自定义对象的比较为什么重写equals和hashcode
类比String
String是我们最常见的一种类型,它同时也很特殊,先不管它的特殊性,我们来看看它的equals方法
- String的equals方法
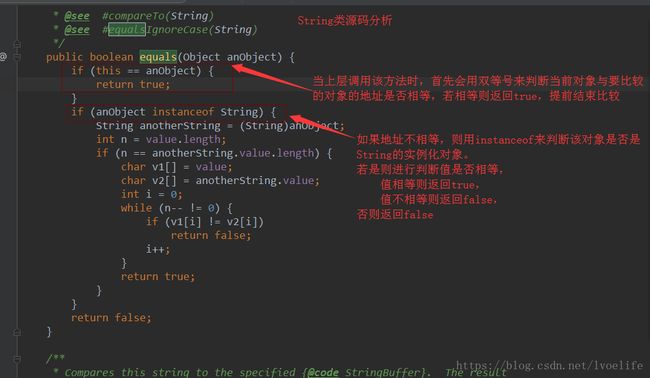
其实,我们在调用改方法时,内部就进行对象的引用地址的判断。 - String的hashcode方法
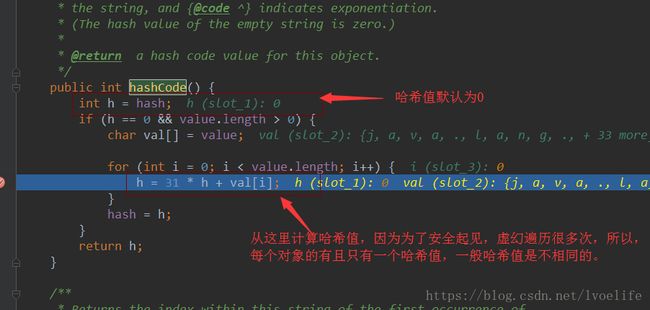
你就会发现,所谓的hash值是计算出来的,因而,hash值是会有冲突的,这种情况很少,也不是没有。我们都知道HashMap中的put(K,V)中的K是唯一的,值可以有多个,如果K的hash值相同,但并不是同一个对象,对hashMap的调用有没有影响呢?
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}上面是jdk的put的源码,你会看到,它调用了另一个方法,我们看看另一个方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}当我们使用put时,会计算键的hash散列值,同时,使用抑或表达式,如图所示:

由于 h>>>16,高16bit 补0,一个数和0异或不变,所以 hash 函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或,目的是减少碰撞。
为什么会有key==null,因为hashmap允许键为null,补充知识:
我们来看看putVal方法。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node[] tab; Node p; int n, i;
// 初始 tab 为 null,resize 初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算下标index,没碰撞,直接放
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
// 碰撞,节点已经存在
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 碰撞,树结构
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
// 碰撞,链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 链表过长,转换成树结构
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 节点已存在,替换value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 超过threshold,进行resize扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 模拟hash冲突。
我们模拟hash冲突
package com.zby.service;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
/**
* @author zhubaoya
* @description 学生的实体类
* @time 2018年08月22日 21点14分
* @projectName test
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Student {
private String name;
private String address;
private Long id;
@Override
public int hashCode() {
return this.hash(name,address,id);
}
/**
* 模拟返回的hash值
* @param obj
* @return
*/
private int hash(Object...obj){
if (obj == null) {
return 0;
}
