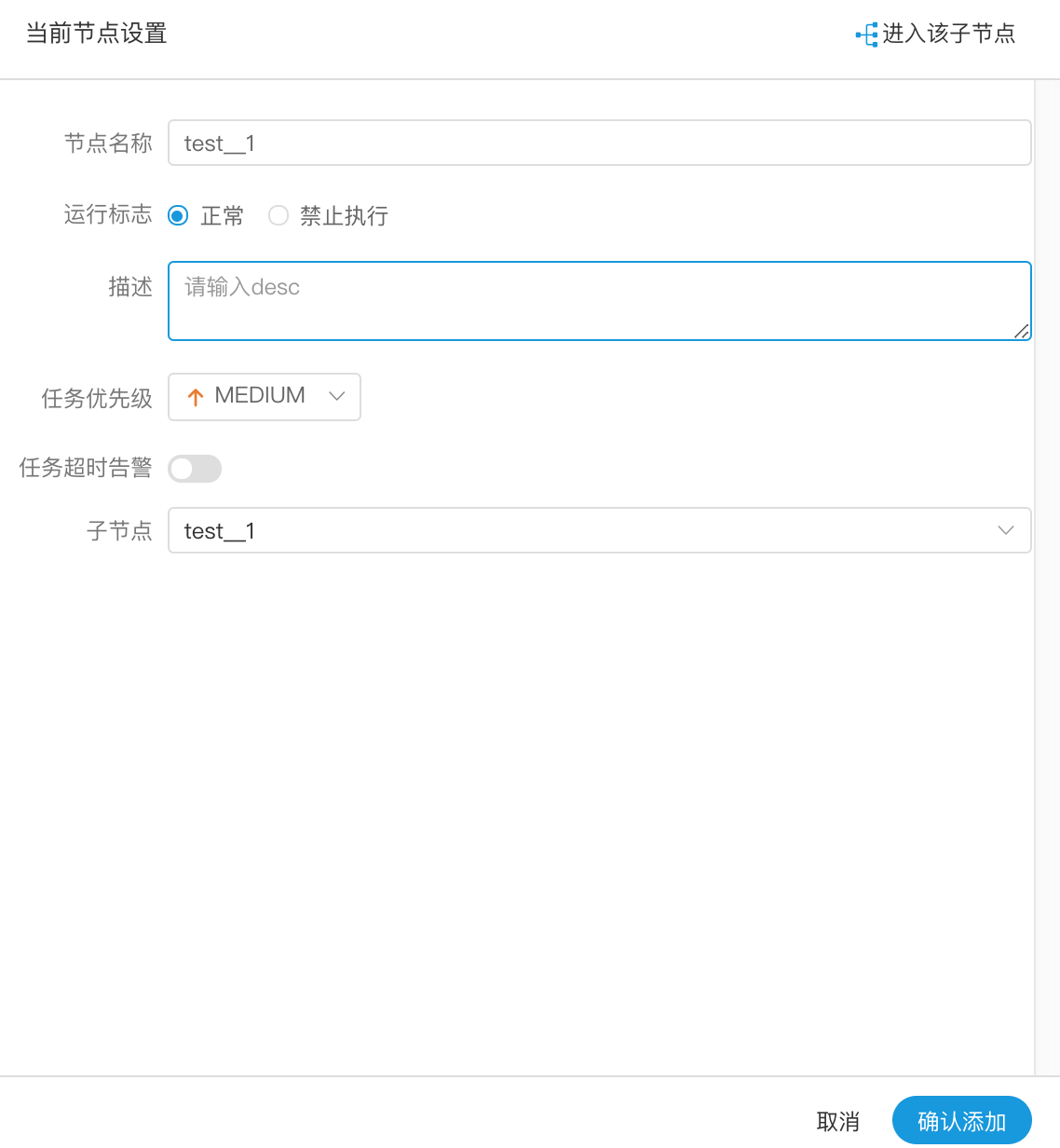
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 子节点:是选择子流程的流程定义,右上角进入该子节点可以跳转到所选子流程的流程定义
创建 存储过程 节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
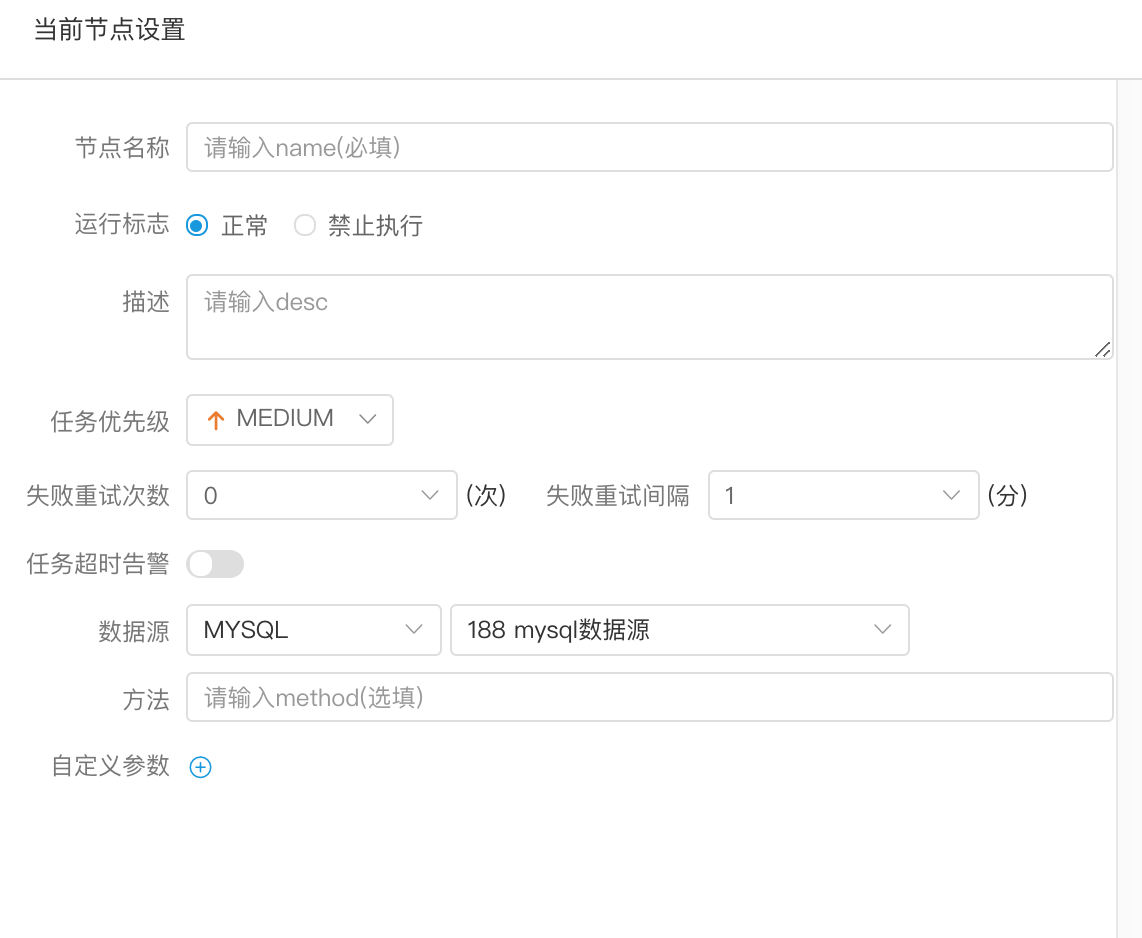
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 数据源:存储过程的数据源类型支持MySQL和POSTGRESQL两种,选择对应的数据源
- 方法:是存储过程的方法名称
- 自定义参数:存储过程的自定义参数类型支持IN、OUT两种,数据类型支持VARCHAR、INTEGER、LONG、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP、BOOLEAN九种数据类型
创建 SQL 节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
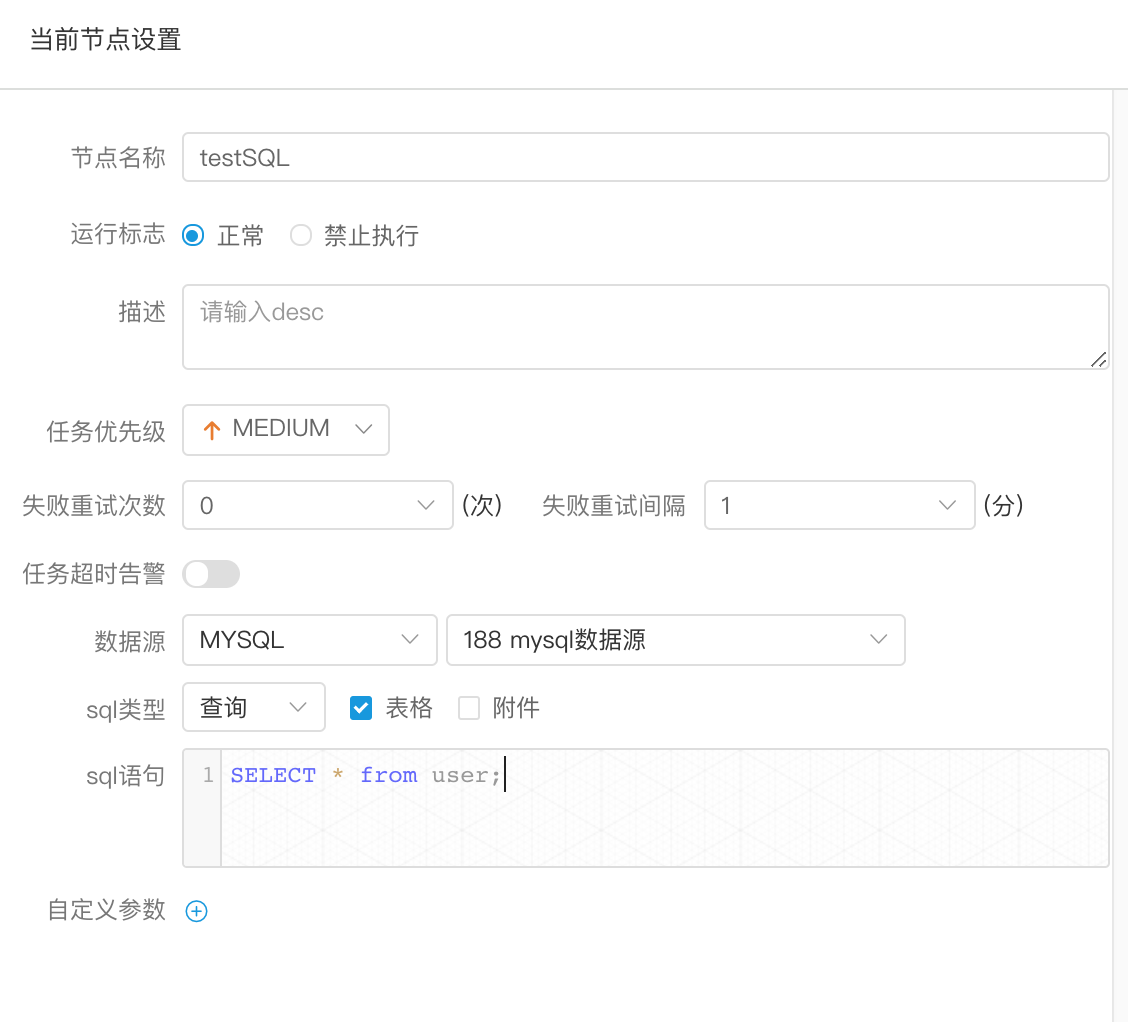
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 数据源:SQL数据源支持MySQL、POSTGRESQL、HIVE和Spark四中数据源类型,选择对应的数据源
