2、kafka环境搭建
这里写自定义目录标题
- 安装前准备
- Java安装
- 第一步、卸载
- 第二步、安装
- 二、搭建Zookeeper集群
- The number of milliseconds of each tick
- The number of ticks that the initial
- synchronization phase can take
- The number of ticks that can pass between
- sending a request and getting an acknowledgement
- the directory where the snapshot is stored.
- do not use /tmp for storage, /tmp here is just
- example sakes.
- the port at which the clients will connect
- the maximum number of client connections.
- increase this if you need to handle more clients
- Be sure to read the maintenance section of the
- administrator guide before turning on autopurge.
- http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
- The number of snapshots to retain in dataDir
- Purge task interval in hours
- Set to "0" to disable auto purge feature
- 三、搭建kafka集群
- 四、kafka web管理安装
- 五、kafka测试
安装前准备
1、NTP时间同步
yum install ntp
systemctl enable ntpd
sudo vi /etc/sysconfig/ntpd
添加-x参数,如“-g -x”
sudo service ntpd restart
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
date
2、修改机器名
vim /etc/hostname
reboot
3、安装规划
地址 安装软件 机器配置
192.168.12.60 zk、kafka 2核4G内存40G磁盘
192.168.12.61 zk、kafka 2核4G内存40G磁盘
192.168.12.62 zk、kafka 2核4G内存40G磁盘
4、修改注解域名解析文件
vim /etc/hosts
添加内容(中间为制表符)
192.168.12.60 kafka1
192.168.12.61 kafka2
192.168.12.62 kafka3
Java安装
第一步、卸载
(1)查看已经安装的jdk
输入指令:rpm -qa | grep jdk
如果没有则没有输出,如果有则输出如下:
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
(2)卸载jdk
输入指令:
yum -y remove java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
测试是否卸载:
java -version
第二步、安装
安装准备,安装lrzsz文件传输工具
yum -y install lrzsz
yum -y install vim
(1)下载JDK
甲骨文下载地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
(2)发送文件至服务器
将下载的jdk-8u171-linux-x64.tar.gz安装包拖拽到xshell中即可传输;
(3)解压
创建目录/usr/local/java:
mkdir /usr/local/java
解压到刚创建目录:
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/java
(4)修改环境变量配置
编辑环境变量文件:
vim /etc/profile
编辑在最后添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export JER_HOME= J A V A H O M E / j r e e x p o r t C L A S S P A T H = . : {JAVA_HOME}/jre export CLASSPATH=.: JAVAHOME/jreexportCLASSPATH=.:{JAVA_HOME}/lib: J R E H O M E / l i b e x p o r t P A T H = {JRE_HOME}/lib export PATH= JREHOME/libexportPATH={JAVA_HOME}/bin:$PATH
更新环境变量,使之生效:
source /etc/profile
(5)检查是否安装成功
java -version
二、搭建Zookeeper集群
每台机器都需要安装Zookeeper,所以如下操作都需要在每台机器执行
(1)上传Zookeeper或直接下载Zookeeper
cd /opt
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
解压
tar -zxvf zookeeper-3.4.6.tar.gz
为操作方便建立软连接
ln -s zookeeper-3.4.6 zk
(2)修改配置文件
cd /opt/zk/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改内容如下
The number of milliseconds of each tick
tickTime=2000
The number of ticks that the initial
synchronization phase can take
initLimit=10
The number of ticks that can pass between
sending a request and getting an acknowledgement
syncLimit=5
the directory where the snapshot is stored.
do not use /tmp for storage, /tmp here is just
example sakes.
dataDir=/opt/zk/data
the port at which the clients will connect
clientPort=2181
the maximum number of client connections.
increase this if you need to handle more clients
#maxClientCnxns=60
Be sure to read the maintenance section of the
administrator guide before turning on autopurge.
http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
Purge task interval in hours
Set to “0” to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.12.60:2888:3888
server.2=192.168.12.61:2888:3888
server.3=192.168.12.62:2888:3888
#server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#192.168.xx为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
(3)创建文件夹
mkdir /opt/zk/data
(4)创建myid文件
所有机器执行
touch /opt/zk/data/myid
60机器
echo “1” > /opt/zk/data/myid
61机器
echo “2” > /opt/zk/data/myid
62机器
echo “3” > /opt/zk/data/myid
(5)设置环境变量
vim /etc/profile
在末尾添加Zookeeper环境变量
export ZK_HOME=/opt/zk
export PATH= Z K H O M E / b i n : {ZK_HOME}/bin: ZKHOME/bin:PATH
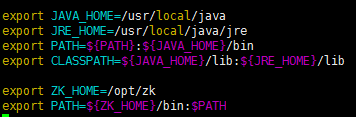
source /etc/profile
(6)启动Zookeeper集群
所有机器关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
每台机器上启动Zookeeper
zkServer.sh start
启动后查看启动结果
zkServer.sh status
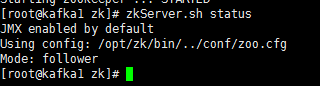
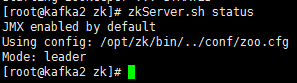
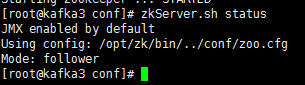
如需停止则使用如下命令
zkServer.sh stop
查看Zookeeper启动错误日志
cat /opt/zk/zookeeper.out
查看Zookeeper是否启动
jps

