机器学习——数据降维——主成分分析(PCA)和奇异值分解(SVD)
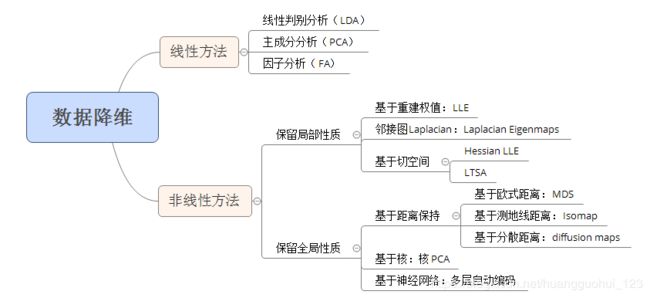
一、主成分分析(PCA)
主成分分析,Principal Component Analysis (PCA),是现代数据分析的标准工具,它可以把庞大复杂的高维数据集(变换之前的数据集各维度之间存在相关性),通过数学变换,转化成较低维度的数据集,并去除掉维度之间的相关性。
PCA的优势和劣势都在于,它是一个非参数的分析。没有需要调整的参数,它的答案是唯一的,独立于用户特性的。
PCA和LDA的区别可见《多元统计分析——数据降维——Fisher线性判别分析(LDA)》中第五节。
主成分分析的应用领域:
-
构建综合指标:主成分分析主要用于构建综合指标来区分目标群体,例如构建顾客各种消费行为的综合指标来进行客户分级。
-
数据降维:通常我们会用少于原始变量数的主成分来描述尽可能多的数据差异,特别是当原始变量维度很高时,可达到降维目的。
-
数据可视化:当原始变量维度很高时,可采用第一、第二主成分散点图来直观表述数据特征,例如数据聚类信息等。
-
变量压缩、重构:由“重要的”主成分重构原始变量(即原始数据
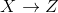 之后,选择主要方差的特征之后,通过线性变化回原维度数据
之后,选择主要方差的特征之后,通过线性变化回原维度数据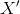 ,以实现降噪的目的),可以去除原始数据中冗余的噪音,突出数据的特征,例如人脸识别。
,以实现降噪的目的),可以去除原始数据中冗余的噪音,突出数据的特征,例如人脸识别。
1、PCA原理
主成分分析的原理非常简单,概括来说就是选择包含信息量大的维度,去除信息量少的“干扰”维度。
注意:这边所谓的“维度”不是原始数据的某个特征,而是原始数据各个特征的组合。
具体如下:
- 数据从原来的坐标系
 转换到新的坐标系
转换到新的坐标系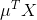 ,新坐标系的选择是由数据本身决定的。第一个新坐标轴
,新坐标系的选择是由数据本身决定的。第一个新坐标轴 选择的是原始数据中方差最大(
选择的是原始数据中方差最大(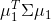 )的方向,第二个新坐标轴
)的方向,第二个新坐标轴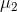 选择与第一个新坐标轴正交(
选择与第一个新坐标轴正交(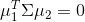 )且具有最大方差(
)且具有最大方差(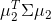 )的方向,第三个新坐标轴
)的方向,第三个新坐标轴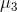 选择与第一个新坐标轴、第二个新坐标轴正交(
选择与第一个新坐标轴、第二个新坐标轴正交(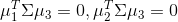 )且具有最大方差(
)且具有最大方差(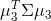 )的方向........以此类推,第
)的方向........以此类推,第 个新坐标轴
个新坐标轴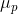 选择与第一个新坐标轴、第二个新坐标轴、...、第
选择与第一个新坐标轴、第二个新坐标轴、...、第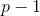 个新坐标轴
个新坐标轴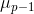 正交(
正交(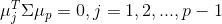 )且具有最小方差(
)且具有最小方差(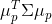 )的方向,共建立与原始数据特征数目相等的新坐标轴。
)的方向,共建立与原始数据特征数目相等的新坐标轴。 - 我们会发现,大部分方差都包含在最前面的几个新坐标轴中,因此我们可以忽略余下的坐标轴,从而实现降维。(方差大代表不同数据之间的差异大,即,包含的可区分信息量大)
注意,PCA降维后,原始数据被映射到了新坐标系,不是原始值了。
pca降维实现的步骤:
1)把数据集组织成一个  的矩阵。
的矩阵。
2)将的每个变量(列)分别进行去中心化![]() ,得到新的数据集
,得到新的数据集 (注意:有时需要做标准化,见下方第四节——基于标准化变量的主成分分析)。
