MySQL进阶及优化
一、MySQL常用存储引擎
进入mysql
show engines;
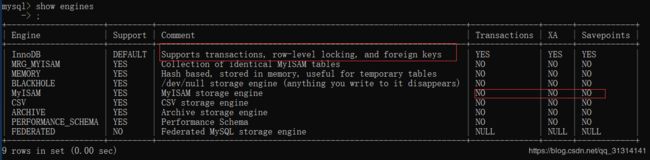
常用的mysql引擎主要有两种,一种是InnoDB(mysql默认),另一种是MyISAM.
显示所有引擎之后从引擎的注释中可以发现,InnoDB是支持事务和外键的并且使用行级锁。而MyISAM不支持事务。
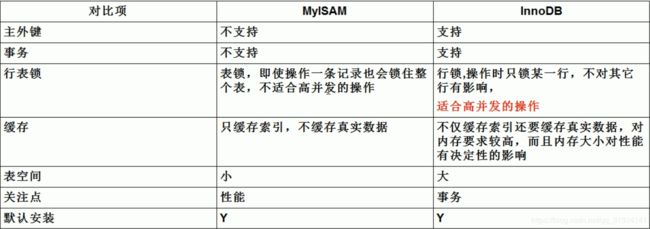
除此之外,两个引擎的其他区别如下表:
二、MySQL索引
单值索引
首先:用到索引的字段一定是经常用来查询的字段:
例如有一user表有四个字段:
id name email phone
经常用的查询语句如下:
select * from user where name = ‘xxx’;
那么就可以在经常用于查询的字段name上面建立索引:
create index idx_user_name on user(name);
上面的索引属于单值索引,在执行上面的查询语句的时候就可以加快查询速度。
复合索引
其实通俗的讲,复合索引就是一张表内的多个索引
还是上面的user表,假设经常用的查询语句如下
select * from user where name = ‘xxx’ and email= ‘[email protected]’;
经常用name和email一起作为查询条件,此时就可以建立复合索引
create index idx_user_nameEmail on user(name, email);
join语句
索引概念和b+树
索引是帮助mysql高效获取数据的数据结构
可以简单理解为“排好序的快速查找数据结构”
总结:索引的本质是数据结构!
索引一般是存储在硬盘当中的,而不是内存中。
所以,索引可以提高
select …where (加索引的字段);
…order by(加索引的字段);
这两类语句的速度和性能
一般来说,MySQL默认的索引的数据结构为b+树索引,b+树和b树有类似的地方,他们的叶子结点都在同一层,且都是平衡树。
关于b+树索引的详细介绍可以看这篇文章:
https://blog.csdn.net/qq_26222859/article/details/80631121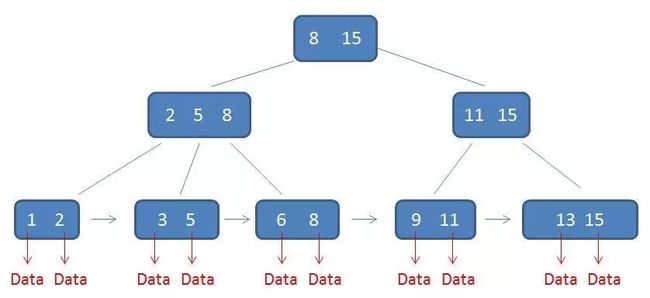