三、搭建kafka集群
解压安装包
tar -zxvf kafka_2.11-2.2.0.tgz -C /usr/local/
ln -s /usr/local/kafka_2.11-2.2.0 /usr/local/kafka
配置环境变量
vim /etc/profile
添加内容
export KAFKA_HOME=/usr/local/kafka
export PATH= P A T H : PATH: PATH:KAFKA_HOME/bin
使环境变量生效
source /etc/profile
修改配置文件
cd /usr/local/kafka/config/
vim server.properties
60机器修改内容如下
broker.id=1 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
listeners=PLAINTEXT://192.168.12.60:9092
log.dirs=/usr/local/kafka/data
zookeeper.connect=192.168.12.60:2181,192.168.12.61:2181,192.168.12.62:2181
61机器修改内容如下
broker.id=2 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
listeners=PLAINTEXT://192.168.12.61:9092
log.dirs=/usr/local/kafka/data #多个则以逗号隔开
zookeeper.connect=192.168.12.60:2181,192.168.12.61:2181,192.168.12.62:2181
62机器修改内容如下
broker.id=3 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样
listeners=PLAINTEXT://192.168.12.62:9092
log.dirs=/usr/local/kafka/data
zookeeper.connect=192.168.12.60:2181,192.168.12.61:2181,192.168.12.62:2181
所有机器创建kafka数据目录
mkdir -p /usr/local/kafka/data
启动kafka集群(所有机器)
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
![]()
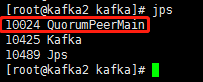
检查启动是否正常
jps
四、kafka web管理安装
方式一:kafka-mamager工具
这里选择的是yahoo 的kafka-mamager工具,先下载二进制包kafka-manager-1.3.3.7.zip
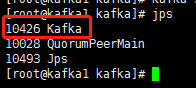
安装解压
cd /opt
unzip kafka-manager-1.3.3.7.zip
mv kafka-manager-1.3.3.7 kafka-manager
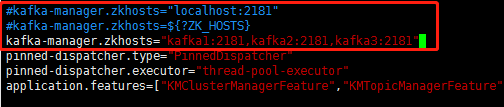
编辑配置文件
cd /opt/kafka-manager/conf/
vim application.conf
添加内容
kafka-manager.zkhosts=“kafka1:2181,kafka2:2181,kafka3:2181”
启动kafka-manager
chmod 777 /opt/kafka-manager/bin/kafka-manager
nohup /opt/kafka-manager/bin/kafka-manager &


启动之后当前目录会有一个nohup.out控制台输出日志
注意
kafka-manager 默认的端口是9000,可通过
-Dhttp.port,指定端口;
-Dconfig.file=conf/application.conf指定配置文件
如下所示
nohup ./kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8080
查看启动情况
jps

