Java中的序列化机制
文章目录
- 序列化的意义
- 市面上的序列化技术
- 序列化接口Serializable、Externalizable
- Serializable
- Externalizable
- serialVersionUID
- 静态变量是否会被序列化?
- Transient关键字
- 序列化技术的缺点
- 写在最后
先抛出序列化相关几个面试问题,各位看看能否答得上来?
- Java序列化机制的意义是什么?
- 你知道哪些序列化技术?
- 如何自定义序列化内容?
- serialVersionUID有什么用?
- 静态变量能否序列化?
- 某个字段(比如密码字段)不想序列化的话,怎么办?
- 序列化机制有什么缺点?
- Dubbo中的异常处理机制了解么?为什么要这么设计?
面试题是抛砖引玉,了解其背后原理才是目的,话不多说,发车了
序列化的意义
-
我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比 JVM 的生命周期更长。但在现实应用中,就可能要求在 JVM 停止运行之后能够保存(持久化)指定的对象,比如将用户数据保存在磁盘中、数据库中,并在将来重新读取被保存的对象。
-
不同Java系统之间经常会有交换数据、通信的需求,但是网络中的数据传输都是以字节流的形式,因此发送方系统有必要把对象数据转化成字节流数据来在网络中传输,而接收方系统接收到字节流后再反序列化成Java对象。Dubbo这种RPC通信框架中,Java对象就必须实现序列化接口。
总得来说:Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。从而达到网络传输、本地存储的效果
- Java序列化机制的意义是什么?已经有了答案
市面上的序列化技术
盗用网上一张图来说明
其中重点提一下JSON和Protobuf, JSON 和 protobuf 之间最显著的区别是 JSON 是基于文本的,并且是人类可读的,而 protobuf 是二进制的,但效率更高;JSON 是一种专门的数据表示,而 protobuf 提供模式(类型)来记录和执行适当的用法。虽然 protobuf 比 JSON 更有效,但是 JSON 对于基于文本的表示非常有效。虽然 protobuf 是一种二进制表示,但它确实提供了另一种文本表示,可用于需要具备人类可读性的场景

- 你知道哪些序列化技术?这里也有了答案
序列化接口Serializable、Externalizable
上面提到了很多序列化技术,当然本文重点是Java中的序列化
Serializable
Java中实现对象的可序列化非常简单,相关Java类实现 Serializable 接口即可,如图所示
@Getter
@Setter
static class User implements Serializable {
//序列化id
private static final long serialVersionUID = 1L;
private Long userId;
private String userName;
}
再来看看把User对象持久化到磁盘,并从磁盘读取后反序列化的例子,可以看到userId、userName被持久化下来,并能成功读取磁盘文件并反序列成Java对象
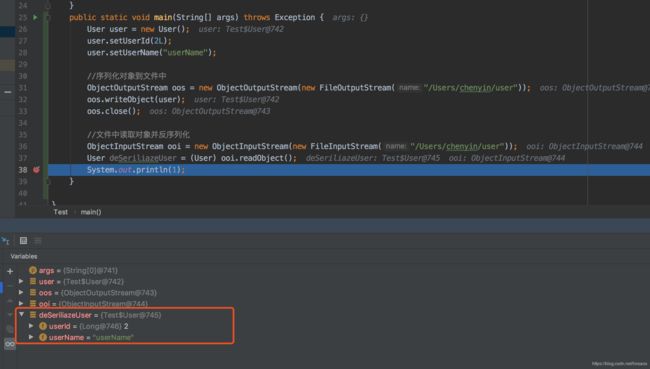
Externalizable
实现了Serializable接口的对象,Java已经为我们提供了内置的序列化功能,那么如果想自己自定义实现序列化内容呢,该怎么做?
Externalizable接口继承自Serializable接口,同时添加了writeExternal、readExternal方法用于实现自定义序列化功能。
修改上述User对象,并实现Externalizable接口
注意: 使用Externalizable接口的对象必须要有一个无参构造函数
@Getter
@Setter
static class User implements Externalizable {
private static final long serialVersionUID = 1L;
private Long userId;
private String userName;
public User() {
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(userId);
out.writeObject(userName);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
userId = (Long)in.readObject();
userName = (String) in.readObject();
}
}
测试过程同上,不再重复贴图,如何自定义序列化内容这个问题也迎刃而解
serialVersionUID
使用Java序列化时,要记住:在编写每个可序列化类时,显式声明序列化版本 UID
为什么一定要声明这个serialVersionUID呢?原因主要有2点
- 这消除了序列版本 UID 成为不兼容性的潜在来源,(同一个对象,如果UID不同,会导致反序列化失败)
- 这么做还能获得一个小的性能优势,如果没有提供序列版本 UID,则Java会执行高开销的计算在运行时生成一个 UID
serialVersionUID有什么用?大家应该心里有数了
静态变量是否会被序列化?
首先要明确一点,静态变量属于这个类Class,并不属于某个具体对象实例,而序列化针对的是Java对象,也就是具体的对象实例,自然不会对静态变量进行序列化
Transient关键字
假设用户对象中有个密码(Password)字段,这个字段出于安全性角度考虑,不想被序列化到磁盘中,这该怎么做?
