深度学习文章阅读2--3D Convolutional Neural Networks for Human Action Recognition
摘要
本文希望在监控视频中识别人体行为。当前的方法大都从原始输入数据中计算复杂的手工特征来构建分类器;CNN是一种深度神经网络模型,但当前CNN仅能处理2D的输入;在本文中我们构建了一个3D CNN模型来完成行为识别,该模型通过执行3D卷积从空间和时间维度提取特征,从而捕获在多个相邻帧中编码的运动信息。该模型从输入帧生成多个信道,最后的特征表示组合了来自所有信道的信息。为了进一步提高性能,本文用不同的模型来预测性能,并将所提出的模型运用到实际环境中,即机场监控视频,取得了不错的效果。
关键词 深度学习 卷积神经网络 3D卷积 模型组合 行为识别
1.引言
识别可应用于诸多领域,如真实环境中视频监控,客户属性和购物行为分析等;但由于背景混乱、闭塞和视觉变化等原因(cluttered backgrounds,occlusions &viewpoing variations),对行动的准确识别是一项非常具有挑战性的任务。目前的大多数方法对视频采取了想当然的假设,例如,小规模和观点变化;但这样的假设在现实环境中很少存在。此外,大多数方法遵循两步法,第一步计算原始视频帧的特征,第二步基于获得的特征学习分类器。在现实场景下,因为特征高度依赖于问题,我们很少知道什么特征对于手头的任务是重要的;特别是对于人类行为的识别,不同的动作类别在外观和运动模式方面可能会显得不同。
深度学习模型可以通过低级别的功能来构建高级功能,从而来学习功能的层次结构。这类模型可以采用监督或无监督的方法进行训练,并在视觉物体识别、人体形态识别、自然语言处理、视频分类脑机互动、人类跟踪、图像恢复、去噪和分割等任务上都取得了不错的效果。卷积神经网络(CNN)是一种深层模型,可训练滤波器和局部邻域池化操作交替地应用于原始输入图像,以此形成越来越复杂的特征层次结构。现有成果以已经表明,利用适当的正规化(regularization)进行训练时,CNN可以在视觉对象识别任务上实现卓越的性能;此外,CNN对姿势、照明和周围的杂乱性能不变。
CNN主要应用于2D图像,而在本文中,我们探讨了CNN在人类行为识别中的运用。目前有一个简单的方法,将视频帧视为静止图像(still images),并应用CNN来识别单个帧的动作;该方法已被应用于分析发育胚胎的视频。然而,这种方法不考虑在多个连续帧中编码的运动信息。为了有效地将视频分析中的运动信息结合起来,我们提出在CNN的卷积层中执行3D卷积,从而捕获空间和时间维度的区分特征。实验表明,在输入数据相同位置上执行多种卷积计算,可以提取出多种类型的特征;基于提出的3D卷积,我们可以设计出各种3D CNN架构来分析视频数据。本文中我们开发了一种3D CNN架构,从相邻的视频帧中生成多个信道,并在每个信道中执行卷积和二次采样。通过组合来自所有信道的信息来获得最终的特征表示,为了进一步提高3D CNN模型的性能,我们提出将辅助输出的模型扩展为高级运动特征,并将各种不同架构的输出集成在预测中。