访问地址
http://192.168.12.60:9000/
添加族参数
Add Cluster
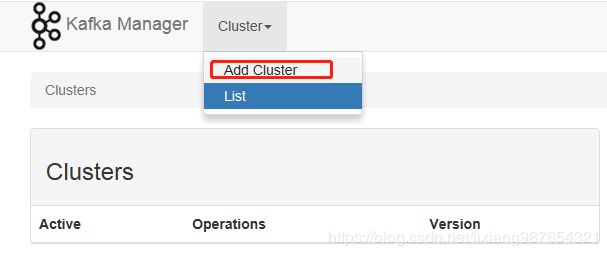
添加参数配置如下
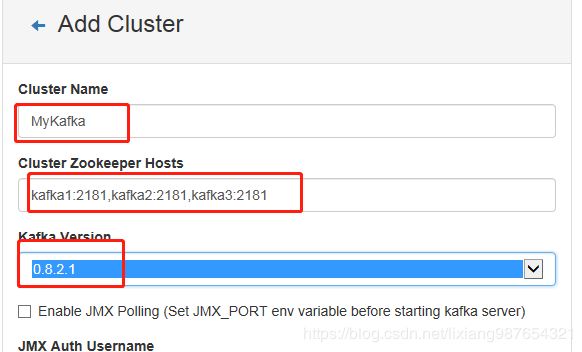
然后保存,最后添加如下
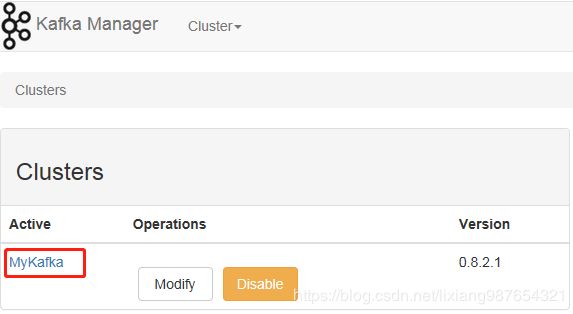
点击进去,然后就可以通过web页面查看集群所有信息了
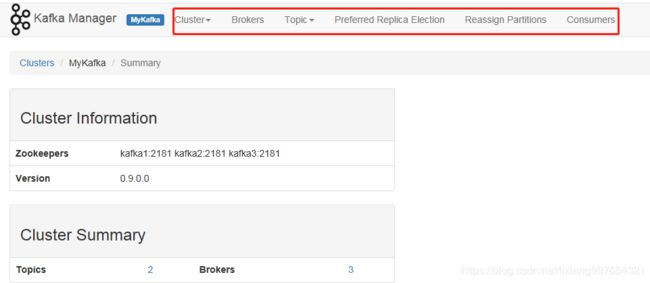
方式二:KafkaOffsetMonitor工具
这个工具耦合性比较低,单用于监控比较适合而且部署很简单。
下载地址: https://github.com/quantifind/KafkaOffsetMonitor/releases
在Linux下创建KafkaOffsetMonitor目录
mkdir /opt/KafkaOffsetMonitor
cd /opt/KafkaOffsetMonitor

上传下载的jar包到改目录,然后运行
java -cp KafkaOffsetMonitor-assembly-0.2.1.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk kafka1:2181,kafka2:2181,kafka3:2181 --port 8088 --refresh 5.seconds --retain 1.days
zk :zookeeper主机地址,如果有多个,用逗号隔开
port :应用程序端口
refresh :应用程序在数据库中刷新和存储点的频率
retain :在db中保留多长时间
dbName :保存的数据库文件名,默认为offsetapp
回车即可看到后台打印输出(如果后台运行使用nohup 命令 &)
为了更方便的启动KafkaOffsetMonitor,可以写一个启动脚本来直接运行,我这里新建一个名为:kafka-monitor-start.sh的脚本,然后编辑这个脚本
java -Xms512M -Xmx512M -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -cp KafkaOffsetMonitor-assembly-0.2.0.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb
–port 8088
–zk kafka1:2181,kafka2:2181,kafka3:2181
–refresh 5.minutes
–retain 1.day >/dev/null 2>&1;