- sql类型:支持查询和非查询两种,查询是select类型的查询,是有结果集返回的,可以指定邮件通知为表格、附件或表格附件三种模板。非查询是没有结果集返回的,是针对update、delete、insert三种类型的操作
- sql参数:输入参数格式为key1=value1;key2=value2…
- sql语句:SQL语句
- UDF函数:对于HIVE类型的数据源,可以引用资源中心中创建的UDF函数,其他类型的数据源暂不支持UDF函数
- 自定义参数:SQL任务类型自定义参数类型和数据类型同存储过程任务类型一样。区别在于SQL任务类型自定义参数会替换sql语句中${变量},而存储过程是自定义参数顺序的给方法设置值
创建 MR 节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
(1) JAVA程序
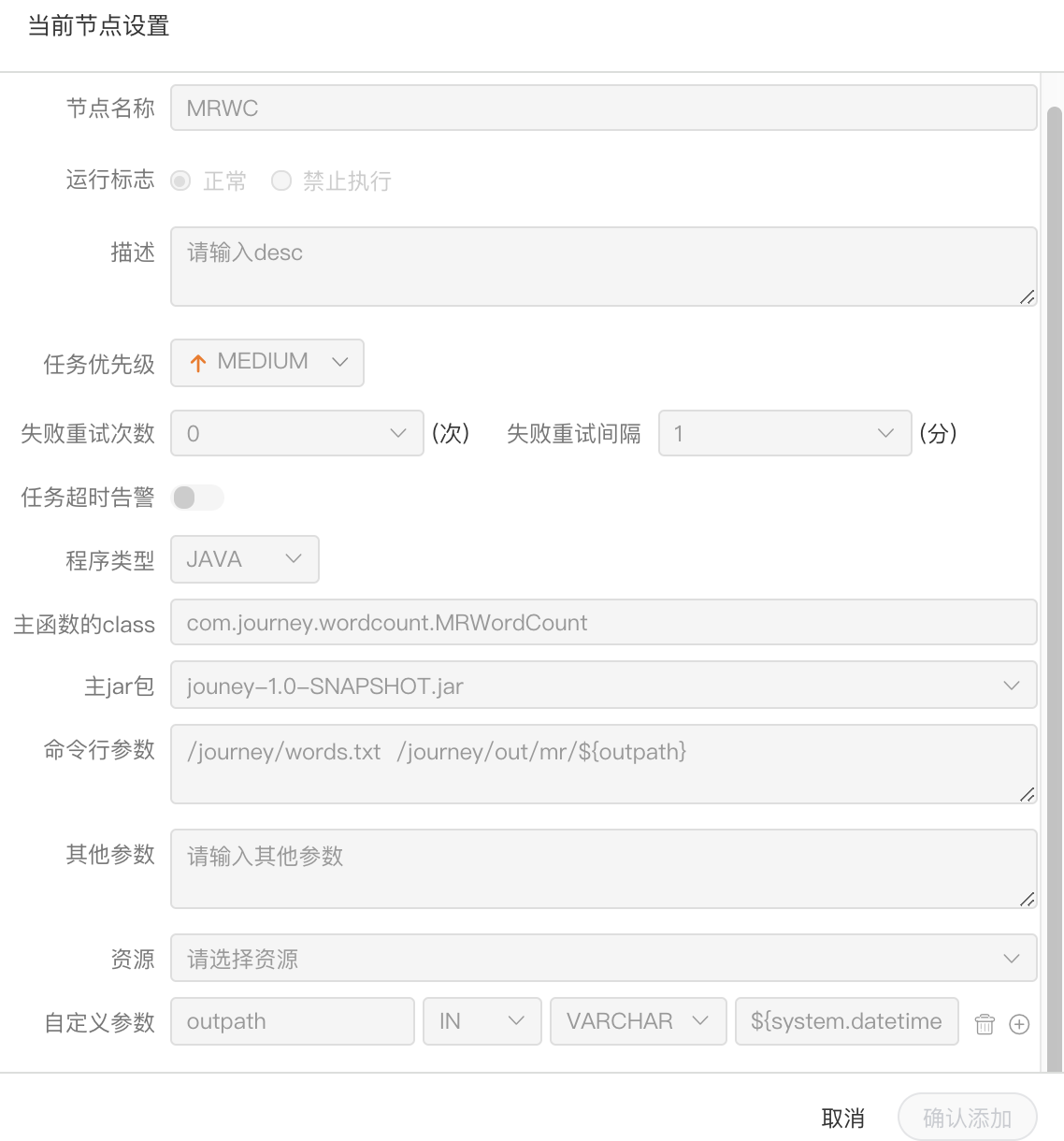
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 主函数的class:是MR程序的入口Main Class的全路径
- 程序类型:选择JAVA语言
- 主jar包:是MR的jar包
- 命令行参数:是设置MR程序的输入参数,支持自定义参数变量的替换
- 其他参数:支持 –D、-files、-libjars、-archives格式
