pytorch:Logistic回归
import matplotlib.pyplot as plt
from torch import nn, optim
import numpy as np
import torch
from torch.autograd import Variable
# 设置字体为中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
def readText():
with open('data.txt', 'r') as f:
data_list = f.readlines()
data_list = [i.split('\n')[0] for i in data_list]
data_list = [i.split(',') for i in data_list]
data = [(float(i[0]), float(i[1]), int(i[2])) for i in data_list]
x_data = [[float(i[0]), float(i[1])] for i in data_list]
y_data = [float(i[2]) for i in data_list]
return data, x_data, y_data
# 原始数据可视化
def visualize(data):
x0 = list(filter(lambda x: x[-1] == 0.0, data)) # 找出类别为0的数据集
x1 = list(filter(lambda x: x[-1] == 1.0, data)) # 找出类别为1的数据集
plot_x0_0 = [i[0] for i in x0] # 类别0的x
plot_x0_1 = [i[1] for i in x0] # 类别0的y
plot_x1_0 = [i[0] for i in x1] # 类别1的x
plot_x1_1 = [i[1] for i in x1] # 类别1的y
plt.plot(plot_x0_0, plot_x0_1, 'ro', label='类别 0')
plt.plot(plot_x1_0, plot_x1_1, 'bo', label='类别 1')
plt.legend() # 显示图例
plt.title(label='原始数据分布情况')
plt.show()
def visualize_after(data):
x0 = list(filter(lambda x: x[-1] == 0.0, data)) # 找出类别为0的数据集
x1 = list(filter(lambda x: x[-1] == 1.0, data)) # 找出类别为1的数据集
plot_x0_0 = [i[0] for i in x0] # 类别0的x
plot_x0_1 = [i[1] for i in x0] # 类别0的y
plot_x1_0 = [i[0] for i in x1] # 类别1的x
plot_x1_1 = [i[1] for i in x1] # 类别1的y
plt.plot(plot_x0_0, plot_x0_1, 'ro', label='类别 0')
plt.plot(plot_x1_0, plot_x1_1, 'bo', label='类别 1')
# 绘制分类函数
w0, w1 = model.lr.weight[0]
w0 = w0.data.item()
w1 = w1.data.item()
b = model.lr.bias.item()
plot_x = np.arange(30, 100, 0.1)
plot_y = (-w0 * plot_x - b) / w1
plt.plot(plot_x, plot_y, 'yo', label='分类线')
plt.legend() # 显示图例
plt.title(label='分类线可视化')
plt.show()
# Logistic回归模型
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.lr = nn.Linear(2, 1)
self.sm = nn.Sigmoid() # 激活函数类型为sigmoid,经过激活函数,值控制在0到1之间
def forward(self, x):
x = self.lr(x)
x = self.sm(x)
return x
# 主函数
if __name__ == '__main__':
data, x_data, y_data = readText() # 读取数据
x_data = torch.from_numpy(np.array(x_data))
y_data = torch.from_numpy(np.array(y_data))
visualize(data) # 可视化(观察原始数据分布情况)
# 获取到模型
model = LogisticRegression()
if torch.cuda.is_available():
model.cuda()
# 损失函数以及梯度下降
criterion = nn.BCELoss() # 二分类的损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
ctn = []
lo = []
for epoch in range(50000):
if torch.cuda.is_available():
x = Variable(x_data).cuda()
y = Variable(y_data).cuda()
else:
x = Variable(x_data)
y = Variable(y_data)
x = torch.tensor(x, dtype=torch.float32)
out = model(x)
y = torch.tensor(y, dtype=torch.float32)
loss = criterion(out, y)
print_loss = loss.data.item()
mask = out.ge(0.5).float() # 大于0.5则输出为1
correct = (mask == y).sum() # 统计输出为1的个数
acc = correct.item() / x.size(0)
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新梯度
ctn.append(epoch+1)
lo.append(print_loss)
if (epoch+1) % 1000 == 0:
print('*'*10)
print('epoch {}'.format(epoch+1))
print('loss is {:.4f}'.format(print_loss))
print('acc is {:.4f}'.format(acc))
visualize_after(data)
# 绘制训练次数与损失值之间的关系
plt.plot(ctn,lo)
plt.title(label='训练次数与损失值关系')
plt.xlabel('训练次数')
plt.ylabel('损失值')
plt.show()实验数据:
34.62365962451697,78.0246928153624,0
30.2867107622687,43.89499752400101,0
35.84740876993872,72.90219802708364,0
60.18259938620976,86.3855209546826,1
79.0327360507101,75.3443764369103,1
45.08327747668339,56.3163717815305,0
61.10666453684766,96.51142588489624,1
75.02474556738889,46.55401354116538,1
76.09878670226257,87.42056971926803,1
84.43281996120035,43.53339331072109,1
95.86155507093572,38.22527805795094,0
75.01365838958247,30.60326323428011,0
82.30705337399482,76.48196330235604,1
69.36458875970939,97.71869196188608,1
39.53833914367223,76.03681085115882,0
53.9710521485623,89.20735013750265,1
69.07014406283025,52.74046973016765,1
67.9468554771161746,67.857410673128,0实验结果:


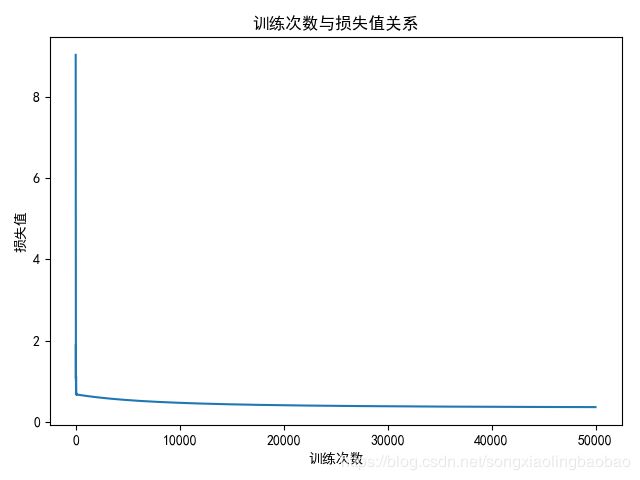
注意事项:
(1)数据太少,没有找到完整数据。
(2)注意类型转换,float64转为float32,对应代码为:
x = torch.tensor(x, dtype=torch.float32)
out = model(x)
y = torch.tensor(y, dtype=torch.float32)