Python3爬虫(五):通过抓包分析实现P站(Pixiv)图片网站的排行榜下载(附带多线程下载的实现)(干货系列)
运行平台:Windows
Python版本:Python3.8.2
IDE:PyCharm2019.3.3
转载请注明作者和出处: https://blog.csdn.net/hjj19991111/article/details/105191395
一、前言
在爬取之前,博主翻看了一些网上的教程,发现有些爬取Pixiv的教程是要模拟登陆的,为什么呢?
其实需要模拟登陆是因为他们爬取的个人中心的首页中的推荐内容,熟悉这个网站的都知道,首页推荐的图片质量都不是很高,即使登陆了,用搜索框去搜索相关标签的图片,没有高级会员,图片质量也不高,所以作为平常人的我们,一般只是看看排行榜上的作品。
那我们就明确了自己的目标——爬取日排行榜、周排行榜以及月排行榜中的内容,本篇教程极其详细,字数较多,之前教程中讲过的内容不再阐述,要是有不理解的地方之前教程中都有。
准备工作:
- 导入requests包和BeautifulSoup4包,没有的可以看博主之前的教程
接下来我们就可是一步步分析吧!
二、实战开始
1.分析排行榜网站链接
我们首先点击P站首页中的的排行榜链接:
https://www.pixiv.net/ranking.php
这个网址并看不出来什么,我们看看页面:
这是P站默认的排行榜,默认的条件就是综合今日排行榜
这里我们主要针对的是插画排行榜的爬取,因为动图质量不高,漫画图片数量太多,而且谁上P站是看漫画和小说的呀!
点击插画,然后记得再分别点击一下今日、本周、本月,我们的网址就变成了这些:
今日:https://www.pixiv.net/ranking.php?mode=daily&content=illust
本周:https://www.pixiv.net/ranking.php?mode=weekly&content=illust
本月:https://www.pixiv.net/ranking.php?mode=monthly&content=illust
这时候,我们就可以发现?后面是对排行榜条件的筛选mode=后面是对于日、周、月排行榜的选择,而content=后面是限定插画排行榜
那怎么爬取之前的排行榜呢,我们在日排行榜点击前一天,可以发现网址变成了:
https://www.pixiv.net/ranking.php?mode=daily&content=illust&date=20200327
这里就很好理解了:data=中跟着的是排行榜的日期
2.分析图片网站链接
我们随便点开几张图片,链接如下:
https://www.pixiv.net/artworks/80372785
https://www.pixiv.net/artworks/80383799
这里也很好理解,图片网页的URL是https://www.pixiv.net/artworks/+图片的id
有了这些基本的认识,我们首先需要来爬取今日排行榜的图片的id
3.爬取排行榜中图片id
先导入我们需要的包,并定义一个类叫Pixiv类
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
class Pixiv():
def __init__(self):
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh',
}
self.daily_url = 'https://www.pixiv.net/ranking.php?mode=daily&content=illust'
def main(self):
if __name__ == "__main__":
P = Pixiv()
P.main()
首先我们先尝试通过requests的post来获取网页内容试试:
def get_id(self):
rs = requests.get(self.daily_url, header=self.header)
rs.encoding = "utf-8"
bs = BeautifulSoup(rs.text, "html5lib")
print(bs)
def main(self):
self.get_id()
这里输出bs的值结果如下:

这个结果有点长,但是仔细观察我们能发现,在解析后的缩进中并没有明显看出那些图片的链接
那么问题来了,我们的想要的链接在哪里呢?其实细品一下,BeautifulSoup转换后的html网页,有一句长度很长的句子,在倒数十几行左右,开头是这个样子的:
后面跟着一个
data-id的属性
那我们是否可以通过bs去筛选出其中的带有data-id的ranking-item,补全get_id()函数:
def get_id(self):
rs = requests.get(self.daily_url, header=self.header)
rs.encoding = "utf-8"
bs = BeautifulSoup(rs.text, "html5lib")
print(bs)
sc_l = bs.select('.ranking-item')
self.url_id = []
for sc in sc_l:
self.url_id.append(sc['data-id'])
print(self.url_id)
输出结果:
这就是我们所爬取到的排行榜中图片id
这里有一个问题,我也是爬取月排行榜的时候才想到的
就是这里的id仅仅是排行前50的图片id,而当我们往下拉的时候可以看到这个排行榜的图片可以一直到100、200甚至更多,那么问题来了,怎么爬取排行50之后的图片id呢?
一种方法是使用Selenium来模拟鼠标滚轮滑动事件
另一种就是我们要使用的对这个网页进行抓包分析
4.抓包爬取图片id
一般来说,这种网站都是动态网页,而排行榜必然是网站向服务器发送请求,返回的json数据信息,然后用json信息去构建网页元素
明白了这一点,我们需要对于这个网页进行抓包分析
使用浏览器自带的开发者工具(按F12打开),点击network