- 资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
(2) Python程序
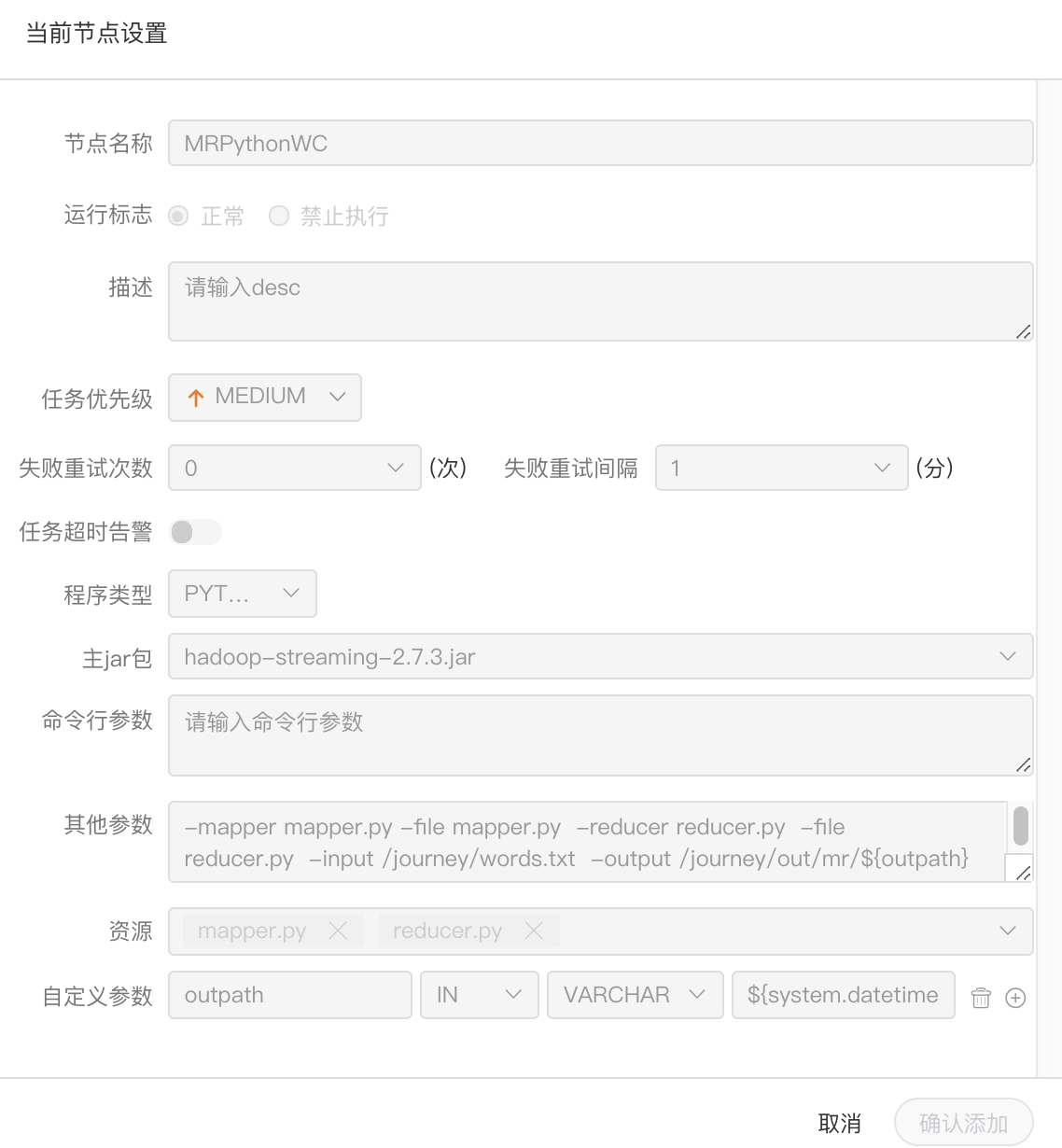
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 程序类型:选择Python语言
- 主jar包:是运行MR的Python jar包
- 其他参数:支持 –D、-mapper、-reducer、-input -output格式,这里可以设置用户自定义参数的输入,比如:
- -mapper "mapper.py 1" -file mapper.py -reducer reducer.py -file reducer.py –input /journey/words.txt -output /journey/out/mr/${currentTimeMillis}
- 其中 -mapper 后的 mapper.py 1是两个参数,第一个参数是mapper.py,第二个参数是1
- 资源: 如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
创建 Spark 节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
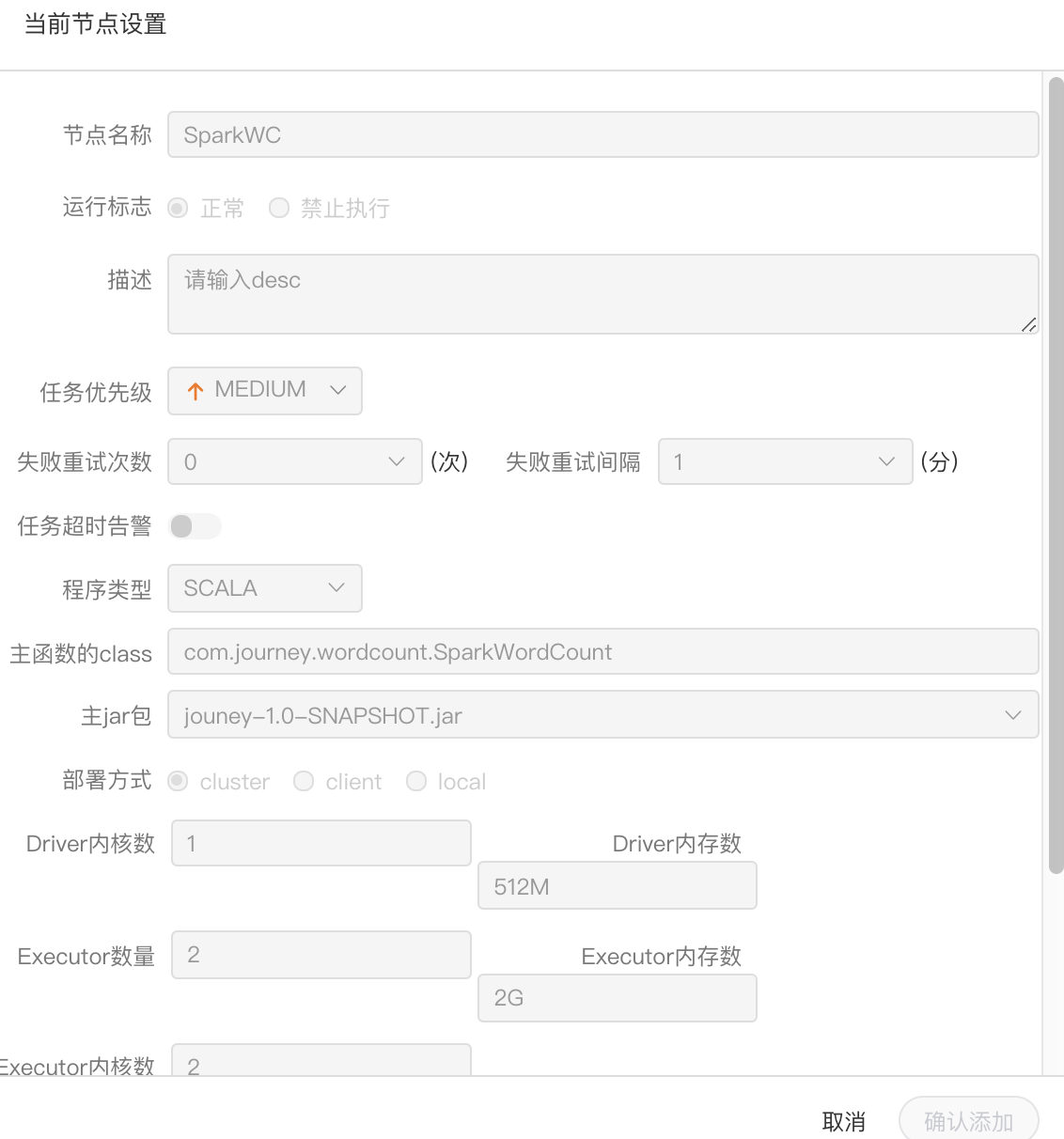
