- Flink启动任务
swg321321
flink大数据
Flink以本地运行作为解读例如:第一章Python机器学习入门之pandas的使用提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录Flink前言StreamExecutionEnvironmentLocalExecutorMiniClusterStreamGraph二、使用步骤1.引入库2.读入数据总结前言提示:这里可以添加本文要记录的大概内容:例如:随着人工智能的不断发
- 机器学习课堂4线性回归模型+特征缩放
木尘152132
机器学习线性回归python
一、实验2-2,线性回归模型,计算模型在训练数据集和测试数据集上的均方根误差代码:#2-2线性回归模型importpandasaspdimportnumpyasnpimportmatplotlib.pyplotasplt#参数设置iterations=3000#迭代次数learning_rate=0.0001#学习率m_train=3000#训练样本的数量flag_plot_lines=False
- 基于Wasm的边缘计算Pandas:突破端侧AI的最后一公里——让数据分析在手机、IoT设备上飞驰
Eqwaak00
Pandas人工智能wasm边缘计算pandas架构深度学习
引言:边缘计算的算力觉醒在智能家居设备每秒产生数万条传感器数据、手机App需要实时分析用户行为的今天,传统云计算模式面临高延迟、隐私风险、带宽成本三大挑战。本文将揭示如何通过WebAssembly(Wasm)+Pandas的技术组合,在边缘设备上实现零云端依赖的实时数据分析,并通过智慧工厂设备预测性维护案例,展示从理论到工程的全链路实现。一、技术架构设计1.1边缘计算范式演进mermaid:gra
- excel文件有两列,循环读取文件两列赋值到字典列表。字典的有两个key,分别为question和answer。将最终结果输出到json文件
大霞上仙
pythonexceljsonpython
importpandasaspdimportjson#1.读取Excel文件(假设列名为question和answer)try:df=pd.read_excel("input.xlsx",usecols=["question","answer"])#明确指定列exceptExceptionase:print(f"读取文件失败:{str(e)}")exit()#2.转换为字典列表result=[{"
- 「Python数据分析」Pandas基础,筛选数据利器:布尔索引
奕澄羽邦
python数据分析pandas
我们在处理数据的时候,数据筛选是一个重要的过程。利用布尔索引,我们可以选择需要的数据区间。布尔索引,是利用各种不等式,以及与或非操作,来对数据区间进行选择。在pandas中,与操作,对应的是&这个符号,表示选取两个数据集重合的部分。或操作,对应的是|这个符号,表示选择两个数据集中,只要在一个数据集中出现的部分。非操作,对应的是~这个符号,表示选取一个数据集中,相反的部分。我们下面通过具体的例子,来
- 数据分析_python进行数据筛选1_行筛选
Monkey*王
python数据分析pandas
以titanic的训练数据为例进行展示,为了简化取前十行为例首先导入模块,导入数据importpandasaspdimportnumpyasnpdf=pd.read_csv(r"C:\Users\admin\Desktop\train.csv")df=df.head(10)df.index=['a','b','c','d','e','f','g','h','i','g']筛选单行1.利用df[行索
- Linux安装Anaconda和Jupyter
硬水果糖
人工智能Linuxlinuxjupyter运维
一、了解Anaconda和Jupyter引言:Anaconda是一个流行的开源数据科学平台,广泛用于数据分析、机器学习、人工智能等领域。它是一个集成了大量科学计算和数据科学工具的Python和R编程语言环境。Anaconda的主要目标是简化数据科学和机器学习的开发流程,提供一个易于安装和管理的环境。而预装了大量常用的Python和R库,这些库涵盖了数据科学的各个方面,包括:数据分析:Pandas、
- python pandas 读取excel单元门公式值_Python pandas对excel的操作实现示例
weixin_39585761
pythonpandas读取excel单元门公式值
最近经常看到各平台里都有Python的广告,都是对excel的操作,这里明哥收集整理了一下pandas对excel的操作方法和使用过程。本篇介绍pandas的DataFrame对列(Column)的处理方法。示例数据请通过明哥的gitee进行下载。增加计算列pandas的DataFrame,每一行或每一列都是一个序列(Series)。比如:importpandasaspddf1=pd.read_e
- pandas整表写入excel指定位置_pandas操作Excel的常用场景及问题
那个吴小明
很多场景下使用pandas就能够胜任手上的excel处理任务,之前写的用python操作具体到excel单元格的方法参考:贺霆:python操作Excel实现自动化报表zhuanlan.zhihu.com现在主要介绍使用pandas读取excel的几种常用场景:一、常规读取importpandasaspdfrompandasimportDataFrame,Seriesimportosos.chdi
- pandas 读取某一单元格的值_07-Pandas Excel新建/读取/填充(一)
扇贝编程
pandas读取某一单元格的值
Excel是微软的经典之作,几乎可以满足我们日常工作的所有需求,但是在处理海量数据时,Excel在效率及性能方面就显得很吃力。正因为Pandas在数据处理方面有着独特的优势,所有掌握pandas库处理excel格式的数据就显得十分必要。目录excel文档新建读取excel文档行列操作空值自动填充行列函数运算excel数据排序excel数据按条件筛选#1.创建excel文件在jupyter中导入pa
- 如何用Python批量将CSV文件编码转换为UTF-8并转为Excel格式?