本文在TREC视频检索评估(TRECVID)数据上评价了提出的3D CNN模型,该数据集包括了伦敦机场的监控视频数据。本文构建了一个多模块事件检测系统,其中3D CNN作为主要模块,并参加了TRECVID 2009评估监控事件检测的三个任务(即CellToEar,ObjectPut和Pointing),在三个任务上都取得了最佳表现。同时,也在KTH数据集上评估了模型性能,实验表明,开发的3D CNN模型在TRECVID数据上的结果优于其他基线方法,并且在KTH数据上实现了竞争性的表现,这表明:1)3D CNN对真实环境更为有效;2)3D CNN 在大多数任务中优于基于帧的2D CNN。
本文的关键性贡献总结如下:
我们建议通过用作为高级运动特征计算的辅助输出来扩展模型,从而规范3D CNN模型,并进一步提出通过结合各种不同架构的输出来提高3D CNN模型的性能。
我们开发了基于3D卷积特征提取器的3D卷积神经网络架构。该CNN架构从相邻视频帧生成多个信道信道,并在每个信道中单独执行卷积和子采样,通过组合来自所有通道的信息来获得最终特征表示。
与基线方法和替代架构相比,我们在TRECVID 2008数据集上评估了3D CNN模型;实验结果表明,提出的模型明显优于2D CNN架构和其他基线方法。
本文的组织结构如下:第2节描述在TRECVID识别系统中采用的3D卷积运算和3D CNN架构;第3节讨论了相关工作;第4节总结了TRECVID和KTH数据集上的实验结果;第5节对本文工作进行总结。
2.3D卷积神经网络
在2D CNN中,在卷积层上执行2D卷积,以从前一层的特征图上的局部邻域提取特征。然后施加加法偏差,并使结果通过sigmoid函数。通常第i层第j个特征图中的位置(x,y)的值计算公式如(1)所示。

公式中,tanh()是双曲正切函数,bij是偏差,Pi和Qi是卷积核的高度和宽度。在子采样层中,通过在上一层的特征图上的局部邻域进行汇总来减少特征图的分辨率,从而增强输入上的失真不变性。可以通过以交替方式堆叠多层卷积和子采样来构建CNN架构,而CNN的参数,如偏差bij和卷积核权重w,通常经监督或无监督的方式进行学习。
2.1 3D卷积
在二维CNN中,卷积应用于2D特征图,仅从空间维度计算特征。当利用视频数据分析问题时,我们期望捕获在多个连续帧中编码的运动信息。为此,提出在CNN的卷积阶段进行3D卷积,以计算空间和时间维度的特征;通过将3D内核与多个相邻帧叠加在一起形成的立方体卷积来实现3D卷积。通过这种结构,卷积层中的特征图连接到上一层中的多个相邻帧,从而捕获运动信息。通常第i层第j个特征图中的位置(x,y,z)计算公式如(2)所示。
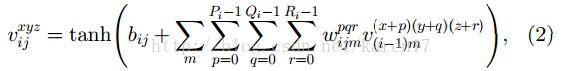
公式中Ri是沿着时间维度的3D内核的大小。2D卷积和3D卷积的对比如图1所示。

图1 2D CNN 与3D CNN的对比
在(b)中,时间维度中卷积核的大小为3,并且连接集是彩色编码的,使得在相同的颜色中共享权重。在3D卷积中,将相同的3D内核应用于输入视频中的重叠3D立方体以提取运动特征。
与2D卷积类似,可将不同内核的3D卷积应用于上一层中的相同位置,详见图2。
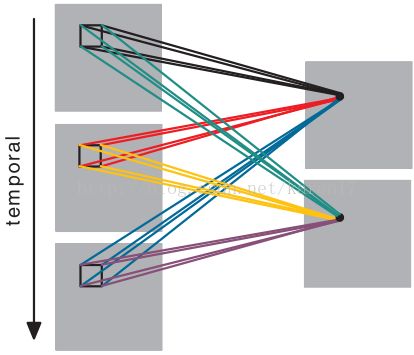
图2 从连续帧中提取特征
可以将多个3D卷积应用于连续帧以提取多个特征。如图1所示,连接组是彩色编码的,所以相同的颜色共享权重。由于六组连接不共享权重,导致图2右侧产生两种结果。