简单来说,b+树叶子节点是连起来的,而且所有的数据都存储在叶子节点,中间的结点不存储数据。
所以,b+树对于b树的优点在于:
1.中间结点不存放数据,减少了磁盘的io次数。
2.b+树的查找是稳定的,b树的查找可能会时快时慢,所以b+树性能稳定。
3.因为b+树的叶子节点都是连接的,所以大大简化了范围查询的流程,但是对于b树来说,还需要复杂的中序遍历来找到对应的范围。
总结:
B+树的特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
索引的优缺点
优点:
1.提高数据检索效率
2.降低数据库io成本
3.降低数据排序的成本,降低排序时cpu的消耗
缺点:
1.最大的缺点是增删改操作效率会降低,因为进行update操作的时候,不仅要保存数据,而且还要维护正常的索引指向,且保存索引文件中更新的部分。
2.索引文件会占用磁盘空间
索引的增删改查
增:
create index indexName on tableName(cloumn1, column2, …);
删:
drop index indexName on tableName;
改:
alter tableName add index indexName on (cloumn1, column2, …);
查:
show index from tableName\G;
三、建立索引的场景
适合建立索引的场景
1.主键自动建立唯一索引
2.频繁作为查询字段的索引
5.当既可以用单值索引,又可以用组合索引时,倾向于组合索引
6.查询中需要排序的字段适合建立索引
7.查询中统计或者分组的字段适合建立索引
不适合建立索引的场景
1.频繁更新的字段不适合建立索引
2.where条件中用不到的字段不用创建索引
3.字段内容大量重复的字段不要建立索引
四、MySQL性能分析explain
概念
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
类似于一个sql语句的化验报告单
使用:
explain + sql 即把explain关键字加在sql语句前面
作用
可以查看以下内容:
- 表的读取顺序
- 数据读取操作的数据类型
- 哪些索引可以使用
- 哪些索引实际被使用
- 表之间的引用
- 每张表有多少行被优化器查询
例如,我这里查询一个user信息表
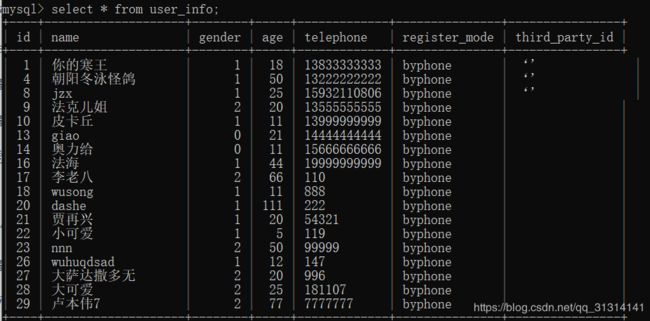
分析如下的查询语句:

