springboot+kafka 以及生产者(Producer)、消费者(Consumer)分离
1.环境准备
1.1、JDK
jdk应该都是配置好了的,这个也是基础,接触java最先就应该是这个,就不多说。
1.2、搭建Zookeeper环境
我们先下载Zookeeper压缩包,搭建Zookeeper环境,将Zookeeper解压缩之后,在conf文件中复制zoo_sample.cfg,将原文件改为zoo.cfg,如图

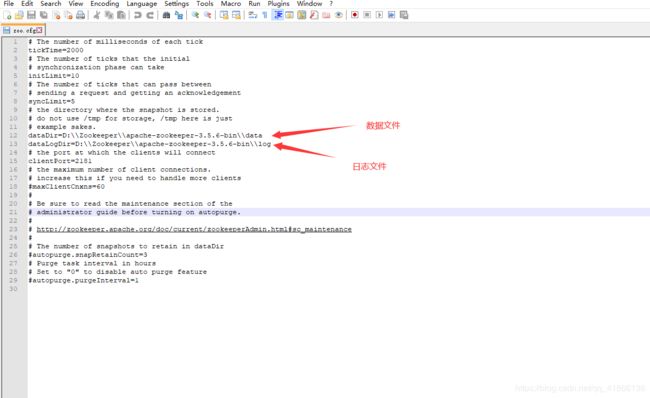
然后用notepad打开zoo.cfg文件,指定数据目录和日志目录,数据目录和日志目录就放在conf同一级目录中,文件名字根据自己喜好命名就好,如图
然后在bin目录中进入终端命令,输入zkserver启动Zookeeper,如图
然后查看是否启动成功,基本上你的日志文件没有遇到error级别日志就不会有啥子问题了,如图
如果执行上面步骤之后不能正常启动使用的话,就去配置一个环境变量,如图
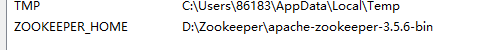
并且在path中配置的jdk后面添加"%ZOOKEEPER_HOME%\bin;",注意,配置的jdk或者jre后面都要用";"隔开,如图

如果这样启动还是有问题的话,就去百度吧,找几篇专门写Zookeeper的教程看看,就应该没得啥子问题了!
1.3、搭建kafka环境
下载kafka压缩包,记住不要下载src版本,那个需要编译后才能运行,是给高级开发人员去做拓展的,我在这儿使用的binary版本就行了,src版本怎么使用我也不知道。
将下载好的kafka解压后进入config目录,修改一下server.properties文件中日志目录,只要日志目录跟config同级就好,名字自己开心,如图
然后在bin、Windows目录下面输入 kafka-server-start.bat …/…/config/server.properties,这里注意是两个点,我不知道怎么显示就是3个点了,自己修改为两个点就好了,启动kafka,如果没有报error级别日志基本上就启动成功了,我倒是遇到一个坑,有时Zookeeper报远程主机强迫关闭了一个现有的连接,如图
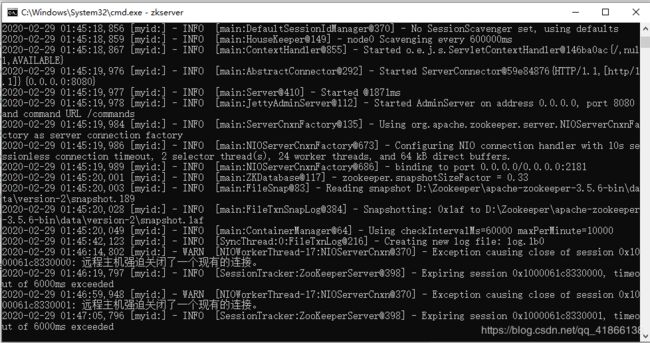
造成了上面原因是我删除了一个topic,这个时候我解决的比较粗暴,直接删除Zookeeper目录下数据目录和日志目录,以及删除kafka目录下自己配置的日志目录,然后再次重启就OK了,搞的我现在一般不敢去删除topic。
下图是正常启动的kafka
2.springboot整合kafka
2.1、项目准备
创建springboot项目过程这里就不提供了,有很多教程、方法。
在这儿我是将Consumer(消费者)和Producer(生产者)分离为两个项目了 ,所以,准备两个springboot项目。
首先,我们分别在两个项目pom文件中添加kafka的maven依赖,如下:
org.springframework.kafka
spring-kafka
2.2、Producer(生产者)
接下来在项目中配置application.yml文件,配置信息如下:
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: foo
# 生产者
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
我们先准备实体类Foo ,方便接收数据
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
@Component
public class Foo {
private Integer id;
private String name;
private String age;
private String sex;
private String message;
}
继续准备一个用于生产者异步和同步发送消息的工具类KafkaSendUtils
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.errors.TimeoutException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import kafka.client.demo.entity.Foo;//**这个路径改为你在项目中实体类的路径就好**
@Component
public class KafkaSendUtils {
@Autowired
private KafkaTemplate kafkaTemplate;
// 异步
public void sendAnsyc(final List foo) {
ListenableFuture> future = kafkaTemplate.send("top_test", foo);
future.addCallback(new ListenableFutureCallback>() {
@Override
public void onSuccess(SendResult result) {
System.out.println("异步发送消息成功:" + result);
}
@Override
public void onFailure(Throwable ex) {
System.out.println("异步发送消息失败:"+ ex.getMessage());
}
});
}
// 同步
public void sendSync(final List foo) throws Exception {
ProducerRecord producerRecord = new ProducerRecord<>("top_test", foo);
try {
kafkaTemplate.send(producerRecord).get(10, TimeUnit.SECONDS);
System.out.println("同步发送成功");
}
catch (ExecutionException e) {
System.out.println("同步发送消息失败:"+ e.getMessage());
}
catch (TimeoutException | InterruptedException e) {