2.2 3D CNN结构
基于上述3D卷积,可以设计出各种CNN架构。在下文中,我们描述了为TRECVID数据集中的人为动作识别开发的3D CNN架构,如图3所示。
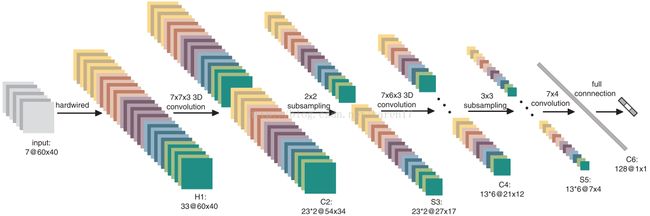
我们考虑以当前帧为中心的大小为60 * 40的七帧,作为3D CNN模型的输入。我们首先应用一组硬连线内核(hardwired kernels)从输入帧生成多个信道,由此在第二层在灰色,渐变x,渐变y,optflow-x和 optflow-y这五个通道中得到了33个特征图,其中灰色通道包含了七个输入帧的灰色像素值。在七个输入帧的水平和垂直方向计算梯度得到gradient-x和gradient-y,并在相邻帧间计算沿水平和垂直方向的光流场得到optflow-x和optflow-y。
随后我们在五个通道上应用大小为7x7x3的3D卷积,7x7是空间维度,3是时间维度;为了增加特征图的数目,在每个位置上应用两种不同的卷积,这使得C2层的每组特征图集中各有23个特征图。在随后的子采样层S3中,我们在C2层中的每个特征图上应用2×2子采样,这降低了空间分辨率,并得到了与C2层相同数量的特征图。接着我们在两种特征图集的五个通道上分别运用7x6x3的卷积,为了增加特征图的数量我们在每个位置上运用了3中卷积,这使得在C4层有6个特征图集,每个包含13个特征图。然后对C4中的每个特征图运用3x3的子采样,以得到S5层,S5层与C4层特征图数目相同,仅降低了空间分辨率。在此阶段,时间维度的尺寸已相对较小,灰色,梯度-x和梯度-y为3,optflow-x和opttflow-y为2,所以我们仅在该层的空间维度上执行卷积操作。卷积核大小设定为7x4,由此输出的特征图大小缩小为1x1,C6层包含了128个大小为1x1的特征图,并且它们中的每一个都连接到S5层中的所有78个特征图。
经多层卷积和子采样后,七个输入帧已被转换为128D的可以在输入帧中捕获运动信息的特征向量,输出层由与动作数相同数量的单元组成,每个单元与C6层的128个单元全链接。在本设计中,我们在128D的特征向量上应用线性分类器来进行动作分类,该模型中的所有可训练参数都随机初始化,并通过在线误差反向传播算法进行训练。
2.3 模型正则化
随着输入窗口大小的增加,可训练参数数量增加,而3D CNN模型的输入被限制在少量的连续帧中;另一方面,许多人类行为跨越了多个帧,由此,应将高级运动信息编码到3D CNN模型中。为此我们提出从大量帧中计算运动特征,并通过运用这些运动特征作为辅助来规范3D CNN 模型,如图4所示。
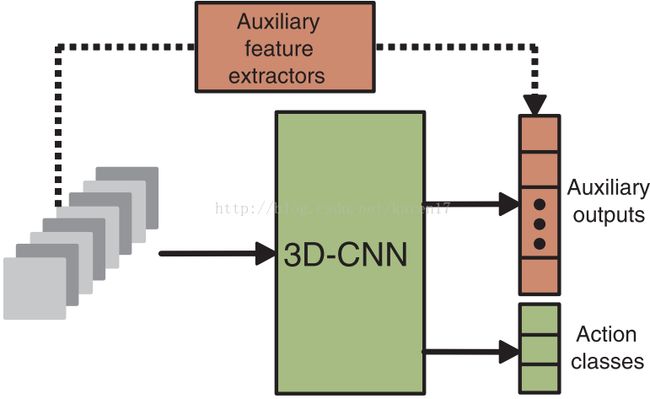
对于每个训练动作,我们生成一个特征向量,将特征向量编码到长期动作信息中。随后我们鼓励CNN去学习一个靠近此特征向量的特征向量,这是通过将多个辅助输出单元链接到CNN的最后一个隐藏层,并在训练期间将计算出的特征向量夹在辅助单元上来实现。这将鼓励隐藏层信息靠近高级运动信息,在本实验中,我们使用在原始灰度图上和MEHI(motion edge history images)计算得到的SIFT描述符作为辅助特征,结果表明这样的正则化方法能提高性能。
