steamdb免费游戏信息爬取(不是爬虫教学,日常记录,贼不工整,不喜勿看)
日常记录而已,不是特别工整,不喜勿喷,不喜勿看。
1. 数据来源于steamdb, 目标网址:https://steamdb.info/upcoming/free/
2. 由于网址存在反爬措施,在没有cookie的情况下,网站会由js进行跳转,跳转过程中post表单的数据由js计算而来,详情请看另一篇文章:stemadb反扒机制分析。为了简化工作量,使用selenium进行访问网页,进行跳转然后获取cookie, cookie有效期为一天。
3. cookie有效时,网站直接采用requests进行访问,爬取数据。当访问失败时,使用selenium访问网站刷新cookie。
4. 上疗效,原先准备作为网站小功能的一部分,每日定时更新并提供订阅定时发送邮件功能,但是由于太耗资源,因而放弃了。
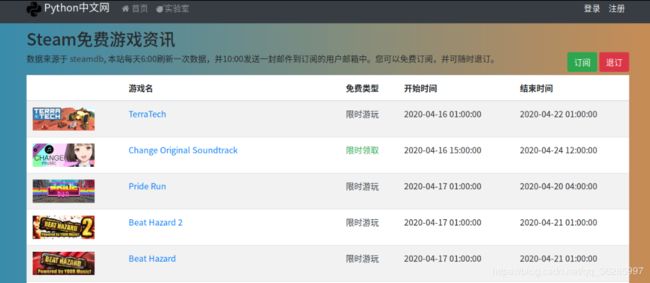
5. 然后直接上代码,这里只贴有关steamdb的代码,涉及到网站的部分就不贴了
5.1 本代码负责手动更新cookie. 也用于selenium测试。
# -*- coding: utf-8 -*-
# @Author : LG
from selenium import webdriver
import argparse
from selenium.webdriver.support.ui import WebDriverWait
def update_cookie(url, file_name, delayed):
# 无头模式,不打开浏览器窗口
option = webdriver.FirefoxOptions()
option.add_argument('--headless')
driver = webdriver.Firefox(options=option)
driver.get(url)
# 这里加了延时,直到页面找到特定元素 或超时。
WebDriverWait(driver, delayed).until(lambda aaa: driver.find_element_by_id('live-promotions'))
# 将cookie保存在特定文件中,平时更新时由其他程序读取
with open(file_name, 'w')as f:
for cookie in driver.get_cookies():
print(cookie)
f.write(cookie['name']+','+cookie['value']+'\n')
driver.close()
return True
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='update cookie')
parser.add_argument('-u', '--url', type=str, default='https://steamdb.info/upcoming/free/')
parser.add_argument('-f', '--filename', type=str, default='cookie.txt')
parser.add_argument('-d', '--delayed', type=int, default=15)
args = parser.parse_args()
update_cookie(url=args.url, file_name=args.filename, delayed=args.delayed)
5.2 自动更新以及自动发送邮件等功能的实现。
# 爬取的时间 转UTC 转本地
def time_analysis(time_str):
months = {'January': '01', 'February': '02', 'March': '03', 'April': '04', 'May': '05', 'June': '06',
'July': '07', 'August': '08', 'September': '09', 'October': '10', 'November': '11', 'December': '12'}
time = time_str.split('')
time = '{}-{}-{} {}'.format(time[2], time[1], time[0], time[4])
for month_en, month_num in months.items():
time = time.replace(month_en, month_num)
utc_dt = datetime.strptime(time, "%Y-%m-%d %H:%M:%S")
local_tz = pytz.timezone('Asia/Chongqing')
local_dt = utc_dt.replace(tzinfo=pytz.utc).astimezone(local_tz)
local_dt = str(local_dt).split('+')[0]
return local_dt
# 更新cookie
def update_cookie():
url = 'https://steamdb.info/upcoming/free/'
option = webdriver.FirefoxOptions()
option.add_argument('--headless')
driver = webdriver.Firefox(options=option)
driver.get(url)
WebDriverWait(driver, delayed).until(lambda aaa: driver.find_element_by_id('live-promotions'))
# 这只是简单调试时的日志,不要在意
if len(driver.get_cookies()) ==1:
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {}\n".format(datetime.now(), 'cookie更新失败'))
return False
with open('cookie.txt', 'w')as f:
for cookie in driver.get_cookies():
f.write(cookie['name']+','+cookie['value']+'\n')
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {}\n".format(datetime.now(), 'cookie更新失败'))
return True
# 读取cookie,并访问网站
def get_html(url='https://steamdb.info/upcoming/free/'):
session = requests.session()
headers = {"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:70.0) Gecko/20100101 Firefox/70.0"}
cookie_str = ''
try:
f = open('cookie.txt','r')
lines = f.readlines()
for line in lines:
name, value = line.rstrip('\n').split(',')
cookie_str+=name+"="+value+";"
except:
pass
headers["Cookie"]=cookie_str
html = session.get(url, headers=headers)
return html
# 从网站页面抽取需要爬取的数据,这里俩个表格格式略有不同,后面会分开处理
def get_tables():
html = get_html()
if html.status_code != 200:
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {} {}\n".format(datetime.now(), '请求失败刷新cookie', html.status_code))
# 请求失败,更新cookies
if update_cookie():
# 重新读取网页
html = get_html()
else:
# 更新失败
return None
if html.status_code != 200:
return None
# 请求成功
soup = BeautifulSoup(html.text, 'lxml')
tables = soup.find_all('table')
return tables
def currently(currently_table):
# 第一个表格
trs = currently_table.find('tbody').find_all('tr')
for tr in trs:
tds = tr.find_all('td')
link = tds[0].a['href']
pic = tds[0].img['src']
name = tds[1].a.b.string
type = tds[3].string or tds[3].b.string
starts = time_analysis(tds[4].string)
ends = time_analysis(tds[5].string)
# 这里是网站专门为这个功能添加一个数据库
steamfree = Steamfree(link=link, pic=pic, name=name, type=type, start=starts, end=ends)