字节王德发
pythonpythonexcel开发语言
在处理数据时,CSV文件格式常常用作数据的交换格式。不过,很多情况下我们会遇到编码问题,特别是当文件不是UTF-8编码时。为了更好地处理这些文件,可能需要将它们转换为UTF-8编码,并且将其转换为Excel格式,这样可以方便后续的数据分析和使用。今天就来聊聊如何用Python实现这一过程。准备工作:安装必要的库我们需要确保安装了所需的Python库。主要用到的库有pandas和openpyxl。p
- Pandas完全指南:数据处理与分析从入门到实战
xiaoyu❅
pythonpythonpandas开发语言
目录引言一、Pandas环境配置与核心概念1.1安装Pandas1.2导入惯例1.3核心数据结构二、数据结构详解2.1Series创建与操作2.2DataFrame创建三、数据查看与基本操作3.1数据预览3.2索引与选择3.3数据排序四、数据清洗实战4.1处理缺失值4.2处理重复值4.3数据类型转换4.4字符串处理五、数据处理进阶5.1数据筛选5.2列操作5.3应用函数六、数据分组与聚合6.1基础
- 焊接性能分析代码(Python)
骑蜗牛上月亮
python开发语言
welding_performance_data.xls数据文件。welding_strengthtoughness5001052012480855015490953013510115401447075601690018600121500139111578115importpandasaspdimportmatplotlib.pyplotaspltimporttkinterastkfrommatp
- Python常用的库讲解(易懂版)
不辉放弃
python开发语言
NumPy:用于科学计算的基础库,提供多维数组对象、各种派生对象和对数组执行操作的工具。importnumpyasnp#创建一个numpy数组arr=np.array([1,2,3,4,5])print(arr)Pandas:数据处理库,提供数据结构和数据分析工具,特别适合处理结构化数据。importpandasaspd#创建一个Pandas数据帧df=pd.DataFrame({'A':[1,2
- 基于Geopandas的地理空间数据可视化与分析方法研究
一键难忘
信息可视化Geopandaspython
地理空间数据可视化是数据科学中重要的应用之一。通过有效地展示地理信息,我们能够深入理解空间数据的分布和模式。Python的Geopandas库为地理空间数据处理和可视化提供了强大的支持,它基于pandas并集成了shapely、fiona等多个库,能够方便地进行地理数据的读取、处理和展示。本文将介绍如何使用Geopandas进行地理空间数据可视化,示范数据处理的基本流程,并通过具体的代码实例,深入
- 如何用python做一个小程序进行炒股?