int result=0;
for (Object o : obj) {
result = result+1;
}
return result;
}
}测试:
@Test
public void testHash(){
Student student1=new Student("珠宝亚","安徽省",111L);
Student student2=new Student("珠宝亚","安徽省",113L);
System.out.println(student1.hashCode()==student2.hashCode());
}
返回结果为ture通过以上的分析,就感觉到非常危险,因为,我们在做购物车时,使用的是hashMap这个对象。我们通过Key来获取值,如果对象A和对象B的Key的hash值相同。对象A本该取对象A的值,对象B取对象B的值,那么,这时就会出现,对象A不仅取到了本身的值,也取到了对象B的值。同理,对象B也是如此。
当然,模拟毕竟时模拟,而实际上不是这样调用的。接下来,我们就分析为什么重写HashCode和equals方法。
解析重写的方法

- 首先判断student1和student2的引用地址是否相等,若想等则直接返回,否则执行第二步操作。
- 假设student2作为参数,判断student2是否为空,为空则直接返回false,不为空执行第三步
- 通过getClass()获得两个对象的类型,类型相等则执行第四步,否则返回false
- 判断两个对象的各个属性是否相等,在这里,就用到上面的equals方法。若各个属性的equals方法相等,则直接返回true,只要有一个不等,则返回false
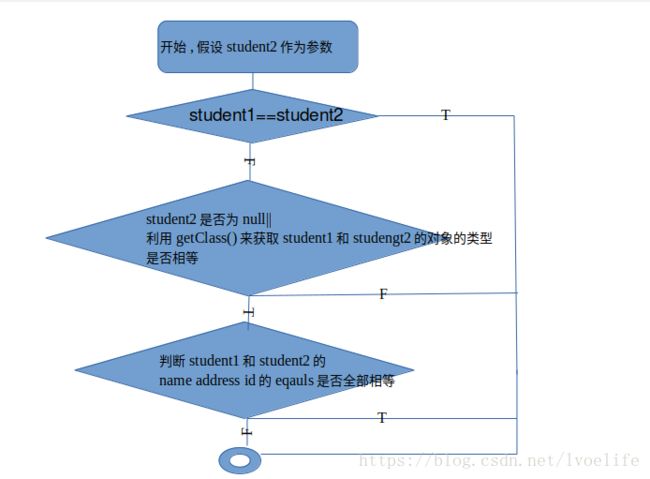
代码如下:
@Override
public boolean equals(Object o) {
if (this == o) {return true;}
if (o == null || getClass() != o.getClass()){ return false;}
Student student = (Student) o;
return Objects.equals(name, student.name) &&
Objects.equals(address, student.address) &&
Objects.equals(id, student.id);
}
调用Obejects当中的equals方法:
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
调用Object的equals方法
public boolean equals(Object obj) {
return (this == obj);
}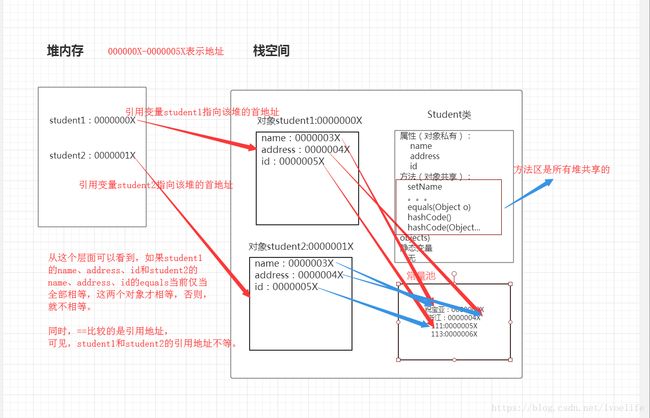
假如student2的id指向 0000006X,这两个对象指定不相等。
我们处理student1和student2的hash值。student1的属性name有个hash值,address也有个hash值,id也有个hash值,三个hash值相加得到student1的总的hash1值,同理,student2也有个总的hash2值。如果hash1==hash2,name他们才相等。
- student1的name address id的hash值相加得到hash1
- student2的name address id的hash值相加得到hash2
- 判断hash1==hash2
代码如下:
@Override
public int hashCode() {
return Objects.hash(name, address, id);
}
调用objects的hash方法:
public static int hash(Object... values) {
return Arrays.hashCode(values);
}
调用Arrays类的hashCode方法
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}这就是我们为什么重写这两个方法了。
还是多看看JDK的源码,你会受用无穷的