修改一下kafka-monitor-start.sh的权限
chmod +x kafka-monitor-start.sh
启动KafkaOffsetMonitor
nohup /opt/KafkaOffsetMonitor/kafka-monitor-start.sh &
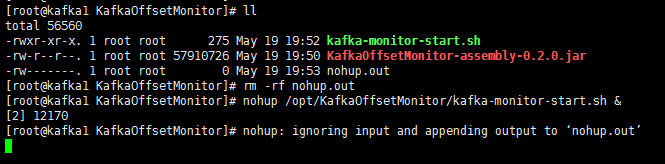
查看KafkaOffsetMonitor Web UI
http://192.168.12.60:8088

五、kafka测试
(1)创建Topic来验证是否创建成功
在其中一台虚拟机(192.168.12.60)创建topic
kafka-topics.sh --create --zookeeper 192.168.12.60:2181 --replication-factor 3 --partitions 1 --topic test-topic
其中:
–zookeeper指定zk集群的某台机器地址,多个以逗号隔开如"kafka1:2181,kafka2:2181"
–replication-factor指定分区的副本数
–partitions指定分区个数
–topic指定话题(主题)名
![]()
查看topic的信息
kafka-topics.sh --describe --zookeeper 192.168.12.60:2181 --topic test-topic

如果要查询素有topic列表
kafka-topics.sh --list --zookeeper kafka1:2181,kafka2:2181,kafka3:2181

(2)在一台机器上创建一个发布者
选择一台机器(192.168.12.61),创建一个发布者
kafka-console-producer.sh --broker-list 192.168.12.61:9092 --topic test-topic
其中:
–broker-list表示broker机器列表,多个以逗号隔开如"b1:9092,b2:9092"
–topic表示生产的主题名

(3)在一台机器上创建一个接收者
选择一台机器(192.168.12.62),创建一个消费者
kafka-console-consumer.sh --bootstrap-server 192.168.12.60:9092,192.168.12.61:9092,192.168.12.62:9092 --topic test-topic --from-beginning
![]()
(4)发送消息

接收者打印如下

解决问题常用
(1)kafka的日志在kafka的logs目录
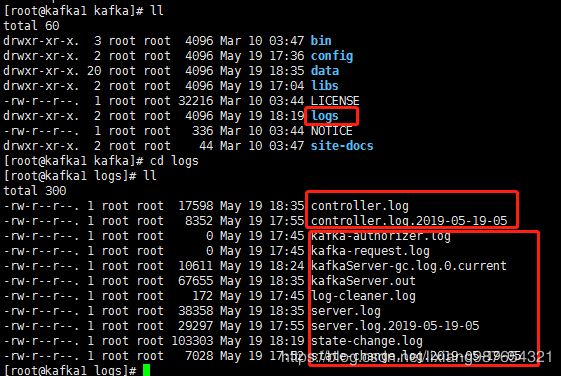
(2)查看zk的目录情况
zkCli.sh -server kafka1:2181

列举zk的目录
ls /
![]()
说明:以上显示的目录只有zookeeper目录是zk原生的,其他都是kafka创建的
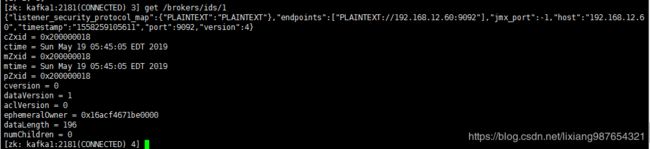
列举brokers列表
ls /brokers/ids
![]()
查看id为1的broker信息
get /brokers/ids/1
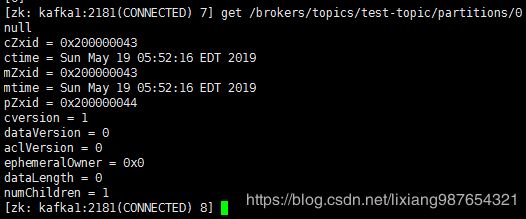
查看test-topic主题的分区信息
ls /brokers/topics/test-topic/partitions