大懒猫软件
python小程序开发语言
使用Python分析股票的完整程序以下是一个完整的Python程序,展示如何获取股票数据、进行数据清洗、计算技术指标、并进行简单的价格走势分析。1.安装必要的库首先,确保安装了必要的库:bash复制pipinstallrequestspandasmatplotlibyfinance2.获取股票数据使用yfinance库获取股票数据。yfinance是一个流行的库,可以方便地从雅虎财经获取股票数据。
- 批量将将xlsx转为csv,将csv转为csv utf-8
Znnjcidmslz
数据pythonpandas
csv转换为csvutf-8将csv格式文件批量转换为csvutf-8格式文件,以下为使用Python处理的代码:importosimportpandasaspd#存有文件的路径current_path=os.getcwd()#current_path=os.path.dirname('G:/weather_output2')#转换之后存放的路径为“UTF8”,会检查当前路径是否有,没有就创建ut
- csv转为utf8编码_中文的csv文件的编码改成utf8的方法
John Sheppard
csv转为utf8编码
直奔主题:把包含中文的csv文件的编码改成utf-8的方法:啰嗦几句:在用pandas读取hive导出的csv文件时,经常会遇到类似UnicodeDecodeError:'gbk'codeccan'tdecodebyte0xa3inposition12这样的问题,这种问题是因为导出的csv文件包含中文,且这些中文的编码不是gbk,直接用excel打开这些文件还会出现乱码,但用记事本打开这些csv则
- 1.4使用pandas读取和写入Excel文件的基本操作
林伽一
python处理excelpandasexcelpython
读取和写入Excel文件是使用Python处理Excel的基本操作。在Python中,可以使用不同的库来实现这些操作,例如pandas、openpyxl等。以下是读取和写入Excel文件的基本操作示例:读取Excel文件使用pandas库读取Excel文件非常方便。下面的示例演示了如何使用pandas读取Excel文件:importpandasaspd#读取Excel文件df=pd.read_ex
- 【Python】爬取高校数据(名字,院校特色,所在地,性质)。可用于判断高校是否为双一流,本科/专科等分析
llzcxdb
Pythonpython开发语言爬虫
源网站:http://college.gaokao.com/schlist/p1利用Python的lxml库进行html解析,源代码:importrequestsfromlxmlimportetreeimportpandasaspdimportcsv#请求URLurl='http://college.gaokao.com/schlist/p'#构建请求头headers={'User-Agent':
- 机器学习Pandas_learn4
XW-ABAP
机器学习机器学习pandas人工智能
importpandasaspddefcalculate_goods_covariance():#定义商品销售数据字典goods_sales_data={"时期":["一期","二期","三期","四期"],"苹果":[15,16,3,2],"橘子":[12,14,16,18],"石榴":[11,8,7,1]}#将字典转换为DataFrame对象goods_dataframe=pd.DataFra
- 如何使用Python对Excel、CSV文件完成数据清洗与预处理?
Python 集中营
python数据分析应用pythonexcel开发语言
在数据分析和机器学习项目中,数据清洗与预处理是不可或缺的重要环节。现实世界中的数据往往是不完整、不一致且含有噪声的,这些问题会严重影响数据分析的质量和机器学习模型的性能。Python作为一门强大的编程语言,提供了多种库和工具来帮助我们高效地完成数据清洗与预处理任务,其中最常用的库包括Pandas、NumPy、SciPy等。本文将详细介绍如何使用Python对Excel和CSV格式的数据文件进行清洗
- Pandas与PySpark混合计算实战:突破单机极限的智能数据处理方案
Eqwaak00
Pandaspandas学习python科技开发语言
引言:大数据时代的混合计算革命当数据规模突破十亿级时,传统单机Pandas面临内存溢出、计算缓慢等瓶颈。PySpark虽能处理PB级数据,但在开发效率和局部计算灵活性上存在不足。本文将揭示如何构建Pandas+PySpark混合计算管道,在保留Pandas便捷性的同时,借助Spark分布式引擎实现百倍性能提升,并通过真实电商用户画像案例演示全流程实现。一、混合架构设计原理1.1技术栈优势分析维度P
- pandas 根据给定的条件动态筛选
Aa123456789_55
pandaspandaspython
defdynamic_filter(df,conditions):"""根据给定的条件动态筛选DataFrame。:paramdf:pandasDataFrame:paramconditions:字典,键为列名,值为筛选条件(单个值、列表或其他布尔表达式):return:筛选后的DataFrame"""mask=pd.Series(True,index=df.index)#初始化全True的mas
- 机器学习Pandas_learn3
XW-ABAP
机器学习pandas
frompandasimportDataFrameimportnumpypaints={"车名":["奥迪Q5L","哈弗H6","奔驰GLC"],"最低报价":[numpy.nan,9.80,numpy.nan],"最高报价":[49.80,23.10,58.78]}goods_in=DataFrame(paints,index=[1,2,3])print(goods_in)goods_in_n
- python绘制密度散点图
龟速前进
anaconda可视化python