不想被序列化的字段前加上transient关键字修饰就能阻止字段被序列化
@Getter
@Setter
static class User implements Serializable {
private static final long serialVersionUID = 1L;
private Long userId;
private String userName;
//transient关键字修饰
private transient String password;
}
可以看到password字段在反序列化后,其值为null,说明transient关键字修饰的字段没有被序列化
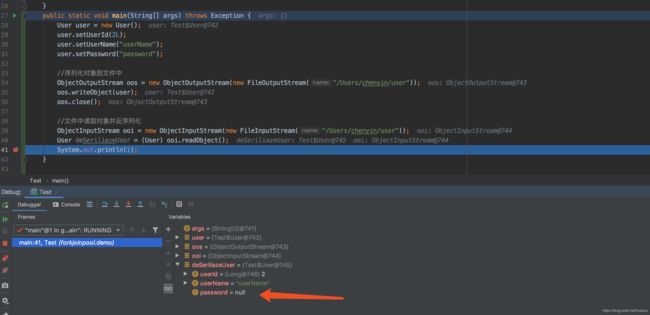
序列化技术的缺点
前面已经提到,Java中实现序列化其实很简单,对象只要实现下Serializable接口,并添加对应的UID字段就行,那么是不是不管什么对象,都可以实现下Serializable接口,反正没什么坏处?
答案是否认的,主要原因有如下几点
- 实现 Serializable 接口的一个主要代价是,一旦类的实现被发布,它就会降低更改该类实现的灵活性、兼容性
什么意思呢?举个例子,Dubbo中消费者依赖提供者的Jar包来调用服务,且Dubbo方法中的Java类必须实现序列化接口,假设某个类中有3个字段,后来服务端删掉了1个字段(或者改变了UID),没有通知消费者升级Jar包版本号,那么消费者仍然以旧的类(3个字段)来反序列化,此时反序列化会失败,这就是潜在的序列化问题,故使用序列化时,务必要考虑到代码更新时的兼容性问题
- 实现 Serializable 接口的第二个代价是,增加了出现 bug 和安全漏洞的可能性
Java 反序列化是一个明显且真实的危险源,因为它被应用程序直接和间接地广泛使用,比如 RMI(远程方法调 用)、JMX(Java 管理扩展)和 JMS(Java 消息传递系统)。不可信流的反序列化可能导致远程代码执行 (RCE)、拒绝服务(DoS)和一系列其他攻击。应用程序很容易受到这些攻击,即使它们本身没有错误
写在最后
最后,再提一提Dubbo中的异常处理机制,先看下Dubbo中的异常处理是怎么做的
当Dubbo的provider端抛出异常(Throwable),会被provider端的ExceptionFilter拦截到,执行以下拦截处理方法
public void onResponse(Result appResponse, Invoker<?> invoker, Invocation invocation) {
if (appResponse.hasException() && GenericService.class != invoker.getInterface()) {
try {
Throwable exception = appResponse.getException();
// 如果是受检异常 直接抛出
if (!(exception instanceof RuntimeException) && (exception instanceof Exception)) {
return;
}
// 方法中有声明该异常,直接抛出
try {
Method method = invoker.getInterface().getMethod(invocation.getMethodName(), invocation.getParameterTypes());
Class<?>[] exceptionClassses = method.getExceptionTypes();
for (Class<?> exceptionClass : exceptionClassses) {
if (exception.getClass().equals(exceptionClass)) {
return;
}
}
} catch (NoSuchMethodException e) {
return;
}
// for the exception not found in method's signature, print ERROR message in server's log.
logger.error("Got unchecked and undeclared exception which called by " + RpcContext.getContext().getRemoteHost() + ". service: " + invoker.getInterface().getName() + ", method: " + invocation.getMethodName() + ", exception: " + exception.getClass().getName() + ": " + exception.getMessage(), exception);
// 如果异常类和接口方法在一个jar包中,直接抛出.
String serviceFile = ReflectUtils.getCodeBase(invoker.getInterface());
String exceptionFile = ReflectUtils.getCodeBase(exception.getClass());
if (serviceFile == null || exceptionFile == null || serviceFile.equals(exceptionFile)) {
return;
}
// 如果是JDK的异常,直接抛出
String className = exception.getClass().getName();
if (className.startsWith("java.") || className.startsWith("javax.")) {
return;
}
// 如果是Dubbo的异常,直接抛出
if (exception instanceof RpcException) {
return;
}
// 将异常包装成RuntimeException
appResponse.setException(new RuntimeException(StringUtils.toString(exception)));
return;
} catch (Throwable e) {
logger.warn("Fail to ExceptionFilter when called by " + RpcContext.getContext().getRemoteHost() + ". service: " + invoker.getInterface().getName() + ", method: " + invocation.getMethodName() + ", exception: " + e.getClass().getName() + ": " + e.getMessage(), e);
return;
}
}
}
具体处理过程都写在注释里了,有的人为了面试可能就会死记硬背,一条条都给记下来,有没想过为什么要大费周章的做这么多判断?
试想一下,假设Dubbo没有做这些判断,并且服务端抛出的自定义异常和提供给消费者的方法不在一个Jar包中会有什么问题?
消费者会无法序列化这个异常,为什么?因为这个服务端抛出的自定义异常只在服务端的代码里,消费端引用的Jar中并没有这个异常。这也就是上文中提到的序列化的兼容性问题,不能让引用方有因为框架原因而序列化报错的可能。
所以Dubbo做了这么多判断,对异常做了处理,均是为了判断消费端能否序列化这个异常。如果确实消费端无法序列化这个异常,则Dubbo将异常包装成RuntimeException抛出
再回过头来看看这个异常处理机制
- 方法中有声明该异常,直接抛出(方法中有声明,说明接口声明中引入了该异常,可以被消费端识别到)
- 如果异常类和接口方法在一个jar包中,直接抛出(同一个Jar里的异常,自然能被识别)
- 如果是JDK的异常,直接抛出(Java代码自然能识别JDK异常)
- 如果是Dubbo的异常,直接抛出(调用Dubbo方法,自然要引入Dubbo的Jar包,其异常也能被识别)
是不是清晰了很多?