查询分区0的节点信息
get /brokers/topics/test-topic/partitions/0
Kafka常用命令
以下是kafka常用命令行总结:
1.查看topic的详细信息
./kafka-topics.sh -zookeeper 127.0.0.1:2181 -describe -topic testKJ1
2、为topic增加副本
./kafka-reassign-partitions.sh -zookeeper 127.0.0.1:2181 -reassignment-json-file json/partitions-to-move.json -execute
3、创建topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testKJ1
4、为topic增加partition
./bin/kafka-topics.sh –zookeeper 127.0.0.1:2181 –alter –partitions 20 –topic testKJ1
5、kafka生产者客户端命令
./kafka-console-producer.sh --broker-list localhost:9092 --topic testKJ1
6、kafka消费者客户端命令
./kafka-console-consumer.sh -zookeeper localhost:2181 --from-beginning --topic testKJ1
注意:kafka 0.11版本后-zookeeper变为boostrap-server,指定kafka集群地址
7、kafka服务启动
./kafka-server-start.sh -daemon …/config/server.properties
8、下线broker
./kafka-run-class.sh kafka.admin.ShutdownBroker --zookeeper 127.0.0.1:2181 --broker #brokerId# --num.retries 3 --retry.interval.ms 60
shutdown broker
9、删除topic
./kafka-run-class.sh kafka.admin.DeleteTopicCommand --topic testKJ1 --zookeeper 127.0.0.1:2181
./kafka-topics.sh --zookeeper localhost:2181 --delete --topic testKJ1
10、查看consumer组内消费的offset
./kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper localhost:2181 --group test --topic testKJ1
11、停止kafka集群
kafka-server-stop.sh
jps
配置讲解
broker.id =0
每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况
log.dirs=/data/kafka-logs
kafka数据的存放地址,多个地址的话用逗号分割/data/kafka-logs-1,/data/kafka-logs-2
port =9092
broker server服务端口
message.max.bytes =6525000
表示消息体的最大大小,单位是字节
num.network.threads =4
broker处理消息的最大线程数,一般情况下不需要去修改
num.io.threads =8
broker处理磁盘IO的线程数,数值应该大于你的硬盘数
background.threads =4
一些后台任务处理的线程数,例如过期消息文件的删除等,一般情况下不需要去做修改
queued.max.requests =500
等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,应该是一种自我保护机制。
host.name
broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置
socket.send.buffer.bytes=1001024
socket的发送缓冲区,socket的调优参数SO_SNDBUFF
socket.receive.buffer.bytes =1001024
socket的接受缓冲区,socket的调优参数SO_RCVBUFF
socket.request.max.bytes =10010241024
socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
log.segment.bytes =102410241024
topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.roll.hours =247
这个参数会在日志segment没有达到log.segment.bytes设置的大小,也会强制新建一个segment会被 topic创建时的指定参数覆盖
log.cleanup.policy = delete
日志清理策略选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖
log.retention.minutes=3days
数据存储的最大时间超过这个时间会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据
log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
log.retention.bytes=-1
topic每个分区的最大文件大小,一个topic的大小限制 =分区数log.retention.bytes。-1没有大小限log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
log.retention.check.interval.ms=5minutes
文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略
log.cleaner.enable=false
是否开启日志压缩
log.cleaner.threads = 2
日志压缩运行的线程数
log.cleaner.io.max.bytes.per.second=None
日志压缩时候处理的最大大小
log.cleaner.dedupe.buffer.size=50010241024
日志压缩去重时候的缓存空间,在空间允许的情况下,越大越好
log.cleaner.io.buffer.size=5121024
日志清理时候用到的IO块大小一般不需要修改
log.cleaner.io.buffer.load.factor =0.9
日志清理中hash表的扩大因子一般不需要修改
log.cleaner.backoff.ms =15000
检查是否处罚日志清理的间隔
log.cleaner.min.cleanable.ratio=0.5
日志清理的频率控制,越大意味着更高效的清理,同时会存在一些空间上的浪费,会被topic创建时的指定参数覆盖
log.cleaner.delete.retention.ms =1day