头大,外行人做个图咋这么难,趋势线还没有研究出来怎么加上去,哎importmatplotlib.pyplotaspltfromscipy.statsimportgaussian_kdefrommpl_toolkits.axes_grid1importmake_axes_locatableimportnumpyasnpimportpandasaspdfromdbfreadimportDBFdata=
- pandas 读写excel
jimox_ai
pandas
在Python中,使用Pandas库读写Excel文件是一个常见的操作。Pandas提供了`read_excel`和`to_excel`方法来分别实现读取和写入Excel文件的功能。以下是一些基本的示例:###读取Excel文件```pythonimportpandasaspd#读取Excel文件df=pd.read_excel('path_to_your_excel_file.xlsx')#显示
- 大话 Python:python 操作 excel 系列 -- pandas 读取、分析、保存
2401_84140734
程序员pythonexcelpandas
read_excel()直接读取excel文件df=pd.read_excel(‘C:/test.xlsx’)4,读取当前字段计算后生成新字段获取原有字段paymount值paymount=df[‘paymount’]业务计算(金额-10)paymount_new=paymount-10添加新字段paymount_newdf[‘paymount_new’]=paymount_new这个步骤可以加入
- pandas寻找四分位数及判断离群点
SXxtyz
python
importpandasaspdtrain_df=pd.read_csv("train.csv")q1,q3=train_df['price'].quantile([0.25,0.75])iqr=q3-
- Ansible、Ansible Tower:操作Pan-OS与常见问题
2huxy
AnsibleAnsibleTower运维linux运维
Ansible、AnsibleTower:操作Pan-OS一、安装1、控制节点中pip安装依赖:Ansible可以直接pipinstallpan-pyhtonpydevicexmltodictAnsibleTower涉及到虚拟环境的问题,应该把相应的虚拟PIP库装进对应模板的虚拟环境中sudo/var/lib/awx/venv/ansible/bin/pipinstallpan-pyhton2、A
- java类加载顺序
3213213333332132
java
package com.demo;
/**
* @Description 类加载顺序
* @author FuJianyong
* 2015-2-6上午11:21:37
*/
public class ClassLoaderSequence {
String s1 = "成员属性";
static String s2 = "
- Hibernate与mybitas的比较
BlueSkator
sqlHibernate框架ibatisorm
第一章 Hibernate与MyBatis
Hibernate 是当前最流行的O/R mapping框架,它出身于sf.net,现在已经成为Jboss的一部分。 Mybatis 是另外一种优秀的O/R mapping框架。目前属于apache的一个子项目。
MyBatis 参考资料官网:http:
- php多维数组排序以及实际工作中的应用
dcj3sjt126com
PHPusortuasort
自定义排序函数返回false或负数意味着第一个参数应该排在第二个参数的前面, 正数或true反之, 0相等usort不保存键名uasort 键名会保存下来uksort 排序是对键名进行的
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8&q
- DOM改变字体大小
周华华
前端
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q
- c3p0的配置
g21121
c3p0
c3p0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。c3p0的下载地址是:http://sourceforge.net/projects/c3p0/这里可以下载到c3p0最新版本。
以在spring中配置dataSource为例:
<!-- spring加载资源文件 -->
<bean name="prope
- Java获取工程路径的几种方法
510888780
java
第一种:
File f = new File(this.getClass().getResource("/").getPath());
System.out.println(f);
结果:
C:\Documents%20and%20Settings\Administrator\workspace\projectName\bin
获取当前类的所在工程路径;
如果不加“
- 在类Unix系统下实现SSH免密码登录服务器
Harry642
免密ssh
1.客户机
(1)执行ssh-keygen -t rsa -C "
[email protected]"生成公钥,xxx为自定义大email地址
(2)执行scp ~/.ssh/id_rsa.pub root@xxxxxxxxx:/tmp将公钥拷贝到服务器上,xxx为服务器地址
(3)执行cat
- Java新手入门的30个基本概念一
aijuans
javajava 入门新手
在我们学习Java的过程中,掌握其中的基本概念对我们的学习无论是J2SE,J2EE,J2ME都是很重要的,J2SE是Java的基础,所以有必要对其中的基本概念做以归纳,以便大家在以后的学习过程中更好的理解java的精髓,在此我总结了30条基本的概念。 Java概述: 目前Java主要应用于中间件的开发(middleware)---处理客户机于服务器之间的通信技术,早期的实践证明,Java不适合
- Memcached for windows 简单介绍
antlove
javaWebwindowscachememcached