下面逐列的介绍这几个字段的含义。
id:表的操作顺序
select查询的序列号,包含一组数字,表示查询中执行select或字句或操作表的顺序。
例子一:
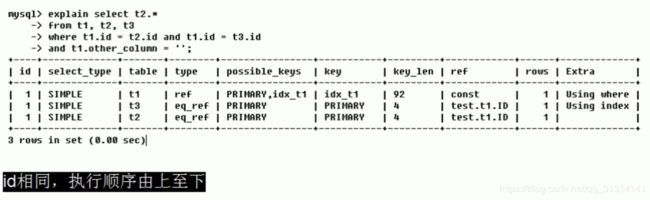
这里因为where条件中有个and,and之后的条件先被判断,所以先执行了t1表的查询,然后是and前面的t3表,最后t2表。因为三张表没有子查询存在,所以id都是相同的,下面是id不同的子查询例子。
例子二:

因为有子查询的存在,所以mysql会先进入最内部一层的子查询表内查询,所以id不同,执行顺序也不同,是从下往上的。id越大越先执行。这里的t1,t3的select_tyep也表明了是子查询。

这张表id有不同的有相同的,规则还是不变,id不同的时候,id大的先执行;id相同的时候,从上到下执行。
注意第三列中的derived2的意思是,这个是id=2的表(即t3)的衍生表。(对应上面sql语句里面的s1)。
总结:id相同:按顺序执行;id不同:id大的先执行。
select_type:查询语句的属性

type:查询操作的性能体现

从上到小
system:表只有一行记录(几乎不出现)
const:表示通过索引一次就找到了
eq_ref:唯一性索引扫描,每个索引键对应一条 记录
ref:非唯一性索引扫描,每个索引键对应非唯一的记录
range:只检索给定范围的行
index:全索引扫描
all:全表扫描
possible keys和keys
possible keys:显示可能应用在这张表中的索引,一个或多个
查询涉及到的字段上若存在索引则该索引将被列出,但不一定被查询实际使用。
keys:实际使使用到的索引
若出现覆盖索引(覆盖索引就是查询的字段和顺序和索引的字段和顺序完全一样)则该索引只出现在keys中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引长度,在不损失精度的情况下,长度越短越好。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
ref
显示索引的那一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
rows
每张表有多少行被优化器查询
五、索引优化
以下内容源于https://cyc2018.github.io/CS-Notes/#/notes/MySQL
1.独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
2.多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
SELECT film_id, actor_ id FROM sakila.film_actor
WHERE actor_id = 1 AND film_id = 1;
3.索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT() AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT() AS customer_id_selectivity,
COUNT()
FROM payment;
Copy to clipboardErrorCopied
staff_id_selectivity: 0.0001
customer_id_selectivity: 0.0373
COUNT(): 16049
4. 前缀索引
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
前缀长度的选取需要根据索引选择性来确定。
5.覆盖索引
索引包含所有需要查询的字段的值。
具有以下优点:
索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
六、主从复制和读写分离
读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。
读写分离能提高性能的原因在于:
主从服务器负责各自的读和写,极大程度缓解了锁的争用;
从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
增加冗余,提高可用性。
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
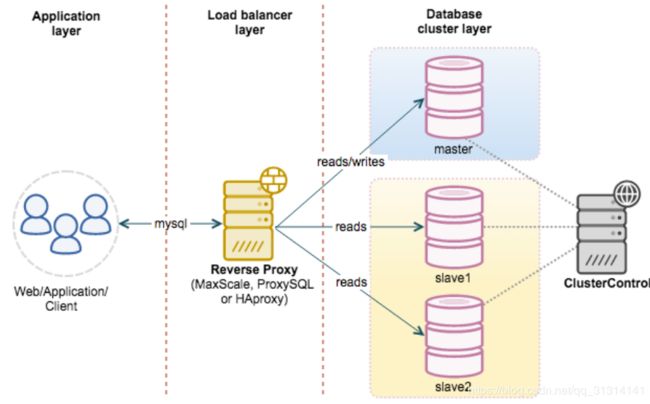
主从复制
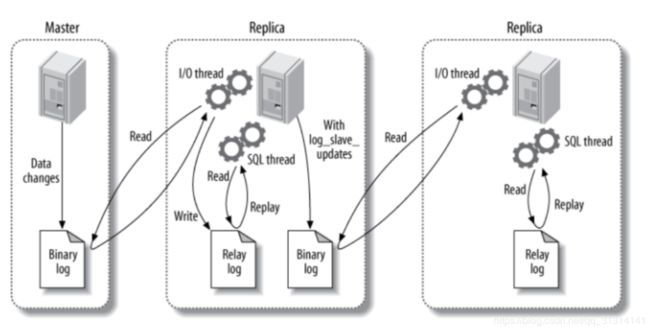
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
binlog 线程 :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
I/O 线程 :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
SQL 线程 :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
补充:
mysql limit关键字的两个参数分别是什么?
不要理解为开始的行和结束的行!这是错误的理解。
正确的两个参数是
1:开始显示的行
2:要显示的行数
比如要做一个分页功能。每一页显示五条记录。
那么就是select * from item limit x, 5;
x为前台传参获得,比如用户点击第五页,那么第五页显示的就是21-25这五条记录,那么就将(5-1) * 5传给即可。
行锁,表锁都是啥?
行锁:只锁一行,并发度较高。
表锁:锁整个表,并发度较低。所以MyISAM引擎不适合频繁写操作。适合大量读的操作。