朴素贝叶斯判断文本的正负性
通过朴素贝叶斯的方法来判断给定的文本是正面的还是负面的。
基础的朴素贝叶斯公式:
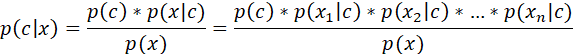
一、读取测试集,进行预处理
1.将所有单词转变为小写,并去除无关的标点符号。
2.将每段文本分成以单词为基本元素单词列表。
二、构建停词表,去除掉一些不影响情感态度的词,减少工作量。
三、根据朴素贝叶斯公式计算每个文本分别为正负文本的概率:
在实际的计算中因为特殊性进行了一些细节的处理:
1.因为p(c=pos)=p(c=neg)=0.5,所以计算时并没有乘上概率![]() 。
。
2.因为公式中的分母中的p(x)在两次的计算中都是一样大的,而结果只比较两者的大小,所以也不用再计算这个概率了。
3.因为一段文本中可能会有大量的单词,所以乘起来的概率会非常的小,不方便比较,所以每次对概率取了对数再相加。并且计算概率时因为都要除以文本的总数获得概率而且数值较大比较影响精度所以实际计算的时候没有除去。这个也不会影响实验的结果。例如 ![]() ,因为count(c=pos)==count(c=neg),所以计算时也可以去掉而不会影响实验结果。
,因为count(c=pos)==count(c=neg),所以计算时也可以去掉而不会影响实验结果。
4.每一个![]() 的计算是去找每个单词在文本中出现的次数除以文本的总数计算出来的,所以每一次都要全部遍历一遍。
的计算是去找每个单词在文本中出现的次数除以文本的总数计算出来的,所以每一次都要全部遍历一遍。
实验改进:
上述方法在程序中的主要计算量花费在每个单词的统计次数中,之前用的策略是每个单词都要在列表中搜索一次很耗费时间,后来改为创建一个全局的字典分被保存正负文本的词频,查找速度大大提升。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import re
import math
path = './dataset_for_homework_1/aclImdb/train/'
pos_path = path + 'pos/'
neg_path = path + 'neg/'
pos_files = [pos_path + x for x in
filter(lambda x: x.endswith('.txt'), os.listdir(pos_path))]
neg_files = [neg_path + x for x in
filter(lambda x: x.endswith('.txt'), os.listdir(neg_path))]
pos_list = [re.sub(r'\W',' ',open(x, 'r').read().lower()) for x in pos_files]
neg_list = [re.sub(r'\W',' ',open(x, 'r').read().lower()) for x in neg_files]
pos_list_1=[x.split(' ') for x in pos_list]#将列表中的每段话先分割成词
neg_list_1=[x.split(' ') for x in neg_list]
pos_p=0.5#正文本的概率
neg_p=0.5#负文本的概率
posDict=dict()
stop_list=['i','he','she','is','it','that','this','was','are','were','what','how','of','from','to','and','a','so','very','','ll',
'because','in','one','these','those','so','two']#去掉一些没有太大影响的词
def serarch(str,label):#找到某个词出现的次数
count=0
if(label==0):
for x in pos_list_1:
if(str in x):
count+=1
if(label==1):
for x in neg_list_1:
if(str in x):
count+=1
if(count==0):
count+=1
return count
###############################
stop_list=set(stop_list)
path = './dataset_for_homework_1/aclImdb/test/'
pos_path1 = path + 'pos/'
neg_path1 = path + 'neg/'
pos_files1 = [pos_path1 + x for x in
filter(lambda x: x.endswith('.txt'), os.listdir(pos_path1))]
neg_files1 = [neg_path1 + x for x in
filter(lambda x: x.endswith('.txt'), os.listdir(neg_path1))]
pos_list1 = [re.sub(r'\W',' ',open(x, 'r').read().lower()) for x in pos_files1]
neg_list1 = [re.sub(r'\W',' ',open(x, 'r').read().lower()) for x in neg_files1]
pos_list1_1=[set(x.split(' '))-stop_list for x in pos_list1]
neg_list1_1=[set(x.split(' '))-stop_list for x in neg_list1]
################################
all_pro=0
count1=0
for test in pos_list1_1:
pos_end=0
neg_end=0
#test=set(test.split())-set(stop_list)
for x in test:#分别计算好评和负评的概率
pos_end+=math.log(serarch(x,0))#取对数相加代替原数相乘防止概率太小,因为正负文本概率相同所以也就都不算了
neg_end+=math.log(serarch(x,1))
if pos_end>neg_end:
all_pro+=1
for test in neg_list1_1:
pos_end=0
neg_end=0
#test=set(test.split())-set(stop_list)
for x in test:#分别计算好评和负评的概率
pos_end+=math.log(serarch(x,0))#取对数相加代替原数相乘防止概率太小,因为正负文本概率相同所以也就都不算了
neg_end+=math.log(serarch(x,1))
if pos_end