1. 安装memcached server
a. 下载memcached-1.2.6-win32-bin.zip
b. 解压缩,dos 窗口切换到 memcached.exe所在目录,运行memcached.exe -d install
c.启动memcached Server,直接在dos窗口键入 net start "memcached Server&quo
- 数据库对象的视图和索引
百合不是茶
索引oeacle数据库视图
视图
视图是从一个表或视图导出的表,也可以是从多个表或视图导出的表。视图是一个虚表,数据库不对视图所对应的数据进行实际存储,只存储视图的定义,对视图的数据进行操作时,只能将字段定义为视图,不能将具体的数据定义为视图
为什么oracle需要视图;
&
- Mockito(一) --入门篇
bijian1013
持续集成mockito单元测试
Mockito是一个针对Java的mocking框架,它与EasyMock和jMock很相似,但是通过在执行后校验什么已经被调用,它消除了对期望 行为(expectations)的需要。其它的mocking库需要你在执行前记录期望行为(expectations),而这导致了丑陋的初始化代码。
&nb
- 精通Oracle10编程SQL(5)SQL函数
bijian1013
oracle数据库plsql
/*
* SQL函数
*/
--数字函数
--ABS(n):返回数字n的绝对值
declare
v_abs number(6,2);
begin
v_abs:=abs(&no);
dbms_output.put_line('绝对值:'||v_abs);
end;
--ACOS(n):返回数字n的反余弦值,输入值的范围是-1~1,输出值的单位为弧度
- 【Log4j一】Log4j总体介绍
bit1129
log4j
Log4j组件:Logger、Appender、Layout
Log4j核心包含三个组件:logger、appender和layout。这三个组件协作提供日志功能:
日志的输出目标
日志的输出格式
日志的输出级别(是否抑制日志的输出)
logger继承特性
A logger is said to be an ancestor of anothe
- Java IO笔记
白糖_
java
public static void main(String[] args) throws IOException {
//输入流
InputStream in = Test.class.getResourceAsStream("/test");
InputStreamReader isr = new InputStreamReader(in);
Bu
- Docker 监控
ronin47
docker监控
目前项目内部署了docker,于是涉及到关于监控的事情,参考一些经典实例以及一些自己的想法,总结一下思路。 1、关于监控的内容 监控宿主机本身
监控宿主机本身还是比较简单的,同其他服务器监控类似,对cpu、network、io、disk等做通用的检查,这里不再细说。
额外的,因为是docker的
- java-顺时针打印图形
bylijinnan
java
一个画图程序 要求打印出:
1.int i=5;
2.1 2 3 4 5
3.16 17 18 19 6
4.15 24 25 20 7
5.14 23 22 21 8
6.13 12 11 10 9
7.
8.int i=6
9.1 2 3 4 5 6
10.20 21 22 23 24 7
11.19
- 关于iReport汉化版强制使用英文的配置方法
Kai_Ge
iReport汉化英文版
对于那些具有强迫症的工程师来说,软件汉化固然好用,但是汉化不完整却极为头疼,本方法针对iReport汉化不完整的情况,强制使用英文版,方法如下:
在 iReport 安装路径下的 etc/ireport.conf 里增加红色部分启动参数,即可变为英文版。
# ${HOME} will be replaced by user home directory accordin
- [并行计算]论宇宙的可计算性
comsci
并行计算
现在我们知道,一个涡旋系统具有并行计算能力.按照自然运动理论,这个系统也同时具有存储能力,同时具备计算和存储能力的系统,在某种条件下一般都会产生意识......
那么,这种概念让我们推论出一个结论
&nb
- 用OpenGL实现无限循环的coverflow
dai_lm
androidcoverflow
网上找了很久,都是用Gallery实现的,效果不是很满意,结果发现这个用OpenGL实现的,稍微修改了一下源码,实现了无限循环功能
源码地址:
https://github.com/jackfengji/glcoverflow
public class CoverFlowOpenGL extends GLSurfaceView implements
GLSurfaceV
- JAVA数据计算的几个解决方案1
datamachine
javaHibernate计算
老大丢过来的软件跑了10天,摸到点门道,正好跟以前攒的私房有关联,整理存档。
-----------------------------华丽的分割线-------------------------------------
数据计算层是指介于数据存储和应用程序之间,负责计算数据存储层的数据,并将计算结果返回应用程序的层次。J
&nbs
- 简单的用户授权系统,利用给user表添加一个字段标识管理员的方式
dcj3sjt126com
yii
怎么创建一个简单的(非 RBAC)用户授权系统
通过查看论坛,我发现这是一个常见的问题,所以我决定写这篇文章。
本文只包括授权系统.假设你已经知道怎么创建身份验证系统(登录)。 数据库
首先在 user 表创建一个新的字段(integer 类型),字段名 'accessLevel',它定义了用户的访问权限 扩展 CWebUser 类
在配置文件(一般为 protecte
- 未选之路
dcj3sjt126com
诗
作者:罗伯特*费罗斯特
黄色的树林里分出两条路,
可惜我不能同时去涉足,
我在那路口久久伫立,
我向着一条路极目望去,
直到它消失在丛林深处.