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 程序类型:支持JAVA、Scala和Python三种语言
- 主函数的class:是Spark程序的入口Main Class的全路径
- 主jar包:是Spark的jar包
- 部署方式:支持yarn-cluster、yarn-client、和local三种模式
- Driver内核数:可以设置Driver内核数及内存数
- Executor数量:可以设置Executor数量、Executor内存数和Executor内核数
- 命令行参数:是设置Spark程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、--files、--archives、--conf格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是MR局部的用户自定义参数,会替换脚本中以${变量}的内容
注意:JAVA和Scala只是用来标识,没有区别,如果是Python开发的Spark则没有主函数的class,其他都是一样
创建 Python 节点
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
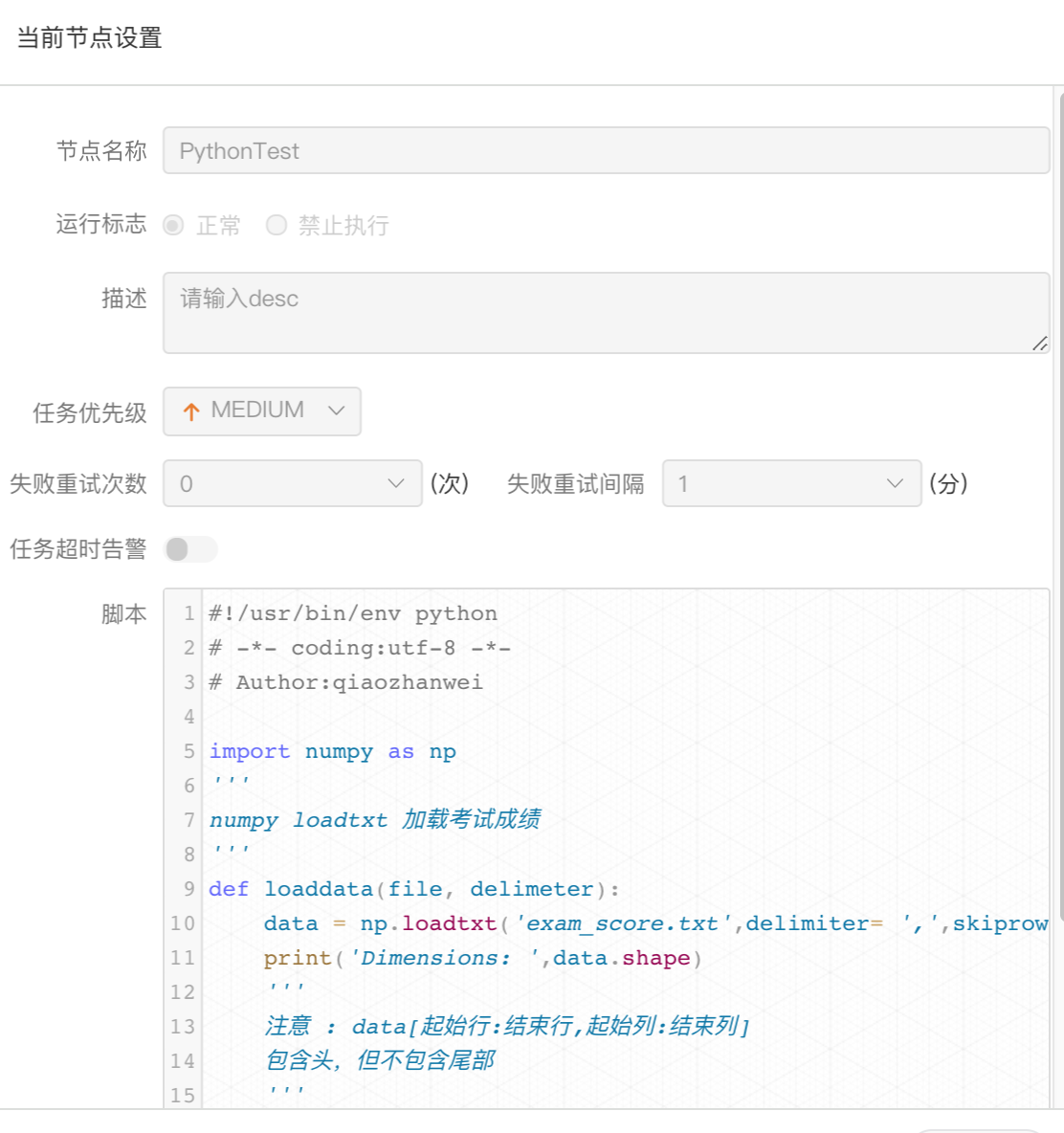
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 脚本:用户开发的Python程序