(注意:有时需要做标准化,见下方第四节——基于标准化变量的主成分分析)。
3)求出协方差矩阵![]() 。
。
4)求出协方差矩阵的特征值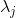 和对应的特征向量
和对应的特征向量![]() 。
。
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前  行组成矩阵
行组成矩阵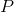 (注意:如何取值请见下方第5节——主成分个数的选择)。
(注意:如何取值请见下方第5节——主成分个数的选择)。
6) ![]() 即为降维到 维后的数据。
即为降维到 维后的数据。
【知识点1】:
设
是
阶方阵,如果标量
和
使关系式
成立,则称
这是
,即
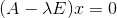
以上步骤的关键点在于:为何协方差的特征值对应的特征向量构成的矩阵能够实现降维的效果?以下我们通过结合案例数据和数据分布的图形进一步进行讲解。
案例分析:
案例1:有以下二维数据:
| 房价(百万) | 面积(平方米) | |
| a | 10 | 9 |
| b | 2 | 3 |
| c | 1 | 2 |
| d | 7 | 6.5 |
| e | 3 | 2.5 |
1)对数据进行去中心化——均值为0
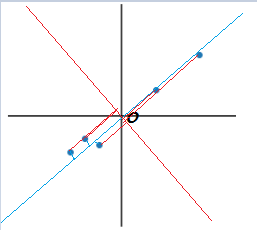
去中心化之后的数据分布如下所示:O为坐标原点。

【小贴士1】
观察点
有时用经过中心化的
代替。这并不会对样本协方差矩阵或者相关系数矩阵有影响,所以不会改变最后得到的系数向量
。
主成分的几何解释?
经过中心化的一系列主成分
可看作将原来坐标系的原点平移到
,然后旋转坐标轴,使得坐标轴与数据最大方差方向一致,如下图所示。
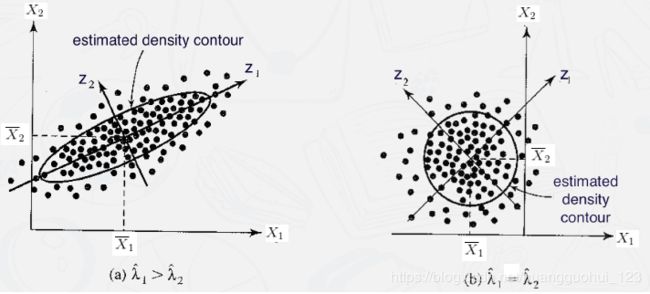
2)数据从原来的坐标系转换到新的坐标系。第一个新坐标轴选择的是原始数据中方差最大的方向(即下图中,数据在蓝色线的投影后的方差最大),第二个新坐标轴选择与第一个新坐标轴正交且具有最大方差的方向(即下图中,数据在红色线的投影后的方差最大)。
我们知道,给定一个单位向量 和空间内一点(根据空间维度可以表示为
和空间内一点(根据空间维度可以表示为![]() ,代表维度),在上的投影距离原点的距离为
,代表维度),在上的投影距离原点的距离为![]() ,同样,如果为数据集合(可表示为矩阵
,同样,如果为数据集合(可表示为矩阵 ,也可以表示为列向量
,也可以表示为列向量![]() )中的一点,因此为了最大化投影点的方差,我们需要选择一个单位向量将如下式子最大化:
)中的一点,因此为了最大化投影点的方差,我们需要选择一个单位向量将如下式子最大化:
,其中
代表样本点的个数。
注意:实际上样本方差和协方差的公式应该是 ,此处为方便用,对结果没有影响。
,此处为方便用,对结果没有影响。
其中 ,
,![]() ,
, ,代入到
,代入到 ,得:
,得:

令![]() ,则上式最终简化为
,则上式最终简化为![]() ,
, 即为原始变量
即为原始变量 的协方差矩阵。
的协方差矩阵。
【知识点2】:
转置矩阵性质:
我们是要求方差最大化,如果越大的话,总体方差也就越大,鉴于我们只想求的方向,而不想依赖于的长度,我们让为一个标准化的向量(单位向量)。接下来, 我们可以通过拉格朗日乘子法构造下面方程:
![]()
![]()
关于拉格朗日乘子法详细解析请见【如何理解拉格朗日乘子法? 】
对其变形:![]()
对其求的偏导:![]() ,即当
,即当![]() 时,
时,![]() 取最大值。
取最大值。
根据上面的【知识点1】,我们可以得出:是方阵的特征值,称为的对应于特征值的特征向量。
此时最大方差为![]() (是一个常数,可以提取出来
(是一个常数,可以提取出来![]() ,又因为
,又因为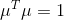 ,得
,得![]() )。
)。
即得出结论,PCA降维,即为求协方差矩阵的特征值和特征向量,![]() 即为原始数据的协方差矩阵。
即为原始数据的协方差矩阵。
【定理1】对于任意向量
对称矩阵
为
,则
极值 极值点 注意:以上
的限制条件其实就是
。我们以
为例,对求
,
是
,则
。因为
是一个常数,可以提到最前,得:
,最后得到:
和
是垂直的(
,因为
和
则
【定理2】记
为协方差矩阵
是标准化的特征向量。
则变量
的第
个主成分由下式给出:
性质1:
性质2:
性质3:
,即变换后的数据还原了原始数据的信息(方差总和相同)
证明:我们知道变化之后的方差之和为:
,原始数据的方差之和
为协方差矩阵
;我们知道