对于压缩的日志保留的最长时间,也是客户端消费消息的最长时间,同log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据。会被topic创建时的指定参数覆盖
log.index.size.max.bytes =101024*1024
对于segment日志的索引文件大小限制,会被topic创建时的指定参数覆盖
log.index.interval.bytes =4096
当执行一个fetch操作后,需要一定的空间来扫描最近的offset大小,设置越大,代表扫描速度越快,但是也更好内存,一般情况下不需要搭理这个参数
log.flush.interval.messages=None
log文件”sync”到磁盘之前累积的消息条数,因为磁盘IO操作是一个慢操作,但又是一个”数据可靠性"的必要手段,所以此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞),如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟.物理server故障,将会导致没有fsync的消息丢失.
log.flush.scheduler.interval.ms =3000
检查是否需要固化到硬盘的时间间隔
log.flush.interval.ms = None
仅仅通过interval来控制消息的磁盘写入时机,是不足的.此参数用于控制"fsync"的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔达到阀值,也将触发.
log.delete.delay.ms =60000
文件在索引中清除后保留的时间一般不需要去修改
log.flush.offset.checkpoint.interval.ms =60000
控制上次固化硬盘的时间点,以便于数据恢复一般不需要去修改
auto.create.topics.enable =true
是否允许自动创建topic,若是false,就需要通过命令创建topic
default.replication.factor =1
是否允许自动创建topic,若是false,就需要通过命令创建topic
num.partitions =1
每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖
以下是kafka中Leader,replicas配置参数
controller.socket.timeout.ms =30000
partition leader与replicas之间通讯时,socket的超时时间
controller.message.queue.size=10
partition leader与replicas数据同步时,消息的队列尺寸
replica.lag.time.max.ms =10000
replicas响应partition leader的最长等待时间,若是超过这个时间,就将replicas列入ISR(in-sync replicas),并认为它是死的,不会再加入管理中
replica.lag.max.messages =4000
如果follower落后与leader太多,将会认为此follower[或者说partition relicas]已经失效
##通常,在follower与leader通讯时,因为网络延迟或者链接断开,总会导致replicas中消息同步滞后
##如果消息之后太多,leader将认为此follower网络延迟较大或者消息吞吐能力有限,将会把此replicas迁移
##到其他follower中.
##在broker数量较少,或者网络不足的环境中,建议提高此值.
replica.socket.timeout.ms=301000
follower与leader之间的socket超时时间
replica.socket.receive.buffer.bytes=641024
leader复制时候的socket缓存大小
replica.fetch.max.bytes =1024*1024
replicas每次获取数据的最大大小
replica.fetch.wait.max.ms =500
replicas同leader之间通信的最大等待时间,失败了会重试
replica.fetch.min.bytes =1
fetch的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会阻塞,直到满足条件
num.replica.fetchers=1
leader进行复制的线程数,增大这个数值会增加follower的IO
replica.high.watermark.checkpoint.interval.ms =5000
每个replica检查是否将最高水位进行固化的频率
controlled.shutdown.enable =false
是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker
controlled.shutdown.max.retries =3
控制器关闭的尝试次数
controlled.shutdown.retry.backoff.ms =5000
每次关闭尝试的时间间隔
leader.imbalance.per.broker.percentage =10
leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡
leader.imbalance.check.interval.seconds =300
检查leader是否不平衡的时间间隔
offset.metadata.max.bytes
客户端保留offset信息的最大空间大小
kafka中zookeeper参数配置
zookeeper.connect = localhost:2181
zookeeper集群的地址,可以是多个,多个之间用逗号分割hostname1:port1,hostname2:port2,hostname3:port3
zookeeper.session.timeout.ms=6000
ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
zookeeper.connection.timeout.ms =6000
ZooKeeper的连接超时时间
zookeeper.sync.time.ms =2000
ZooKeeper集群中leader和follower之间的同步实际那
参考文章
https://blog.csdn.net/zhongwumao/article/details/81171143
http://www.imooc.com/article/262018
https://www.cnblogs.com/luotianshuai/p/5206662.html
整个kafka集群启动命令
启动zk
zkServer.sh start
启动kafka
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
启动web界面
nohup /opt/kafka-manager/bin/kafka-manager &
停止kafka集群
kafka-server-stop.sh
停止zk
szServer.sh stop
停止web
jps
kil -9 进程id
快来成为我的朋友或合作伙伴,一起交流,一起进步!
QQ群:961179337
微信:lixiang6153
邮箱:[email protected]
公众号:IT技术快餐
更多资料等你来拿!