2.4 模型融合
在本文中,我们提出构建具有不同架构的3D CNN模型,从而从输入中捕获潜在的补充信息;而在预测阶段,给出每个模型的输入,然后组合这些模型的输出。
2.5 模型实现
本文利用C++实现3D CNN模型,是NEC人类动作识别系统的一部分,所有子采样层都应用最大采样,用于训练正则化模型的总体损失函数是由真实动作类别和辅助输出引起的损失函数的加权求和。真实动作类的权重设置为1,辅助输出的权重设定为0.005,所有模型参数随机初始化,并使用随机对角线Levenberg-Marquardt进行训练,在该种方法中,在这种方法中,使用在1000个随机抽样的训练实例上的Hessian矩阵的Gauss-Newton近似估计的对角项来计算每个参数的学习率。
实验
本文在TRECVID2008和KTH数据集上完成了实验。
3.1 在TRECVID数据集上实验
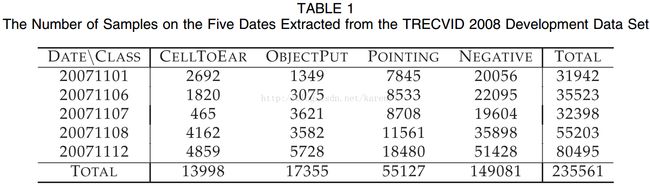
TRECVID 2008数据集包括了在伦敦机场拍摄的49小时的视频,在当前的实验中,我们专注于三个动作类(CellToEar,ObjectPut和Pointing)的识别。 每个动作都是以一对一的方式分类,并且在这三个类之外的动作产生大量的负样本。实验中使用的数据总结如表1。
由于视频被记录在现实环境中,每帧包含多个人,所以我们应用人体检测器和检测驱动的跟踪器来定位人的头部。定位的示例结果如图5所示。

基于检测和跟踪结果,计算出执行动作的每个人的边界框。 图3显示了3D CNN模型所需的多个帧是通过从当前帧之前和之后的连续帧中提取相同位置的边界框来获得的, 包含动作的多维数据集。在我们的实验中,立方体的时间维度设置为7,因为已经显示5-7个帧足以实现与整个视频序列可获得的性能相似的性能,以2的步长提取帧。如果当前位置为0,我们从编号为-6,-4,-2,0,2,4,6的帧的相同位置提取一个边界框,每个框中的patch被缩放到60x40像素。
与其他论文中的对比结果,详见原文。
3.2 在KTH数据集上的实验
我们对KTH数据上的3D CNN模型进行评估,其中包括由25名受试者执行的六个动作类,我们使用9帧立方体作为输入,为了减少内存需求,输入帧的分辨率降低到80x60。我们使用与图3相似的3D CNN结构,考虑到输入为80x60x9,则每层的内核大小和特征图数量相应需要做出修改;三个卷积层分别选用尺寸为9x7,7x7和6x4的内核,且两个子采样层使用大小为3x3的内核。通过这样的设置,80x60x9的输入将转换为128D的特征向量,最后一层由6个单位组成,对应6个类别。我们使用16个随机选择的受试者的数据进行训练,其他9个受试者的数据用于测试。多数投票用于根据个别帧的预测来生成视频序列的标签。五个随机试验中的识别性能平均值与文献中公布的结果一并报告在表5中。
与其他论文中的对比结果,详见原文。
4 结论
本文研究了3D CNN 模型进行动作识别,这类模型从空间和时间维度执行3D卷积来构建特征,开发的深层架构从相邻输入帧生成多个信道信道,并在每个信道中分别执行卷积和子采样,通过组合来自所有通道的信息来获得最终特征表示。我们开发了模型正则化和组合方案,以进一步提高模型性能,最后在TRECVID和KTH数据集上评估了3D CNN模型。