db.session.add(steamfree)
return True
def upcoming(upcoming_table):
# 第二个表格
trs = upcoming_table.find('tbody').find_all('tr')
for tr in trs:
tds = tr.find_all('td')
link = tds[0].a['href']
pic = tds[0].img['src']
name = tds[1].a.b.string
type = tds[2].string or tds[2].b.string
starts = time_analysis(tds[3].string)
ends = time_analysis(tds[4].string)
steamfree = Steamfree(link=link, pic=pic,name=name,type=type,start=starts,end=ends)
db.session.add(steamfree)
return True
def steamfree_delete_all():
# 更新数据库前,需要全部删除
steamfrees = Steamfree.query.all()
for steamfree in steamfrees:
db.session.delete(steamfree)
db.session.commit()
def steamdb_free_update():
# 这里添加了一个手动刷新数据的函数,在前端给了接口调用,不用在意
tables = get_tables()
if not isinstance(tables, int):
steamfree_delete_all()
currently(tables[0])
upcoming(tables[1])
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {}\n".format(datetime.now(), 'steamfree手动更新成功'))
else:
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {}\n".format(datetime.now(), 'steamfree手动更新失败'))
# 自动发送邮件
def send_steamfree_auto():
# 这里定时,用到了 flask_apscheduler,在操作数据库时,需要一个app
with scheduler.app.app_context():
steamfrees = Steamfree.query.all()
# 订阅用户
subers = Steamfree_sub.query.all()
for sub in subers:
send_email(to=sub.email,
subject='steam免费信息',
template='laboratory/email/steam_free_send',
steamfrees=steamfrees,
link='')
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {} {}\n".format(datetime.now(), 'steamfree自动发送邮件成功', sub.email))
# 自动更新
def steamdb_free_update_auto():
with scheduler.app.app_context():
tables = get_tables()
if not isinstance(tables, int):
steamfree_delete_all()
currently(tables[0])
upcoming(tables[1])
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {}\n".format(datetime.now(), 'steamfree自动更新成功'))
else:
with open('XXX/steamfree_log.txt', 'a') as f:
f.write("{} {}\n".format(datetime.now(), 'steamfree自动更新失败'))
# 每6小时自动更新一次数据库
scheduler.add_job(func=steamdb_free_update_auto,
id='1',
trigger='interval', # trigger='interval' 表示是一个循环任务,每隔多久执行一次
hours=6)
# 每天早上10点自动发送邮件
scheduler.add_job(func=send_steamfree_auto,
id='2',
trigger='cron', # 定时任务
day_of_week='0-6',
hour=10,
minute=0,
second=0)5.3 数据库模型也贴一下
# steam 免费游戏数据库
class Steamfree(db.Model):
__bind_key__ = 'laboratory' # 这里由于网站有多个数据库,所以需要指定bind
__name__ = 'steamfrees'
id = db.Column(db.Integer, primary_key=True)
link = db.Column(db.Text) # steam游戏页面链接
pic = db.Column(db.Text) # 缩略图
name = db.Column(db.String) # 游戏名
type = db.Column(db.String) # 免费类型
start = db.Column(db.String) # 开始时间
end = db.Column(db.String) # 结束时间
# steam免费游戏服务订阅数据库
class Steamfree_sub(db.Model):
__bind_key__ = 'laboratory'
__name__ = 'steamfree_subs'
id = db.Column(db.Integer, primary_key=True)
email = db.Column(db.Text) # 这里只保存订阅者的邮箱
5.4 网站前端也发出来吧(但是基础页面不发)
{% extends "base.html" %}
{% block contents %}
游戏名
免费类型
开始时间
结束时间
{% for steamfree in steamfrees %}

{{ steamfree.name }}
{% if steamfree.type == 'Weekend' %}
限时游玩
{% elif steamfree.type == 'Keep' %}
限时领取
{% endif %}
{{ steamfree.start }}
{{ steamfree.end }}
{% endfor %}
{% endblock %}
5.5 视图,这里只贴部分代码
# 免费资讯主页面
@laboratory_blueprint.route('/laboratory/steamfree')
def steamfree():
steamfrees = Steamfree.query.all()
return render_template('laboratory/steamfree.html', steamfrees=steamfrees, current_user=current_user)
# 手动更新
@laboratory_blueprint.route('/laboratory/steamfree/update')
@login_required
def steamfree_update():
steamdb_free_update()
return redirect(url_for('laboratory.steamfree'))
# 订阅
@laboratory_blueprint.route('/laboratory/steamfree/subscribe')
@login_required
def subscribe():
sub = Steamfree_sub.query.filter(Steamfree_sub.email == current_user.email).first()
if sub is None:
sub = Steamfree_sub(email=current_user.email)
flash('您已订阅steam免费游戏资讯。')
db.session.add(sub)
else:
flash('您已订阅steam免费游戏资讯,无需重复订阅。')
return redirect(url_for('laboratory.steamfree'))
# 退订
@laboratory_blueprint.route('/laboratory/steamfree/unsubscribe')
@login_required
def unsubscribe():
sub = Steamfree_sub.query.filter(Steamfree_sub.email==current_user.email).first()
if sub is None:
flash('您还未订阅steam免费游戏资讯,无需退订。')
else:
db.session.delete(sub)
db.session.commit()
flash('您已退订steam免费游戏资讯。')
return redirect(url_for('laboratory.steamfree'))