点击左边黑色的清除原来的数据,然后我们刷新网页,network中多出了很多数据,有图片,有css文件,json文件等等,将数据格式切换到查看js格式的数据:
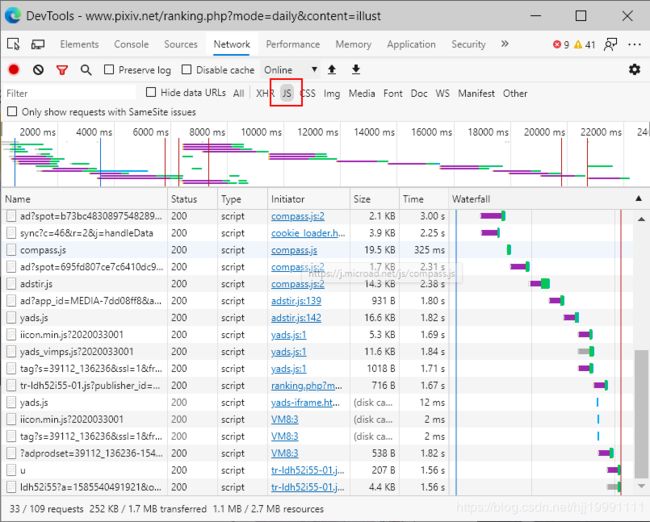
随便点击一个左侧的一个数据,然后将试图切换到Preview,逐一去查看每个数据,但是好像并没有我们想要的带有图片id的json数据,同理查看XHR中的数据,好像也没有

按Ctrl+F,调出查找框,搜索排行榜第一的图片id,好像也搜不到什么什么:

我找了很久都没有找到,就在我要放弃的时候,忽然想到,当我们模拟下拉的时候,一直拖动到排行榜第51名时,那个信息也是动态获取的,是否可以从中寻找突破口呢?
先将network中的数据给清除,然后一直往下拉到排行第51的图片,接着搜索第51的图片id:

发现有一个XHR文件,点开它,这不就是我们想要的数据吗,这个数据包中每个列表元素中的illust_id就是我们需要的

那么问题来了,怎么通过爬虫去获取这个数据呢?
将视图切换到Headers:

对这个请求链接分析一波,这个链接的前半部分异常的熟悉,就是后面的:
&p=2&format=json
我们大胆猜测,p=后接的是否指第2批的50个数据,而后面的format=json应该是指返回的数据格式是json,我们通过代码进行尝试,重写get_id()函数,并优化一下整个Pixiv类:
class Pixiv():
# 初始化类
def __init__(self, p, b):
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh',
}
self.daily_url = 'https://www.pixiv.net/ranking.php?mode=daily&content=illust'
self.week_url = 'https://www.pixiv.net/ranking.php?mode=weekly&content=illust'
self.month_url = 'https://www.pixiv.net/ranking.php?mode=monthly&content=illust'
# 下载的排行榜模式
self.p = p
# 下载的图片数量
self.b = b
# 获取图片id
def get_id(self):
# 每50个图片id进行分类
if self.b/50 == int(self.b/50):
tl = int(self.b/50)
else:
tl = int(self.b/50) + 1
url_list = []
# 通过返回的json数据抓取所有图片的数据
for t in range(tl):
self.id_url = self.url + '&p=' + str(t+1) + '&format=json'
rs = requests.get(self.id_url, headers=self.header).json()
url_list += rs['contents']
# Pixiv类中的主函数
def main(self):
if self.p == '1':
self.url = self.daily_url
if self.p == '2':
self.url = self.week_url
if self.p == '3':
self.url = self.month_url
self.get_id()
if __name__ == "__main__":
P = Pixiv('1', 120)
P.main()
这样就成功得到我们的json字典数据中的contents的键值了,接着对于每个数据获取其中的illust_id:
def get_id(self):
# 每50个图片id进行分类
if self.b/50 == int(self.b/50):
tl = int(self.b/50)
else:
tl = int(self.b/50) + 1
url_list = []
# 通过返回的json数据抓取所有图片的数据
for t in range(tl):
self.id_url = self.url + '&p=' + str(t+1) + '&format=json'
rs = requests.get(self.id_url, headers=self.header).json()
url_list += rs['contents']
# 对每一个id进行编号,采用二维数组
num = 1
self.url_id = []
for u in url_list:
self.url_id.append([num, str(u['illust_id'])])
num = num + 1
print(self.url_id)
得到结果:
这里可能有人会问,明明就已经有图片的下载链接了,为啥还要去还要进行后面的操作呢?
当然是因为这个图片链接是略缩图,图片进行了压缩,不是原图,而且这样子也获取不到有多张图片的其他图片。
作为对于图片有高品质追求的我们,得到了id,接下来就是获取图片的下载链接了
5.分析单个图片的链接
同样从分析网页链接出发,写出代码:
def get_durl(self):
pic_url = 'https://www.pixiv.net/artworks/' + '80392830'
rs = requests.get(pic_url, headers=self.header)
rs.encoding = 'UTF-8'
bs = BeautifulSoup(rs.text, "html5lib")
print(bs)
代码的返回与排行榜页面的返回如出一辙:

但是我们在这个返回的页面中,并没有找到任何有用标签,甚至他的
标签中的内容就只有最后行那么一点,那怎么办呢?于是我又想到了我们的抓包大法!
调出开发者工具,开干:
历史总是惊人的相似,刚开始我们也没有发现任何有用的数据,但是当我们点击图片将图片放大出原图时,我们可以在Headers中看到图片的请求链接是这个:

那我们Ctrl+F调出搜索框输入这个时,发现:

这里需要点下最下面的{}将返回值格式化一下,看的更清楚
这行数据就是我们想要的,那么我忽然意识到,其实在python中的返回信息是有我们想要的原图链接的,于是添加代码:
def get_durl(self):
pic_url = 'https://www.pixiv.net/artworks/' + '80392830'
rs = requests.get(pic_url, headers=self.header)
rs.encoding = 'UTF-8'
bs = BeautifulSoup(rs.text, "html5lib")
this = bs.select('#meta-preload-data')[0]['content']
# 这里的'80392830'是这个图片的id
img_url = json.loads(this)['illust']['80392830']['urls']['original']
print(img_url)
上面的img_url就是图片的下载链接,如何下载并保存到文件,之前的教程中也有
但是,还有一个问题,当我们点开多P的图片id时,会发现他还是只返回p0的图片,也就是说我们获取不到这张图片的所有分p,这怎么办呢?
我们对于多p图片的网页进行分析:
清空network中的内容,然后点击查看全部:

这时候,我们神奇的发现了我们想要的东西:

在page这个数据包中,竟然含有我们想要下载的图片的链接:

于是,大胆的想法诞生了,我们完全可以补通过爬取网页获取数据,而是通过返回的json包来获取这个id里所有图片
我们转到Headers:

请求链接是这个样子的,将中间图片id换一下就可以获取已知id的所有图片的下载地址了,改写get_durl()函数并添加循环:
def get_durl(self):
for id in self.url_id:
url = 'https://www.pixiv.net/ajax/illust/' + id[1] + '/pages'
# 获取json中的body内容
img_body = requests.get(url, headers=self.header).json()['body']
img_url = []
# 应对其中的多p
for imgp in img_body:
img_url.append(imgp['urls']['original'])
print(img_url)
这样就是实现了获取所有id中的图片,并将下载链接放入img_url中
6.附上源码
完善代码,添加交互,补全函数:
# -*- coding: UTF-8 -*-
import requests
import time
import os
class Pixiv():
# 初始化类
def __init__(self, p, b):
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh',
}
self.pic_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Sec-Fetch-Dest': 'image'
}
self.daily_url = 'https://www.pixiv.net/ranking.php?mode=daily&content=illust'
self.week_url = 'https://www.pixiv.net/ranking.php?mode=weekly&content=illust'
self.month_url = 'https://www.pixiv.net/ranking.php?mode=monthly&content=illust'
# 下载的排行榜模式
self.p = p
# 下载的图片数量
self.b = b
# 下载地址
self.folder_path = 'Pixiv'
# 设置requests,防止连接过多无法继续连接
self.s = requests.session()
requests.adapters.DEFAULT_RETRIES = 5 # 增加重连次数
self.s.keep_alive = False # 关闭多余连接
# 获取图片id
def get_id(self):
# 每50个图片id进行分类
if self.b/50 == int(self.b/50):
tl = int(self.b/50)
else:
tl = int(self.b/50) + 1
url_list = []
# 通过返回的json数据抓取所有图片的数据
for t in range(tl):
self.id_url = self.url + '&p=' + str(t+1) + '&format=json'
rs = self.s.get(self.id_url, headers=self.header).json()
url_list += rs['contents']
# 对每一个id进行编号,采用二维数组
num = 1
self.url_id = []
for u in url_list:
self.url_id.append([num, str(u['illust_id'])])
num = num + 1
for id in self.url_id[:self.b]:
self.get_durl()
# 获取图片下载地址
def get_durl(self):
for id in self.url_id:
url = 'https://www.pixiv.net/ajax/illust/' + id[1] + '/pages'
# 获取json中的body内容
img_body = self.s.get(url, headers=self.header).json()['body']
img_url = []
# 应对其中的多p
for imgp in img_body:
img_url.append(imgp['urls']['original'])
self.download_img(img_url, id)
# 下载图片
def download_img(self, img_url, id):
# 需要添加Refer,不然拒绝访问
self.pic_header['Referer'] = 'https://www.pixiv.net/artworks/' + id[1]
for img in img_url:
img_back = img[-7:]
img_path = self.folder_path + '/' + id[1] + img_back
if not os.path.isfile(img_path):
print(str(id[0]) + '.正在下载图片:' + id[1] + img_back + '...')
imgRes = self.s.get(img, headers=self.pic_header).content
with open(img_path, 'wb') as f:
f.write(imgRes)
f.close()
else:
print(str(id[0]) + '.文件已存在')
# 创建文件夹
def creat_floder(self):
if not os.path.exists('Pixiv'):
os.mkdir('Pixiv')
if not os.path.exists('Pixiv/day'):
os.mkdir('Pixiv/day')
if not os.path.exists('Pixiv/week'):
os.mkdir('Pixiv/week')
if not os.path.exists('Pixiv/month'):
os.mkdir('Pixiv/month')
# 判断文件夹是否已经存在
if not os.path.exists(self.folder_path):
os.mkdir(self.folder_path)
print('文件夹已创建...')
# Pixiv类中的主函数
def main(self):
if self.p == '1':
self.url = self.daily_url
self.folder_path = self.folder_path + '/day/' + time.strftime("%Y.%m.%d", time.localtime())
print('正在下载日排行榜的图片...')
elif self.p == '2':
self.url = self.week_url
self.folder_path = self.folder_path + '/week'
print('正在下载周排行榜的图片...')
elif self.p == '3':
self.url = self.month_url
self.folder_path = self.folder_path + '/month'
print('正在下载月排行榜的图片...')
self.get_id()
self.creat_floder()
if __name__ == "__main__":
x = input("请输入要下载的是日排行榜(1)、周排行榜(2)、月排行榜(3):")
y = input("请输入要下载的图片数量:")
P = Pixiv(x, int(y))
P.main()
结果展示:


7.进阶:多线程下载
当我们下载几百张图片的时候,如果一张一张下载会很慢,这个时候,多线程就很重要
如何实现多线程下载你,这里采用了Python3的Thread库以及queue库,代码如下:
# -*- coding: UTF-8 -*-
import requests
import time
import os
from threading import Thread
from queue import Queue
class Pixiv():
# 初始化类
def __init__(self, p, b):
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh',
'Connection': 'close'
}
self.pic_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Sec-Fetch-Dest': 'image',
'Connection': 'close'
}
self.daily_url = 'https://www.pixiv.net/ranking.php?mode=daily&content=illust'
self.week_url = 'https://www.pixiv.net/ranking.php?mode=weekly&content=illust'
self.month_url = 'https://www.pixiv.net/ranking.php?mode=monthly&content=illust'
# 下载的排行榜模式
self.p = p
# 下载的图片数量
self.b = b
# 下载地址
self.folder_path = 'Pixiv'
# 设置requests,防止连接过多无法继续连接
self.s = requests.session()
requests.adapters.DEFAULT_RETRIES = 5 # 增加重连次数
self.s.keep_alive = False # 关闭多余连接
# 获取图片id
def get_id(self):
# 每50个图片id进行分类
if self.b/50 == int(self.b/50):
tl = int(self.b/50)
else:
tl = int(self.b/50) + 1
url_list = []
# 通过返回的json数据抓取所有图片的数据
for t in range(tl):
self.id_url = self.url + '&p=' + str(t+1) + '&format=json'
rs = self.s.get(self.id_url, headers=self.header).json()
url_list += rs['contents']
# 对每一个id进行编号,采用二维数组
num = 1
self.url_id = []
for u in url_list:
self.url_id.append([num, str(u['illust_id'])])
num = num + 1
# 创建下载id队列
self.u_id = Queue()
for id in self.url_id[:self.b]:
self.u_id.put(id)
# 获取图片下载地址
def get_durl(self):
while True:
try:
# 不阻塞的读取队列数据
id = self.u_id.get_nowait()
except:
break
url = 'https://www.pixiv.net/ajax/illust/' + id[1] + '/pages'
# 获取json中的body内容
img_body = self.s.get(url, headers=self.header).json()['body']
img_url = []
# 应对其中的多p
for imgp in img_body:
img_url.append(imgp['urls']['original'])
self.download_img(img_url, id)
# 下载图片
def download_img(self, img_url, id):
# 需要添加Refer,不然拒绝访问
self.pic_header['Referer'] = 'https://www.pixiv.net/artworks/' + id[1]
for img in img_url:
img_back = img[-7:]
img_path = self.folder_path + '/' + id[1] + img_back
if not os.path.isfile(img_path):
print(str(id[0]) + '.正在下载图片:' + id[1] + img_back + '...')
imgRes = self.s.get(img, headers=self.pic_header).content
with open(img_path, 'wb') as f:
f.write(imgRes)
f.close()
else:
print(str(id[0]) + '.文件已存在')
# 创建文件夹
def creat_floder(self):
if not os.path.exists('Pixiv'):
os.mkdir('Pixiv')
if not os.path.exists('Pixiv/day'):
os.mkdir('Pixiv/day')
if not os.path.exists('Pixiv/week'):
os.mkdir('Pixiv/week')
if not os.path.exists('Pixiv/month'):
os.mkdir('Pixiv/month')
# 判断文件夹是否已经存在
if not os.path.exists(self.folder_path):
os.mkdir(self.folder_path)
print('文件夹已创建...')
# Pixiv类中的主函数
def main(self):
if self.p == '1':
self.url = self.daily_url
self.folder_path = self.folder_path + '/day/' + time.strftime("%Y.%m.%d", time.localtime())
print('正在下载日排行榜的图片...')
elif self.p == '2':
self.url = self.week_url
self.folder_path = self.folder_path + '/week'
print('正在下载周排行榜的图片...')
elif self.p == '3':
self.url = self.month_url
self.folder_path = self.folder_path + '/month'
print('正在下载月排行榜的图片...')
self.get_id()
self.creat_floder()
self.threads()
print('已完成排名前' + str(self.b) + '图片的下载,下载目录在:' + self.folder_path)
# 多线程下载
def threads(self):
T = []
for i in range(10):
t = Thread(target=self.get_durl, args=())
T.append(t)
for i in T:
i.start()
for i in T:
i.join()
if __name__ == "__main__":
x = input("请输入要下载的是日排行榜(1)、周排行榜(2)、月排行榜(3):")
y = input("请输入要下载的图片数量:")
P = Pixiv(x, int(y))
P.main()
下载速度那是突飞猛进,这里分了十个线程,只要网速够,一秒下载不是梦!

这就是对于Python爬虫的一次综合性实战,学会了本篇教程,基本可以应对百分之九十的网站了!