关于矩阵迹和特征值得关系可见《线性代数——韦达定理、矩阵行列式、矩阵的迹、矩阵特征值及关系》
在这边,特征向量我们可以理解为转换的方向,特征值,我们可以理解为平移的速度。
【知识点3】:
教科书上求
求出n阶方阵A的特征多项式
。
求出特征方程
,......,
,即为A的特征值。
把每个特征值
代入线性方程组
,求出基础解系,就是A对应于
我们可以对上面的例子求下解。
对原始数据集去中心化得到:
,我们以
求出协方差矩阵
求解特征多项式
,得
,
。
当
,当
,再结合求得的向量为单位向量
,求得
,
。
按照特征值大小排列,得主成分矩阵为
。
2、PCA算法的python实现
import numpy as np
dataMat=pd.DataFrame([[10,9],
[2,3],
[1,2],
[7,6.5],
[3,2.5]])
meanVals=np.mean(dataMat,axis=0) #求dataMat各列均值
meanRemoved=dataMat-meanVals #减去原始数据中的均值,避免协方差计算中出现乘以0的情况
covMat=np.cov(meanRemoved,rowvar=0) #rowvar=0-->以列代表一个变量,计算各列之间的协方差
eigVals,eigVects=np.linalg.eig(np.mat(covMat)) #协方差矩阵的特征值和特征向量
eigVals
eigVects输出:
array([23.32440667, 0.15059333])
matrix([[ 0.78139452, -0.62403734],
[ 0.62403734, 0.78139452]])去中心化的数据集乘以主成分矩阵,即为降维后的数据,注意:此时eigVects中一列是代表着一个特征向量。
meanRemoved*eigVects输出:
matrix([[ 6.96529471, 0.06833426],
[-3.0300855 , 0.37226585],
[-4.43551736, 0.21490867],
[ 3.0610178 , -0.01304002],
[-2.56070965, -0.64246875]])3、利用sklearn中的PCA进行降维
import numpy as np
from sklearn.decomposition import PCA
#导入数据
x=np.array([[10,9],
[2,3],
[1,2],
[7,6.5],
[3,2.5]])
x
x_t=x-x.mean() #去中心化
x_t
#降维
model_pca=PCA() #建立PCA模型对象
model_pca.fit(x1) #将数据输入模型
x_=model_pca.transform(x1) #将数据集进行转换映射,x_为进行降维过后的数据集,形状和原数据集一样
components=model_pca.components_ #获得转换后的所有主成分
components_var=model_pca.explained_variance_ #获得各主成分的方差
components_var_ratio=model_pca.explained_variance_ratio_ #获得各主成分的方差占比
x_
components
components_var
components_var_ratio输出:


【参数解析】:
- x:原始数据集
- x_t:原始数据集去中心化后的数据集
- x_:降维过后的数据集
- components:转换过后的所有主成分,算法的重点在于求出此主成分(矩阵);原数据集去中心化之后,乘以该主成分(矩阵),即为降维过后的数据集。有如下关系
- components_var:转换过后的数据集x_各维度(注:形状和原始数据集一样,但是维度和原始数据集的完全不一样)的数据方差,即x_.var()
- components_var_ratio:components_var中各维度的方差,占全部维度方差之和的比例。
4、基于标准化变量的主成分分析
如果变量![]() 的波动性(由于度量单位不同等原因)差距过大,直接用协方差矩阵生成的主成分会由方差大的变量主导。
的波动性(由于度量单位不同等原因)差距过大,直接用协方差矩阵生成的主成分会由方差大的变量主导。
这个时候,我们可对每个变量分别进行标准化:![]() ,
,![]() ,
,![]() 为单个变量的标准差。
为单个变量的标准差。
则标准化之后的数据![]() ,其中
,其中![]() ,为原始数据,为原始数据的均值向量。
,为原始数据,为原始数据的均值向量。
所以对标准化后的数据进行主成分分析,即求的协方差矩阵![]() ,进而求
,进而求![]() 的特征值和特征向量。
的特征值和特征向量。
![]() ,其中