- 资源:是指脚本中需要调用的资源文件列表
- 自定义参数:是Python局部的用户自定义参数,会替换脚本中以${变量}的内容
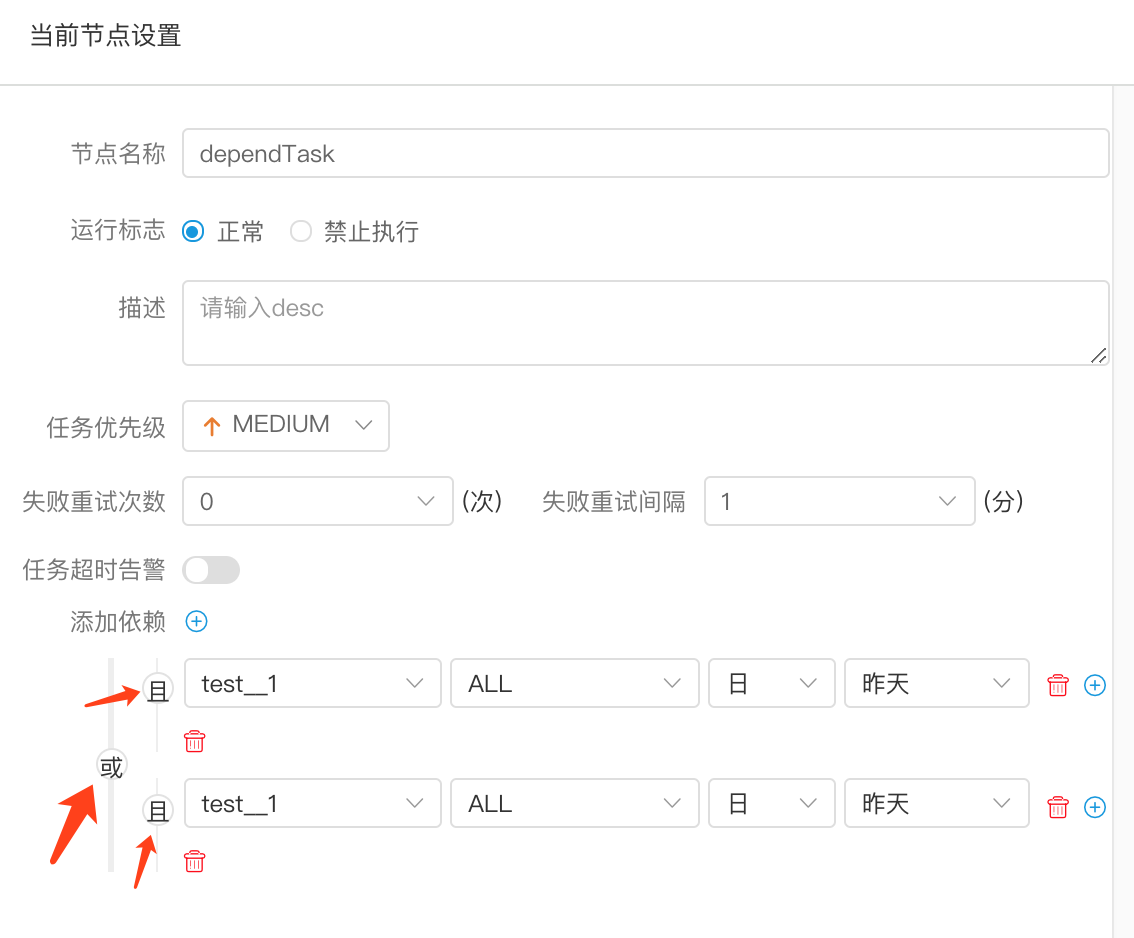
创建 依赖 节点
> 任务依赖分为水平依赖和垂直依赖
-
水平依赖就是指DAG图的有向依赖,是同一个流程实例任务节点的前驱,后继之间的依赖关系
-
垂直依赖是流程实例之间的任务依赖,基于定时的依赖。
> 拖动工具栏中的任务节点到画板中,双击任务节点,如下图:
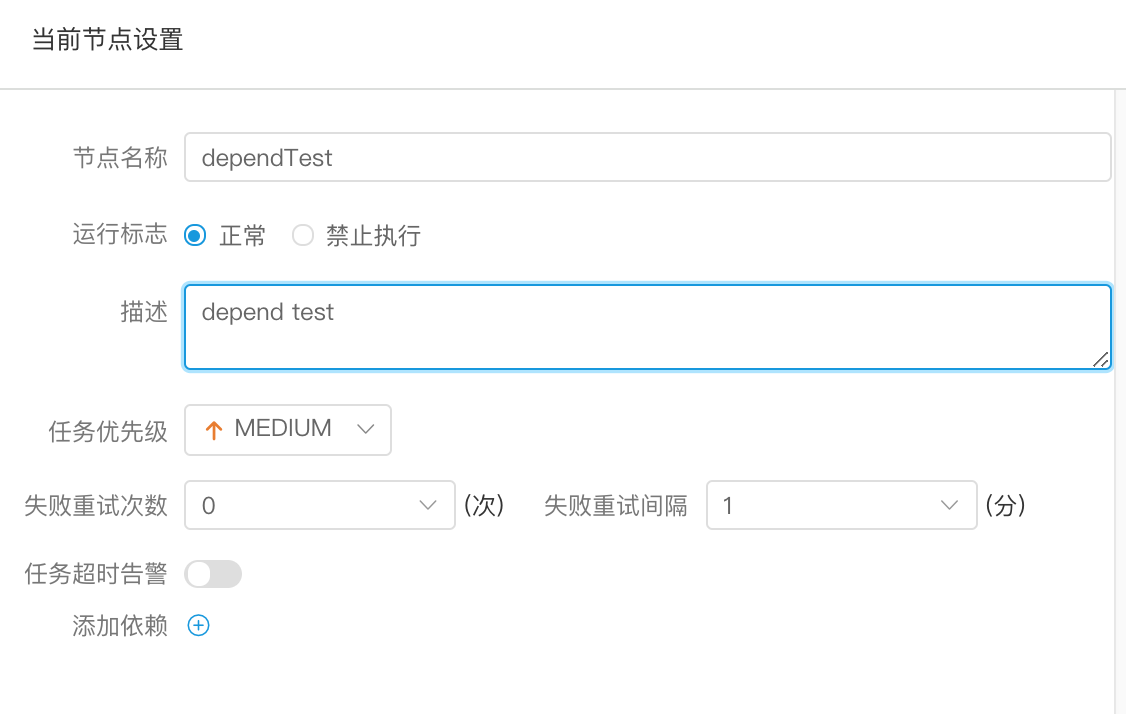
- 节点名称:一个流程定义中的节点名称是唯一的
- 运行标志:标识这个节点是否能正常调度
- 描述信息:描述该节点的功能
- 失败重试次数:任务失败重新提交的次数,支持下拉和手填
- 失败重试间隔:任务失败重新提交任务的时间间隔,支持下拉和手填
- 任务依赖:增加依赖条件,选择依赖流程定义、节点名称(默认为全部节点)、依赖周期、依赖时间点
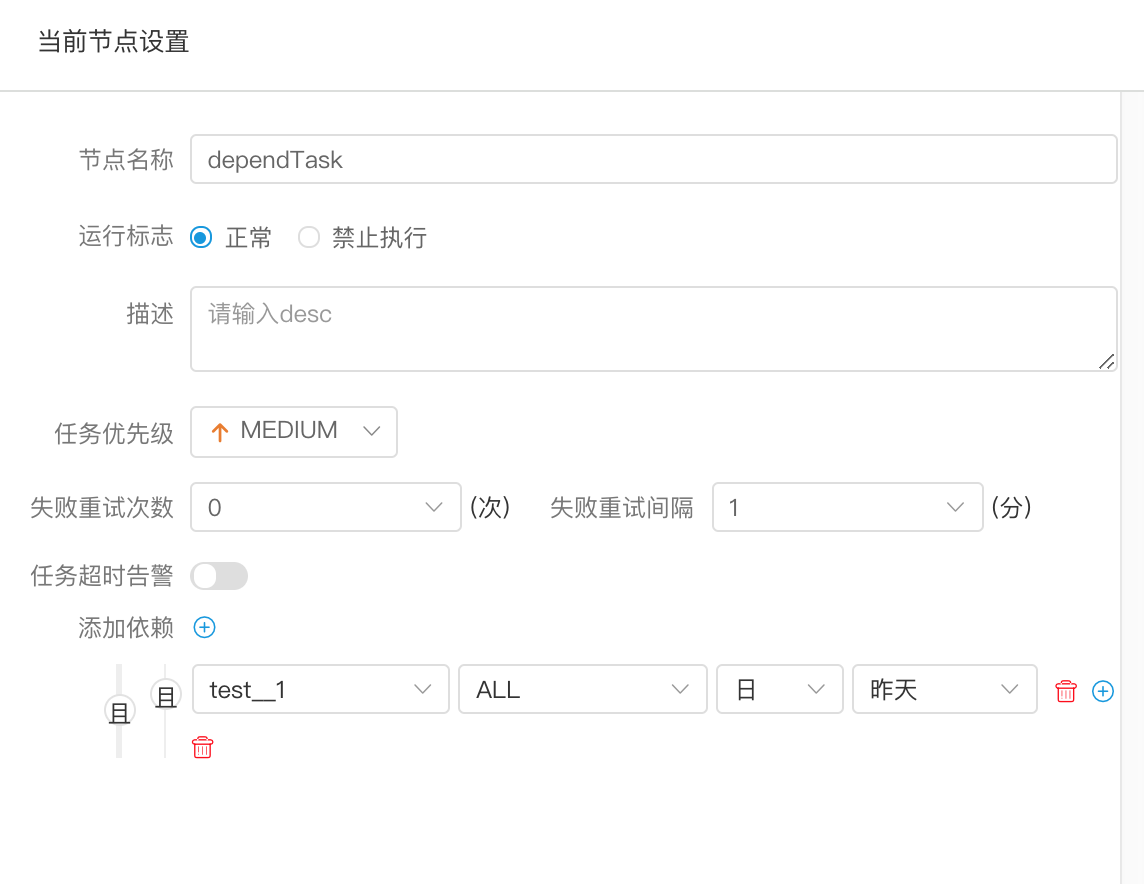
- 选择多个依赖条件之间的关系:或、且
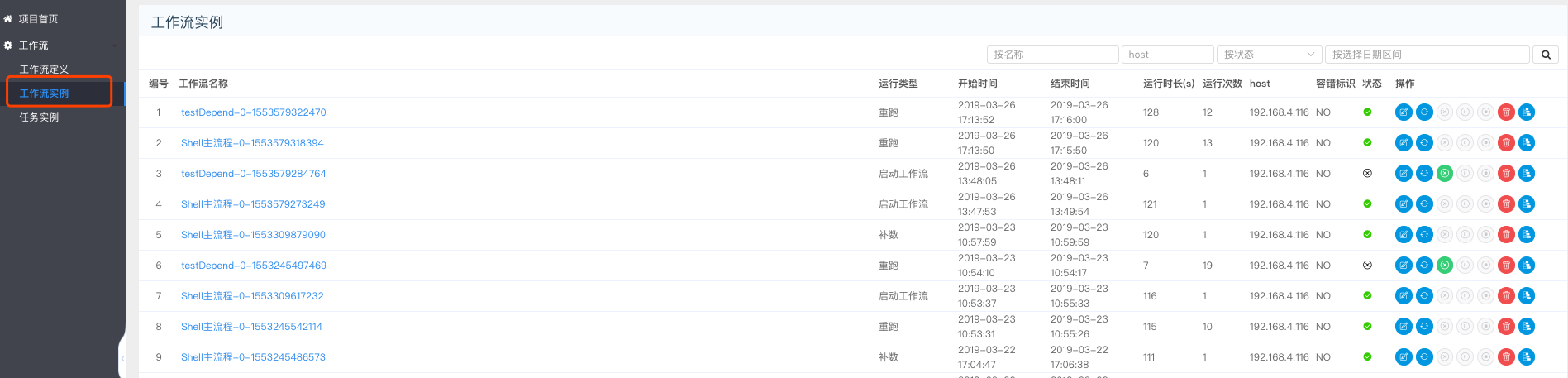
流程实例列表
> 流程实例列表页是可以显示所有本项目下所有流程实例的列表,并有对流程实例进行名称、状态、时间等字段的筛选功能。 > 通过列表页可以直接对某一个流程实例进行编辑、重跑、恢复失败、暂停、停止、恢复暂停、删除、查看甘特图等操作.