但我却选了另外一条路,
它荒草萋萋,十分幽寂;
显得更诱人,更美丽,
虽然在这两条小路上,
都很少留下旅人的足迹.
那天清晨落叶满地,
两条路都未见脚印痕迹.
呵,留下一条路等改日再
- Java处理15位身份证变18位
蕃薯耀
18位身份证变15位15位身份证变18位身份证转换
15位身份证变18位,18位身份证变15位
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 201
- SpringMVC4零配置--应用上下文配置【AppConfig】
hanqunfeng
springmvc4
从spring3.0开始,Spring将JavaConfig整合到核心模块,普通的POJO只需要标注@Configuration注解,就可以成为spring配置类,并通过在方法上标注@Bean注解的方式注入bean。
Xml配置和Java类配置对比如下:
applicationContext-AppConfig.xml
<!-- 激活自动代理功能 参看:
- Android中webview跟JAVASCRIPT中的交互
jackyrong
JavaScripthtmlandroid脚本
在android的应用程序中,可以直接调用webview中的javascript代码,而webview中的javascript代码,也可以去调用ANDROID应用程序(也就是JAVA部分的代码).下面举例说明之:
1 JAVASCRIPT脚本调用android程序
要在webview中,调用addJavascriptInterface(OBJ,int
- 8个最佳Web开发资源推荐
lampcy
编程Web程序员
Web开发对程序员来说是一项较为复杂的工作,程序员需要快速地满足用户需求。如今很多的在线资源可以给程序员提供帮助,比如指导手册、在线课程和一些参考资料,而且这些资源基本都是免费和适合初学者的。无论你是需要选择一门新的编程语言,或是了解最新的标准,还是需要从其他地方找到一些灵感,我们这里为你整理了一些很好的Web开发资源,帮助你更成功地进行Web开发。
这里列出10个最佳Web开发资源,它们都是受
- 架构师之面试------jdk的hashMap实现
nannan408
HashMap
1.前言。
如题。
2.详述。
(1)hashMap算法就是数组链表。数组存放的元素是键值对。jdk通过移位算法(其实也就是简单的加乘算法),如下代码来生成数组下标(生成后indexFor一下就成下标了)。
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>>
- html禁止清除input文本输入缓存
Rainbow702
html缓存input输入框change
多数浏览器默认会缓存input的值,只有使用ctl+F5强制刷新的才可以清除缓存记录。
如果不想让浏览器缓存input的值,有2种方法:
方法一: 在不想使用缓存的input中添加 autocomplete="off";
<input type="text" autocomplete="off" n
- POJO和JavaBean的区别和联系
tjmljw
POJOjava beans
POJO 和JavaBean是我们常见的两个关键字,一般容易混淆,POJO全称是Plain Ordinary Java Object / Pure Old Java Object,中文可以翻译成:普通Java类,具有一部分getter/setter方法的那种类就可以称作POJO,但是JavaBean则比 POJO复杂很多, Java Bean 是可复用的组件,对 Java Bean 并没有严格的规
- java中单例的五种写法
liuxiaoling
java单例
/**
* 单例模式的五种写法:
* 1、懒汉
* 2、恶汉
* 3、静态内部类
* 4、枚举
* 5、双重校验锁
*/
/**
* 五、 双重校验锁,在当前的内存模型中无效
*/
class LockSingleton
{
private volatile static LockSingleton singleton;
pri
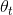 为第t个元素的值,
为第t个元素的值, 代表可调节的超参数(类似ewm()函数的参数span,控制指数下降的速度)。
代表可调节的超参数(类似ewm()函数的参数span,控制指数下降的速度)。