,其中![]() 即为原数据的协方差矩阵,
即为原数据的协方差矩阵,![]() 为对角阵,则
为对角阵,则![]() ,代入得:
,代入得:![]() (即为的相关系数矩阵) 。
(即为的相关系数矩阵) 。
总结:由于![]() (即为的相关系数矩阵),则对
(即为的相关系数矩阵),则对![]() 进行主成分分析,就相当于基于原变量
进行主成分分析,就相当于基于原变量![]() 的相关系数矩阵进行主成分分析。
的相关系数矩阵进行主成分分析。
【定理3】记
,...,
为
并且特征向量
是标准化的特征向量。
则对
进行主成分分析,相当于基于原变量
性质:
(注意:相关系数矩阵
【小贴士2】
基于相关系数矩阵
如果变量数值差异很大,推荐进行标准化来获得一个较平衡的数据集。
5、主成分个数的选择
在主成分分析中,为了有效地归纳数据、达到降维目的,应该使用多少个主成分?
5.1、百分比截点(Percentage cutoff)
使用足够多的主成分来反映一定百分比(比如80%)的总方差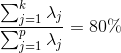 。
。
5.2、平均比截点(Average cutoff)
使用特征值大于平均特征值![]() 的主成分;对使用相关矩阵做的主成分分析来说,这个平均值为1。
的主成分;对使用相关矩阵做的主成分分析来说,这个平均值为1。
平均截点准则广为使用,是很多软件包的默认准则。
当数据能够在相对较小的维度下被很好地归纳时,特征值可以明显地地分为“大特征值”和“小特征值”。
5.3、碎石图 (Scree graph):
画出关于的图像,从图上寻找能区分“大特征值”和“小特征值”的分界点。

6、案例分析:主成分的解读
例:下表记录了52位学生6门功课的考试分数的部分数据,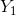 到
到![]() 依次表示数学、物理、化学、语文、历史、英语成绩,部分数据如下:
依次表示数学、物理、化学、语文、历史、英语成绩,部分数据如下:
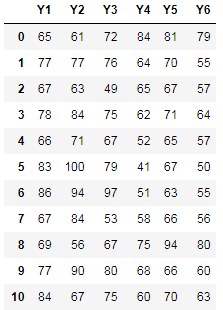
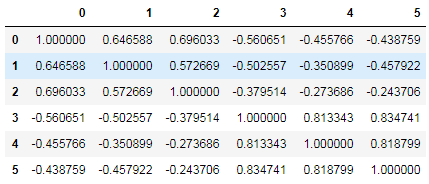
6.1、计算相关系数矩阵
corr=pd.DataFrame(np.corrcoef(data,rowvar=0))
corr输出:
6.2、数据标准化
#数据标准化
data_=(data-data.mean(0))/data.std()
data_输出:

6.3、sklearn实现PCA降维
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
from sklearn.decomposition import PCA
model_pca=PCA() #建立PCA模型对象
model_pca.fit(data_) #将数据输入模型
x_=model_pca.transform(data_) #将数据集进行转换映射,x_为进行降维过后的数据集,形状和原数据集一样
components=model_pca.components_ #获得转换后的所有主成分
components_var=model_pca.explained_variance_ #获得各主成分的方差
components_var_ratio=model_pca.explained_variance_ratio_ #获得各主成分的方差占比
components
components_var
components_var_ratio输出:
array([[-0.41205198, -0.38117795, -0.33213465, 0.46118457, 0.4205876 ,
0.43013716],
[-0.37597731, -0.356706 , -0.5626165 , -0.27852313, -0.41478358,
-0.40650217],
[ 0.21582978, -0.80555264, 0.46743533, -0.04426879, -0.25039004,
0.14612244],
[-0.78801362, 0.11755209, 0.58763655, -0.02783261, -0.03376008,
-0.13410793],
[ 0.0205822 , -0.21203603, 0.0333622 , -0.59904487, 0.73843439,
-0.22218 ],
[ 0.14450829, -0.14061074, 0.09068468, 0.59003773, 0.20479353,
-0.74902427]])
array([3.70990438, 1.26248122, 0.44083653, 0.27050177, 0.16951589,