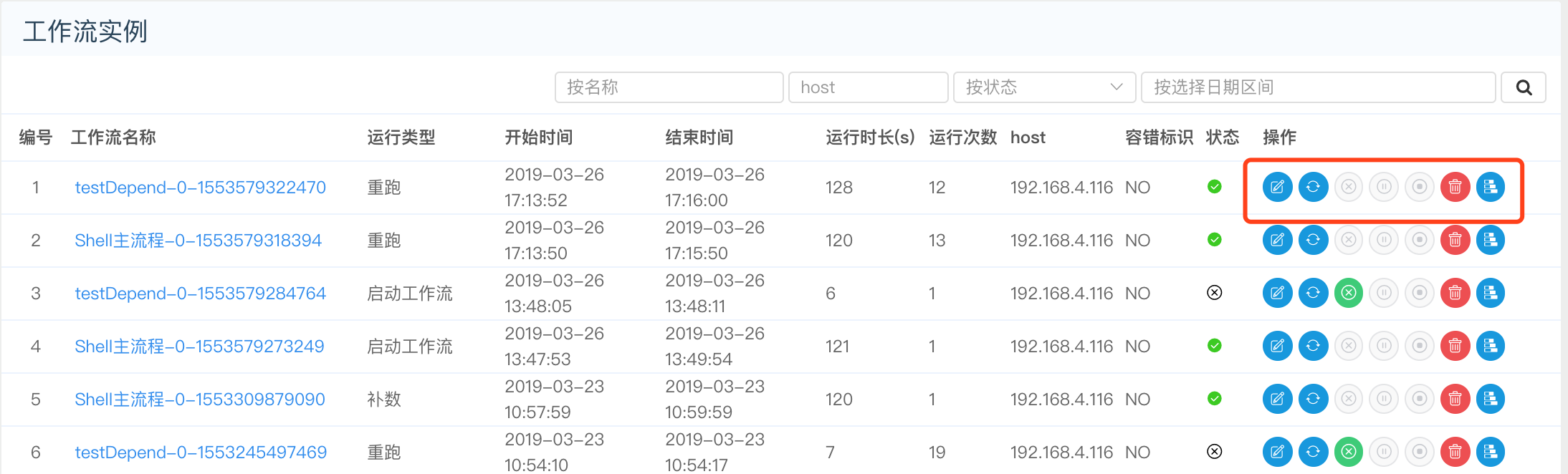
- 编辑功能: 对已经完成的流程实例,点击编辑按钮,可以对其编辑,如图:
- 查看流程实例运行变量
- 点击隐藏按钮,查看流程实例运行变量。如下图:

-
点击变量是对变量的复制
-
点击"重跑",可以对已经完成的流程实例进行重新运行操作,如图:
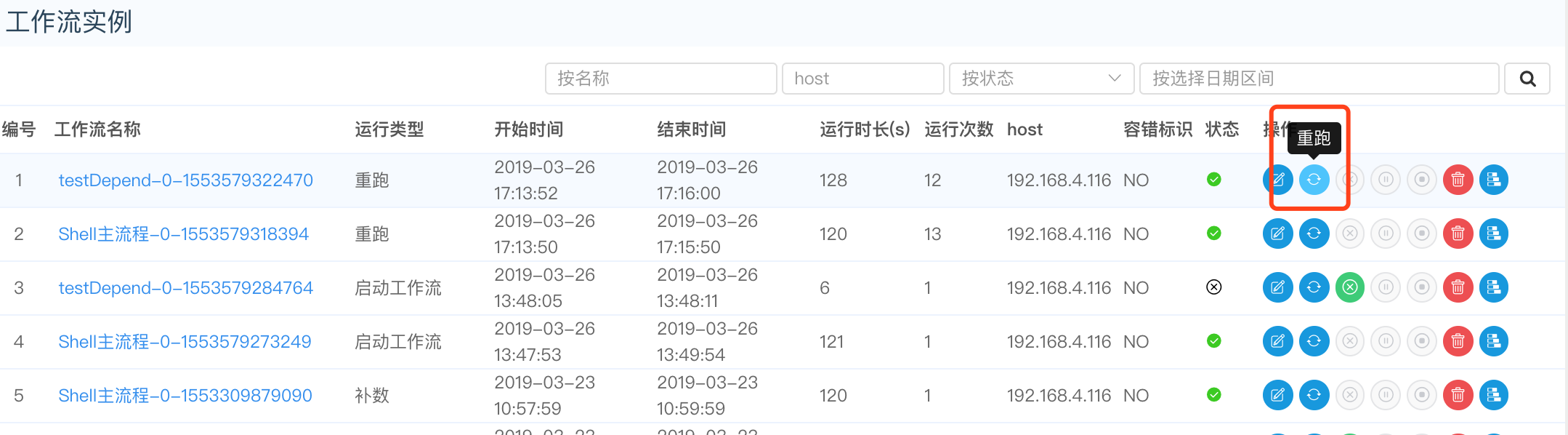
- 点击"恢复失败", 可以对失败的流程进行恢复,直接从失败的任务节点开始运行。如图:
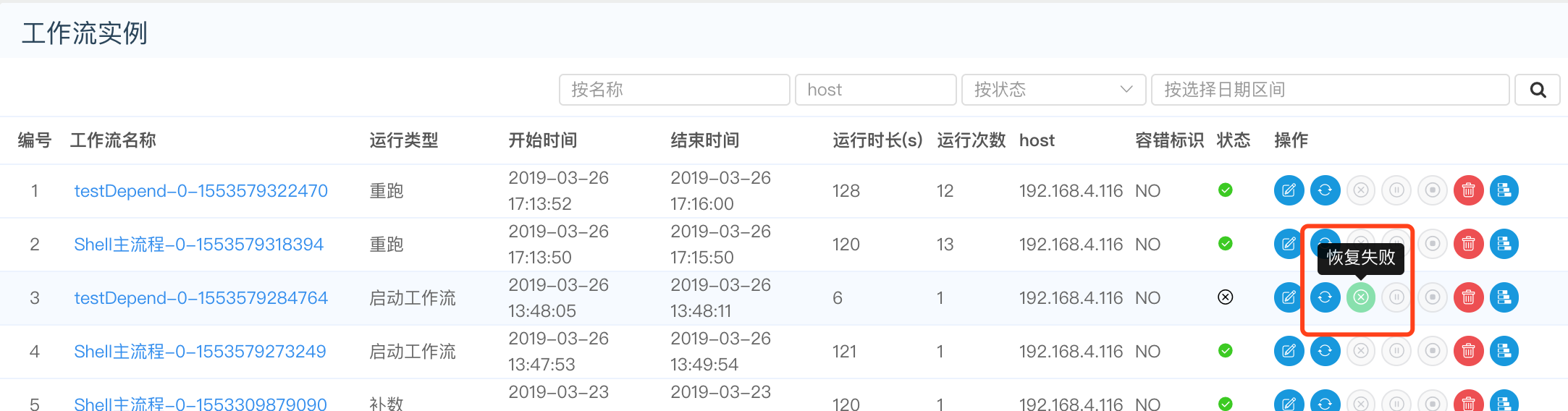
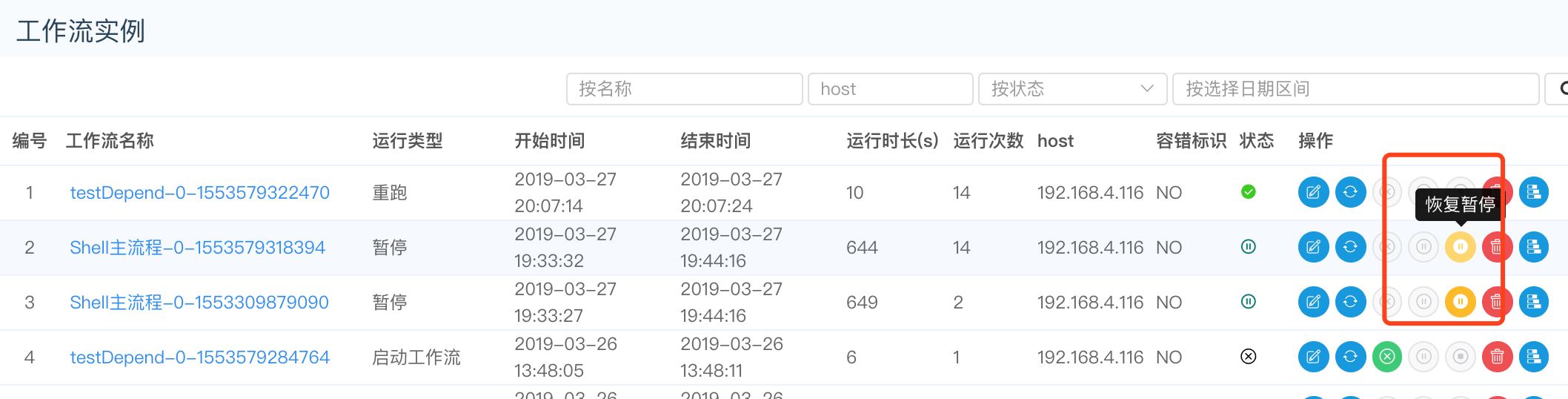
- 点击"暂停", 可以对正在运行的流程进行暂停操作,如图:
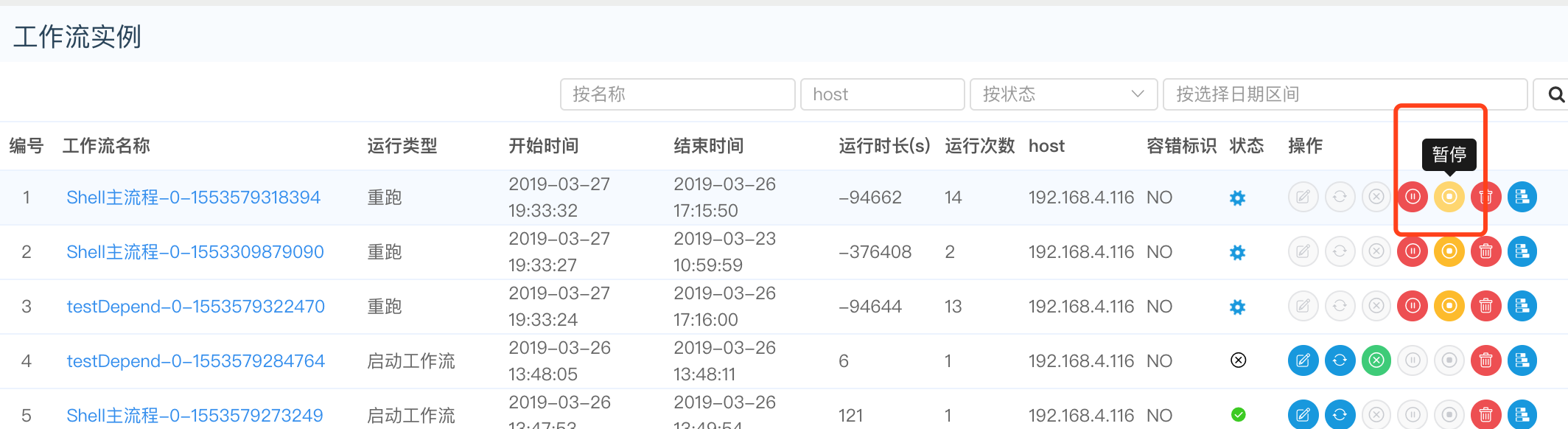
- 点击"停止",可以对正在运行的流程进行停止操作,如图:
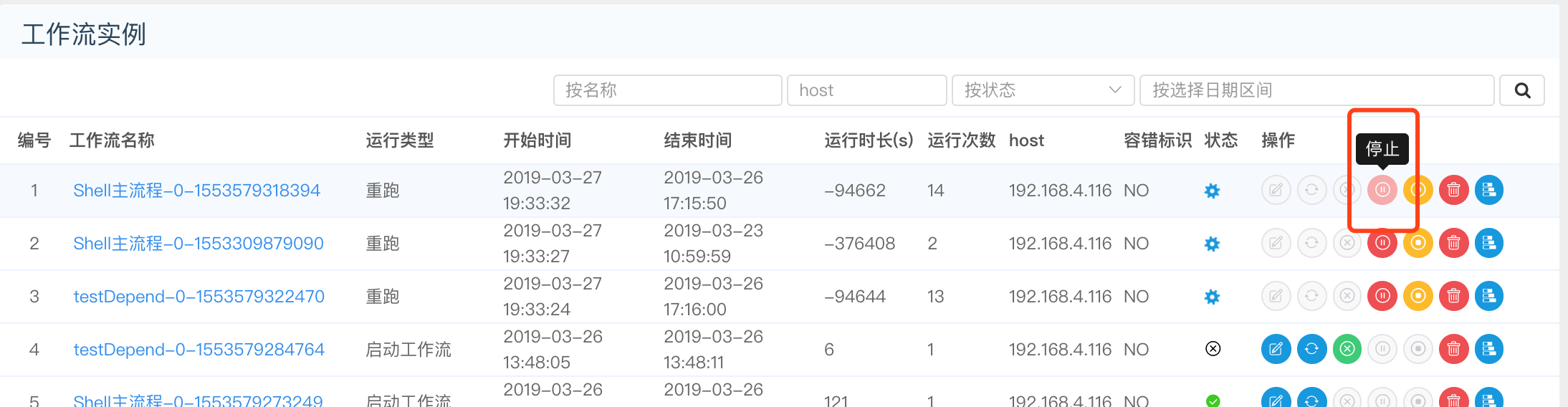
- 点击"恢复暂停",可以对暂停的流程恢复,直接从暂停的节点开始运行,如图:
-
删除 > 删除流程实例及流程实例下的任务实例
-
Gantt
> Gantt图纵轴是某个流程实例下的任务实例的拓扑排序,横轴是任务实例的运行时间

任务实例列表页
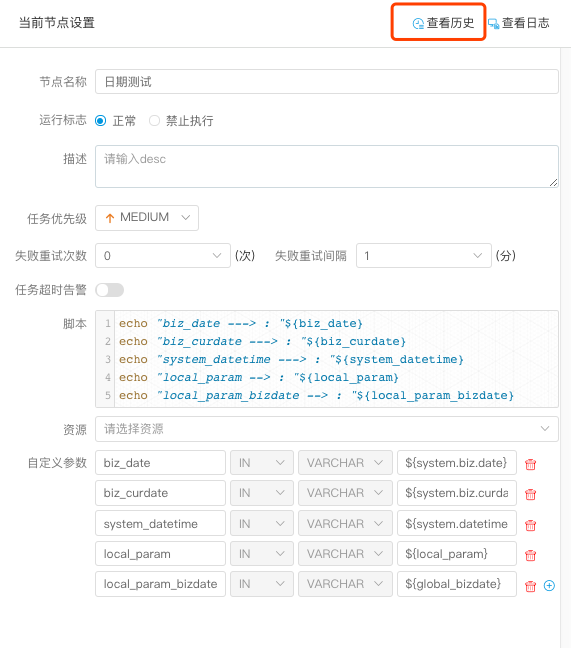