System.out.println("同步发送消息失败:"+ e.getMessage());
}
}
}
接下来就是producer生产者的发送
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import kafka.client.demo.entity.Foo;
import kafka.client.demo.utils.KafkaSendUtils;
/**
* 测试kafka生产者
*/
@RestController
@RequestMapping("kafka")
public class KafkaProducerController {
@Autowired
private KafkaSendUtils kafkaSendUtils;
@PostMapping("/ansyc")
public String send(@RequestBody List list) throws Exception{
// kafkaSendUtils.sendAnsyc(list);//**异步发送**
// kafkaSendUtils.sendSync(list);//**同步发送**
kafkaTemplate.send("top_test", list);
return "返回给前端的数据";
}
}
以上关于生产者部分就算已经完成了
2.3、Consumer(消费者)
在Consumer(消费者)项目中配置application.yml文件,配置信息如下:
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
# 消费者
consumer:
#消费组
group-id: foo
auto-offset-reset: latest
在该项目中也需要准备Foo实体类,同上
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
@Component
public class Foo {
private Integer id;
private String name;
private String age;
private String sex;
private String message;
}
消费者类准备
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.List;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.BatchPreparedStatementSetter;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import com.alibaba.fastjson.JSONObject;
import com.rxdatainfo.rh.Internetofthingsdata.temperaturesmoke.entity.Foo;
/**
* kafka消费者测试
*/
@Component
public class Consumer {
@Autowired
private JdbcTemplate jdbcTemplate;
//@KafkaListener用于监听多个或者单个topic
@KafkaListener(topics = {"top_test"}, groupId = "foo")
public void listen3 (ConsumerRecord record) throws Exception {
//解析接收到的数据List及将接收到的数据入库
List list = JSONObject.parseArray(record.value(), Foo.class);
long starttime = System.currentTimeMillis();
String sql = "INSERT INTO `test` (`id`, `age`, `name`, `sex`, `message`) VALUES (?,?,?,?,?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Foo foo = list.get(i);
ps.setLong(1, foo.getId());
ps.setString(2, foo.getAge());
ps.setString(3, foo.getName());
ps.setString(4, foo.getSex());
ps.setString(5, foo.getMessage());
}
@Override
public int getBatchSize() {
System.err.println("接收数据条数:"+list.size());
return list.size();
}
});
long endtime = System.currentTimeMillis();
System.out.println("foo结束!耗费时间为"+(endtime-starttime)/1000+"s:::msg:");
System.out.printf("topic = %s, partition = %s, offset = %d, value = %s \n", record.topic(), record.partition(), record.offset(), record.value());
}
}
接下来我们可以使用postman测试一下,这里总共有1081条数据,如图
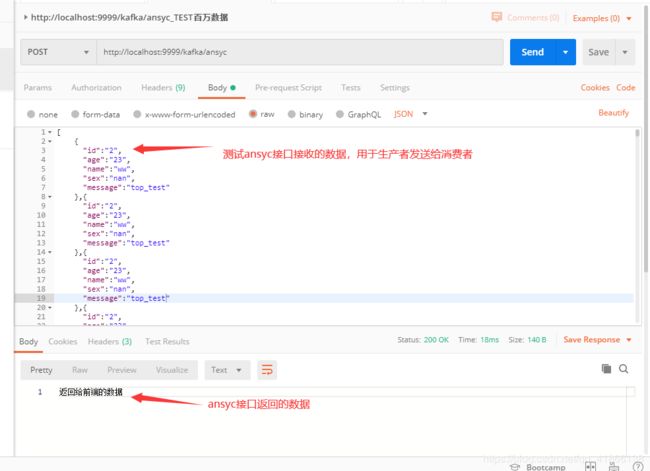
下图是消费者打印的接收到Foo数据的条数,以及kafka的一些信息及传递的数据,如图
![]()
上面的信息已经说明消费者成功接收到了生产者发送的数据,也已经入库了。
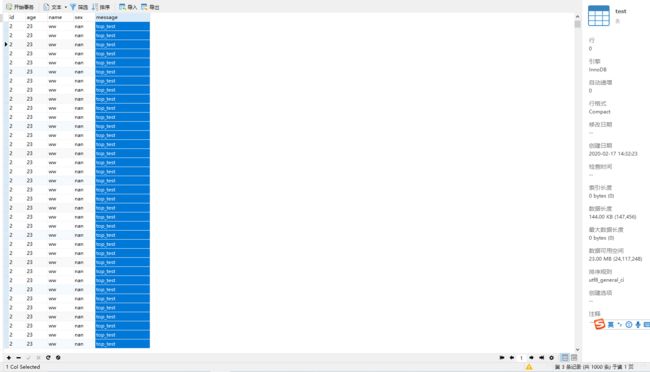
下面是数据库中数据,这说明数据库也入库成功了!如图
异步发送和同步发送我就不在这里测试了,把生产者代码中注释去掉就行了,有需要的自己测试看看。
需要注意在入库的时候,url路径一定要加**&rewriteBatchedStatements=true**,否则入库非常的慢,我之前使用jdbc遇到过这个问题,我用博客记录了下,有兴趣的可以去看看https://blog.csdn.net/qq_41866138/article/details/103802012