0.14676021])
array([0.6183174 , 0.21041354, 0.07347275, 0.04508363, 0.02825265,
0.02446003])其中,components代表的是所有的主成分,第一行代表的是第一个主成分,第二行代表的是第一个主成分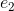 ,以此类推。由components_var_ratio我们知道前两个主成分对应的方差之和为0.8287309(超过80%)
,以此类推。由components_var_ratio我们知道前两个主成分对应的方差之和为0.8287309(超过80%)
6.3、画碎石图,选择主成分个数
import matplotlib.pyplot as plt
plt.plot(components_var,marker='o')输出:
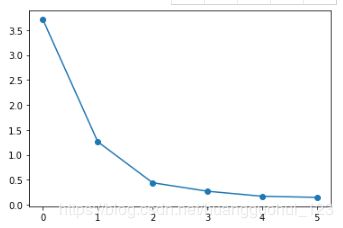
我们也可以通过观测碎石图,得出结论:取前两个主成分进行进一步的研究。
6.4、解读
根据以上两个主成分,我们是可以写出主成分的构造方式,如下:
![]()
![]()
我们可以将其理解为两个综合指标,那么我们如何来解读呢?
由下图的分解,我们可以将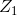 指标理解为文理科的偏科情况,
指标理解为文理科的偏科情况,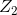 可以理解为全部科目的平均分。
可以理解为全部科目的平均分。

有了这两个指标的意义,进一步探索一些典型学生的样本主成分取值/得分?
x_.round(2)[[5,6,44],:]
data.iloc[[5,6,44],:]输出:

例如:5,6,44号同学,利用上面的结论:第一列代表的是偏科情况(数值越大文科越好,越小理科越好),说明这三位同学是理科成绩要好于文科(注意:“各科主成分得分”是经PCA降维之后的数据x_),对应我们查看其原始成绩数据:发现确实其理科成绩要优于文科成绩。
x_.round(2)[[29,48],:]
data.iloc[[29,48],:]输出:
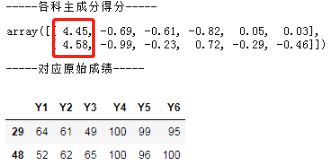
29,48号同学,情况正好相反:文科成绩要好于理科。
print('-----各科主成分得分-----')
x_.round(2)[[25,32],:]
print('-----对应原始成绩-----')
data.iloc[[25,32],:]输出:

25,32号同学,利用上面的结论:第二列代表的是均衡情况(数值越大总成绩越小,越小总成绩越高),说明这二位同学总成绩是比较高的(各科成绩相对均衡)。
print('-----各科主成分得分-----')
x_.round(2)[[7],:]
print('-----对应原始成绩-----')
data.iloc[[7],:]输出:

7号同学,情况正好相反:总成绩比较低(不理想)。
二、奇异值分解(SVD)
1、SVD定义
SVD可以看成是对PCA主特征向量的一种解法,在上述PCA介绍过程中,为了求数据的主特征方向,我们通过求协方差矩阵![]() 的特征向量来表示样本数据的主特征向量,但其实我们可以通过对X进行奇异值分解得到主特征方向,下面我们首先比较一下特征值分解和奇异值分解,然后分析一下特征值和奇异值的关系以及SVD在PCA中的应用。
的特征向量来表示样本数据的主特征向量,但其实我们可以通过对X进行奇异值分解得到主特征方向,下面我们首先比较一下特征值分解和奇异值分解,然后分析一下特征值和奇异值的关系以及SVD在PCA中的应用。
SVD也是对矩阵进行分解,但是和特征分解不同,SVD并不要求要分解的矩阵为方阵。假设我们的矩阵A是一个m行×n列的矩阵(注意:只有行数m>列数n的矩阵才能进行svd分解),那么我们定义矩阵A的SVD为:
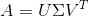
其中 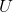 是一个
是一个  的矩阵, 是一个 的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,
的矩阵, 是一个 的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,  是一个
是一个 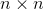 的矩阵。 和 都是酉矩阵,即满足
的矩阵。 和 都是酉矩阵,即满足![]() ,
,![]() 。下图可以很形象的看出上面SVD的定义:
。下图可以很形象的看出上面SVD的定义:

2、如何求出SVD分解后的U,Σ,V这三个矩阵
- 矩阵:将A的转置和A做矩阵乘法,得到n×n的一个方阵
 ,得到的特征值和特征向量满足下式:
,得到的特征值和特征向量满足下式: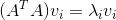 。这样可以得到矩阵 的n个特征值和对应的n个特征向量
。这样可以得到矩阵 的n个特征值和对应的n个特征向量 了。将的所有特征向量张成一个n×n的矩阵V,就是我们SVD公式里面的V矩阵了。一般我们将V中的每个特征向量叫做A的右奇异向量。
了。将的所有特征向量张成一个n×n的矩阵V,就是我们SVD公式里面的V矩阵了。一般我们将V中的每个特征向量叫做A的右奇异向量。 -
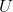 矩阵:将A和A的转置做矩阵乘法,得到m×m的一个方阵
矩阵:将A和A的转置做矩阵乘法,得到m×m的一个方阵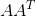 ,得到的特征值和特征向量满足下式:
,得到的特征值和特征向量满足下式: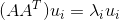 。这样可以得到矩阵 的m个特征值和对应的m个特征向量
。这样可以得到矩阵 的m个特征值和对应的m个特征向量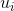 了。将的所有特征向量张成一个m×m的矩阵U,就是我们SVD公式里面的U矩阵了。一般我们将U中的每个特征向量叫做A的左奇异向量。
了。将的所有特征向量张成一个m×m的矩阵U,就是我们SVD公式里面的U矩阵了。一般我们将U中的每个特征向量叫做A的左奇异向量。 - 矩阵:由于Σ除了对角线上是奇异值其他位置都是0,那我们只需要求出每个奇异值σ就可以了。
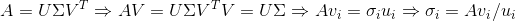 ,根据
,根据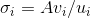 算出每一个奇异值
算出每一个奇异值 ,组成的矩阵等于
,组成的矩阵等于,
矩阵为m行*n行的矩阵。
【问题】
为什么
以V矩阵的证明为例。
上式证明使用了
,
。可以看出
进一步我们还可以看出我们的特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
这样也就是说,我们可以不用
得到,取的前个列向量即可,注意:np.linalg.svd()算法得到的是右奇异矩阵的转置矩阵。
左奇异矩阵可以用于行数的压缩。
右奇异矩阵可以用于列数即特征维度的压缩,也就是我们的PCA降维。
3、SVD算法的python实现
import numpy as np
dataMat=pd.DataFrame([[10,9],
[2,3],
[1,2],
[7,6.5],
[3,2.5]])
meanVals=np.mean(dataMat,axis=0) #求dataMat各列均值
meanRemoved=dataMat-meanVals #减去原始数据中的均值,避免协方差计算中出现乘以0的情况
U,sigma,VT = np.linalg.svd(meanRemoved) #svd分解
U
sigma
VT #矩阵V的转置矩阵输出:
array([[-0.72111445, -0.08804519, 0.3845965 , -0.3104834 , 0.47741762],
[ 0.31370366, -0.47964546, -0.36128726, 0.08356321, 0.73076601],
[ 0.45920751, -0.2768988 , 0.8388389 , 0.09029741, 0.02551835],
[-0.31690607, 0.0168014 , 0.07527715, 0.94221156, 0.07654401],
[ 0.26510935, 0.82778805, 0.11063315, 0.02647648, 0.48118945]])
array([9.65906966, 0.77612712])
array([[-0.78139452, -0.62403734],
[ 0.62403734, -0.78139452]])
三、主成分分析的特点
- 有多少个变量就会有多少个正交的主成分;
- 主成分的变异(方差)之和等于原始变量的所有变异(方差);
- 前几大主成分的变异(方差)累计可以解释原多元数据中的多数变异(方差);
- 原始自变量间有较高线性相关的情况下可以考虑使用主成分分析,如果原始变量不相,则不需要做主成分分析;
- 主成分分析适用于正态分布的变量,商业分析中右偏型数据可以通过取对数、Tukey正态性打分等方式可转换为接近正态分布。