- 点击任务实例节点,点击 查看历史,可以查看该流程实例运行的该任务实例列表
查看日志
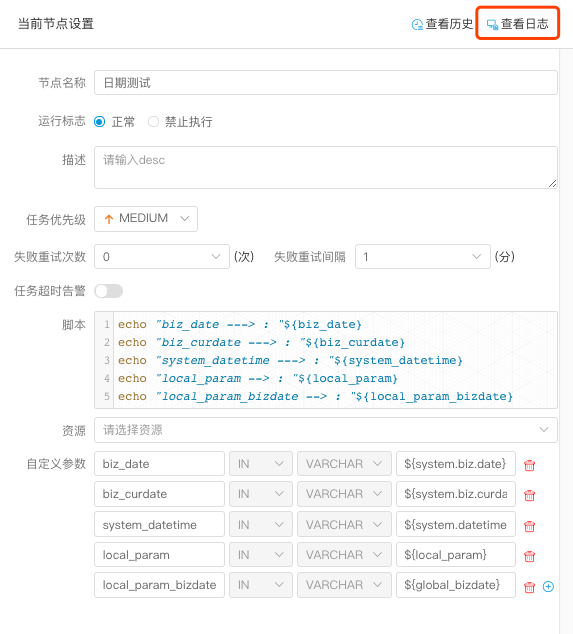
- 点击任务实例节点,点击 查看日志,可以查看该任务实例运行的日志,如下图:
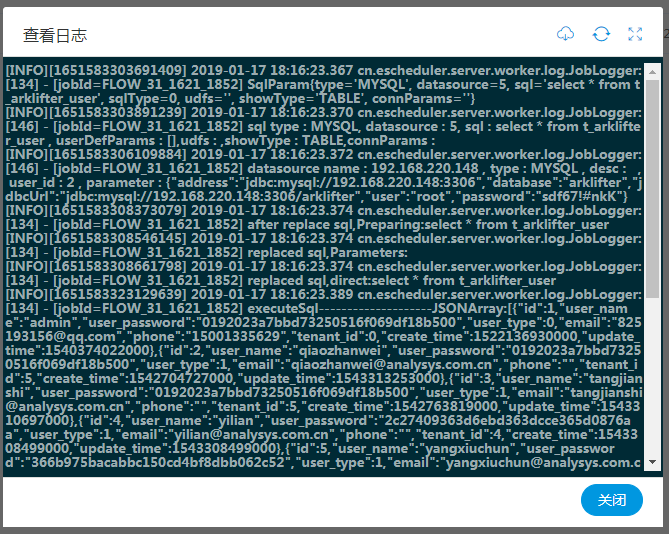
- 右上角是下载日志、刷新日志和放大/缩小按钮
- 注意:日志查看是分片的查看,上下滚动查看
任务实例
> 任务实例是流程实例任务节点的列表
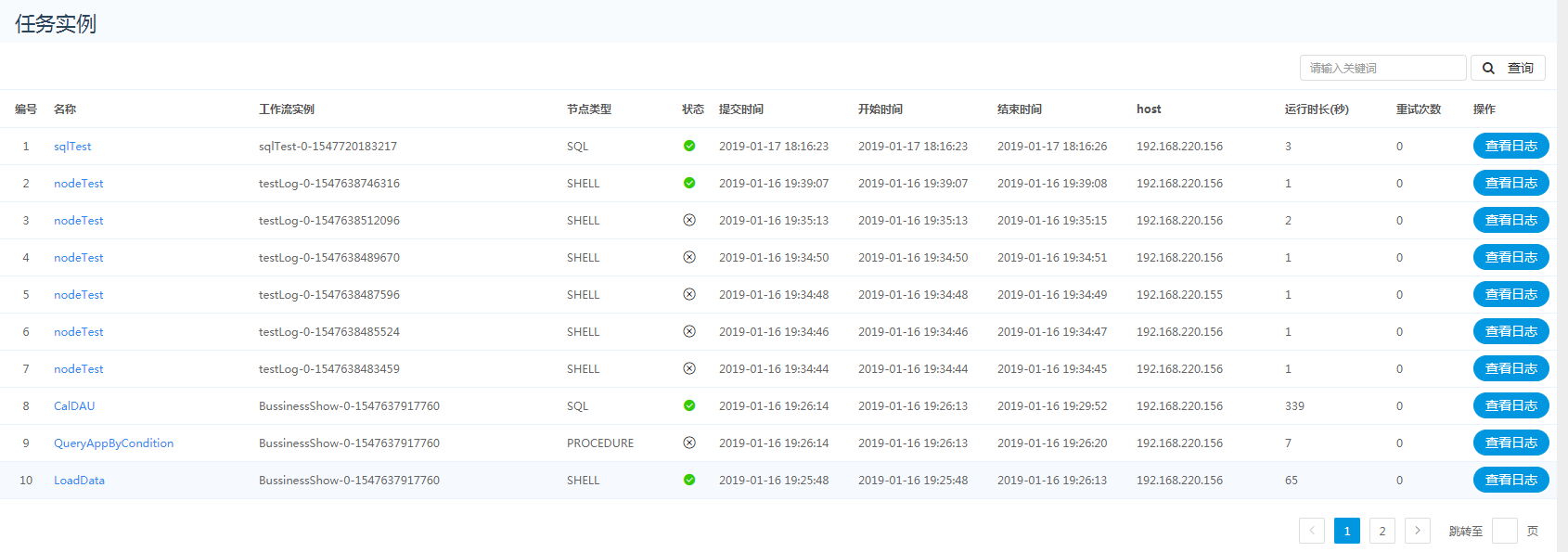
两种方式查看任务实例:
- 第一种是通过流程实例任务节点 查看历史,这时查看的是此流程实例的任务实例 重跑的列表
- 第二种是通过点击 流程实例 导航栏,调转到流程实例列表,这时查看的是所有流程实例的任务实例列表
> 查看日志:点击 查看日志 按钮,可下载和查看日志
系统参数
系统参数
| 变量 | 含义 |
|---|---|
| ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 |
时间自定义参数
> 支持代码中自定义变量名,声明方式:${变量名}。可以是引用 "系统参数" 或指定 "常量"。
> 我们定义这种基准变量为 $[...] 格式的,$[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
> 也可以这样:
- 后 N 年:$[add_months(yyyyMMdd,12*N)]
- 前 N 年:$[add_months(yyyyMMdd,-12*N)]
- 后 N 月:$[add_months(yyyyMMdd,N)]
- 前 N 月:$[add_months(yyyyMMdd,-N)]
- 后 N 周:$[yyyyMMdd+7*N]
- 前 N 周:$[yyyyMMdd-7*N]
- 后 N 天:$[yyyyMMdd+N]
- 前 N 天:$[yyyyMMdd-N]
- 后 N 小时:$[HHmmss+N/24]
- 前 N 小时:$[HHmmss-N/24]
- 后 N 分钟:$[HHmmss+N/24/60]
- 前 N 分钟:$[HHmmss-N/24/60]
用户自定义参数
> 用户自定义参数分为全局参数和局部参数。全局参数是保存流程定义和流程实例的时候传递的全局参数,全局参数可以在整个流程中的任何一个任务节点的局部参数引用。
> 例如:
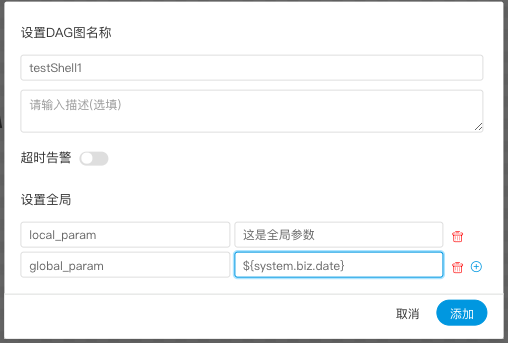
- global_bizdate为全局参数,引用的是系统参数。
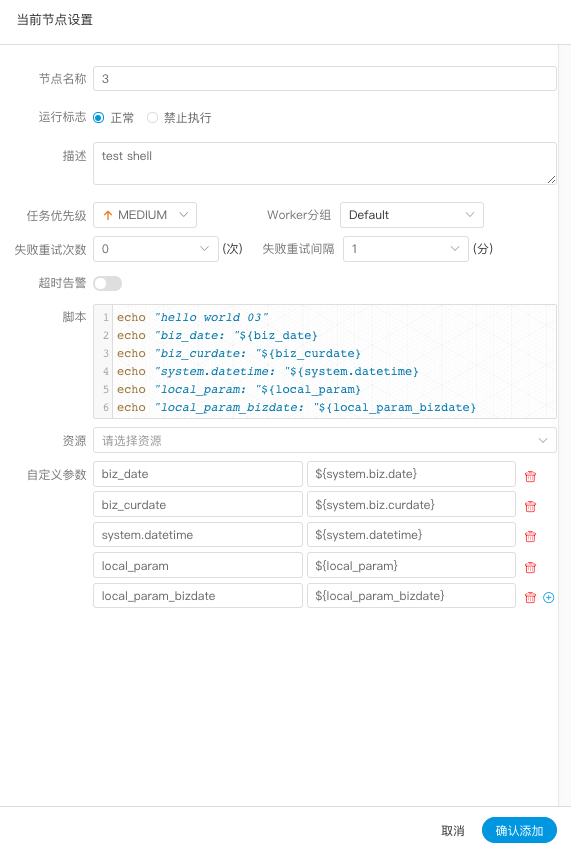
- 任务中local_param_bizdate通过${global_bizdate}来引用全局参数,对于脚本可以通过${local_param_bizdate}来引用变量local_param_bizdate的值,或通过JDBC直接将local_param_bizdate的值set进去